连接和通道
不要每次发送消息都创建连接/通道
在 RabbitMQ 中,创建连接是一个“昂贵”的操作。每个连接会使用至少 100KB 的内存,连接数过多会增大 Broker 的内存压力。连接建立时的握手过程十分复杂,至少需要 7 个 TCP 数据包。相比之下,通道是一种更加轻量的通信方式,建议尽可能多的使用通道来复用连接。在程序启动时创建连接,每次发送消息时复用此长连接,能够提升发送性能和减少服务端内存占用。理想情况下,每个进程使用一个连接,每个线程使用一个通道。
不要在线程之间共享通道
确保不在线程之间共享通道,大多数 RabbitMQ 客户端的通道实现不是线程安全的,共享可能会导致消息处理出错,性能反而下降,出现非预期的连接问题。
生产者和消费者使用独立的连接
由于 RabbitMQ 有独特的流控机制,如果生产者和消费者复用同一个连接,且消费流量大触发了流控,可能会导致生产者被流控导致发送慢或超时,因此建议生产者和消费者初始化时使用不同的物理连接,避免互相影响。
大量的连接和通道可能会影响 RabbitMQ 管理接口的性能
管理界面需要为每个连接和通道实时收集运行指标、进行数据分析并提供可视化展示,这些操作会消耗大量系统资源。随着连接和通道数量的增加,管理界面的响应速度可能会下降,从而影响监控和管理效率。
生产和消费
消费者不建议开启自动消息确认
RabbitMQ 服务端提供了至少投递一次的消费语义,以确保消息正确地触达到下游业务系统。一旦消费端开启了自动确认消息,服务端将消息推送给消费方后,就自动确认删除消息,即使消费端处理消息时出现了异常也不会重试,可能会导致业务上漏处理消息。
消费者幂等处理消息
RabbitMQ 服务端提供了至少投递一次的消费语义,极端场景下有可能重复投递消息,因此建议关键业务处理消息时一定要做幂等处理,即使收到重复消息,也不会产生负面业务影响。
业务幂等处理可以通过在消息中加入唯一业务标识,消费端消费时检查此类标识和消息状态等,根据业务需求处理重复消息,保证即使重复接收消息也不会产生业务上的负面影响。
使用 Consume 消费消息
Get 作为拉模式的消息消费方式,每消费一条消息都需要向 Broker 发送一个请求。而 Consume 一次可以接收一批消息,并且由服务端根据实际情况推送消息。不建议通过 Get 消费消息,因为这非常低效且会消耗大量资源,持续空拉(队列中已经无待消费的消息,但消费端一直持续 Get)会导致服务端 CPU 负载异常高。
设置合理的消息负载
消息负载(大小与类型)的处理是 RabbitMQ 用户常遇到的问题。需注意,每秒处理的消息数量对性能的影响通常远大于单一消息的大小。尽管发送过大的消息并非良好实践,但频繁发送大量小型消息可能对系统造成更大压力。
一种推荐的做法是将多条小消息合并为一条较大的消息进行发送,由消费者在接收后解包处理。但需注意,消息合并可能引入以下问题:
若合并后的某条子消息处理失败,是否需整体重传?
捆绑处理可能增加单次消息的处理时长,影响实时性。
因此,在决定是否捆绑消息时,应综合考虑网络带宽、系统架构及业务容错要求。
设置合理的预取值(Prefetch Count)
预取值用于指定同时向消费者发送的消息数量。预取值过低可能导致消费者频繁等待新消息,造成资源空闲;预取值过高则可能造成部分消费者过载,而其他消费者闲置,导致负载不均。
若存在一个或少数几个能快速处理消息的消费者,建议适当提高预取值,例如250。即一次预取多条消息,以保持客户端持续处于忙碌状态。
若各消息处理时间相对稳定且网络条件可控,可通过以下方式估算预取值:预取值 ≈ 总往返时间(RTT) / 单条消息平均处理时间。
在消费者数量较多且单条消息处理时间较短的场景中,建议设置较低的预取值。
若消费者数量较多和/或单条消息处理时间较长,建议将预取值设置为 1,以确保消息在多个消费者间均匀分配。
请注意:
若客户端设置为自动确认消息(Auto-Ack),则预取机制不会生效。
一个常见错误是采用无限制的预取策略。这可能导致单个客户端接收全部消息,耗尽内存并崩溃,进而引发所有消息被重新投递,严重影响系统稳定性。
global prefetch 已废弃,请不要使用。
队列
控制队列里的消息数量
队列里积压太多消息会占用大量内存,为了降低内存占用,RabbitMQ 会把部分消息刷新到磁盘上,但这会让消息处理变慢。特别是当积压消息特别多时,分页读取消息会拖累整个系统的处理速度。
另外,当需要重启 RabbitMQ 集群时,如果有大量积压消息也会遇到两个问题:
1. 重启时要重新建立消息索引,耗时较长。
2. 重启后各个节点之间同步消息也需要额外时间
建议通过提高消费能力、设置 max-length 或 TTL 等手段控制队列中的消息数量,避免消息积压,这样系统才能保持最佳性能。
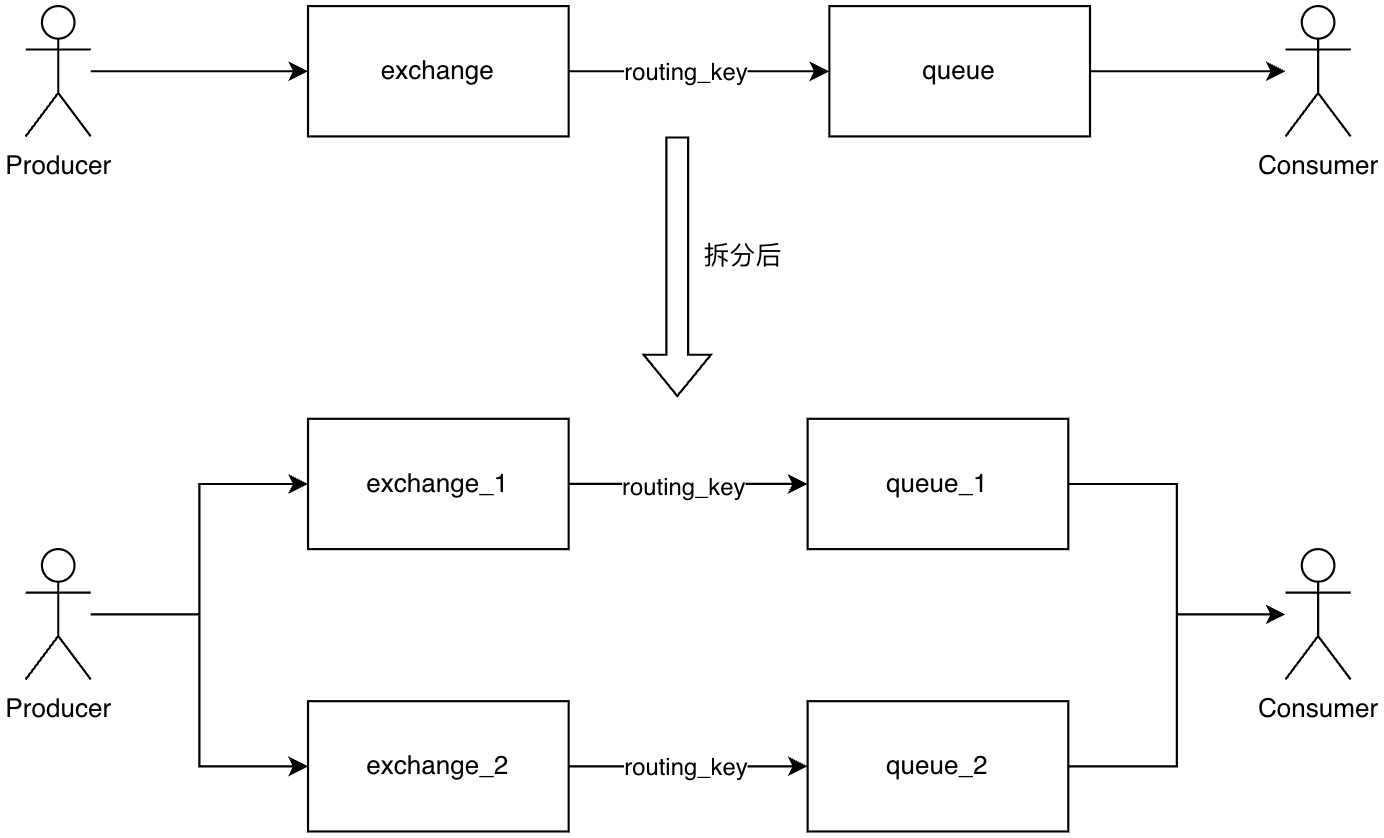
拆分队列流量
受限于 Erlang 的进程模型,RabbitMQ 中的队列性能受限于 CPU 单核性能,无法横向扩展。因此如果需要提升集群吞吐,可以将流量拆分到不同的队列上,以利用 CPU 多核能力。以下是一种可供参考的拆分方案。
控制队列数量
RabbitMQ 管理插件会为集群中的每个队列收集和计算指标,且每个队列都需要占用一定的系统资源,因此如果队列数量过多,集群性能会受到影响。建议根据业务侧估算的队列数量在购买页选择合适的节点规格。
合理设置优先级队列的数量
RabbitMQ 的优先级队列会占用额外资源(因为每个优先级在底层都会单独处理)。
建议:
大多数业务场景下,设置 3-5 个优先级级别 就完全够用了。
不要设置过多优先级(例如 10 个以上),否则会浪费系统资源。
自动删除未使用的队列
客户端连接可能因意外中断而失败,遗留未使用的队列资源,进而影响系统性能。以下三种机制支持队列的自动删除:
1. 设置队列 TTL 策略可为队列配置生存时间(TTL)。例如,设置 28 天的 TTL 后,队列若在 28 天内未被使用,将被自动删除。
2. 自动删除队列(Auto-Delete Queues):当队列的最后一个消费者取消订阅,或声明该队列的通道/连接关闭(包括与服务器之间的 TCP 连接丢失)时,此类队列将被自动删除。
3. 独占队列(Exclusive Queues):独占队列仅允许由其声明连接进行操作(例如消费、清除或删除)。当声明连接关闭或异常断开(如底层 TCP 连接丢失)时,独占队列会被立即自动删除。
使用仲裁队列
自 RabbitMQ 3.8 起引入了一种新的队列类型——仲裁队列(Quorum Queues)。这是一种基于 Raft 协议实现的复制队列,旨在提供更高的数据安全性和可用性。在3.13 版本推荐优先选择仲裁队列以替代传统镜像队列。
启用惰性队列以提升性能可预测性(适用于 RabbitMQ 版本 < 3.12)
RabbitMQ 3.6 版本引入了“惰性队列”(Lazy Queues)功能。惰性队列会将消息直接持久化到磁盘,而非尽量保留于内存,从而显著降低内存使用量,但可能会增加消息处理的延迟。
根据实际运维经验,惰性队列有助于构建更稳定的集群环境,其性能表现也更具可预测性。消息不会在无预警的情况下集中刷入磁盘,避免了队列性能的突然下降。因此,在需要一次性处理大量消息(如批处理任务),或预计消费者处理速度可能持续落后于生产者时,建议启用惰性队列。
请注意,从 RabbitMQ 3.12 版本开始,所有经典队列(Classic Queues)已默认采用与惰性队列相同的行为机制,无需再单独配置。
客户端机制
确认重连机制
Broker 在 OOM、容器母机故障等极端场景下会自愈重启,日常业务自行操作集群升配等场景也会触发 Broker 重启,为避免 Broker 重启期间客户端持续连接异常,需要确保连接能够自动恢复。常见的客户端例如 Java 和 .NET 提供了自动重连机制,但是其他客户端例如 Python(pika)、PHP(php-amqplib)和 Go(amqp091-go)需要在应用层代码捕获异常并恢复连接。请查阅具体的客户端文档确定如何实现连接自动恢复。
不要关闭 heartbeat 设置
heartbeat 在服务端和客户端分别有一个配置值(服务端为 60 秒),最终生效的 heartbeat 由服务端和客户端协商决定,且不同语言/版本的客户端协商机制不同。heartbeat 为0代表关闭心跳检测,会导致服务端无法自动剔除长期无数据交互的无用连接,最终可能引起非预期的连接泄露。
网络分区
网络分区是在使用 RabbitMQ 时不得不面对的一个问题。网络分区会带来集群状态的不一致,即使是网络恢复后,RabbitMQ 仍需通过重启 Broker 的方式来重新同步状态。腾讯云 RabbitMQ 目前使用的 autoseal 模式,它会自动决出一个获胜的分区,然后重启非信任分区内的 Broker。
建议客户端做好以下措施,尽可能减小网络分区带来的负面影响:
消息发送方,考虑发送消息时配合使用 mandatory 机制并有处理 basic.return 的能力,以便及时处理网络分区时可能出现的消息路由失败。
消息消费方,网络分区出现/处理过程中,可能会伴有消息重复,消费端需要做好幂等处理。



