数据湖计算 DLC 支持将 COS 上的数据直接导入至 DLC 托管存储的数据表,目前支持导入 CSV、JSON、Parquet、Avro、ORC 文件。DLC 托管存储目前为内测中,如需免费体验可 提交工单 进行申请。
数据湖计算 DLC 与数据开发治理平台 WeData 进行了深度融合,通过 WeData 可将超过二十种的数据源数据导入 DLC 中进行分析。
通过控制台导入
通过控制台,您可以通过导入 COS 创建数据表或选择已有数据表进行 COS 数据导入,操作步骤如下:
说明
1. 登录 数据湖 DLC 控制台,选择服务地域,登录账户须有数据库建表权限。
2. 进入数据管理页,单击数据名称进入数据库详情。
3. 单击创建数据表或导入数据,即可选择 COS 为数据源进行数据导入。详细操作可参见 数据表管理。
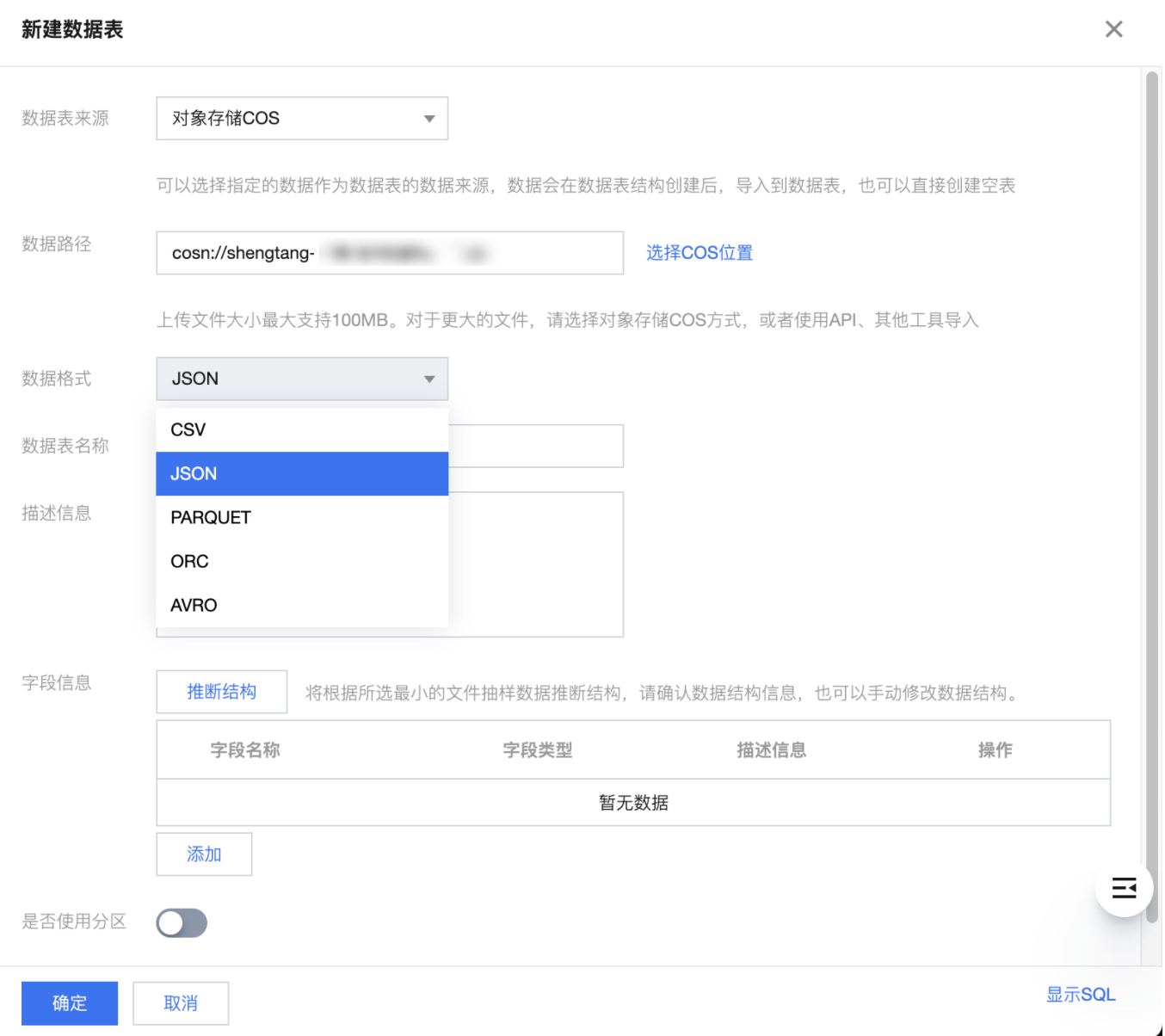
CSV:支持可视化配置解析 CSV 规则,包括压缩格式、列分割符号、字段域符。支持自动推断数据文件的 Schema 和将首行解析为列名。
JSON:DLC 仅将 JSON 的第一层级识别为列,支持自动推断 JSON 文件的 Shema,系统会将 JSON 第一层字段识别为列名。
支持 Parquet、ORC、AVRO 等常见大数据格式数据文件。
可手动添加和输入列名称和字段类型。
若选择了自动推断结构,DLC 会自动填充识别到的列、列名称、字段类型,若不正确请手动修改。
通过 API 导入
接口说明
参数名 | 类型 | 描述 | 是否必须 |
InputConf | []KVPair | 输入配置:导入任务的输入配置参数,如fileType、paths、以及各种文件类型各自支持的参数,具体查看下文 | true |
InputType | string | 输入类型:目前仅支持 cos | true |
OutputConf | []KVPair | 输出配置:导入任务的输出配置参数,如 databaseName、tableName,具体查看下文 | true |
OutputType | string | 输出类型:目前仅支持 lakefsStorage | true |
其中 InputConf 参数如下:
参数名 | 类型 | 描述 | 是否必须 |
fileType | string | 文件类型,可选 csv、JSON、parquet、avro、orc | true |
paths | string | 文件(目录)路径,多个路径使用英文逗号分隔 | true |
...... | string | 查看下文获取具体文件类型所支持的参数 | false |
其中 OutputConf 参数如下:
参数名 | 类型 | 描述 | 是否必须 |
databaseName | string | 数据库名 | true |
tableName | string | 表名 | true |
mode | string | 导入模式,可选 append(默认)、overwrite | false |
导入 CSV 数据
注意
默认会按照列的顺序导入到目标表,可通过参数设置 importByColumn 为 true 以按列名来导入;当importByColumn 为 true 时,数据来源对比目标表多列忽略,少列为 null。
参数名 | 描述 | 默认值 |
sep | 指定单个字符分割字段和值 | , |
encoding | 通过给定的编码类型进行解码 | uft-8 |
quote | 其中分隔符可以是值的一部分,设置用于转义带引号的值的单个字符 | " |
escape | 设置单个字符用于在引号里面转义引号 | \\ |
header | 是否有表头。若有表头则可以使用按照 key 读取数据,可通过参数 importByColumn 控制 | false |
allowJaggedRows | 是否允许锯齿形数据(数据少列、多列),若为 false 则会被当成错误数据处理 | false |
onError | 遇到错误时的处理方式。CONTINUE | SKIP_num | SKIP_num% | ABORT_STATEMENT CONTINUE:忽略该行错误数据,继续导入。 SKIP_num:允许 num 条错误数据,如:SKIP_12。 SKIP_num%:允许 num%百分比的错误数据。 ABORT_STATEMENT:直接中止任务,报错。 | ABORT_STATEMENT |
importByColumn | 根据列名匹配值导入数据,默认按照列顺序读取数据 | false |
errorOnColumnCountMismatch | 按照顺序读取,当数据集列数和目标表列数不匹配时是否报错,若为 false,则多列忽略、少列默认为null | true |
importLimit | 最大导入行数,若配置,数值不超过2147483647 | -1(全量导入) |
trimSpace | 去掉前后空格 | false |
nullMarker | 此标志表示一个可选的自定义字符串,该字符串代表数据中的一个 NULL 值 | NULL |
导入 JSON 数据
注意
数据来源对比目标表多列忽略,少列为 null。
参数名 | 描述 | 默认值 |
encoding | 通过给定的编码类型进行解码 | uft-8 |
onError | 遇到错误时的处理方式。CONTINUE | SKIP_num | SKIP_num% | ABORT_STATEMENT CONTINUE:忽略该行错误数据,继续导入。 SKIP_num:允许 num 条错误数据,如:SKIP_12。 SKIP_num%:允许 num%百分比的错误数据。 ABORT_STATEMENT:直接中止任务,报错。 | ABORT_STATEMENT |
importLimit | 最大导入行数,若配置,数值不超过2147483647 | -1(全量导入) |
trimSpace | 去掉前后空格 | false |
nullMarker | 此标志表示一个可选的自定义字符串,该字符串代表数据中的一个 NULL 值 | NULL |
导入 Parquet 数据
注意
数据来源对比目标表多列忽略,少列为 null。
参数名 | 描述 | 默认值 |
importLimit | 最大导入行数,若配置,数值不超过2147483647 | -1(全量导入) |
trimSpace | 去掉前后空格 | false |
nullMarker | 此标志表示一个可选的自定义字符串,该字符串代表数据中的一个 NULL 值 | NULL |
导入 Avro 数据
注意
数据来源对比目标表多列忽略,少列为 null。
参数名 | 描述 | 默认值 |
importLimit | 最大导入行数,若配置,数值不超过2147483647 | -1(全量导入) |
trimSpace | 去掉前后空格 | false |
nullMarker | 此标志表示一个可选的自定义字符串,该字符串代表数据中的一个 NULL 值 | NULL |
导入 ORC 数据
注意
数据来源对比目标表多列忽略,少列为 null。
参数名 | 描述 | 默认值 |
importLimit | 最大导入行数,若配置,数值不超过2147483647 | -1(全量导入) |
trimSpace | 去掉前后空格 | false |
nullMarker | 此标志表示一个可选的自定义字符串,该字符串代表数据中的一个 NULL 值 | NULL |