腾讯云
开发者社区
文档
建议反馈
控制台
首页
学习
活动
专区
工具
TVP
最新优惠活动
文章/答案/技术大牛
搜索
搜索
关闭
发布
登录/注册
精选内容/技术社群/优惠产品,
尽在小程序
立即前往
首页
学习
活动
专区
工具
TVP
最新优惠活动
返回腾讯云官网
知识漂流计划——分享你“压箱底”的宝藏好书
一书换一友,旧书换新知
立即分享
腾讯技术创作狂欢月,瓜分万元奖品池!
邀你启笔,“码”上创作 21 天。
立即发文
答题瓜分10000元现金,腾讯技术面霸挑战赛
更有机械键盘、智能手表等千份豪礼等你来赢
立即参加
RAG七天入门训练营
鹅厂大牛手把手带你上手实战,赢鹅厂证书、公仔好礼!
立即学习
精选文章
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
管理
intellij idea
插件
腾讯技术创作特训营S6
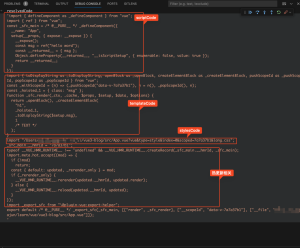
啥?IDEA可以帮我写代码了?
前言--这是一篇关于CodeGeeX的使用测评。在AI时代,还不会使用AI工具助力提升工作效率的,多半会被同事或者领导嫌弃,甚至于被时代所抛弃...........
世玉
2024-04-24
280
4
程序员
流媒体
模型
调试
音视频
程序员不存在了……吗?
从 2016 年 AlphaGo 击败李世石开始,关注 AI 技术发展的人越来越多。其实,AI 技术已经在数十年前便开始发展和沉淀,而且最近几年内,AI 技术发展的速度变得越来越快,AI 技术在发展的速度和质量上也有了非常显著的提升。这让我越来越看到希望,并且期待未来 AI 技术的发展。
腾讯云开发者
2024-04-24
132
0
python
websocket
使用 Postman、Python 测试 WebSocket(wss)
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
Lorin 洛林
2024-04-24
166
0
字符串
debug
编译
对象
函数
通过debug搞清楚.vue文件怎么变成.js文件
我们每天写的vue代码都是写在vue文件中,但是浏览器却只认识html、css、js等文件类型。所以这个时候就需要一个工具将vue文件转换为浏览器能够认识的js文件,想必你第一时间就想到了webpack或者vite。但是webpack和vite本身是没有能力处理vue文件的,其实实际背后生效的是vue-loader和@vitejs/plugin-vue。本文以@vitejs/plugin-vue举例,通过debug的方式带你一步一步的搞清楚vue文件是如何编译为js文件的,看不懂你来打我。
前端欧阳
2024-04-24
79
0
java
c++
rust
rust-lang
一起长锈:1 超好用的Rust工具链(Java与C++程序员转Rust之旅)
女程序员赵可菲加班到深夜,正在修复老旧Java系统的nul pointer exception缺陷。
程序员吾真本
2024-04-24
59
0
腾讯技术创作特训营S6
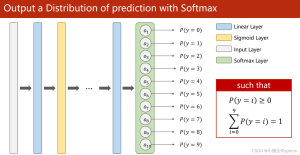
使用PyTorch解决多分类问题:构建、训练和评估深度学习模型
之前我们讨论的问题都是二分类居多,对于二分类问题,我们若求得p(0),南无p(1)=1-p(0),还是比较容易的,但是本节我们将引入多分类,那么我们所求得就转化为p(i)(i=1,2,3,4…),同时我们需要满足以上概率中每一个都大于0;且总和为1。
小馒头学Python
2024-04-24
140
0
开源
mysql
【每日精选时刻】OSI有7层,你在第几层?MySQL并发事务该怎么处理?我贡献了一次5倍性能提升的PR!
大家吼,我是你们的朋友煎饼狗子——喜欢在社区发掘有趣的作品和作者。【每日精选时刻】是我为大家精心打造的栏目,在这里,你可以看到煎饼为你携回的来自社区各领域的新鲜出彩作品。点此一键订阅【每日精选时刻】专栏,吃瓜新鲜作品不迷路! *当然,你也可以在本篇文章,评论区自荐/推荐他人优秀作品(标题+链接+推荐理由),增加文章入选的概率哟~
社区好文捕手-煎饼狗子
2024-04-24
100
0
对象
垃圾回收
内存
学习笔记
go
GO语言学习笔记 | 垃圾回收机制剖析
垃圾回收(Garbage Collection,GC) 是Go语言的核心特性之一,是实现内存自动管理的一种形式。golang的自动垃圾回收屏蔽了复杂且容易出错的内存操作,让开发变得更加简单、高效。在Go语言中,从实现机制上来说,垃圾回收可能是最复杂的模块了。了解垃圾回收的机制,有助于更好地理解Go语言的内存管理机制,从而更好的使用Go语言进行开发。
windealli
2024-04-23
143
0
图像处理
图像创作
腾讯技术创作特训营S6
c#
C#实战:基于腾讯云的图像服务实现图片清晰度增强介绍和案例实践
基于腾讯云深度学习等人工智能技术,消除图片因有损压缩导致的噪声,改善因使用滤镜、拍摄失焦等导致的图像模糊问题,让图片的边缘和细节更加清晰自然。
IT技术分享社区
2024-04-24
106
0
nlp
LLM
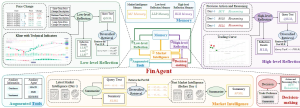
解密Prompt系列28. LLM Agent之金融领域智能体:FinMem & FinAgent
本章介绍金融领域大模型智能体,并梳理金融LLM的相关资源。金融领域的大模型智能体当前集中在个股交易决策这个相对简单的场景,不需要考虑多资产组合的复杂场景。交易决策被简化成市场上各个信息,包括技术面,消息面,基本面等等在不同市场情况下,对资产价格变动正负面影响的综合判断。
风雨中的小七
2024-04-24
112
0
精选文章
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
啥?IDEA可以帮我写代码了?
前言--这是一篇关于CodeGeeX的使用测评。在AI时代,还不会使用AI工具助力提升工作效率的,多半会被同事或者领导嫌弃,甚至于被时代所抛弃...........
世玉
2024-04-24
程序员不存在了……吗?
从 2016 年 AlphaGo 击败李世石开始,关注 AI 技术发展的人越来越多。其实,AI 技术已经在数十年前便开始发展和沉淀,而且最近几年内,AI 技术发展的速度变得越来越快,AI 技术在发展的速度和质量上也有了非常显著的提升。这让我越来越看到希望,并且期待未来 AI 技术的发展。
腾讯云开发者
2024-04-24
使用 Postman、Python 测试 WebSocket(wss)
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
Lorin 洛林
2024-04-24
通过debug搞清楚.vue文件怎么变成.js文件
我们每天写的vue代码都是写在vue文件中,但是浏览器却只认识html、css、js等文件类型。所以这个时候就需要一个工具将vue文件转换为浏览器能够认识的js文件,想必你第一时间就想到了webpack或者vite。但是webpack和vite本身是没有能力处理vue文件的,其实实际背后生效的是vue-loader和@vitejs/plugin-vue。本文以@vitejs/plugin-vue举例,通过debug的方式带你一步一步的搞清楚vue文件是如何编译为js文件的,看不懂你来打我。
前端欧阳
2024-04-24
一起长锈:1 超好用的Rust工具链(Java与C++程序员转Rust之旅)
女程序员赵可菲加班到深夜,正在修复老旧Java系统的nul pointer exception缺陷。
程序员吾真本
2024-04-24
使用PyTorch解决多分类问题:构建、训练和评估深度学习模型
之前我们讨论的问题都是二分类居多,对于二分类问题,我们若求得p(0),南无p(1)=1-p(0),还是比较容易的,但是本节我们将引入多分类,那么我们所求得就转化为p(i)(i=1,2,3,4…),同时我们需要满足以上概率中每一个都大于0;且总和为1。
小馒头学Python
2024-04-24
【每日精选时刻】OSI有7层,你在第几层?MySQL并发事务该怎么处理?我贡献了一次5倍性能提升的PR!
大家吼,我是你们的朋友煎饼狗子——喜欢在社区发掘有趣的作品和作者。【每日精选时刻】是我为大家精心打造的栏目,在这里,你可以看到煎饼为你携回的来自社区各领域的新鲜出彩作品。点此一键订阅【每日精选时刻】专栏,吃瓜新鲜作品不迷路! *当然,你也可以在本篇文章,评论区自荐/推荐他人优秀作品(标题+链接+推荐理由),增加文章入选的概率哟~
社区好文捕手-煎饼狗子
2024-04-24
GO语言学习笔记 | 垃圾回收机制剖析
垃圾回收(Garbage Collection,GC) 是Go语言的核心特性之一,是实现内存自动管理的一种形式。golang的自动垃圾回收屏蔽了复杂且容易出错的内存操作,让开发变得更加简单、高效。在Go语言中,从实现机制上来说,垃圾回收可能是最复杂的模块了。了解垃圾回收的机制,有助于更好地理解Go语言的内存管理机制,从而更好的使用Go语言进行开发。
windealli
2024-04-23
C#实战:基于腾讯云的图像服务实现图片清晰度增强介绍和案例实践
基于腾讯云深度学习等人工智能技术,消除图片因有损压缩导致的噪声,改善因使用滤镜、拍摄失焦等导致的图像模糊问题,让图片的边缘和细节更加清晰自然。
IT技术分享社区
2024-04-24
解密Prompt系列28. LLM Agent之金融领域智能体:FinMem & FinAgent
本章介绍金融领域大模型智能体,并梳理金融LLM的相关资源。金融领域的大模型智能体当前集中在个股交易决策这个相对简单的场景,不需要考虑多资产组合的复杂场景。交易决策被简化成市场上各个信息,包括技术面,消息面,基本面等等在不同市场情况下,对资产价格变动正负面影响的综合判断。
风雨中的小七
2024-04-24
下午好!
欢迎来到腾讯云开发者社区
登录
沙龙日历
全部 >
加入讨论
的问答专区 >
原创作者热度排行榜
更多 >
问题归档
专栏文章
快讯文章归档
关键词归档
开发者手册归档
开发者手册 Section 归档
领券