
3,8字符切分不起作用
3,8字符切分不起作用
提问于 2018-05-06 07:53:47
我对图像处理很陌生。我想在OCR中执行字符分割。我已经做过必要的预处理了。当我通过寻找轮廓来执行字符分割时,除了字符3,8之外,它工作得很好。
经过预处理后的图像如下,
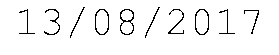
求出3和8的轮廓后的输出是
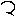

所用代码:
imgGray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
ret, imgThresh = cv2.threshold(imgGray, 127, 255, 0)
image, contours , _ = cv2.findContours(imgThresh, cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)但是对于其他角色来说,这是一个很好的结果:

如何解决这个问题?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-05-06 08:16:56
由于您的图像不涉及任何复杂的背景,所以我使用Otsu的方法为我选择正确的阈值:
threshold, thresh_img = cv2.threshold(imgGray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)

现在,当你找到等高线时,它会更容易。这是因为在白色的物体或字符中可以找到等高线。

看看那些现在引起问题的字符:
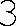

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50197440
复制相关文章
相似问题
腾讯云开发者
