腾讯云目前提供的通用领域语音识别服务,能够在大部分场景下实现较好的识别效果。对于专业名词、特殊表达较多的应用场景,我们提供了自学习定制模型帮助用户自助提升专有领域的识别效果。
如果用户在专有领域或行业积累了丰富的文本数据,可以用自学习定制模型进行定向优化,从而有效提高语音识别准确率。
功能介绍
用户可以通过 API直接调用 和 控制台配置 两个方式来使用腾讯云语音识别的自学习定制模型。用户可以在创建自学习定制模型后,通过在对应的自学习定制模型内配置语料、指定关联语音识别基础模型,来实现语言模型的自训练,从而极大提升垂类场景下的语音识别准确率。腾讯云的自学习定制模型对于专有名词、高频词汇、领域专有表达,有较好的优化效果。
支持范围
使用建议
训练数据为用户在专有领域和行业积累的文本数据,数据越接近真实使用场景,优化的效果越好。
如果客户所储备的语料中多为词汇、短语,建议通过添加 热词 的形式进行模型优化。
对于需要加强优化、强调优化的语句,建议单独使用一行。
对于在使用自学习模型后、依旧出现识别效果不佳的字词,可能是因为当前字词的同音词过多的缘故。可以尝试用该字词造不同表达的句子、且这些句子最好是当前垂类场景中真实会使用到的表达(一个字词或一个句子在训练文本中占一行),可参考 训练文本数据示例 添加。如果对识别效果仍不满意,可以适当增加不同表达的句子数量。
训练文本中的数字部分最好按照发音替换为对应的汉字,例如“689元”替换为“六百八十九元”。
使用限制
默认每个账号最多可创建30个自学习定制模型,但同时最多可同时上线10个(如调用非上线状态的自学习定制模型,则会导致调用无效)。每个自学习定制模型最大支持2MB,最多支持50万行,每行最多1000个字符。
自学习定制模型的文件必须为 UTF-8 或 GBK 编码格式,每行添加一个词或一句话,详见 训练文本数据示例。
确认模型已上线后,直接通过 语音识别 API 或 SDK 调用该模型对应的引擎模型类型即可体验经自学习模型优化后的识别效果,无需额外设置。
对于每一次识别请求,同时只能有一个自学习定制模型ID起作用。
自学习定制模型生效流程
2. 自学习定制模型完成自训练,处于预上线状态,客户可自行选择需要上线的自学习定制模型(每个账号下最多可同时上线10个)。
3. 产品后端服务将自学习定制模型配送至识别层(由后端服务完成,客户无感知)。
4. 客户发起语音识别请求,并传入自学习定制模型 ID,且需要是已上线的自学习定制模型 ID。
5. 识别层根据请求传入的自学习定制模型 ID 生效对应的模型(由后端服务完成,客户无感知)。
自学习定制模型使用方法一:通过API创建并使用
您可以通过调用下述接口,对自学习定制模型进行创建、删除、更新、设置等操作,无需依赖控制台的操作:
查询自学习模型列表:用户通过本接口查询自学习定制模型的列表。
更新自学习模型:用户通过本接口可以更新自学习模型,如模型名称、模型类型、模型语料。
删除自学习模型:用户通过本接口可以删除自学习模型。
修改自学习模型状态:用户通过本接口可以修改自学习模型状态,上下线自学习模型。
下载自学习模型语料:用户通过本接口可以下载自学习模型的语料。
对于每个语音识别请求,同时只能有一个自学习定制模型起作用,但不同的请求可以使不同的自学习定制模型生效。针对不同语音识别子产品的请求说明如下:
语音识别子产品 | 接口文档连接 | 接口对应自学习定制模型参数名 | 如何定义请求 |
录音文件识别 | CustomizationId | 每个 HTTP 请求 | |
实时语音识别 | customization_id | 每个音频流 | |
录音文件识别极速版 | customization_id | 每个 HTTP 请求 | |
一句话识别 | CustomizationId | 每个 HTTP 请求 | |
语音流异步识别 | 暂不支持 | 每个音频流 |
自学习定制模型使用方法二:通过控制台配置
1. 新建自学习模型
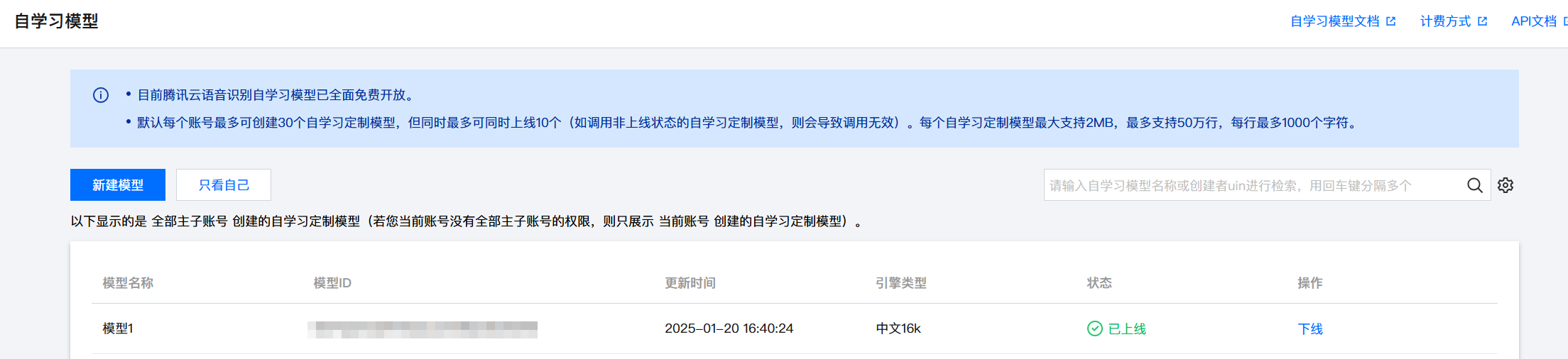
(2) 在新建模型页面中,填写模型名称、引擎类型、训练数据和标签,填写完成后,单击确定即可创建一个自学习模型。其中,训练数据为用户在专有领域和行业积累的文本数据,数据越接近真实使用场景,识别准确率越高。请正确选择您需要应用该自学习模型的引擎类型,上传训练数据文件并提交。
训练文件格式要求 | 训练文本数据示例 |
训练文件的文件格式要求 UTF-8 或 GBK 编码的 txt 文件,文件最大不超过2MB。 文件中不能有空行,且每行的字节数最多为1000,总行数最多为50万行。 其中的数字推荐按照发音替换为对应汉字,例如“689元”替换为“六百八十九元”。 |  |
2. 自学习模型列表
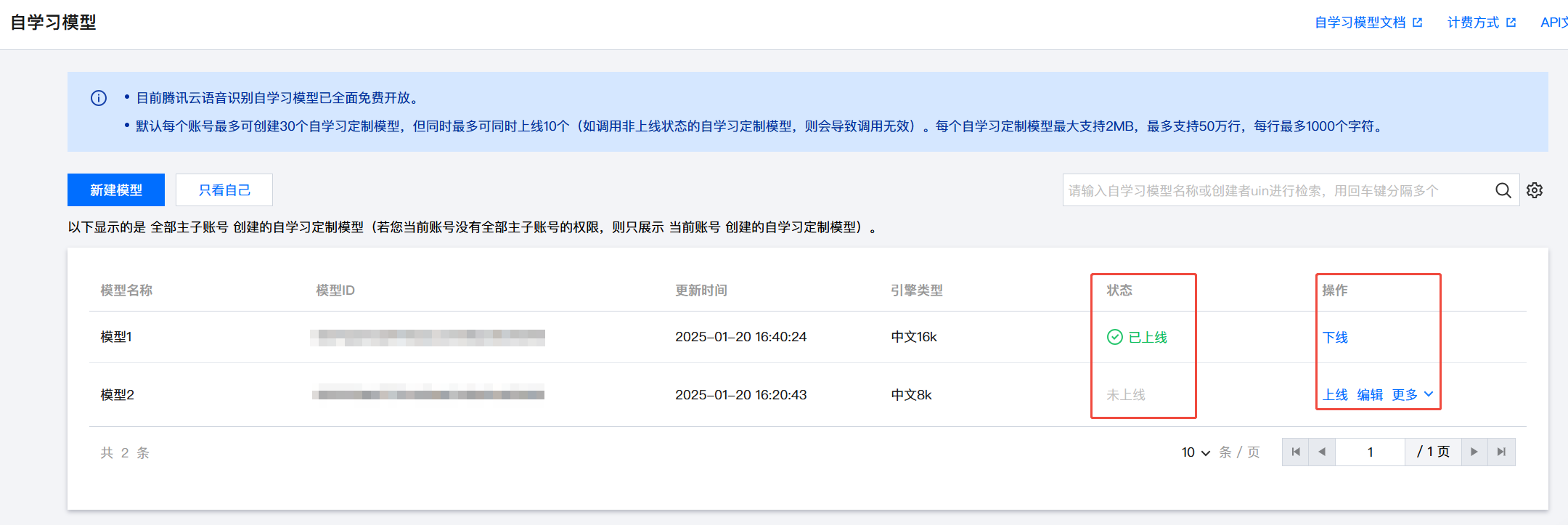
3. 上线自学习模型
注意
同一个账号最多允许同时上线10个自学习模型。
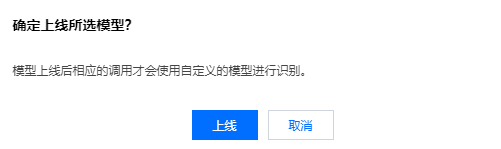
刚创建的自学习模型的状态为“未上线”,需要选择操作 > 上线,在弹出页面单击上线,即可上线自学习模型。模型上线后,直接通过语音识别 API 或 SDK 调用该模型对应的引擎模型类型即可使用自学习模型测试识别效果,无需再单独设置。
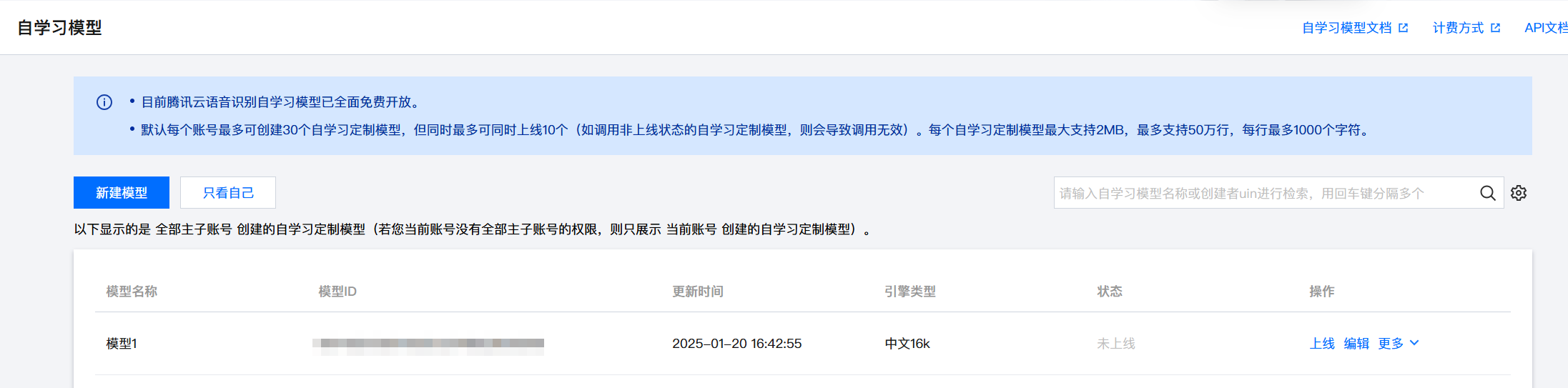
4. 下线自学习模型
对于“已上线”自学习模型,可选择操作 > 下线,在弹出页面单击下线,即可下线自学习模型。模型下线后相应的接口调用将使用默认通用模型进行识别。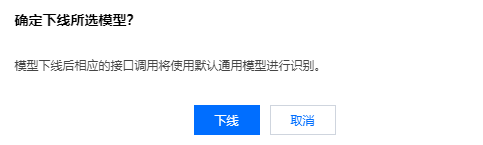
5. 编辑自学习模型
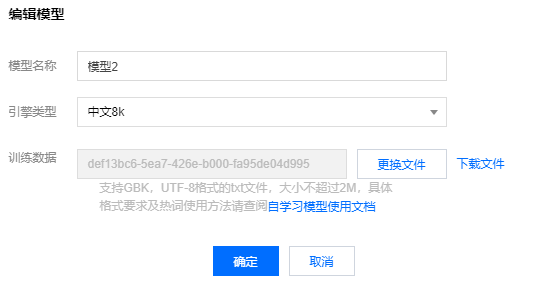
对于未上线的自学习模型,可以选择操作 > 编辑,在弹出页面中填写需要编辑的模型名称、引擎类型、训练数据,填写完成后,单击确定,即可完成自学习模型的编辑。
6. 删除自学习模型
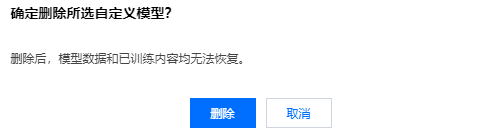
对于未上线的自学习模型,可以选择操作 > 删除,在弹出页面中单击删除,即可删除自学习模型。删除后,模型数据和已训练内容均无法恢复。
7. 编辑自学习模型标签
对于未上线的自学习模型,可以选择操作 > 编辑标签,在弹出页面中设置标签键和标签值,也可增加多个标签键和标签值,设置完成后,单击确定即可。
训练文本数据示例




