功能概述
Studio Notebook 提供了 dlcutils 函数库、魔法命令等内置开发工具,帮助开发者实现 Notebook 参数化运行、对接 SSM 密钥管控、多语法切换等高阶用法。本篇文档举例说明几种内置开发工具的实践教程。
注意:
以上 WeData Notebook 的内置开发工具,仅适用于连接 DLC 引擎机器学习资源组-Spark MLlib 类型进行使用。
DLC Utilities(dlcutils)
dlcutils 是 WeData 基于 DLC 引擎提供的一个实用工具库,主要用于简化在 Notebook 环境中的各种操作,可以帮助用户执行与数据处理、参数传递、环境配置等相关的任务。详情请参见 dlcutils 工具库及魔法命令使用指南。
Magic 语法(魔法命令)
Magic 语法是 Jupyter Notebook 中的一种特性,允许用户通过特定的命令来执行一些特殊的操作,通常以 % 或 %% 开头。Magic 命令可以用于简化常见任务,提高工作效率。详情请参见 dlcutils 工具库及魔法命令使用指南。
实践教程
Notebook 动态参数替换
使用场景说明
使用场景 | 场景举例 | 使用方式 |
单一参数的动态调整 | 需要重复执行相同的代码,但代码的输入条件不同。例如,每天需要查询前一天的数据,因此数据的时间参数会有所变化。 | 将时间参数定义为动态变量,通过调整时间参数进行测试,而不需要修改代码的其他部分,避免重复编写相似的代码 |
开发和生产隔离 | 在开发环境和生产环境,需要设置同一个参数的不同取值 | 定义项目参数,并且分别设置调试运行取值、周期调度取值,或者开发环境取值、生产环境取值,则在任务调试和调度运行时,会分别从对应场景中取不同的值 |
操作说明
在 Notebook 文件中使用动态参数
在 Studio Notebook 文件调试运行时,支持使用项目或者文件上配置的参数。如果两个地方定义了同一个参数的不同取值,则优先级:文件 > 项目。
1. 参数定义:
目前在 Notebook 文件中定义高级参数,支持代码定义和可视化界面定义两种方法:
代码定义:在代码中使用 dlcutils.widgets.text(name='your_name', defaultValue='your_value', label='your_name')函数,分别定义参数名、参数值、标签;
界面定义:单击参数 > 添加,手动设置参数名、参数值、标签。
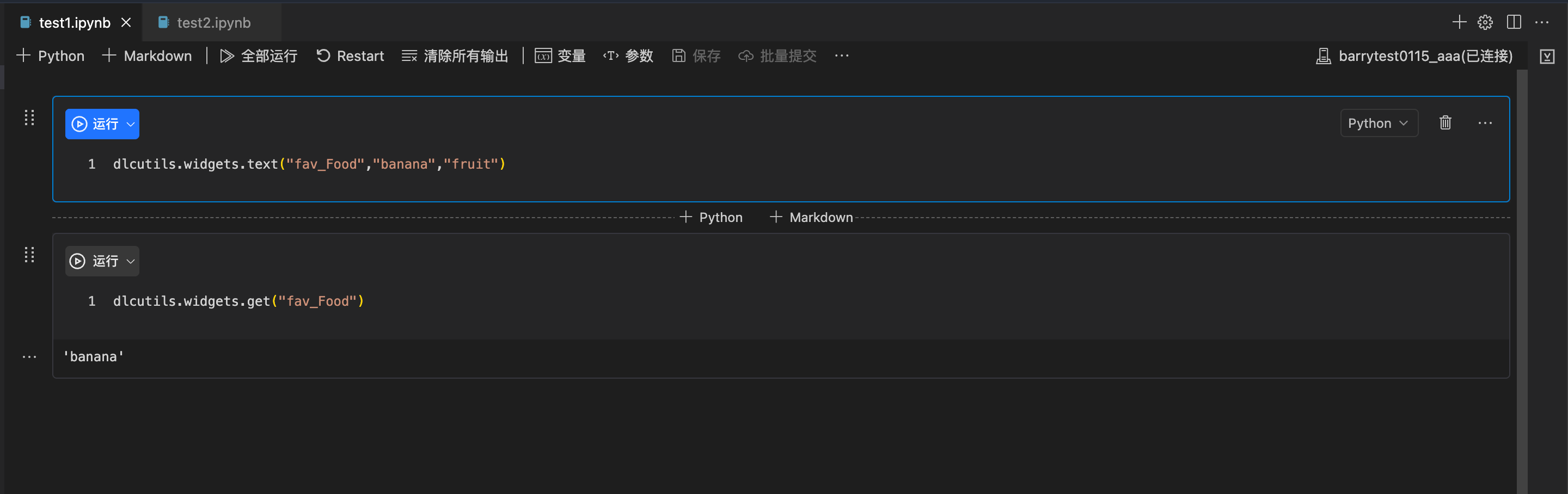
2. 参数值修改:在“参数”界面中修改参数的取值。
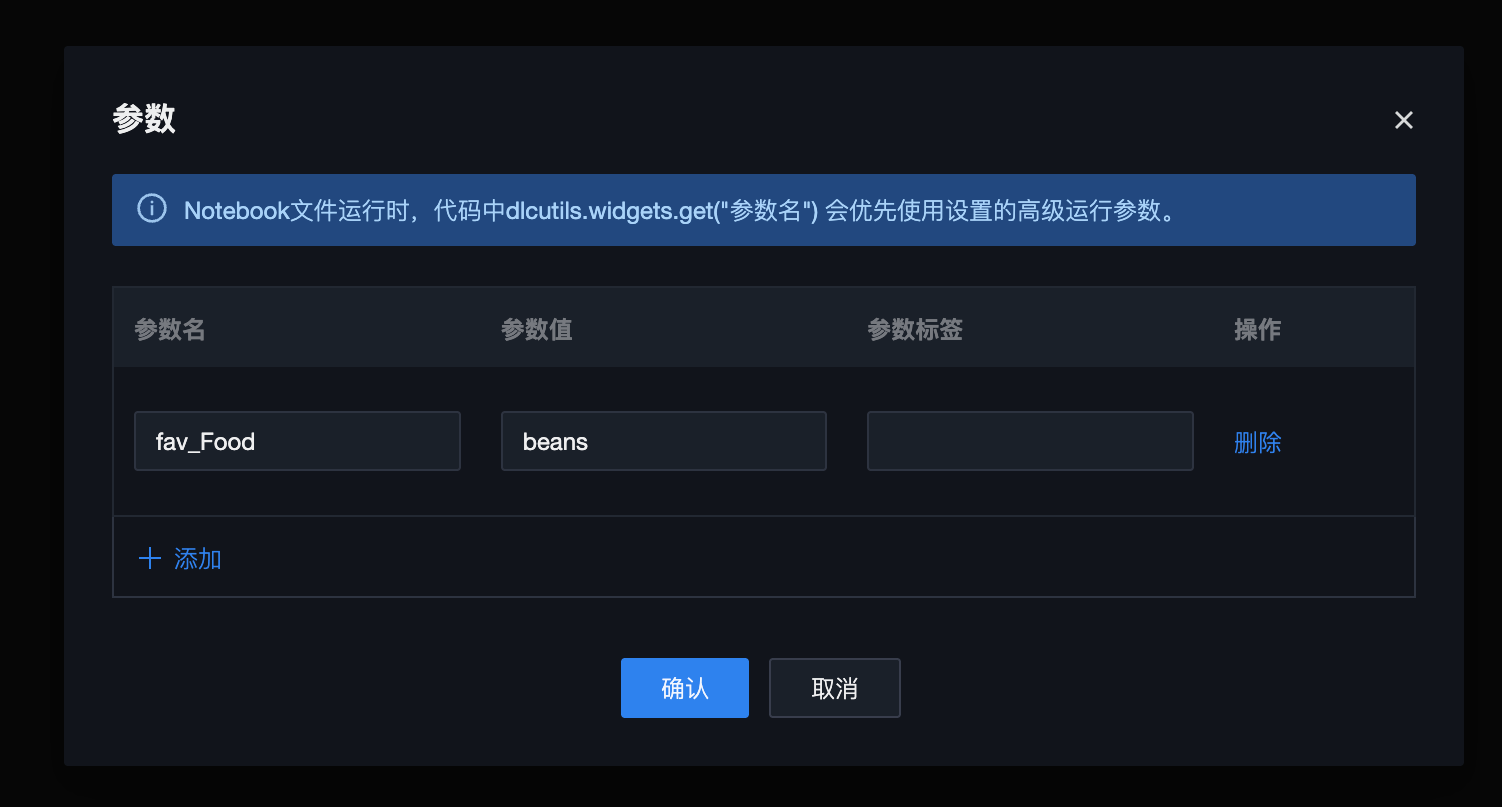
3. 参数值获取:在代码中使用 dlcutils.widgets.get(“your_name”)函数获取参数值。
dlcutils.widgets.get("fav_Food")# output beans
在 Notebook 文件中使用项目参数
1. 参数定义:
进入项目管理 > 参数设置界面,单击新增,完成项目参数的新建。
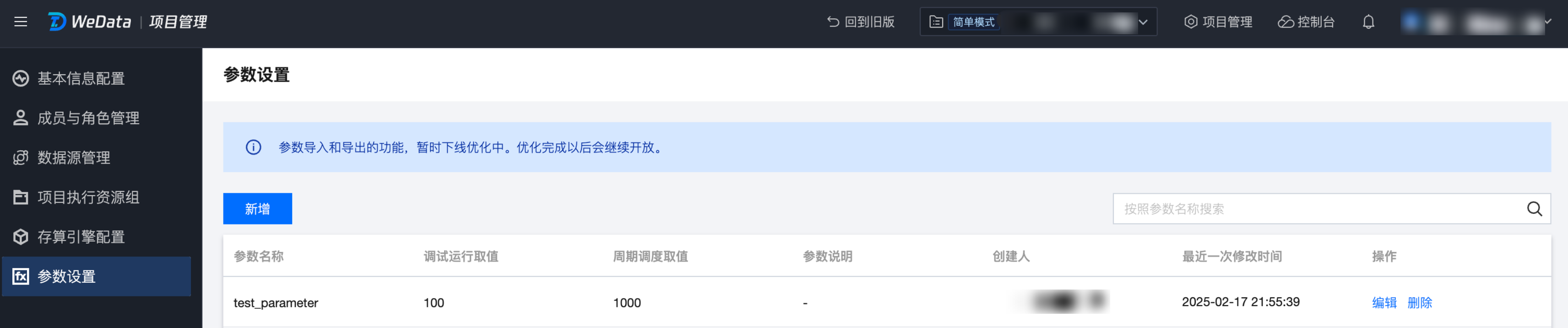
2. 参数值获取:
如果在项目管理的参数中已经定义了参数,例如参数名称 test_parameter,取值是100,在 notebook 中可以直接使用项目参数。
# print project parametersdlcutils.widgets.get("test_parameter")# output 100
在 Notebook 任务中使用项目、工作流或者任务参数
1. 参数配置。
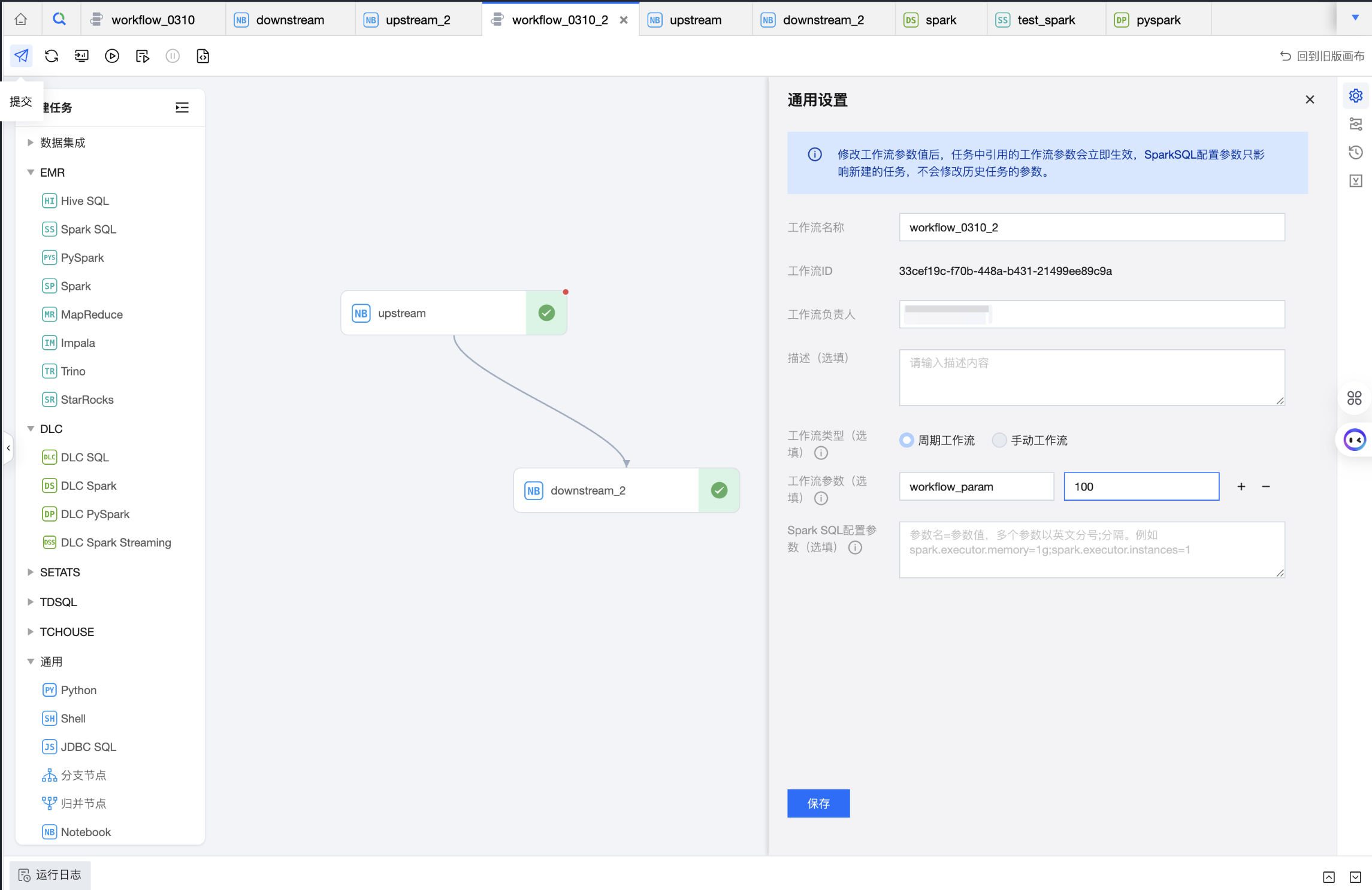
工作流参数可在工作流通用配置中进行配置。
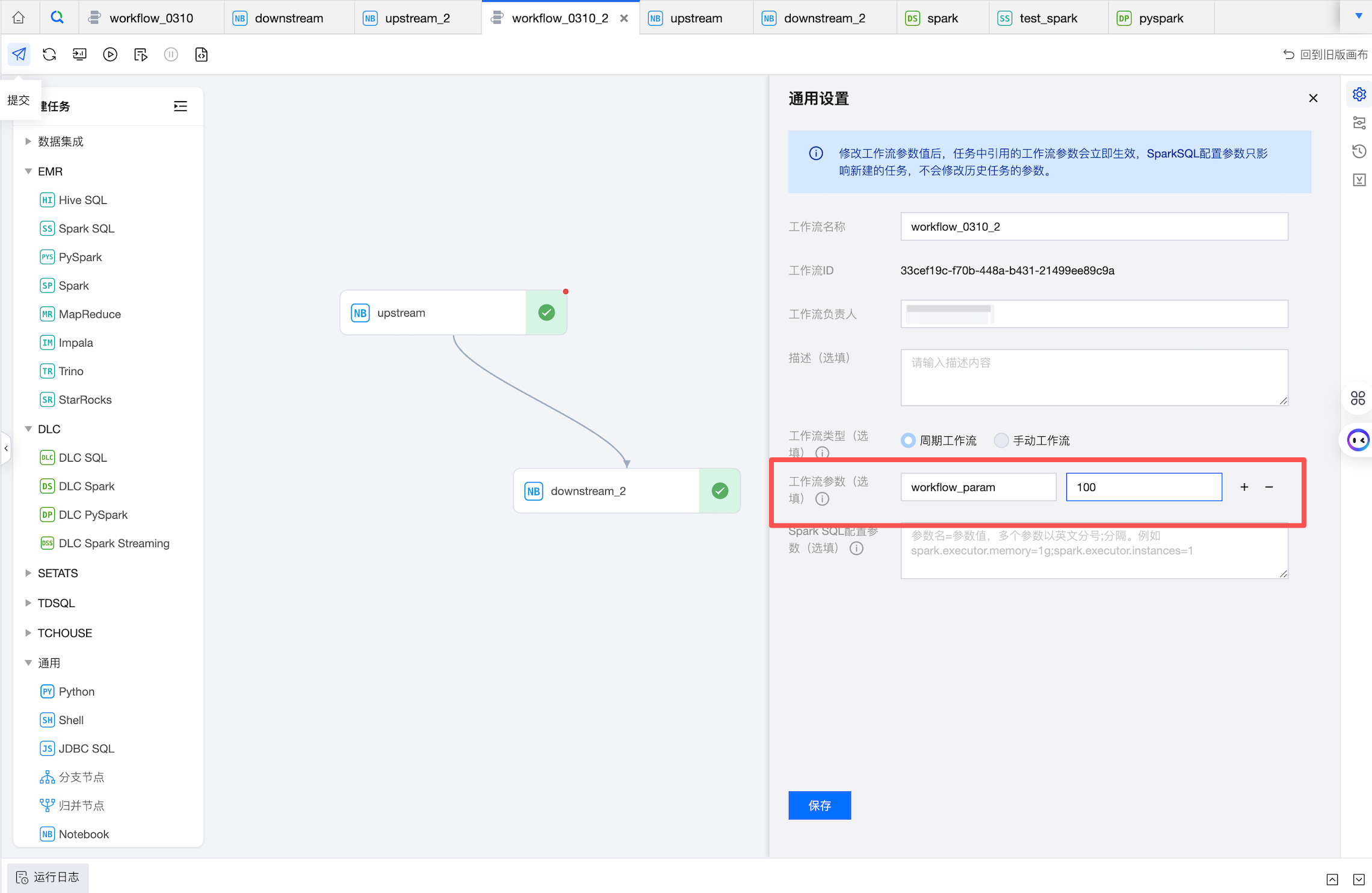
任务参数可在任务的任务属性中进行配置。
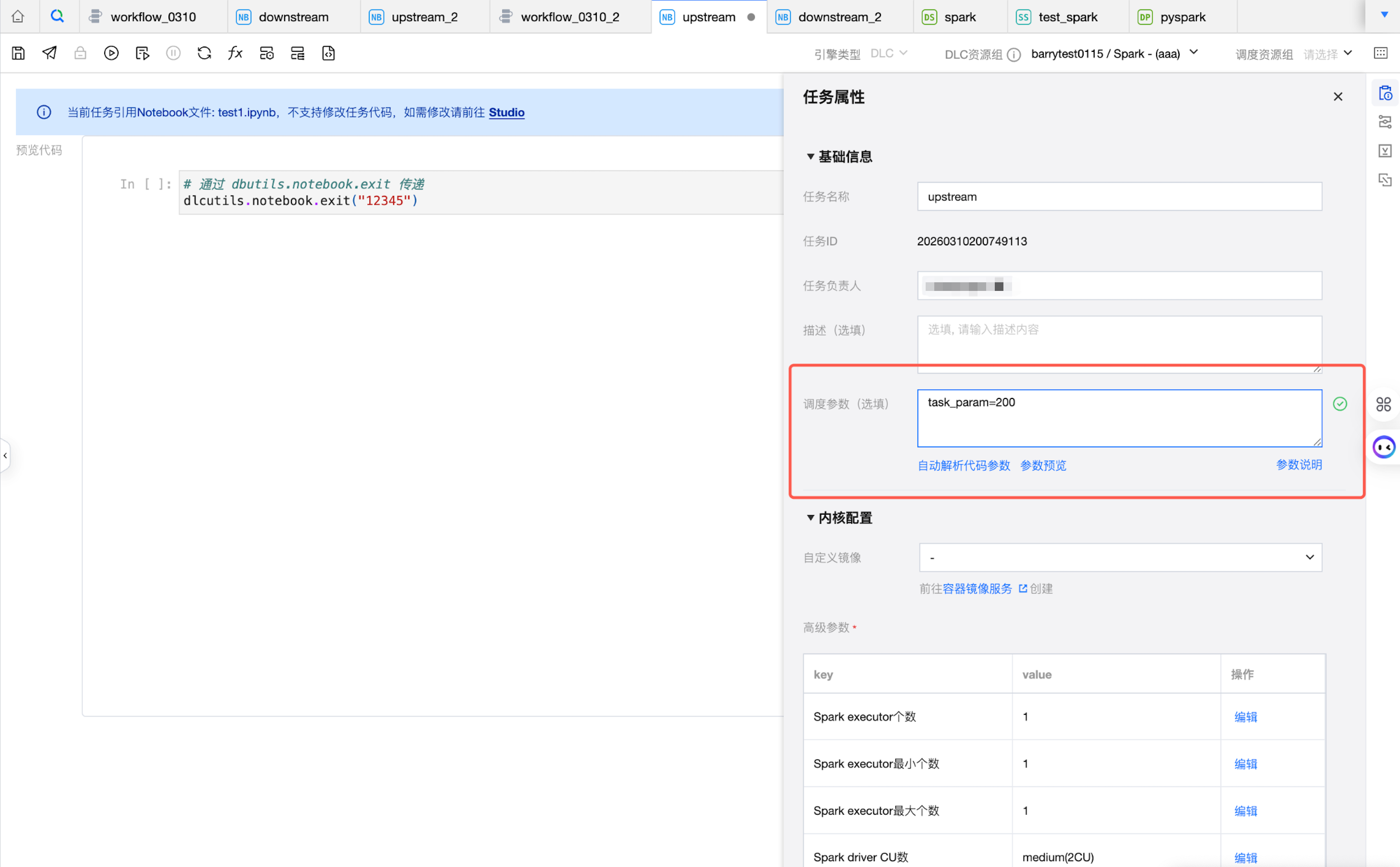
2. 参数值获取。
在编排空间 Notebook 任务中调试运行或者周期运行时,可以使用dlcutils.widgets.get() 函数获取项目、工作流或者任务上配置的参数。
如果三个地方定义了同一个参数的不同取值,则优先级:任务 > 工作流 > 项目。
# get task_test_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a task.try:task_test_param_value = dlcutils.widgets.get("task_param")if not task_test_param_value: # 如果获取到的值是空字符串task_test_param_value = 'task_default_value'except Exception: # 如果完全获取不到参数task_test_param_value = 'task_default_value'print(f"Using toy value: {task_test_param_value}")
# get workflow_test_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a workflow.try:workflow_test_param_value = dlcutils.params.get("workflow_param")if not workflow_test_param_value: # 如果获取到的值是空字符串workflow_test_param_value = 'workflow_default_value'except Exception: # 如果完全获取不到参数workflow_test_param_value = 'workflow_default_value'print(f"Using toy value: {workflow_test_param_value}")
Notebook 任务间参数传递
使用场景说明
使用场景 | 场景举例 | 使用方式 |
工作流的自动化 | 数据处理工作流:在 ETL(提取、转换、加载)过程中,第一个 Notebook 提取并转换数据,第二个 Notebook 进行加载或进一步分析。 机器学习工作流:第一个 Notebook 训练模型并保存结果,第二个 Notebook 使用该模型进行预测或评估。 | 第一个 Notebook 的输出参数直接作为第二个 Notebook 的输入,实现任务之间的自动化连接。 |
分支逻辑的完成 | 条件处理:在数据处理或分析过程中,根据不同的输入条件执行不同的逻辑。 动态决策:在机器学习或数据科学项目中,根据模型预测或数据特征的不同,选择不同的处理路径。 | 第二个 Notebook 文件通过判断第一个 Notebook 的输出结果,选择性地运行不同的代码逻辑。 |
操作说明
1. 在 Studio 中,创建两个 notebook 文件:notebook_upstream.ipynb 和 notebook_downstream.ipynb,文件内容如下:
notebook_upstream.ipynb
# Exit the notebook and output parametersdlcutils.notebook.exit('12345')
notebook_downstream.ipynb
# get task_input_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a task.try:task_input_param = dlcutils.widgets.get("parameter")if not task_input_param: # 如果获取到的值是空字符串task_input_param = 'task_input_default_value'except Exception: # 如果完全获取不到参数task_input_param = 'task_input_default_value'print(f"Using toy value: {task_input_param}")
2. 同时,在编排空间创建两个任务 upstream、downstream,分别选中上面两个 notebook 文件。
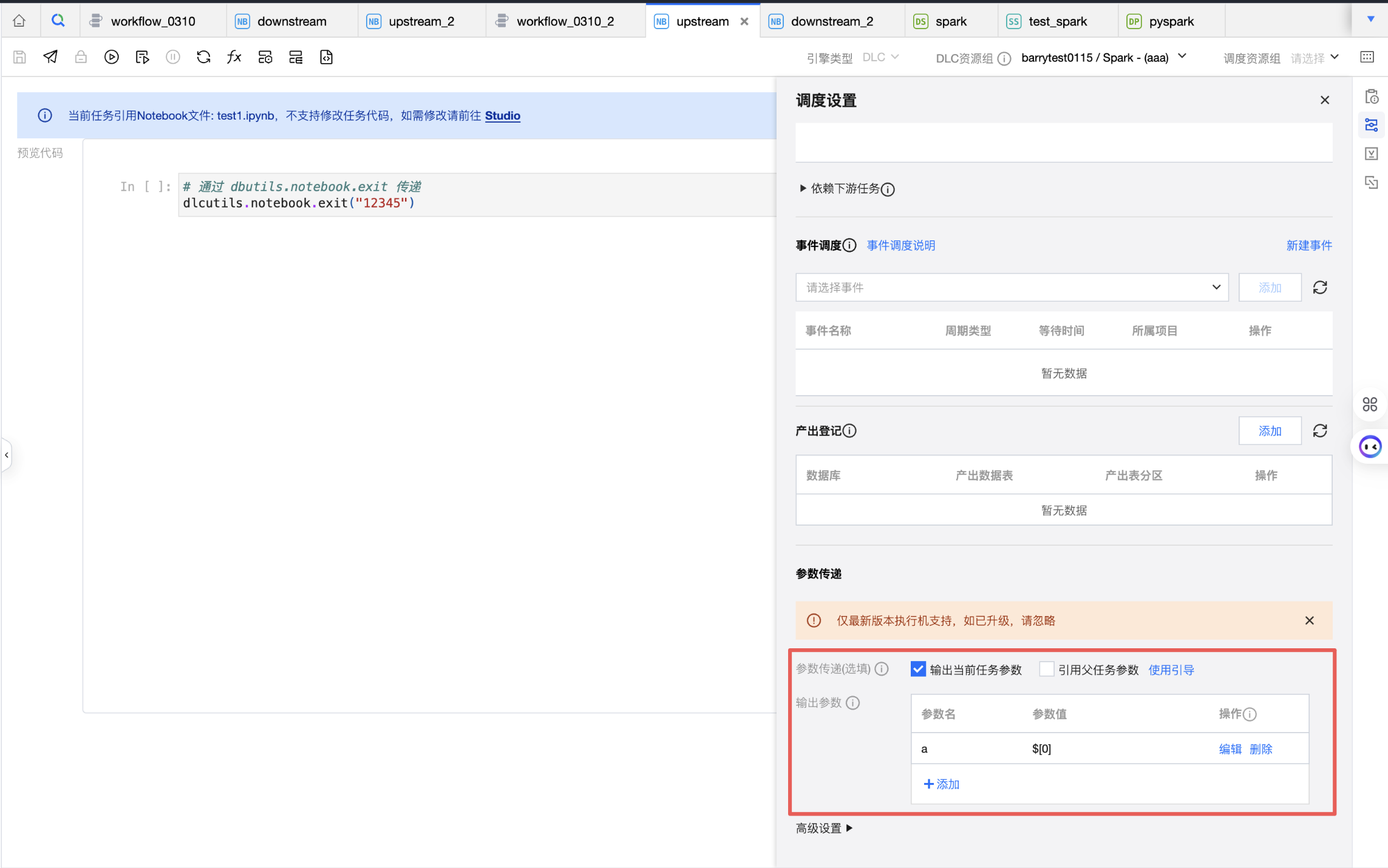
3. 在任务 upstream 的调度设置中,设置输出当前任务参数 a 为 $[0]。
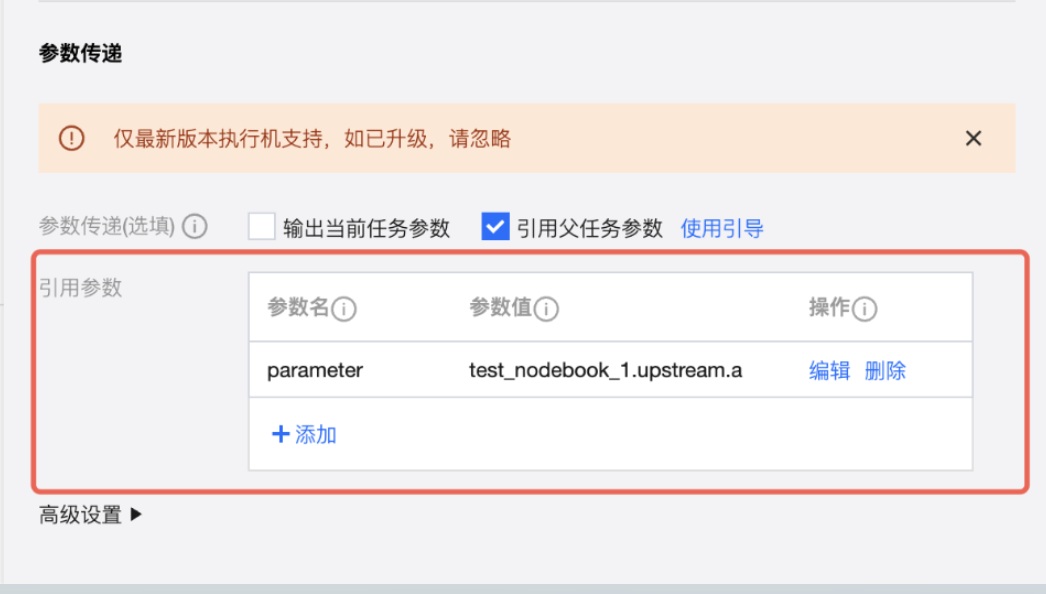
4. 在任务 downstream 的调度设置中,设置参数 parameter 为引用父任务参数 a。
5. 最后,在工作流调试运行或者调度运行中,即可查看 downstream 的输出为 12345。
Notebook 对接 SSM 密钥管控
使用场景说明
出于安全性考虑,通常不希望将密钥等信息通过明文写到代码中,因此将其存在腾讯云 SSM 中,通过 Notebook 对接 SSM 进行密钥获取,场景举例:
调用 SDK 时需要传入的 ak、sk 信息。
访问数据库时的用户名、密码信息。
操作说明
1. 登录 腾讯云 SSM, 在自定义凭据中定义凭据名称、版本和内容。
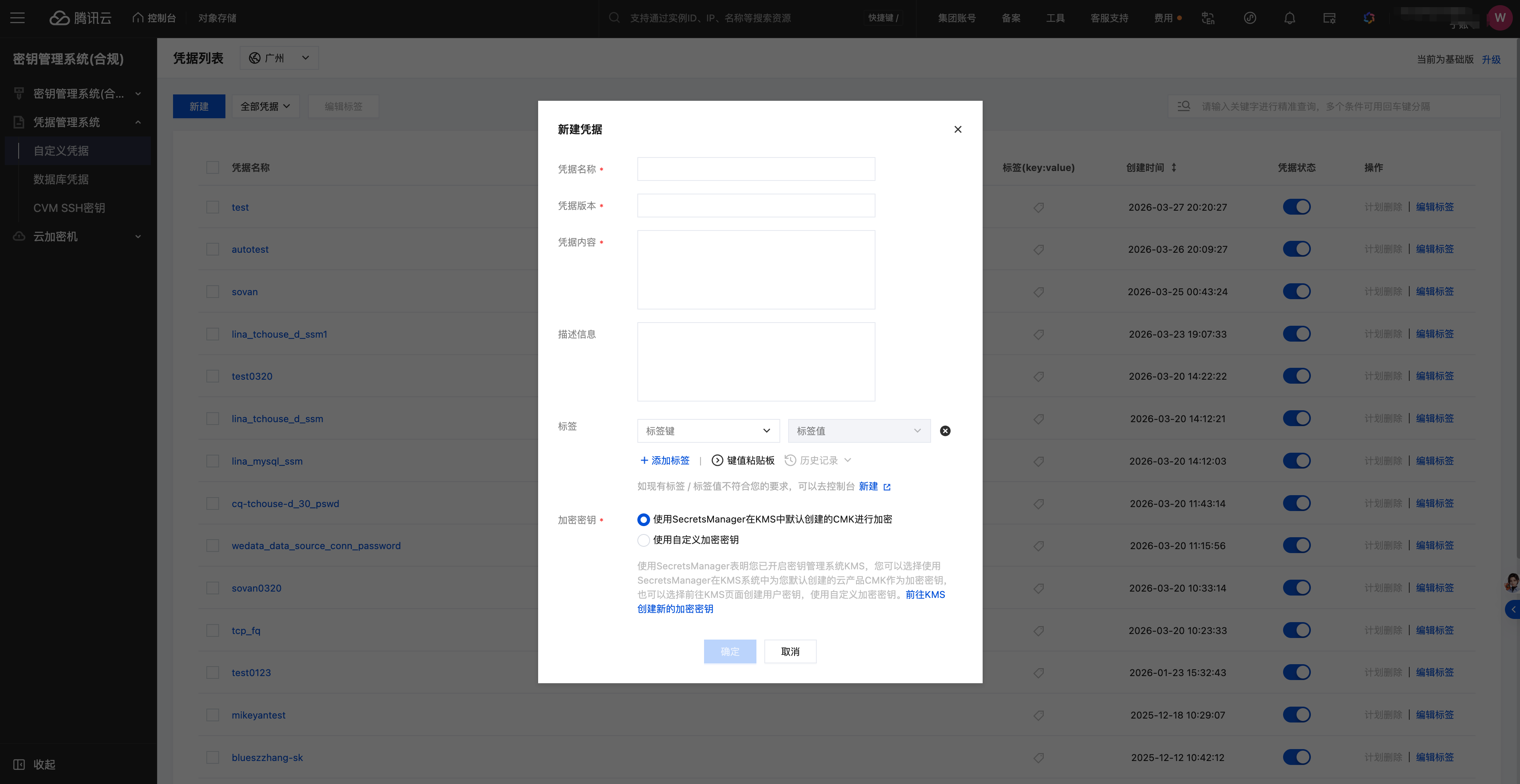
2. 在 Notebook 中调用 dlcutils.secrets.get(secretName, secretVersion, region)函数,获取密钥取值;
dlcutils.secrets.get("secret_name", "v1", "ap-guangzhou")# output secret_value
3. 使用密钥值进行后续操作,例如 SDK 调用、数据库访问等。



