
如何在Google BigQuery上计算移动和/平均值?
分析波动过大的数据序列的趋势是困难的。在许多情况下,使用平滑技术(如移动平均值或移动和)是有用的。有很多工具可以执行这类操作,但是当我们谈论数百万行时,直接在云环境(如Google )中这样做是很有用的。
我的问题是:如何计算Google上的移动和/avg?
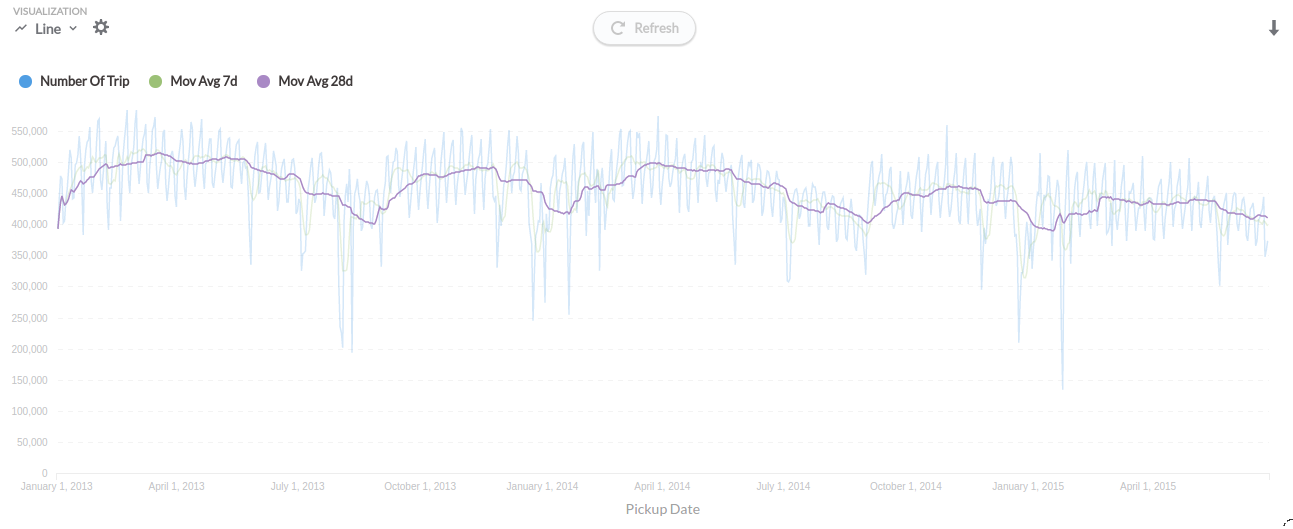
下面是我想要达到的移动平均线的数字:
回答 2
Stack Overflow用户
发布于 2017-10-17 22:12:26
下面是用于BigQuery标准SQL的
#standardSQL
SELECT
pickup_date,
number_of_trip,
AVG(number_of_trip) OVER (ORDER BY day RANGE BETWEEN 6 PRECEDING AND CURRENT ROW) AS mov_avg_7d,
AVG(number_of_trip) OVER (ORDER BY day RANGE BETWEEN 27 PRECEDING AND CURRENT ROW) AS mov_avg_28d
FROM (
SELECT
DATE(pickup_datetime) AS pickup_date,
UNIX_DATE(DATE(pickup_datetime)) AS day,
COUNT(*) AS number_of_trip
FROM `nyc-tlc.yellow.trips`
GROUP BY 1, 2
)
WHERE pickup_date>'2013-01-01'乍一看,这个答案看起来与OP的回答非常相似,所以很少有人评论这个答案是如何不同的:
首先(也是最不重要的)--这是BigQuery标准SQL,这是BigQuery团队强烈推荐使用的--除非一个人确实有充分的理由使用Legacy -例如,因为范围快照或一些非常特定于遗留SQL的内容。
第二,最重要的是,在这样的上下文中对行使用OVER并不是最好的选择,因为它计算行数而不是天数,因此,如果偶然地错过了任何一天,计算将分别使用最后8天和29天(而不是7天和28天)。
在这种情况下,人们应该使用范围超过。
Stack Overflow用户
发布于 2017-10-17 21:18:58
我花了大量的时间研究这个答案,但没有成功,所以我认为与更多的人分享这个答案是值得的。
解决方案:为了得到答案,我使用了Big的分析函数OVER with ROWS (https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#analytic-function-syntax)。贝娄有一个使用BigQuery公开数据的7天移动平均和28天移动平均的出租车旅行的例子:
SELECT
pickup_date,
number_of_trip,
avg(number_of_trip) OVER (ORDER BY pickup_date ROWS BETWEEN 6 PRECEDING and CURRENT ROW) AS mov_avg_7d,
avg(number_of_trip) OVER (ORDER BY pickup_date ROWS BETWEEN 27 PRECEDING and CURRENT ROW) AS mov_avg_28d
FROM
(SELECT
date(pickup_datetime) as pickup_date,
count(*) as number_of_trip,
FROM [nyc-tlc:yellow.trips]
group each by 1
order by 1)
where pickup_date>'2013-01-01'要小心反模式!网上有很多帖子建议使用JOIN甚至CROSS JOIN来实现同样的结果。然而,根据大查询文档(https://cloud.google.com/bigquery/docs/best-practices-performance-patterns),这些方法是反模式的。这意味着,如果使用蛮力解决问题,对于大量的数据,性能将是一个问题。
https://stackoverflow.com/questions/46799371
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号