WeData 数据治理理念
WeData 数据治理旨在为企业沉淀可信数据及其语义资产,帮助企业构建AI Ready 的数据,提升企业基于全域数据资产构建智能应用的效率。
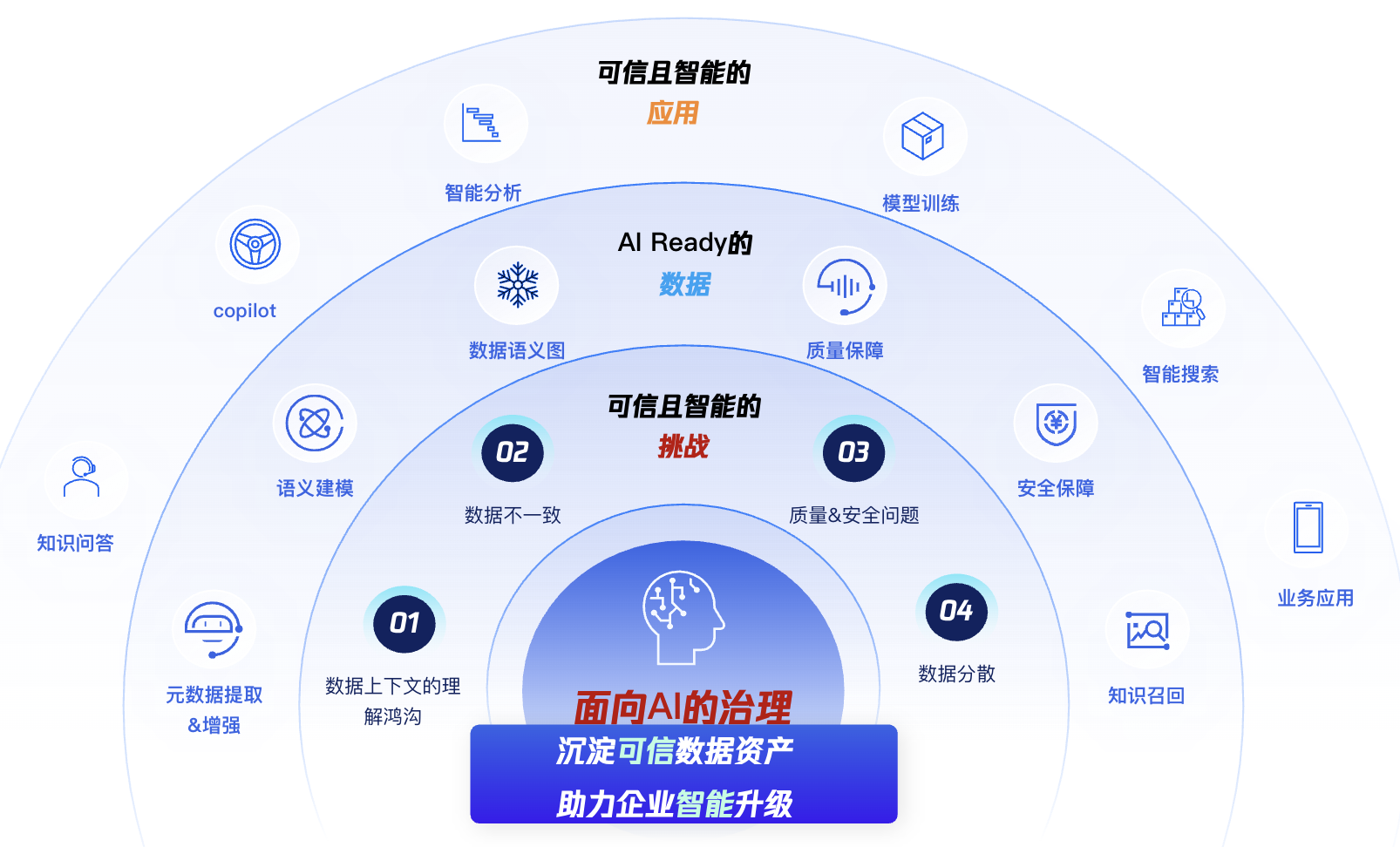
数据之所以称之为资产,有三个必需属性:价值、知识、信息。
WeData 数据治理能力建设,秉持帮助企业将信息变为有价值的知识的理念,在大规模海量数据的场景下:
企业内的数据信息全景需要通过元数据采集、增强来进行汇总呈现
数据的信息需要通过语义建模+治理的方法转换为人与机器都能理解的语义知识
数据资产要产生价值,必须要有丰富的应用连接能力,能够方便地下游应用、智能体访问调用
WeData 数据治理最终交付的数据资产的服务形式是数据统一语义层(WeData Unity Semantics),统一语义层为下游提供一致、可信、高效的数据访问接口,例如:MCP、API、JDBC、数据发现服务等。

产品简介
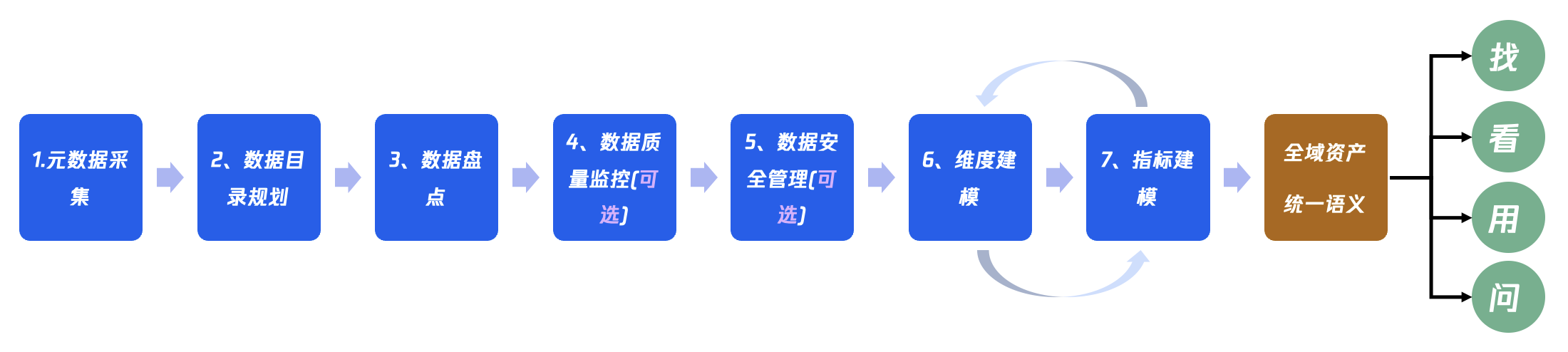
数据治理是一个广泛的概念,同时也是复杂工程,在 WeData 平台实施数据治理,主路径包含7步,如下图所示:
核心能力
模块 | 能力描述 |
元数据中心 | 元数据采集是构建企业全域数据资产的第一步,WeData 支持自动采集腾讯云 DLC、EMR、TCHouse 等系统引擎元数据,同时支持用户自定义数据源(如 MySQL、Oracle、Doris 等18种)元数据采集。并支持用户对采集任务进行运维管理,例如停止、重采、更改采集频率等。 |
资产目录配置 | 提供数据目录规划,例如业务域、主题域规划、数仓分层规划等,支持数据标准定义,例如取值标准、命名标准等。 |
治理中心 | 提供治理大盘概况查看、个人治理工作台功能,提供数据盘点、业务元数据补齐、数据打标等功能。 |
数据质量 | 提供数据质量概况查看,质量校验规则管理,针对数据表配置质量校验规则,实现质量告警、下游阻断等能力。 |
数据安全 | 提供数据权限管理,数据分类分级扫描、数据脱敏规则设置等能力。 |
指标建模 | 基于 headless BI 的理念构建数据分析指标语义层,提供维度建模、指标定义、指标应用生态对接能力(包含 REST API、JDBC、MCP 接口等),同时支持指标分析能力,提供 SemQL(Semantic Query Language) 实现基于类 SQL 语言进行指标分析。 |
数据资产 | 提供全域数据资产检索能力,具备关键词、语义、智能问答检索能力;提供数据目录管理能力,将进行资产盘点上架的资产,展示在数据目录,提升企业高质量资产管理能力。 |
快速上手
元数据采集
元数据采集有两种场景:
1. 用户在项目空间绑定 DLC、EMR、TCHouse 等腾讯云大数据引擎实例时,平台会自动创建元数据采集任务,用户无需配置。
2. 用户可以在元数据中心新建采集任务,采集第三方数据源的元数据。
注意:
配置元数据采集的数据源一定要是实际用于数据开发、数据集成的数据源,否则采集上来的元数据无法实现数据血缘串联。
数据目录规划
进入数据治理>配置中心>资产目录配置,进行资产目录规划和配置,一般建议资产目录树不超过3层:两层业务,一层主题。
数据资产盘点
基于资产目录规划,可以在治理中心进行资产盘点:
可以批量更改数据表、指标等所属资产目录。
可以修改业务信息:修改表、字段描述、重要等级、数据标签等。
数据质量监控(可选)
进入数据监控页面,点击新增监控,主要配置有:选择监控表对象、设置监控任务触发时机、设置监控规则等。
数据安全管理(可选)
1. 分类、分级的模板。
2. 设置分类分级检测任务。
3. 查看分类分级结果。
指标建模(可选)
1. 进行维度建模。
2. 指标定义,支持原子指标、衍生指标定义。
数据资产
1. 在数据资产门户可以进行全域数据资产检索。
2. 在数据目录中,支持对上架的数据资产进行管理。
常见问题
WeData 是否支持跨平台数据治理?
是的,WeData 支持与多种数据平台的元数据集成,能够实现对除腾讯云大数据底座之外的数据库、数据引擎数据进行治理,例如进行元数据采集、数据资产盘点、元数据补齐、全域数据发现能力,也支持基于第三方 OLAP 引擎(如 StarRocks、Doris、ClickHouse 等)进行指标建模,提供统一指标语义层服务。
WeData 统一语义层 Unity Semantics 与指标建模是什么关系?
Unity Semantics 的目标是为人、AI agent 提供全域数据资产的分析语义,指标是数据分析最重要的语义之一,所以其核心能力包含指标建模,此外 Unity Semantics 还包括统一元数据、业务元数据打标、非结构化数据的元数据提取等能力。
如何衡量数据治理的效果?
一般来讲,企业数据治理的衡量效果分为主观性指标和客观性指标。 主观性指标主要包含数据 NPS 调研。 客观性指标主要取决于治理目标的设定。例如目标如果是沉淀可信数据资产,提升大家找数据、用数据的效率,目标可以关注数据资产门户易用性相关指标,例如:使用人数(使用用户渗透率等)、资产搜索CTR、资产价值密度、表重复率等,如果目标是提升自助BI分析效率,目标可以定报表、自助取数效率类指标,例如:自助配置报表用户比、自助取数占比、人均配置报表耗时、数据问题反馈占比等。
需要说明的是,数据治理是一个广泛的概念,需要根据企业自身情况确定合理的目标和量化方式,
维度建模、指标建模如何实施,存量指标如何治理?
维度、指标建模的核心理念是基于 Headless BI 的理念为下游数据分析应用提供一致的、可信的指标语义和数据服务。 核心实施策略是收新增、治存量。整体在实施过程中首先应该由数据工程或者数据分析角色梳理指标体系,然后再用指标平台进行固化。
存量治理,指标体系的梳理是避免不了的,可以参考如下模板:
业务目录 | 指标 | 分析维度 | 是否可衍生 | 聚合逻辑 | 依赖的数仓表 | 表过滤条件 |
例:商品/交易 | 用户数 | 地域、年龄段、性别 | 否 | count(distinct userid) | 事实表:dws_user_action_tbl 维度表: user_info_dim | 过滤status!=0的非法用户数 |
例:商品/交易/会员 | 会员数 | 地域、年龄段、性别 | 是 | 上游指标:用户数 衍生逻辑:是否会员="是" | 无 | 无 |
例:商品/交易/会员 | 高活会员数 | 地域、性别 | 是 | 上游指标:会员数、周活跃天数 衍生逻辑:周活跃天数>3的会员数 | 无 | 无 |
基于以上表格的梳理,数据工程师才能抽象形成对全局数据模型的框架,创建和优化需要的维度模型,并在维度模型上定义指标。
对存量指标、模型进行梳理后,后续针对指标新增的需求,可以直接在指标平台进行建模和指标创建。



