腾讯云
开发者社区
文档
建议反馈
控制台
首页
学习
活动
专区
工具
TVP
最新优惠活动
文章/答案/技术大牛
搜索
搜索
关闭
发布
登录/注册
精选内容/技术社群/优惠产品,
尽在小程序
立即前往
首页
学习
活动
专区
工具
TVP
最新优惠活动
返回腾讯云官网
腾讯技术创作狂欢月,瓜分万元奖品池!
邀你启笔,“码”上创作 21 天。
立即发文
答题瓜分10000元现金,腾讯技术面霸挑战赛
更有机械键盘、智能手表等千份豪礼等你来赢
立即参加
有奖问答—长期当程序员会改变什么?
一如编程深似海,从此代码夜夜改
立即回答
RAG七天入门训练营
鹅厂大牛手把手带你上手实战,赢鹅厂证书、公仔好礼!
立即学习
玩转EdgeOne,发文即有奖,豪礼来袭!
鹅厂下一代 CDN 能力又升级!限时免费体验
立即参加
精选文章
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
管理
前端
腾讯技术创作特训营S6
vue.js
echarts
【问题解决】解决 ECharts 图表窗口自适应与数据不渲染问题
在项目中使用 ECharts 遇到了一些问题,包括图表不会随着窗口大小变化而变化,以及父组件向子组件传值时,ECharts 中的值不会被同步渲染等,因此写本博文进行记录;
sidiot
2024-04-15
60
0
玩转EdgeOne
cdn
EdgeOne
腾讯EdgeOne产品测评体验—使用后不敢相信,我的3D网站性能居然提升这么多
随着云计算技术的飞速发展,边缘计算和加速作为连接云端与终端的关键桥梁,正逐渐成为行业关注的焦点。腾讯作为国内领先的科技企业,推出的EdgeOne边缘计算产品引起了市场的广泛关注。本篇文章博主通过亲身测评EdgeOne产品集成后,3D网站的加速和安全两个维度的性能,为读者全面展示腾讯EdgeOne产品的性能与优点。
国服第二切图仔
2024-04-15
2.9K
0
nginx
腾讯技术创作特训营S6
nginx安装:源码case语句不加break导致编译错误,该怎么办...
上篇文章写了在新买的vps上,使用nginx搭建了一个http代理服务器。在nginx的编译、安装过程中,遇到了几个问题,所以本篇文章就是总结一下nginx安装问题和解决方法。
叫我阿柒啊
2024-04-16
119
1
边缘安全加速平台 EO
EdgeOne
玩转EdgeOne
【玩转EdgeOne】 实践教程:打造全面安全防护策略
在数字化时代背景下,安全防护需求的增长已成为一个不可忽视的全球性议题。随着互联网、物联网和云计算等技术的广泛应用,数据已成为推动社会发展的关键资源。然而,这些技术的普及也带来了新的安全挑战,如个人信息泄露、网络诈骗和网络攻击等,对个人隐私、企业资产和国家安全构成威胁。因此,加强安全防护措施,提升网络安全意识和能力,对于保障数字化进程中的安全至关重要。
Y-StarryDreamer
2024-04-15
86
0
go
EdgeOne
【每日精选时刻】Mojo一门为 AI 而生的语言;EdgeOne安全在哪;微信视频号编译优化
大家吼,我是你们的朋友煎饼狗子——喜欢在社区发掘有趣的作品和作者。【每日精选时刻】是我为大家精心打造的栏目,在这里,你可以看到煎饼为你携回的来自社区各领域的新鲜出彩作品。点此一键订阅【每日精选时刻】专栏,吃瓜新鲜作品不迷路! *当然,你也可以在本篇文章,评论区自荐/推荐他人优秀作品(标题+链接+推荐理由),增加文章入选的概率哟~
社区好文捕手-煎饼狗子
2024-04-17
92
0
python
python3
热点技术征文第六期Mojo
实战Mojo🔥安装 & 使用,Python 开发者不必惊慌
前一阵子就在各个公众号中看到 Mojo 相关的文章推送了,标题中均与 py 进行了对比
远哥制造
2024-04-15
159
0
java
腾讯技术创作特训营S6
JWT在Spring Boot中的最佳实践:构建坚不可摧的安全堡垒
大家好,我是腾讯云开发者社区的 Front_Yue,本篇文章将介绍什么是JWT以及在JWT在Spring Boot项目中的最佳实践。
Front_Yue
2024-04-16
147
0
权限控制
腾讯技术创作特训营S6
java
权限
什么是Spring Security?具有哪些功能?
本篇将带你快速了解什么是Spring Security,通过入门案例以及相关原理和类的分析让你快速入门。
reload
2024-04-16
67
1
c++11
c++
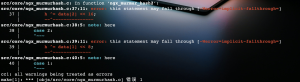
深度解读《深度探索C++对象模型》之默认构造函数
提到默认构造函数,很多文章和书籍里提到:“在需要的时候编译器会自动生成一个默认构造函数”。那么关键的问题来了,到底是什么时候需要?是谁需要?比如下面的代码会生成默认构造函数吗?
爱分享
2024-04-16
101
0
边缘安全加速平台 EO
EdgeOne
玩转EdgeOne
DDoS 防护
cdn
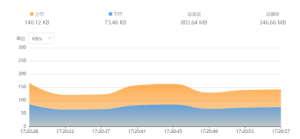
腾讯EdgeOne产品测评体验—Web服务全能一体化服务,主打一步到位
现在网络Web攻击真的防不胜防啊,相信有很多独狼开发者自己建站,租个云服务器,一部署自己的服务,每隔一段时间内测和网站总有一个要崩。自己感觉难受不说,网站稍微有点要出头的时候,数不清的访问攻击就接踵而至:恶意软件、SQL注入、网站挟持、钓鱼攻击、跨站脚本攻击、恶意爬虫等等,让个人开发者甚为揪心,如果是企业网站的话,攻势有过之无不及。
fanstuck
2024-04-16
1.8K
0
精选文章
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
【问题解决】解决 ECharts 图表窗口自适应与数据不渲染问题
在项目中使用 ECharts 遇到了一些问题,包括图表不会随着窗口大小变化而变化,以及父组件向子组件传值时,ECharts 中的值不会被同步渲染等,因此写本博文进行记录;
sidiot
2024-04-15
腾讯EdgeOne产品测评体验—使用后不敢相信,我的3D网站性能居然提升这么多
随着云计算技术的飞速发展,边缘计算和加速作为连接云端与终端的关键桥梁,正逐渐成为行业关注的焦点。腾讯作为国内领先的科技企业,推出的EdgeOne边缘计算产品引起了市场的广泛关注。本篇文章博主通过亲身测评EdgeOne产品集成后,3D网站的加速和安全两个维度的性能,为读者全面展示腾讯EdgeOne产品的性能与优点。
国服第二切图仔
2024-04-15
nginx安装:源码case语句不加break导致编译错误,该怎么办...
上篇文章写了在新买的vps上,使用nginx搭建了一个http代理服务器。在nginx的编译、安装过程中,遇到了几个问题,所以本篇文章就是总结一下nginx安装问题和解决方法。
叫我阿柒啊
2024-04-16
【玩转EdgeOne】 实践教程:打造全面安全防护策略
在数字化时代背景下,安全防护需求的增长已成为一个不可忽视的全球性议题。随着互联网、物联网和云计算等技术的广泛应用,数据已成为推动社会发展的关键资源。然而,这些技术的普及也带来了新的安全挑战,如个人信息泄露、网络诈骗和网络攻击等,对个人隐私、企业资产和国家安全构成威胁。因此,加强安全防护措施,提升网络安全意识和能力,对于保障数字化进程中的安全至关重要。
Y-StarryDreamer
2024-04-15
【每日精选时刻】Mojo一门为 AI 而生的语言;EdgeOne安全在哪;微信视频号编译优化
大家吼,我是你们的朋友煎饼狗子——喜欢在社区发掘有趣的作品和作者。【每日精选时刻】是我为大家精心打造的栏目,在这里,你可以看到煎饼为你携回的来自社区各领域的新鲜出彩作品。点此一键订阅【每日精选时刻】专栏,吃瓜新鲜作品不迷路! *当然,你也可以在本篇文章,评论区自荐/推荐他人优秀作品(标题+链接+推荐理由),增加文章入选的概率哟~
社区好文捕手-煎饼狗子
2024-04-17
实战Mojo🔥安装 & 使用,Python 开发者不必惊慌
前一阵子就在各个公众号中看到 Mojo 相关的文章推送了,标题中均与 py 进行了对比
远哥制造
2024-04-15
JWT在Spring Boot中的最佳实践:构建坚不可摧的安全堡垒
大家好,我是腾讯云开发者社区的 Front_Yue,本篇文章将介绍什么是JWT以及在JWT在Spring Boot项目中的最佳实践。
Front_Yue
2024-04-16
什么是Spring Security?具有哪些功能?
本篇将带你快速了解什么是Spring Security,通过入门案例以及相关原理和类的分析让你快速入门。
reload
2024-04-16
深度解读《深度探索C++对象模型》之默认构造函数
提到默认构造函数,很多文章和书籍里提到:“在需要的时候编译器会自动生成一个默认构造函数”。那么关键的问题来了,到底是什么时候需要?是谁需要?比如下面的代码会生成默认构造函数吗?
爱分享
2024-04-16
腾讯EdgeOne产品测评体验—Web服务全能一体化服务,主打一步到位
现在网络Web攻击真的防不胜防啊,相信有很多独狼开发者自己建站,租个云服务器,一部署自己的服务,每隔一段时间内测和网站总有一个要崩。自己感觉难受不说,网站稍微有点要出头的时候,数不清的访问攻击就接踵而至:恶意软件、SQL注入、网站挟持、钓鱼攻击、跨站脚本攻击、恶意爬虫等等,让个人开发者甚为揪心,如果是企业网站的话,攻势有过之无不及。
fanstuck
2024-04-16
中午好!
欢迎来到腾讯云开发者社区
登录
沙龙日历
全部 >
加入讨论
的问答专区 >
原创作者热度排行榜
更多 >
问题归档
专栏文章
快讯文章归档
关键词归档
开发者手册归档
开发者手册 Section 归档
领券