背景
本文指导如何使用 Python 的工具包 pyarrow 操作 CHDFS。
部署环境
1. Python 3.7版本及以上。PyArrow 目前与 Python 3.7、3.8、3.9 和 3.10 兼容。
2. 使用如下命令,安装 pyarrow 库:
pip3 install pyarrow -imagepip3 install pyarrow -image -i http://mirrors.tencent.com/pypi/simple --trusted-host mirrors.tencent.com
部署组件
编写 Python 程序
1. 使用 pyarrow 访问 CHDFS,示例代码如下:
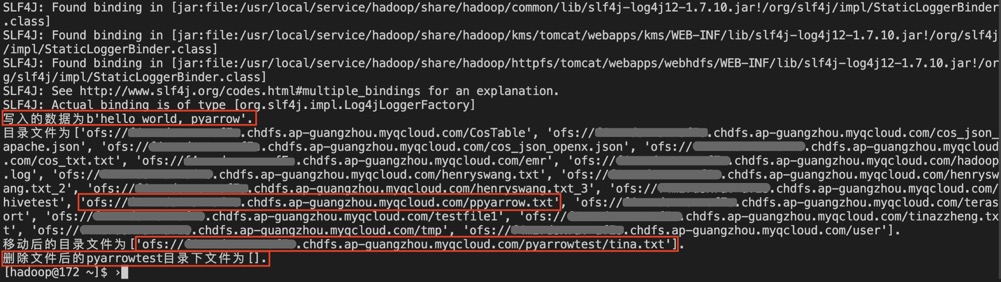
import pyarrow as pahost = "ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com"fs = pa.hdfs.connect(host, 0)# open(path, mode)模式 w,文件不存在创建一个文件out_file = fs.open("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/ppyarrow.txt","wb")out_file.write(str.encode("hello world, pyarrow")) #写out_file.close()in_file = fs.open("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/ppyarrow.txt","rb")# 将光标重置到起始位置in_file.seek(0)data = in_file.read() # 读print("写入的数据为%s."%(data))in_file.close()# 列出文件ls_file = fs.ls("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/")print("目录文件为%s." %(ls_file))# 创建目录fs.mkdir("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/pyarrowtest")# 移动并重命名文件fs.mv("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/ppyarrow.txt", "ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/pyarrowtest/tina.txt")# 列出文件mv_file = fs.ls("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/pyarrowtest")print("移动后的目录文件为%s." %(mv_file))# 删除测试文件,重新列出文件fs.delete("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/pyarrowtest/tina.txt")de_file = fs.ls("ofs://xxx-xxx.chdfs.ap-guangzhou.myqcloud.com/pyarrowtest/")print("删除文件后的pyarrowtest目录下文件为%s." %(de_file))
2. 设置环境变量,示例如下:
export JAVA_HOME=/usr/local/jdk #设置 JAVA_HOME,根据自己安装位置定export HADOOP_HOME=/usr/local/service/hadoop #设置 HADOOP_HOME,hadoop 的安装位置export CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath --glob`#参考网址 https://arrow.apache.org/docs/python/filesystems.html#hadoop-file-system-hdfs
3. 执行 Python 文件:
python3 libtest.py
4. 执行过程及结果如下: