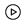The content of this page has been automatically translated by AI. If you encounter any problems while reading, you can view the corresponding content in Chinese.
The WeData data workflow provides a visual interface for creating and organizing workflows. A workflow is a logical collection of multiple tasks. It is recommended to organize a single complete data processing scenario in a workflow to avoid having too many tasks or tasks without logical connections, thereby reducing the maintenance costs of the workflow. The data workflow provides various types of task management and orchestration capabilities, such as Hive SQL, Spark SQL, Shell, etc.
Orchestration Space Directory Tree Area: In this area, you can view created folders and workflow tasks. Double-click to enter the edit interface. You can also perform operations such as global search, refresh, localization, collapse, and new creation.
3
Submit (
): After editing the workflow, click the icon in the toolbar to submit the nodes in the workflow to the scheduling system.
Refresh (
): Refresh all configuration information of the current workflow to ensure the parameters are up-to-date.
Go to Operation and Maintenance (
): Click this icon to go to the Operation and Maintenance - Workflow List page.
Workflow Testing (
): Click this icon to test the current workflow.
Stop Workflow Testing (
): Click this icon to stop testing the current workflow.
4
Task Node List: This area displays all the node information that Data Development supports configuration for.
5
Canvas: Double-click the workflow name in the directory tree to edit the dependency running relationships between tasks in the expanded workflow canvas.
6
This area is for the format configuration items of the canvas. You can configure the current workflow canvas accordingly.
7
This area allows you to configure the scheduling of the current workflow tasks to ensure the workflow runs properly.
General Settings: General configurations take effect for the current workflow orchestration and the task nodes within the workflow. Specific configurations can also be set in the node attributes (the scheduling is ultimately based on the node attribute settings; information that has been individually set for a node will not change with modifications to the workflow configuration).
Unified Scheduling: Set unified scheduling configurations for all task nodes under the workflow. Supports conventional and crontab methods.
History: Supports viewing the historical change records of the workflow, including the operator, change time, and operation content.
Version: Displays the historical submission records of computational tasks. You can view the Node Historical Versions, Submitted by, Submission Time, Change Type, Status, Remarks, and other information in the version panel. You can view the information of a single version and support the comparison between two selected versions.