
如何从零开始建立人脸识别系统?
如何从零开始建立人脸识别系统?
提问于 2019-03-22 00:10:18
我正在为人脸识别系统构建一个原型,在编写算法时,我有几个问题。
算法:
- 收集锚点的(A(i),P(i),N(i)) -set,XYX公司员工的正面、负面图像。
- 利用梯度下降训练三重态损失函数来学习它的参数。实际上,我在这里训练一个暹罗网络(在两个不同的输入上运行两个相同的CNN‘,一次在A(i)-P(i)和next A(i)-N(i)上运行,然后比较它们)。
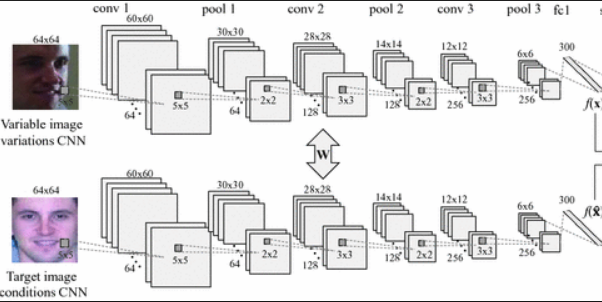
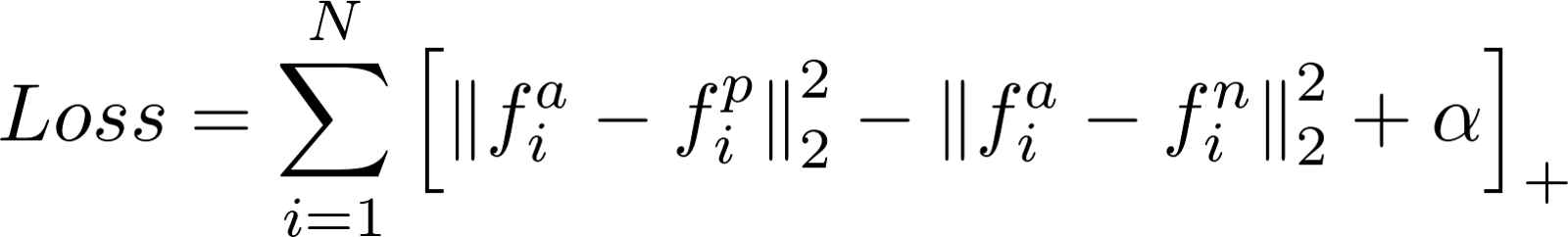
这些学习参数将确保相同图像的平坦的n-昏暗编码之间的距离会很小,而不同的图像之间的距离会很大。
- 现在,创建一个数据库,您将存储XYX公司员工的每个培训图像的编码! 简单地向前通过经过训练的CNN,并将每幅图像的对应编码存储在数据库中。
- 在测试时,您有XYX公司员工的形象和局外人的形象!
- You will pass both of the test images through the CNN and get the corresponding encodings!
- Now, **The question comes** that how would you find the similarity between the test-picture-encoding and all the training-picture-encoding in the database? - **First question**, Would you do cosine similarity or I need to do something else? Can you add more clarity on it?
- **Second question**, Also, in terms of efficiency, how would you handle a scenario wherein you have 100,000 employees training-picture-encoding in the database present and for every new person you need to look these 100,000 encodings and compute cosine similarity and give result in <2 secs? Any suggestion on this part?
- **Third question** usually for face recognition task if we use approach(Image-->CNN-->SoftMax--> output), Each time a new person joins your organization you need to retrain your network, that's why it's a bad approach! - This problem can be mitigated by using the 2nd approach wherein we are using a learned distance function "d(img1, img2)" over a pair of images of employees as stated above on in **point 1 to 3**.
-
- **My question** is in case of a new employee joining the organization, How this learned distance function would be able to generalize when it was not been used in the training set at all? Isn't a problem of changed data distribution of test and train set? Any suggestion in this regards
有人能帮助理解这些概念上的小故障吗?
Stack Overflow用户
回答已采纳
发布于 2019-03-27 19:36:45
在对人脸验证和识别/检测的相关文献进行综述的基础上,提出了计算机视觉领域的研究论文。我想我所有的问题都有答案,所以我在这里试着回答。
第一个问题,你会做余弦相似吗?你能给它增加更多的清晰度吗?
- 通过简单计算测试之间的欧几里德距离,找出测试与每个保存的列车图像之间的最小距离。
- 不保持一个阈值,比如说0.7,并且是最小距离是< 0.7,返回员工的姓名,否则“不在数据库错误!
第二个问题,在效率方面,您将如何处理这样一个场景:数据库中有100,000名员工进行培训-图像编码,对于每一个需要查看这100,000个编码和计算余弦相似性的新人员,并给出<2秒?的结果。
- 应该注意的是,在训练过程中使用了128维浮点矢量,但是它可以量化到128字节,而不会失去准确性。因此,每个人脸都用128维字节向量来表示,这是大规模聚类和识别的理想选择。较小的嵌入可以在较小程度上丢失准确性,并可用于移动设备上。
第三个问题:-首先,我们正在通过最小化三重态损失函数来学习深层CNN的网络参数!
- 第二,假设你已经在数百万人的庞大数据集上训练了这些模型权重,这些权重学到了两个更高层次的特征,比如一个人的身份、性别等等!以及低层次特征,如与人脸相关的边缘。
- 现在,假设这些模型参数一起至少可以表示任何人脸,因此您将继续通过网络将“新的人”编码保存在数据库中,然后使用答案1来计算此人是否属于组织(人脸识别问题)。此外,在FaceNet的论文中提到,我们保留了大约100万张图像,其分布与我们的训练集相同,但身份不相交。
- 第三,这两种技术的不同之处在于,我们在第一种技术中训练这些模型权重的方法是使用损失函数:交叉熵、softmax和第二技术损失函数:三重态损失函数!
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55291009
复制相关文章
相似问题
腾讯云开发者
