背景信息
前提条件
1. 已配置好来源及目标端的数据源以备后续任务使用。详情请参见 数据源管理与配置方式。
2. 已购买数据集成资源组。详情请参见 配置集成资源组。
3. 已完成数据集成资源组与数据源的网络连通。详情请参见 集成连通性与使用规划。
4. 已完成数据源环境准备。您可以基于您需要进行的同步配置,在同步任务执行前,授予数据源配置的账号在数据库进行相应操作的权限。
操作步骤
步骤一:创建整库迁移任务
进入配置中心 > 实时同步任务页面后,单击新建整库迁移任务。

步骤二:链路选择
您可以根据实际业务选择需要同步的来源与去向数据类型。选择后,后续步骤将基于此步选择的类型展示对应来源及目标端配置参数。请保证所选择数据源类型与实际配置数据源类型保持一致。
说明:
快速选择中只展示了常用链路和主要目标端的所有链路,并非整库迁移支持的所有链路。不在快速选择中的链路可通过下拉选择链路类型后面的来源端和目标端数据源类型进行配置。
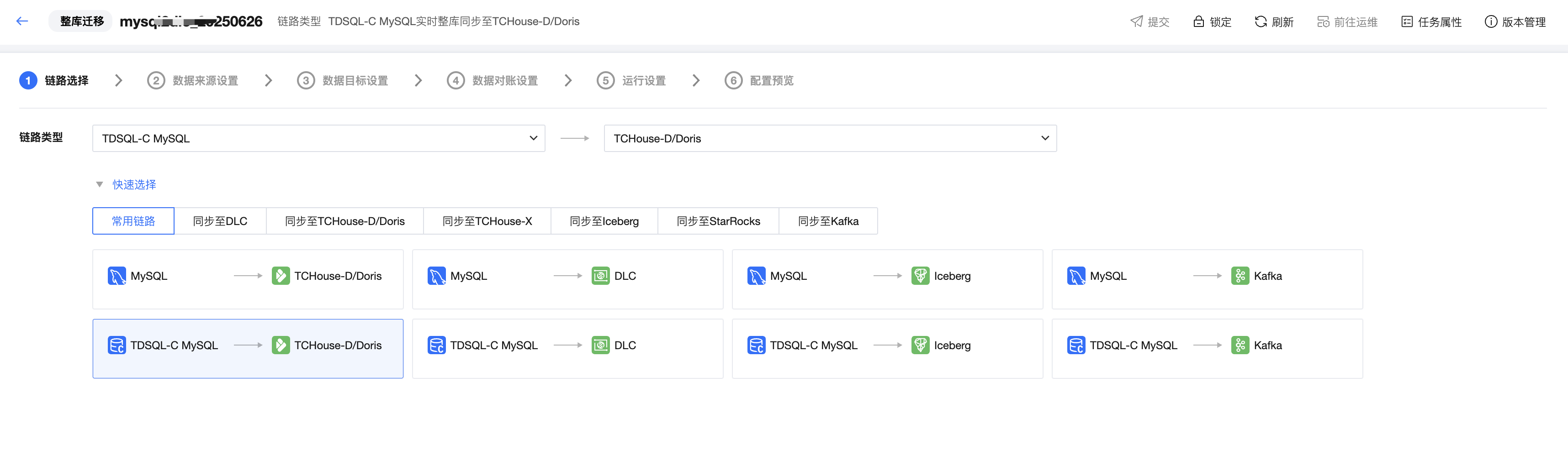
步骤三:数据来源设置
在此步骤中,您可以选择源端数据源中需要同步的库和表,配置来源端读取方式、一致性语义、过滤操作、时区等。
说明:
此处的配置项根据来源端数据源类型的不同而存在一定的差异,具体以数据源实际配置界面为准。
一致性语义建议选择 At-least-once。
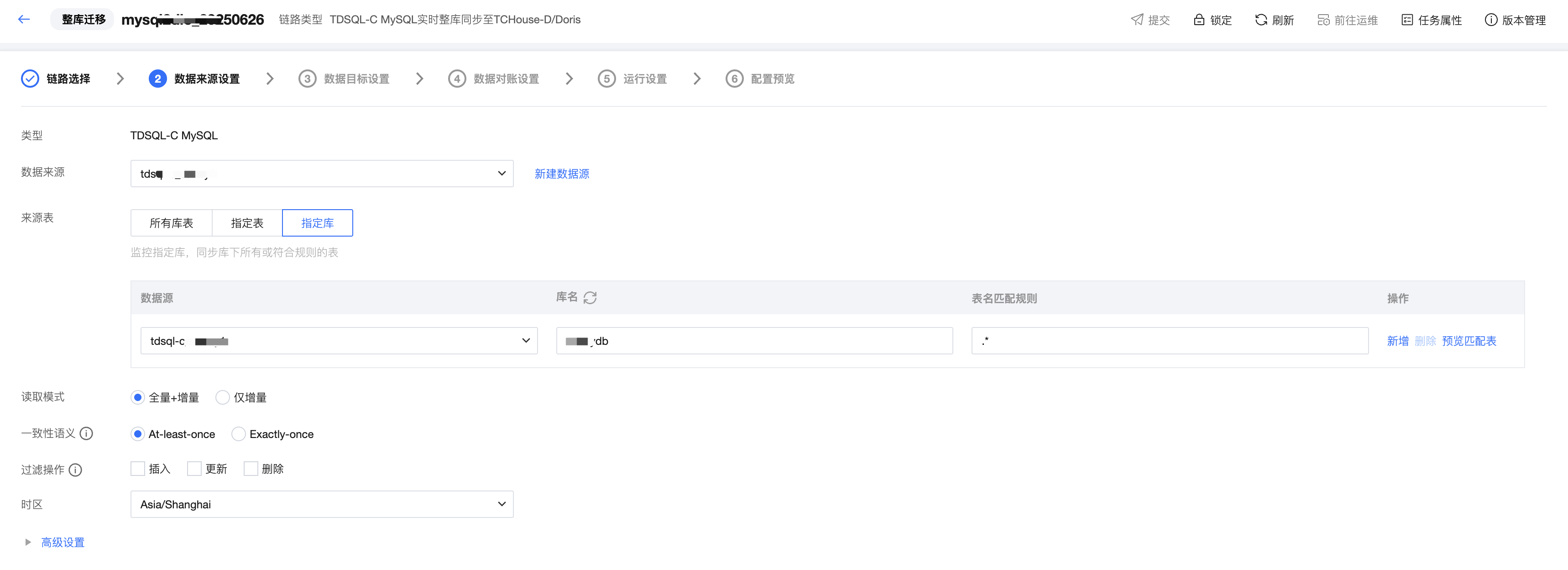
步骤四:数据目标设置
1. 基本配置
在此步骤中,您可以定义写入目标端数据源及库表等相关属性。例如,写入模式,库、表名称匹配规则等,以及设定目标对象与来源对象之间的名称映射规则。
说明:
此处的配置项根据目标端数据源类型的不同而存在一定的差异,具体以目标端数据源实际配置界面为准。
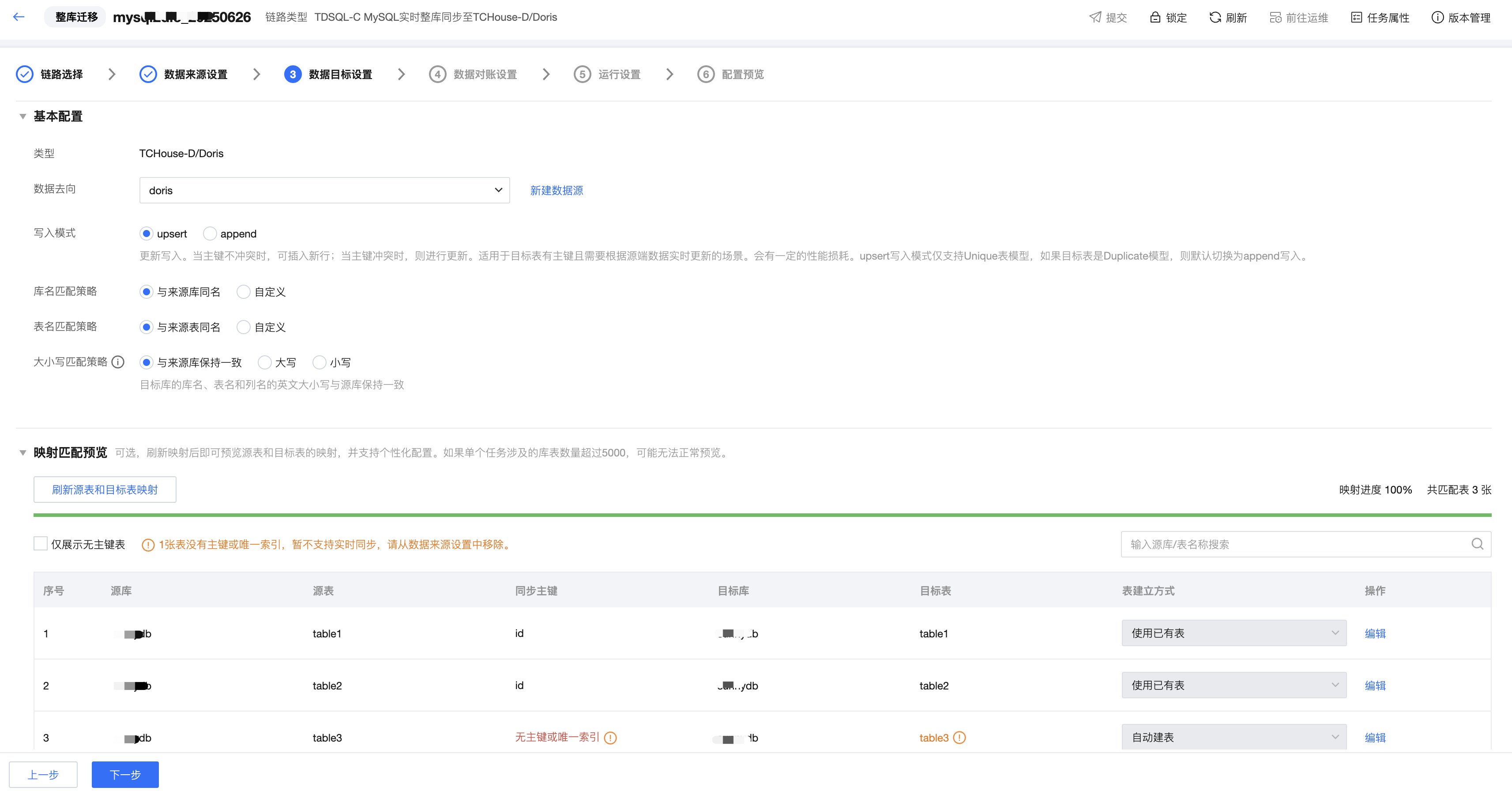
目前整库目标对象匹配策略支持“与来源同名”、以及“自定义”两类:
与来源库/来源表同名
默认情况下,整库同步任务中源端数据库、数据表将写入目标端同名库或同名表中。此策略下,任务运行时系统将默认在目标数据源内匹配与来源库/表同名对象。

说明:
任务计划同步将源端数据库 DB1 下的 TableA 和 TableB 同步至 Doris 数据源,配置与来源库同名以及与来源表同名策略以后,任务运行时候将默认在 Doris 连接内分别匹配 “DB1.TableA” 和 “DB1.TableB”。
自定义
自定义规则支持设置来源与目标之间特殊关系,例如统一将源端库名或表名加上统一固定前缀或者后缀在写入目标库或表任务运行时。此策略下,任务运行时系统将默认根据命名规则匹配目标对象。

自定义方式下,系统针对整库场景提供了内置系统参数。内置参数主要覆盖源端数据源名称、源端库名、源端表名等。其中 Kafka 类型,支持动态匹配消息内数据字段 value 值。自定义方式下内置参数说明如下:
参数名称 | 参数说明 |
来源数据源名 | ${datasource_name_di_src} |
来源库名 | ${db_name_di_src} |
来源表名 | ${table_name_di_src} |
来源 schema 名 | ${schema_name_di_src} 说明: 适用于 PostgreSQL、Oracle 等带 Schema 属性的数据源类型。 |
来源 Topic 名 | ${topic_di_src} 说明: 仅适用于 kafka 类型。 |
数据字段 | ${key} 说明: 仅适用于 kafka 类型,请替换 key 为具体字段名称。 |
说明:
示例1:如来源表名称为 table1,映射规则为${table_name_di_src}_inlong,则 table1的数据将被最终映射写入至 table1_inlong 中。
示例2:如果来源 kafka 消息格式为{“name”:“inlong”;“age”:12},映射规则为${name}_di,则此条消息将被最终映射写入至 inlong_di 表中。
此处的配置项根据目标端数据源类型的不同而存在一定的差异,具体以各目标端实际配置界面为准。
2. 映射匹配预览
针对 MySQL、TDSQL-C MySQL、TDSQL MySQL 为来源端的所有链路,目前支持映射匹配预览,支持按单表粒度进行配置。该功能为可选功能,用户可以不刷新源表和目标表映射,直接进入下一步。
如果需要按单表粒度进行配置,或查看来源表的主键情况,可单击刷新源表和目标表映射。按照用户设置的库匹配策略、表匹配策略进行映射,匹配到的目标表如果已存在则使用已有表,暂不支持使用其他表;匹配到的目标表如果在目标端不存在,则默认走自动建表。
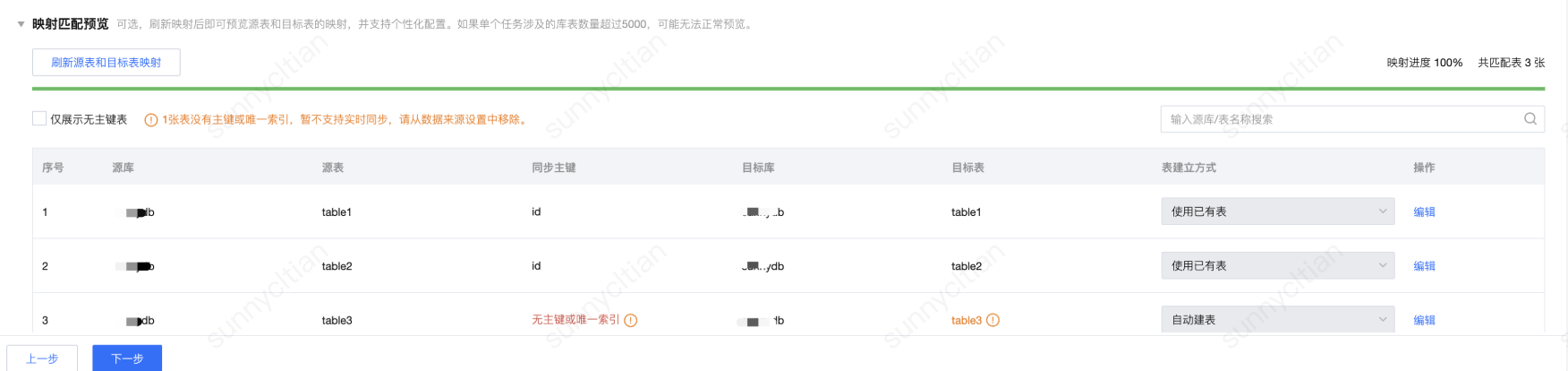
如果来源表选择了Exactly-once读取语义或者目标端为upsert写入模式,但是来源表无主键也无唯一索引,则同步主键列会提示:无主键或唯一索引。该表暂不支持实时同步,需要从数据来源设置中移除。源表的读取语义和目标端的写入模式依赖源表主键情况如下:
源端 Exaclty-once+目标端 upsert 写入模式:依赖源表主键或唯一索引
源端 Exaclty-once+目标端 append 写入模式:依赖源表主键或唯一索引
源端 At-least-once+目标端 upsert 写入模式:依赖源表主键或唯一索引
源端 At-least-once+目标端 append 写入模式:不依赖源表主键或唯一索引
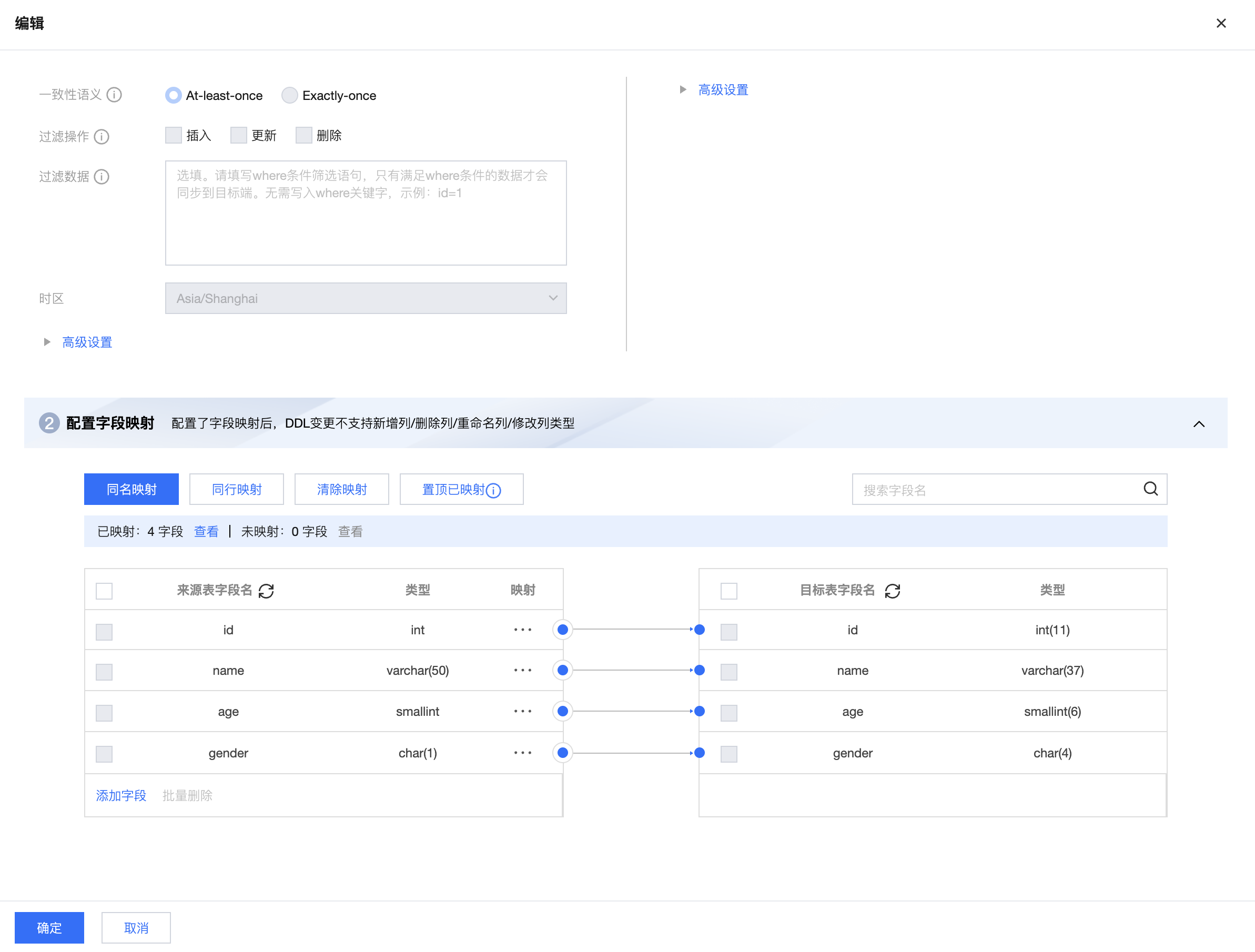
单击操作列的编辑支持按单表粒度进行配置。支持数据过滤、字段映射、函数转换等功能。
数据过滤:当前仅支持=、!=、>、<操作符
字段映射:支持自定义字段映射关系;支持添加常量或函数字段,映射到目标端字段。
3. 批量手动创建目标表(可选)
针对来源表与目标表之间名称匹配策略,系统将自动转换异构数据源之间 DDL 结构,为您提供手动批量快速修改、及创建目标表的能力。
系统将根据库及表匹配策略扫描目标对象,并自动生成目标表 DDL 语句。您可以在此步骤中检查目标表是否匹配正确、配置目标表创建方式、及编辑建表语句等。重点功能及对应说明如下:
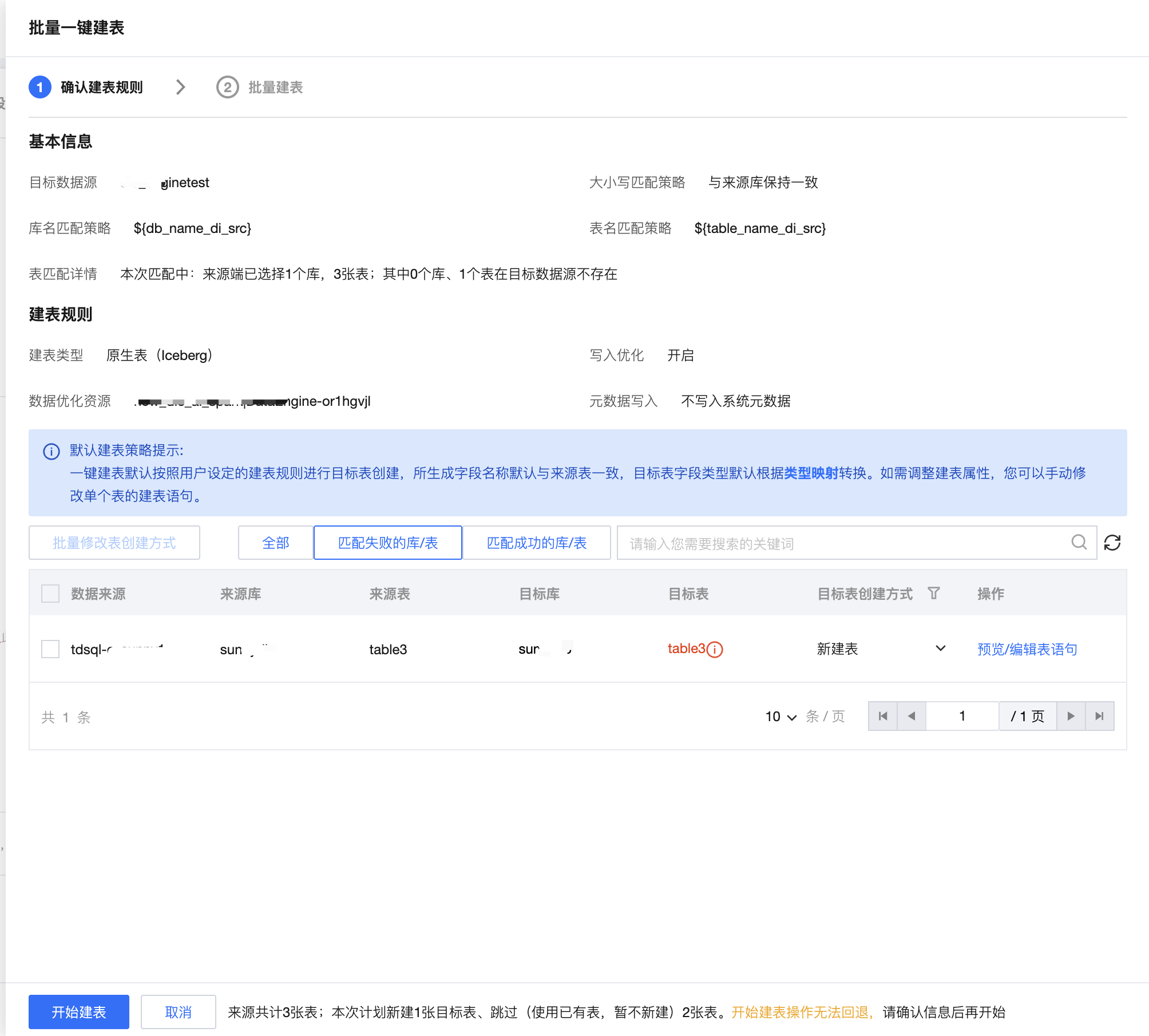
重点功能点 | 功能说明 | 功能示例 | |
1 | 目标库/表名称 | 系统将默认根据匹配规则预设生成目标库/表名称,同时扫描确认该库/表在目标数据源中是否存在: 匹配失败的库/表:未在目标数据源中发现符合匹配规则的库/表对象。列表默认高亮展示匹配失败的库表。 匹配成功的库/表:目标数据源中存在符合匹配规则的库/表对象。 | 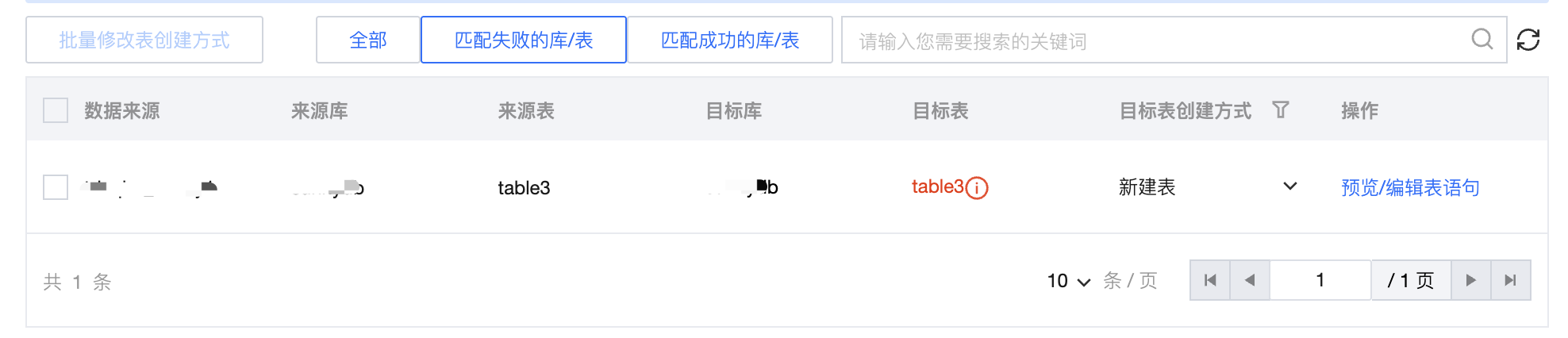 |
2 | 目标表建立方式 | 针对目标数据源中库/表对象,系统提供多种建表策略: 匹配失败的库/表:支持新建表、暂不新建两种方式 新建表:此次批量创建中,根据转换生成的目标表DDL 自动创建。 暂不新建:本次操作暂时忽略此表。 匹配成功的库/表:支持使用已有表、删除已有表并新建两种方式 使用已有表:本次操作暂时忽略此表。 删除已有表并新建:本次操作中删除已有表,并根据转换生成的目标表 DDL 重新创建同名表。 | 1. 匹配失败的库/表策略配置:  2. 匹配成功的库/表策略配置: 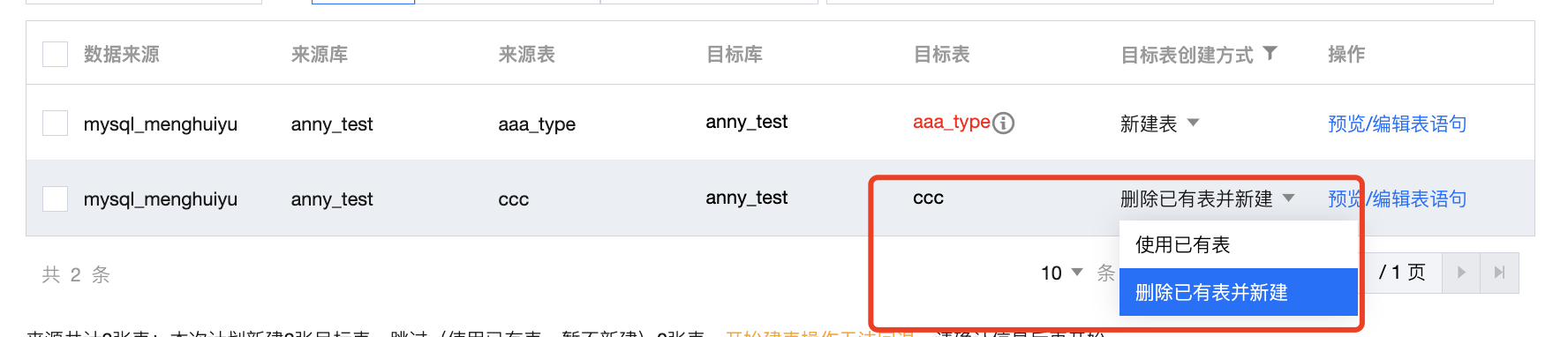 |
3 | 预览/编辑表语句 | 针对指定的目标表创建方式,系统将自动生成 DDL 样例。您可查看、编辑建表语句: 1. 目标表名称默认根据来源表名、目标表匹配策略自动生成。 2. 目标表字段默认与来源表名称保持一致。 3. 部分具有多个数据模型的目标数据源(例如 doris),系统将根据默认策略指定相应的模型。您可手动修改 DDL 语句以符合业务特性。 | 1. 新建表 DDL 语句: 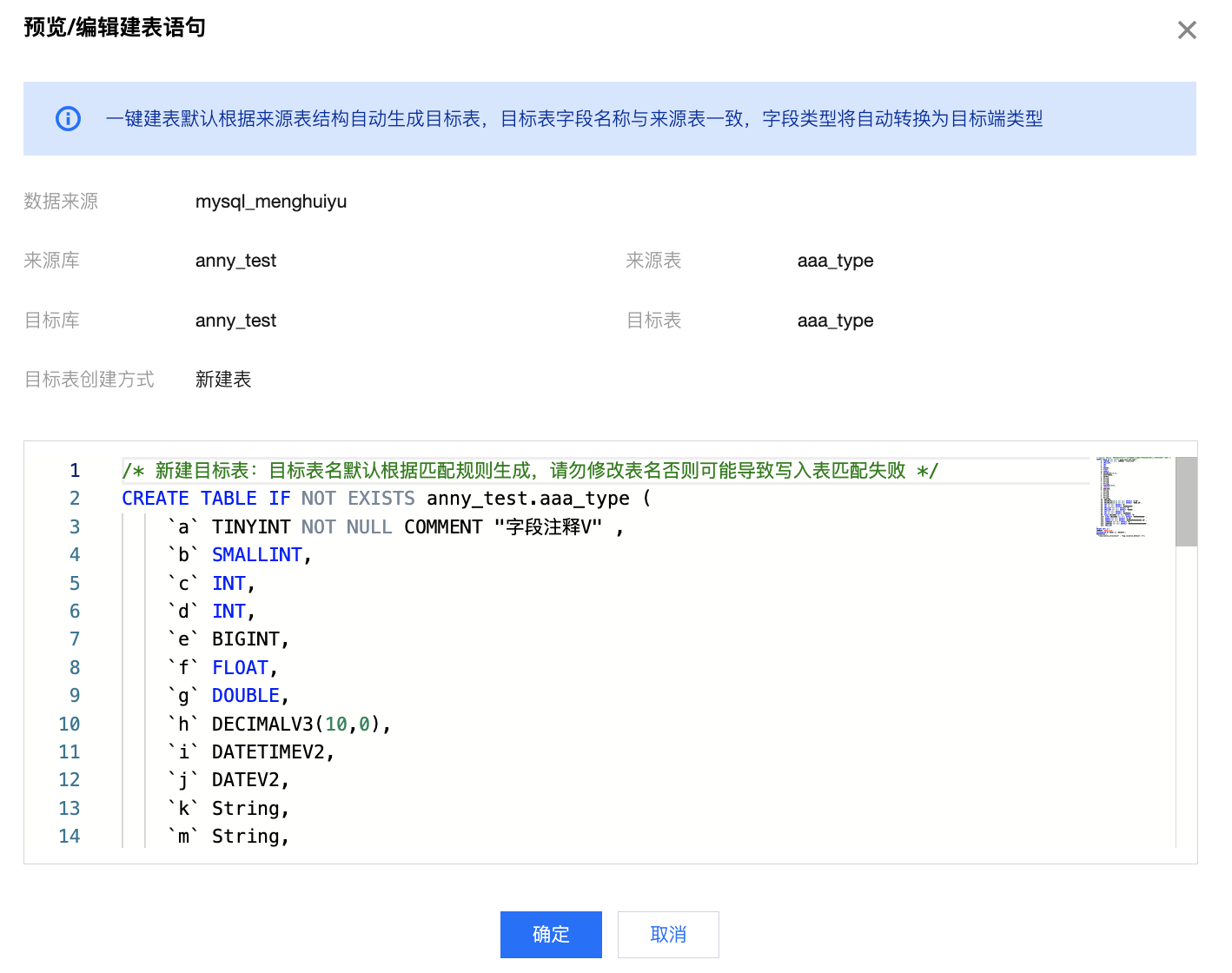 2. 删除已有表并新建 DDL 语句: 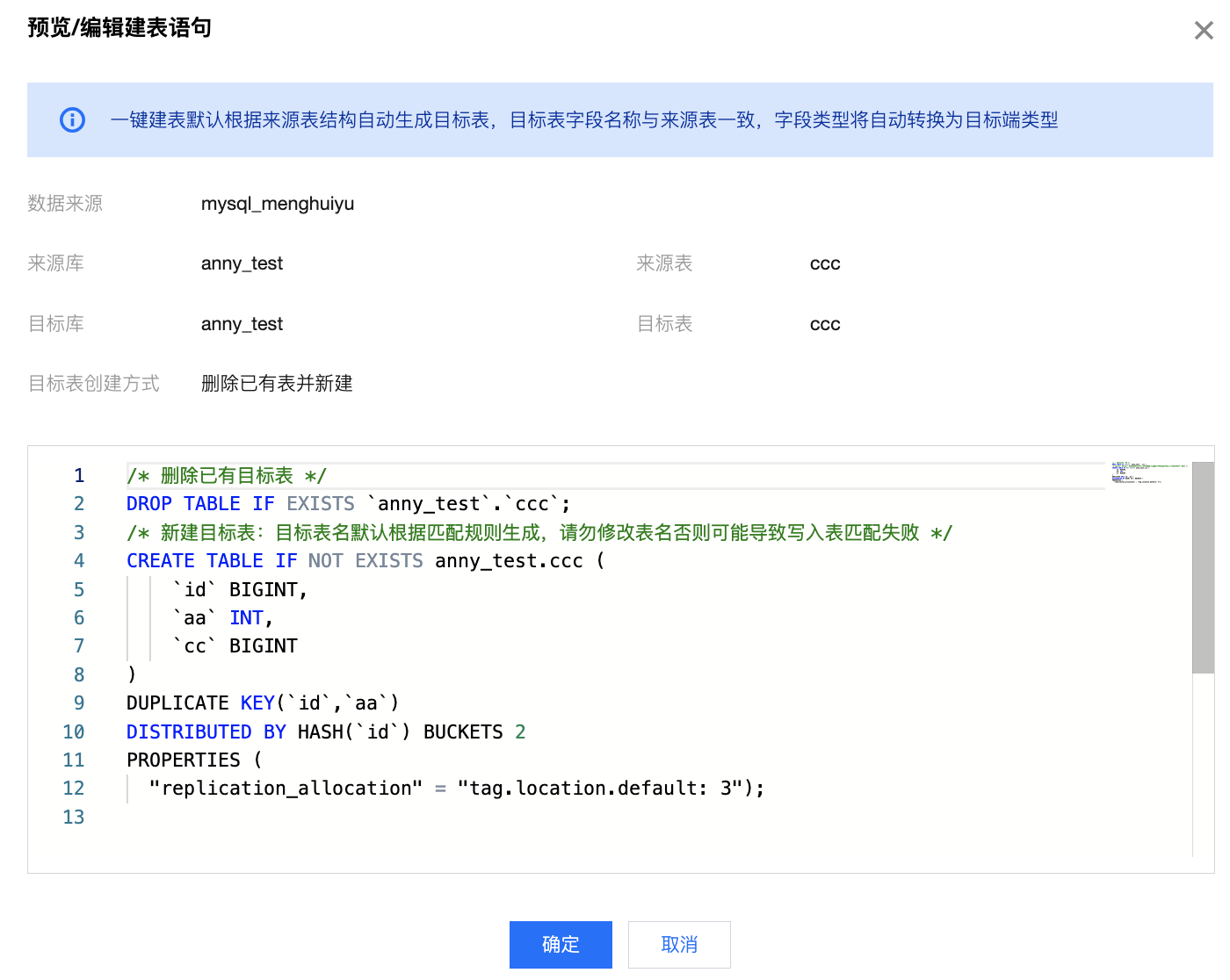 |
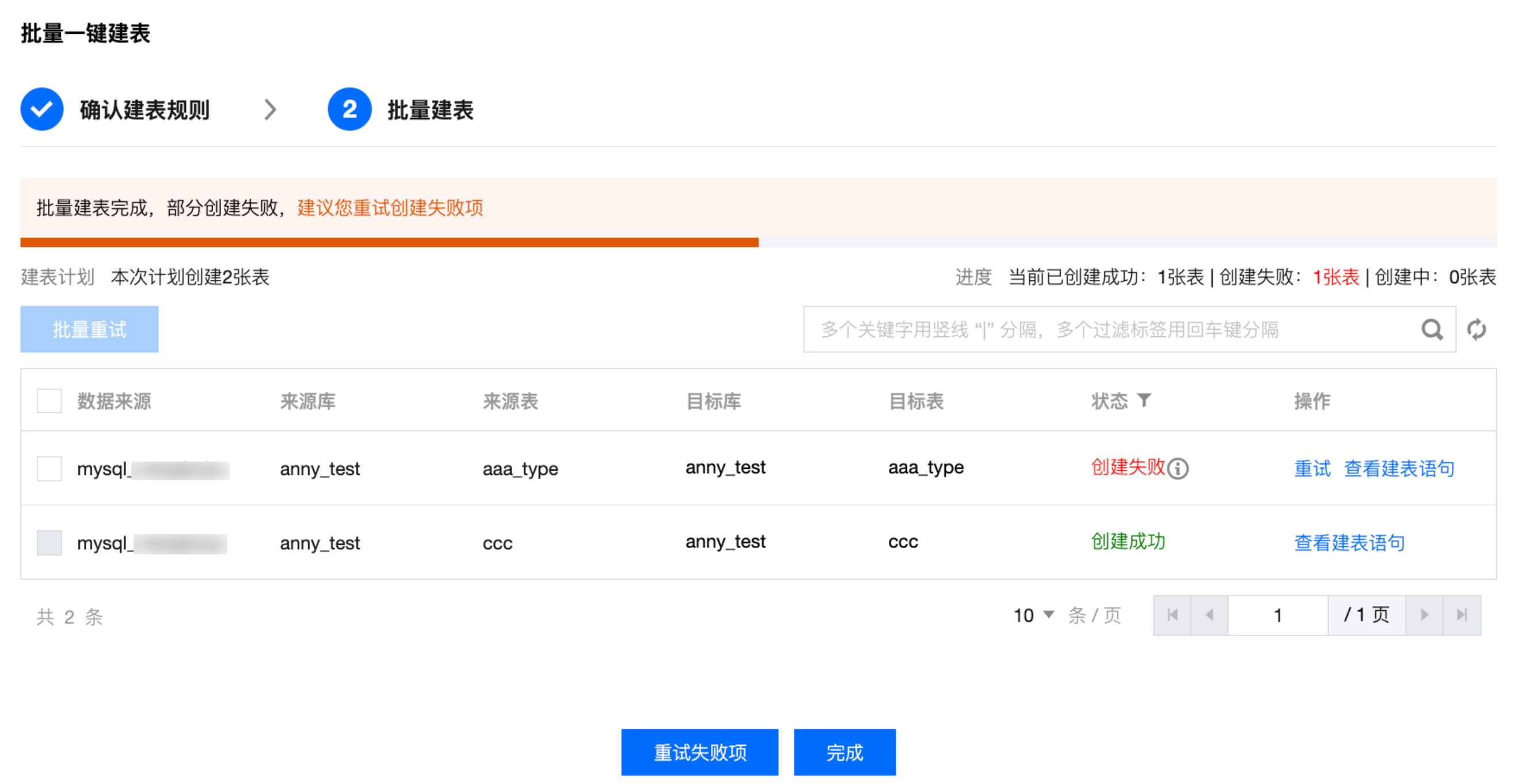
完成确认目标表创建规则后,可在本步骤中一次性创建目标表。
创建成功后,您可单击完成关闭弹窗,并继续配置后续任务。
若存在创建失败的表,您可查看创建失败的原因或单击重试重新创建。
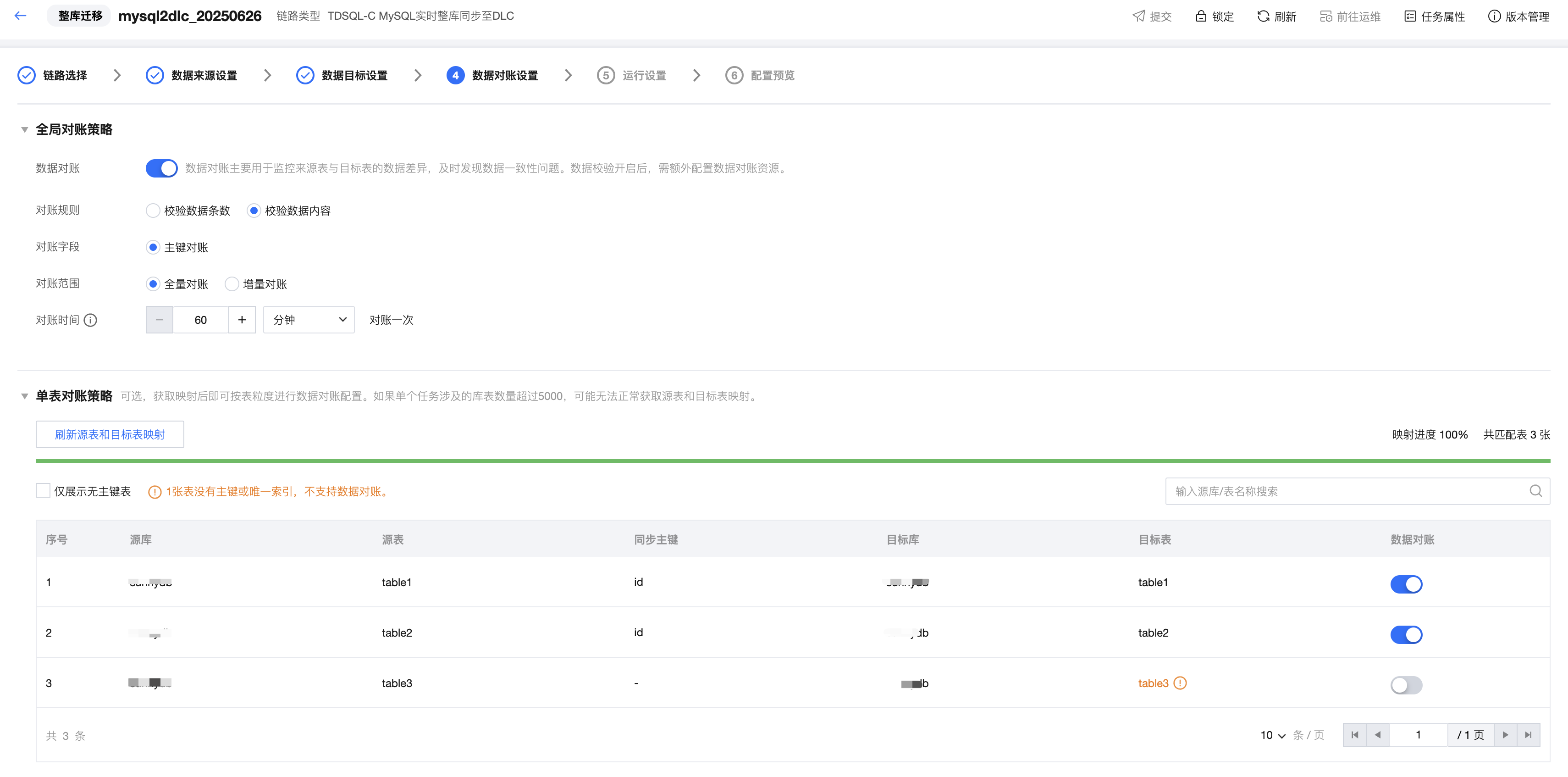
步骤五:数据对账设置
目前部分整库迁移链路支持数据对账,对源端数据和目标端数据进行一致性校验。支持全局对账策略配置,对任务中包含的所有库表生效;也支持按单表粒度进行对账策略配置,如按单表粒度进行数据对账开启或关闭、按单表修改增量对账条件。具体的配置说明及支持的对账链路见同步任务数据对账能力
说明:
校验数据条数不依赖主键;校验数据内容目前仅支持主键对账,所以需要源表包含主键。无主键且无唯一索引的表不支持基于主键的内容校验。
步骤六:配置运行资源和策略
当前步骤主要是为任务配置资源、DDL 和异常数据处理策略、以及高级运行参数等。
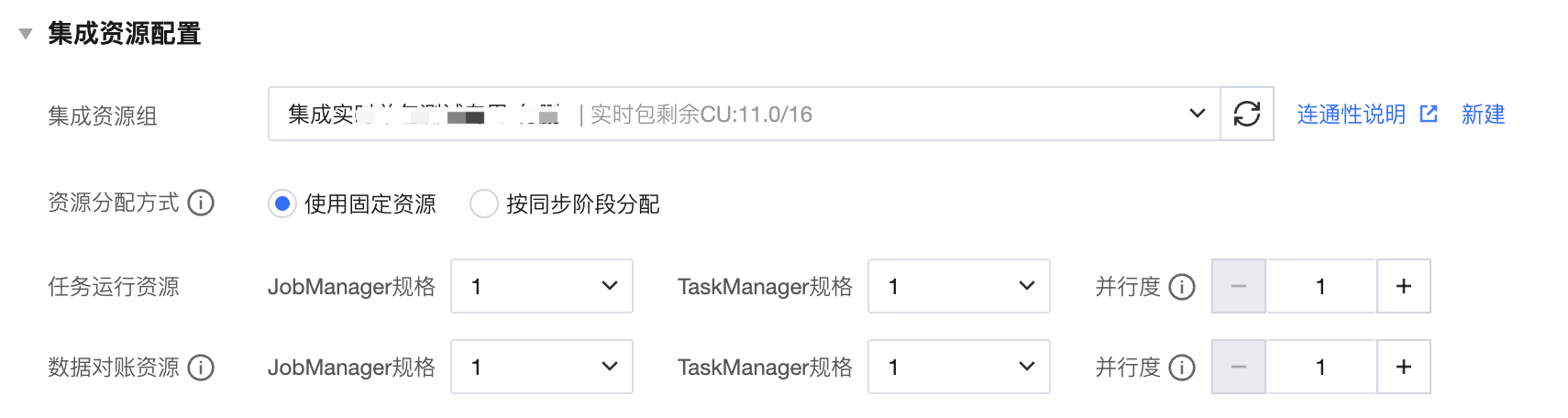
1. 集成资源配置
集成资源支持多种分配方式
固定分配:此方式下不区分任务同步阶段,全量及增量同步过程中始终为当前任务分配固定资源量。此方式可避免任务间资源抢占,适用于任务运行过程中数据可能存在较大变动的场景。
按同步阶段分配:按全量和增量不同同步阶段分配计划的资源使用量,以节约整体资源用量。
为当前任务关联对应的集成资源组,同时设定运行时 JM、TM 规格以及任务运行并行度。其中,当前任务实际运行时实际占用 CU 数 = JobManager 规格 + TaskManager 规格 × 并行度。
2. 消息处理策略
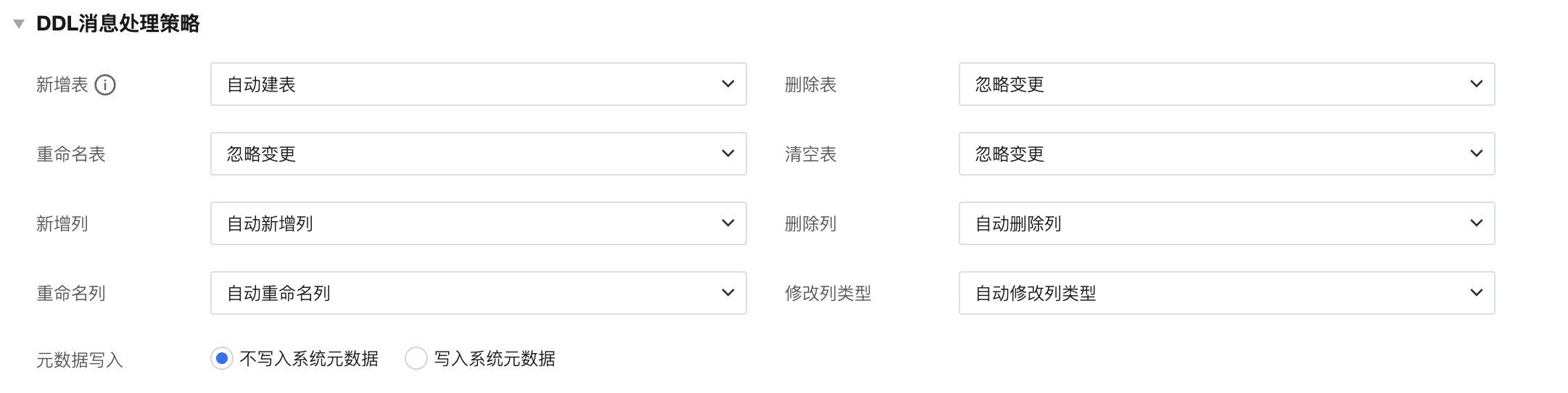
为当前任务配置包括写入 DDL 消息响应策略、元数据写入策略。
说明:
此处的配置项根据目标端数据源类型的不同而存在一定的差异,具体以各链路实际配置界面为准。
参数 | 说明 |
DDL 消息 | 该参数主要用于设置任务同步过程中,将来源端捕获的 DDL 变更消息捕获后传递至下游,下游如何响应对应消息。目标端针对 DDL 消息提供了以下响应策略: 1. 自动变更:此策略下针对来源端捕获的消息,目标端将自动跟随响应源端的结构变化,包括自动建表、自动新增列等。 2. 忽略变更:此策略下,目标端将忽略 DDL 变更消息不做任何响应以及消息通知等。 3. 日志告警:此策略下,目标端忽略 DDL 变更消息,但是日志中将提醒 DDL 变更消息详情。 4. 任务出错:此策略下,一旦源端出现 DDL 变更,整个任务将出现异常持续重启并报异常。 说明: |
元数据写入 | 勾选对应的元数据字段会在目标表中创建相应的元数据字段,同步过程中写入相应系统元数据。 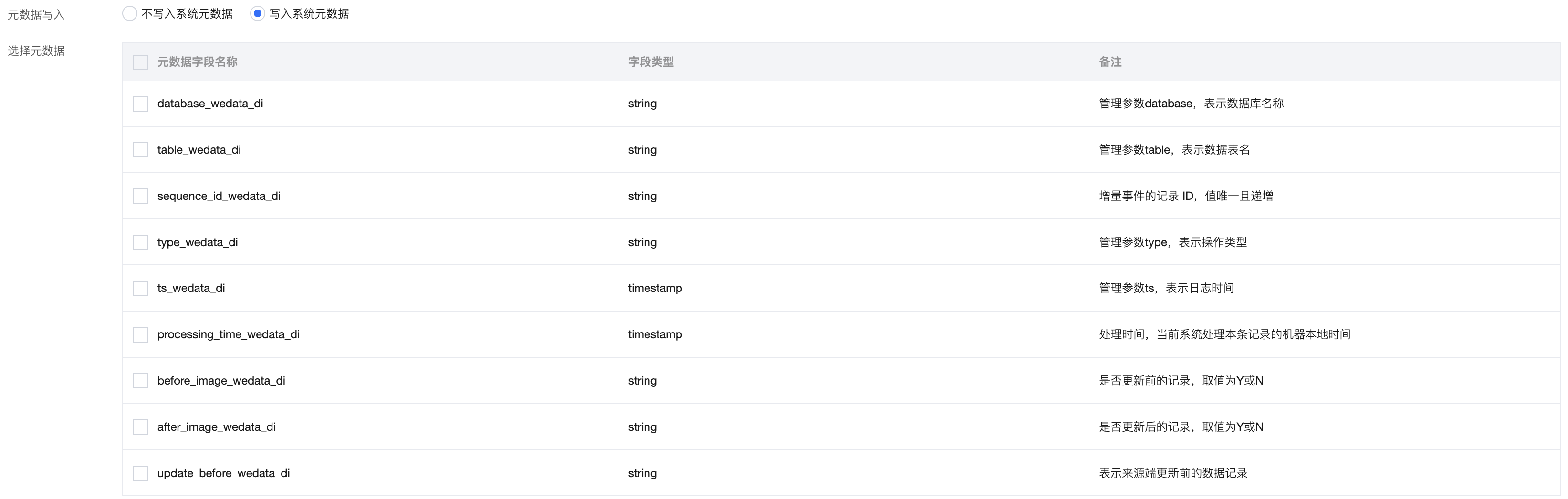 说明: 目前仅来源端为MySQL、TDSQL-C、Oracle、PostgreSQL、SQL Server类型时支持系统元数据。 |
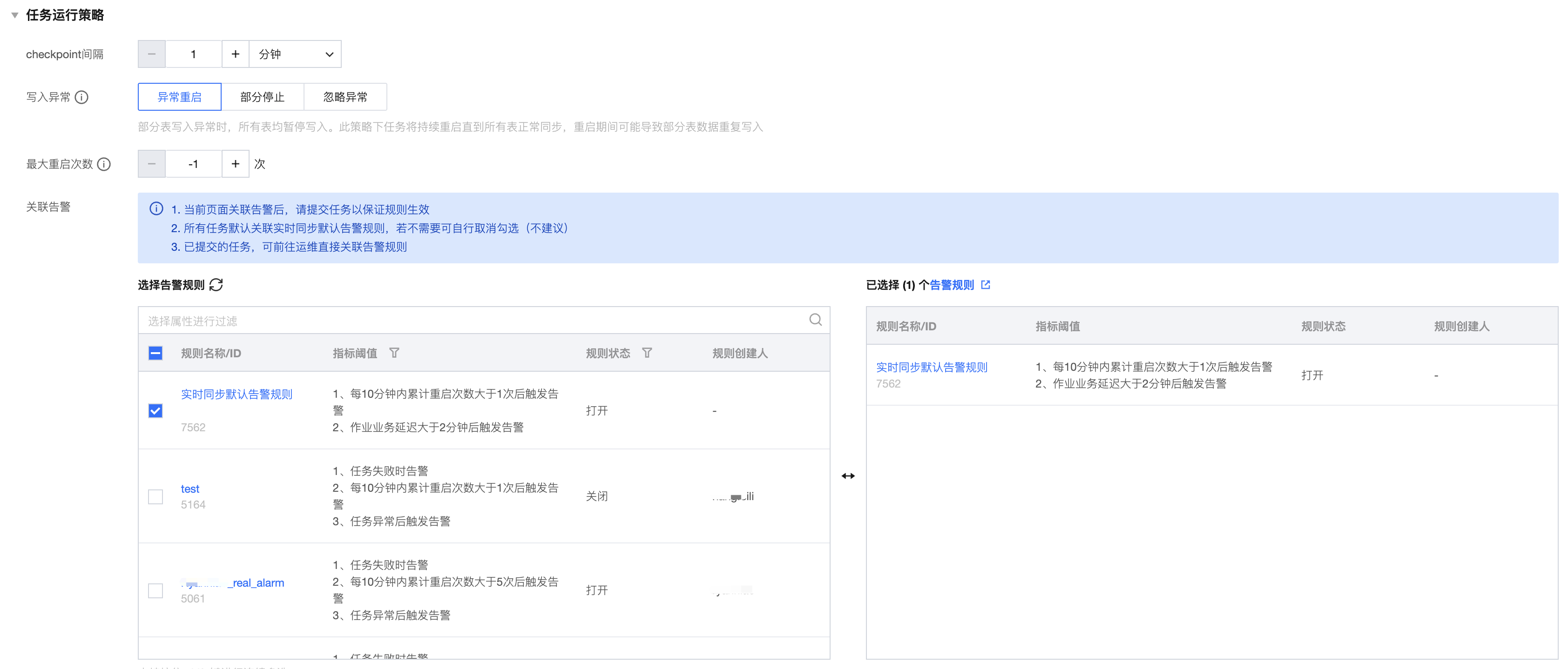
3. 任务运行策略
为当前任务设置提交间隔、写入异常策略、脏数据归档策略、最大重启次数、关联告警。
参数 | 说明 |
checkpoint 间隔 | 当前任务提交的最大 checkpoint 间隔。 |
写入异常 | 该参数用于设置在同步过程中由于表段结构不匹配、字段类型不匹配等各种原因导致数据写入失败时,任务如何处理该异常写入数据、以及是否中断数据流。整体写入异常策略包含: 1. 部分停止:部分表写入异常时,仅停止该表数据写入,其他表正常同步。已停止的表不可在本次任务运行期间恢复写入。 2. 异常重启:部分表写入异常时,所有表均暂停写入。此策略下任务将持续重启直到所有表正常同步,重启期间可能导致部分表数据重复写入。 3. 忽略异常:忽略表内无法写入的异常数据并标记为脏数据。该表的其他数据、以及任务内的其他表正常同步。脏数据提供COS 归档和不归档两种方案。 |
脏数据 | 当写入异常配置为忽略异常时,可选择针对忽略的数据是否进行归档: 1. COS 归档:统一将写入异常的数据归档至 COS 文件中保存,此方式下可避免异常写入数据丢失,可在后续场景中进行异常写入原因分析、数据补录等。 2. 不归档:任务完全忽略并丢弃写入异常的数据。 |
最大重启次数 | 设置在执行过程中发生故障时任务最大的重启阈值,若运行中重启次数超过此阈值,任务状态将置为失败,设置范围为[-1,100]。其中 阈值为0表示不重启; -1 表示不限制最大重启次数。 |
关联告警 | 为新建的任务配置告警规则,系统默认勾选实时同步默认告警规则,用户可自行按需勾选。 |
4. 高级设置

步骤七:配置预览及任务提交
1. 配置预览
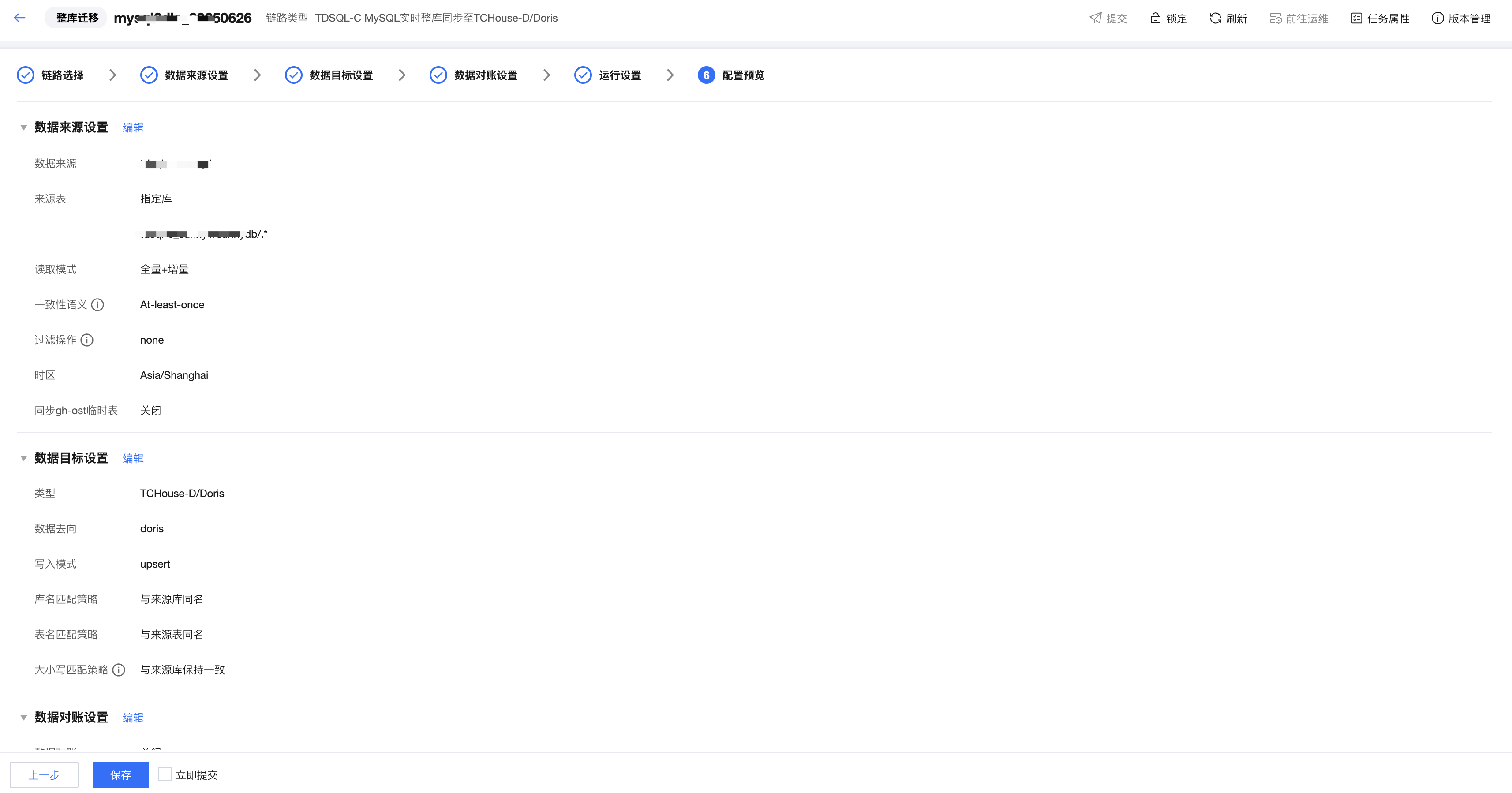
序号 | 参数 | 说明 |
1 | 提交 | 将当前任务提交至生产环境,提交时根据当前任务是否有生产态任务可选择不同运行策略: 若当前任务无生效的线上任务,即首次提交或线上任务处于“失败”状态,可直接提交。 若当前任务存在“运行中”或“暂停”状态的线上任务需选择不同策略。停止线上作业将抛弃之前任务运行位点,从头开始消费数据,保留作业状态将在重启后从之前最后消费位点继续运行。  说明: 单击立即启动任务将在提交后立即开始运行,否则需要手动触发才会正式运行。 |
2 | 锁定/解锁 | 默认创建者为首个持锁者,仅允许持锁者编辑任务配置及运行任务。若锁定者5分钟内没有编辑操作,其他人可单击图标抢锁,抢锁成功可进行编辑操作。 |
3 | 前往运维 | 根据当前任务名称快捷跳转至任务运维页面。 |
4 | 保存 | 预览完成后,可单击保存按钮,保存整库任务配置。仅保存的情况下,任务将不会提交至运维中心。 |
2. 任务配置检测与提交。
步骤 | 步骤说明 | |
任务配置检测 | 本步骤将针对任务内读端、写端以及资源进行检测: 检测通过:配置无误。 检测失败:配置存在问题,需修复以进行后续配置。 检测告警:此检测为系统建议修改项,修改完成后可单击重试重新检测;或者,您可以单击忽略异常进入下一步骤不阻塞后续配置。 当前支持的检测项见后续表格。 | 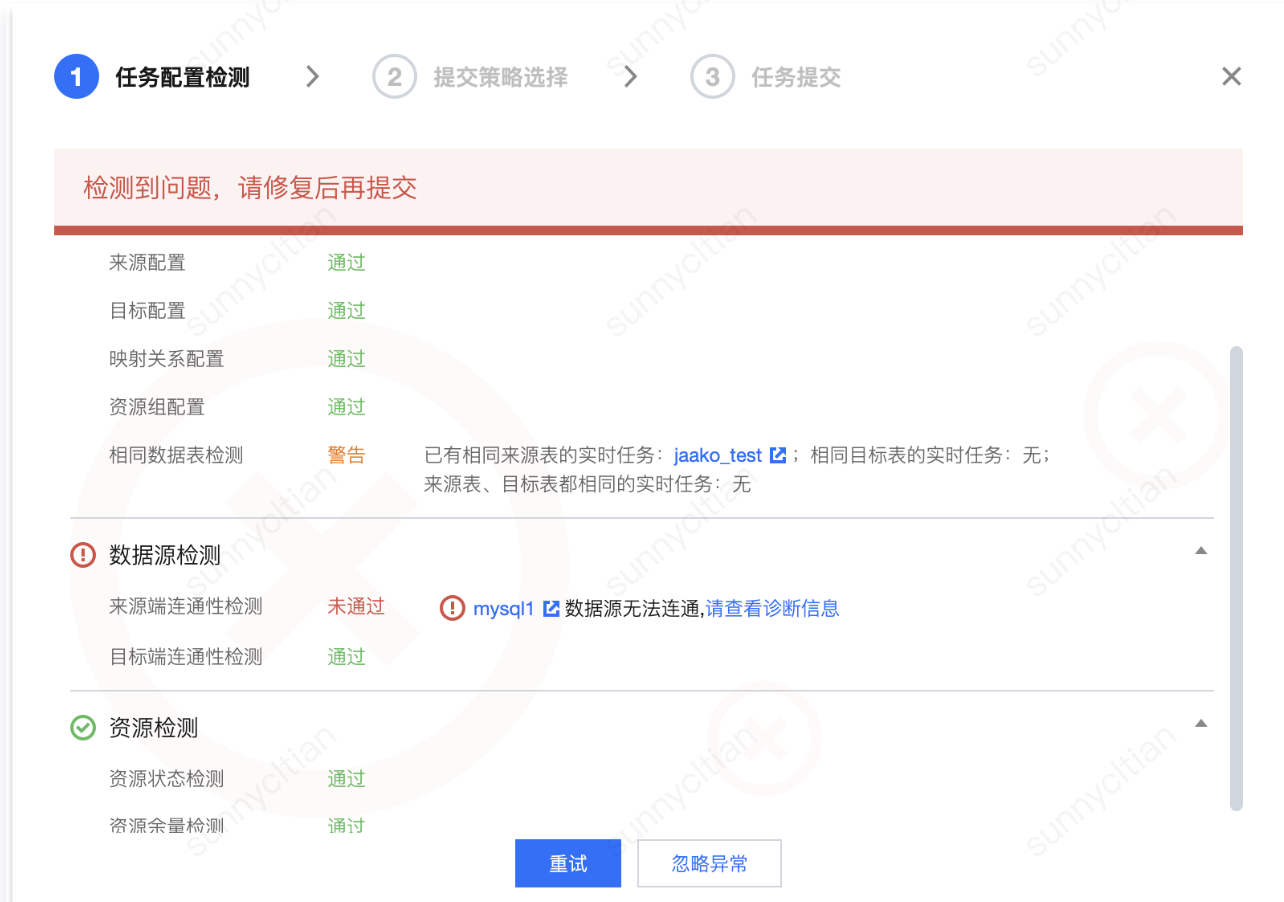 |
提交策略选择 | 本步骤中可选择本次任务提交策略: 首次提交:首次提交任务支持从默认或指定点位同步数据 立即启动,从默认点位开始同步:若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 立即启动,从指定时间点开始同步:任务将根据配置的时间及时区同步数据。若未找到指定的时间位点,任务将默认从 binlog 最早位点开始同步;若源端读取方式为“全量 + 增量”,任务将默认跳过全量阶段从增量的指定时间位点开始同步。 暂不启动:提交后暂不启动运行任务,后续可在运维列表内手动启动任务。 非首次提交:支持带运行状态启动或继续运行任务 继续运行:此策略下新版本任务提交后,将从上次同步最后位点继续运行。 重新启动,从指定位点开始:此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从 binlog 最早位点开始同步。 重新启动,从默认位点开始运行:此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量+增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 不同的任务状态支持的提交运行策略有所差异,详见后续表格。 同时,每次提交都将新生成一个实时任务版本,您可在对话框内配置版本描述。 | 1. 首次提交 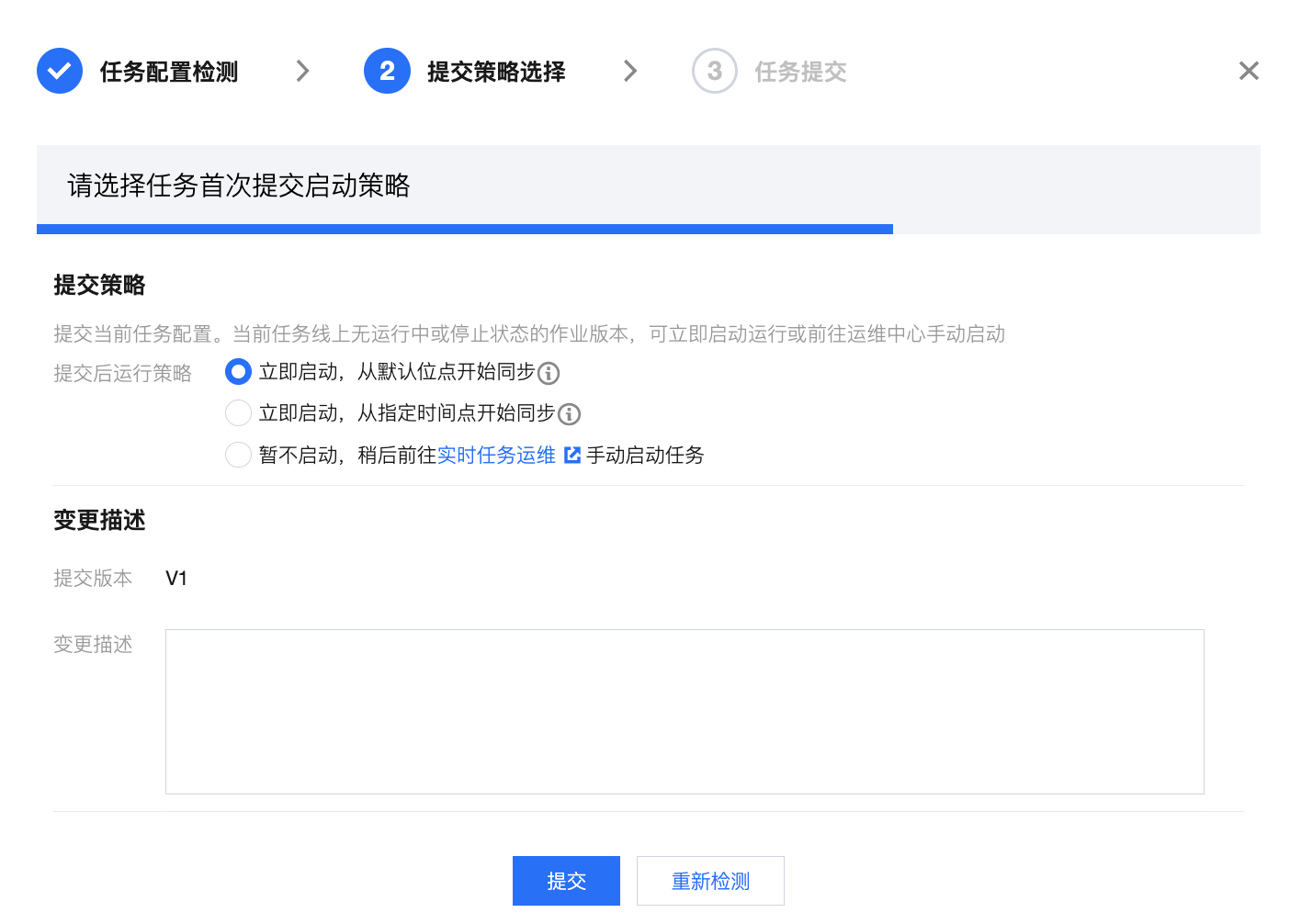 2.非首次提交 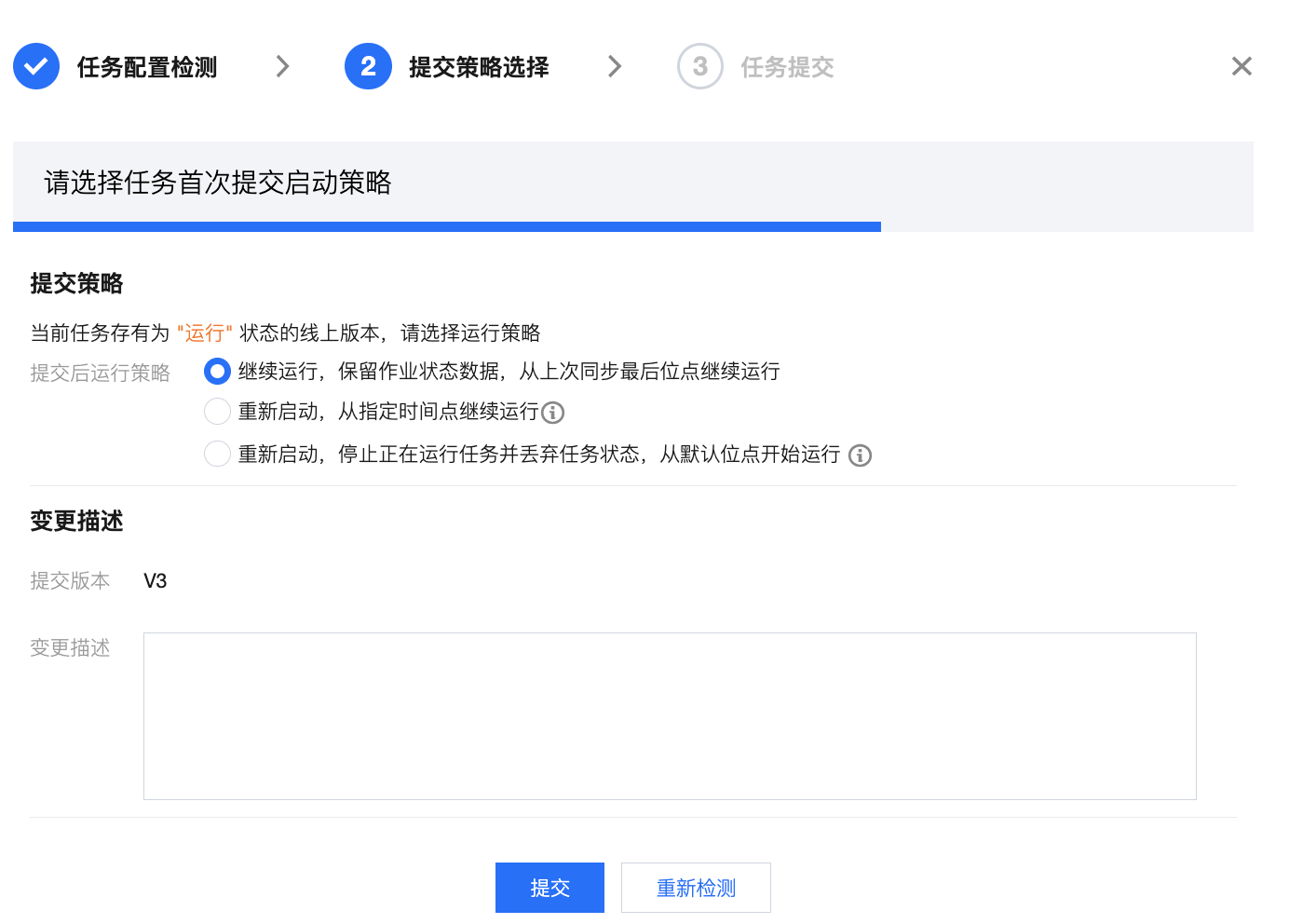 |
任务提交 | 提交成功后,您可单击前往运维查看任务运行情况。 |  |
任务配置检测支持的检测项:
检测分类 | 检测项 | 说明 |
任务配置检测 | 来源配置 | 检测来源端的必填项是否有缺失 |
| 目标配置 | 检测目标端的必填项是否有缺失 |
| 映射关系配置 | 检测字段映射是否已配置 |
| 资源组配置 | 检测资源组是否有配置 |
| 相同数据表检测 | 检测当前项目下所有的实时单表任务(包含已提交和未提交)是否有同样来源表或目标表或来源表与目标表都相同的情况。相同表的判断依据为是否是同一个数据源同一个DB下的同名表。此检测项主要用于同一个表不希望有多个任务重复读取的场景。 |
数据源检测 | 来源端连通性检测 | 检测来源端数据源跟任务配置的资源组是否网络联通。检测不通过可查看诊断信息,打通网络后可重新检测,否则任务大概率会运行失败。 |
| 目标端连通性检测 | 检测目标端数据源跟任务配置的资源组是否网络联通。检测不通过可查看诊断信息,打通网络后可重新检测,否则任务大概率会运行失败。 |
资源检测 | 资源状态检测 | 检测资源组是否为可用状态。若资源状态不可用,请更换任务配置的资源组,否则任务大概率会运行失败。 |
| 资源余量检测 | 检测资源组当前剩余的资源是否满足任务配置的资源需求。若检测不通过,请适当调小任务资源配置或扩容资源组。 |
不同的任务运行状态支持的提交运行策略:
任务状态 | 提交运行策略 | 说明 |
1. 首次提交 2. 已停止/检测异常/初始化(非首次提交) | 立即启动,从默认位点开始同步 | 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量+增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
| 立即启动,指定时间点开始同步 | 此策略下需选择具体的开始时间,根据时间匹配位点。 1. 从指定时间点开始读取数据。若未匹配到指定位点,任务则默认从 binlog 最早位点开始同步 2. 若您源端读取方式为全量 + 增量,选择此策略将默认跳过全量阶段从增量的指定时间位点开始同步 |
| 暂不启动,稍后前往实时任务运维手动启动任务 | 此策略下仅提交任务到实时运维,不进行任务启动,后续可从实时运维页面批量启动任务。 |
运行中(非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 |
| 重新启动,从指定时间点继续运行 | 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从binlog最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
已暂停(非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 注意: 暂停操作时会生成快照,任务重新提交支持从最后位点继续运行。 强制暂停时不生成快照,任务重新提交支持从任务运行时最近一次生成的快照运行。这种暂停会导致任务数据重放一部分,如果目标写入是 Append 会有重复的数据,如果目标写入是 Upsert 则不会有重复问题。 |
| 重新启动,从指定时间点继续运行 | 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从 binlog 最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
失败(非首次提交) | 从上次运行失败(checkpoint)位点恢复运行 | 此策略下将从任务上一次运行失败的位点继续运行 |
| 重新启动,根据任务读取配置从默认位点开始运行 | 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
操作中(非首次提交) | 不支持 | 线上有同名任务且状态为操作中时,不支持重新提交任务 |



