概述
由于 Doris 高度兼容 Mysql 协议,两者在 SQL 语法方面有着比较强的一致性,另外 Mysql 客户端也是 Doris 官方选择的客户端。因此,如需对 Mysql 进行数据分析,使用 Doris 的迁移成本较低。另外加上 Doris 各种优秀的计算能力,对原 Mysql 开发人员来说,基于 Doris 进行 Mysql 数据分析是一个良好的选择。
数据同步
Doris Mysql 外表
可以基于 Doris ODBC 外表的机制建立 Mysql 外表。语法如下:
CREATE EXTERNAL TABLE `doris_mysql_external_tbl1` (`aaaa` int(11) NULL COMMENT "",`bbbb` varchar(256) NULL COMMENT "") ENGINE=ODBCCOMMENT "ODBC"PROPERTIES ("host" = "xxxxx","port" = "3306","user" = "root","password" = "xxxxx","driver" = "MySQL ODBC 8.0 Driver","odbc_type" = "mysql","charest" = "utf8","database" = "abc","table" = "abc_utf8")
适用场景:
适用于少数据量的查询或计算。
通常在外表数据量较小,少于100W条时,可以通过外部表的方式访问。由于外表无法发挥Doris在存储/计算引擎部分的能力和会带来额外的网络开销,所以建议根据实际对查询的访问时延要求来确定是否通过外部表访问还是将数据导入 Doris 之中。
如果不符合上述计算场景,例如 Mysql 表数据较大或需要进行关联查询的表较多或计算较复杂,那就需要把 Mysql 的数据导入 Doris,然后在 Doris 中做计算。由于 Mysql 一般是作为实时更新的业务库存在,导入 Mysql 数据到 Doris 最好也是实时同步。
实时导入 Mysql 数据
有多种生态组件可以方便实现实时导入 Mysql 数据到 Doris。第一种是基于 Mysql binlog + Canal 的方案,第二种是 Mysql binlog + Flink CDC。
基于 Mysql binlog + Canal 实现实时同步
适用场景:
INSERT/UPDATE/DELETE 支持。
过滤 Query。
暂不兼容 DDL 语句。
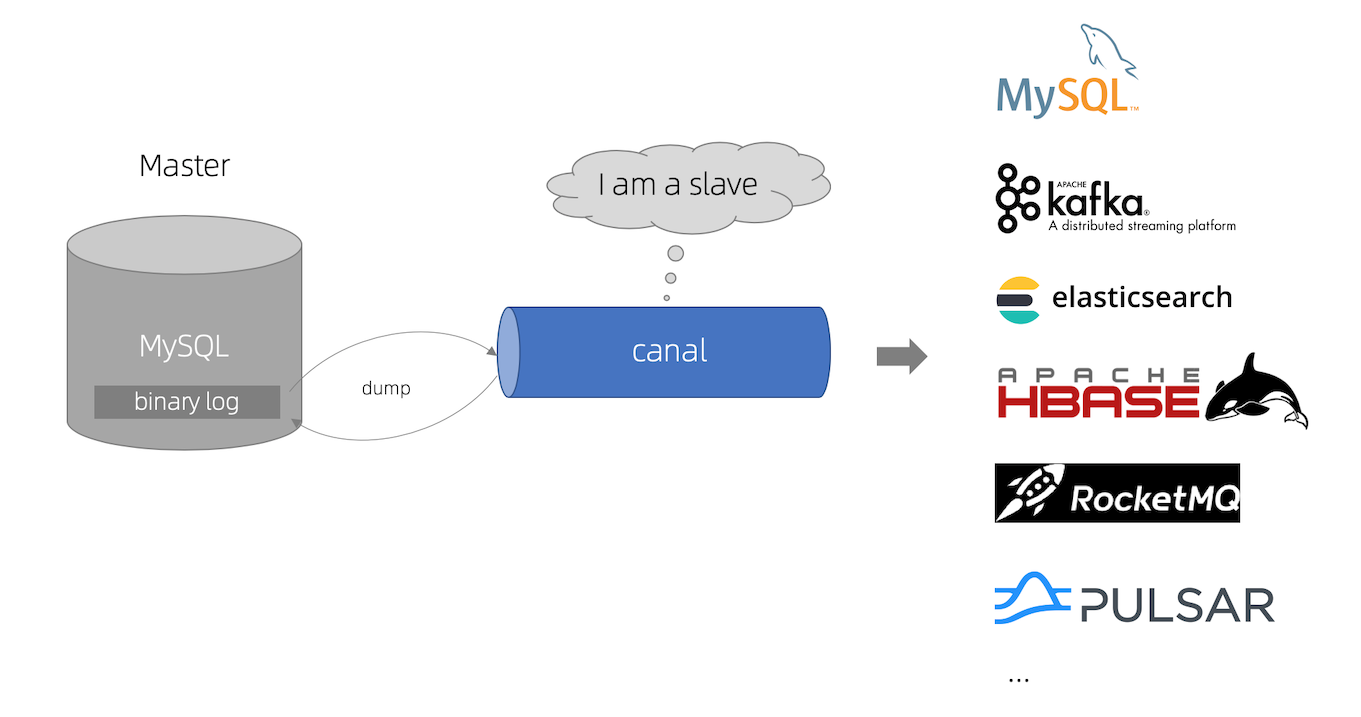
基本原理:
Canal 模拟 MySQL Slave 的交互协议,伪装自己为 MySQL Slave,向 MySQL Master 发送 dump 协议。
MySQL Master 收到 dump 请求,开始推送 binary log 给 Slave (即 Canal )。
Canal 解析 binary log 对象(原始为 byte 流),并且通过连接器发送 Doris 中。
基于 Mysql binlog + Flink CDC 实现实时同步
Flink CDC 基于数据库日志的 Change Data Capture 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。Flink SQL 原生支持的 Changelog 机制,可以让 CDC 数据的加工变得非常简单。用户通过 SQL 便能实现数据库全量和增量数据的清洗、打宽、聚合等操作,极大地降低了用户门槛。此外, Flink DataStream API 支持用户编写代码实现自定义逻辑,给用户提供了深度定制业务的自由度。
适用场景:
大量库表或整库导入
分库分表数据导入
需要额外ETL处理
希望导入存量数量
Flink CDC 的优势:
Flink 的算子和 SQL 模块更为成熟和易用。
Flink 作业可以通过调整算子并行度的方式轻松扩展处理能力。
Flink 支持高级的状态后端(State Backends),允许存取海量的状态数据。
Flink 提供更多的 Source 和 Sink 等生态支持。
使用 Doris 加速业务分析
作为专业的 OLAP 引擎,Doris 拥有多种技术可加速数据分析能力。存储层面 Doris 采用列式存储在极大降低存储、网络 IO 消耗之外,可以方便支持列裁剪、谓词下推、向量执行、SIMD 等高级特性加速执行效率。存储格式是默认行为,用户无需操作。除此之外,用户在 Doris 中可采用不同数据模型、为表添加多种类型索引、预聚合等功能以及多种优化的算法加速 SQL 运行效率。
数据模型
Doris 的数据模型主要分为3类:
Aggregate:表中列分为维度列和聚合列,在数据写入过程中即完成聚合计算。
Unique:表需设定主键,保证按主键的唯一性。
Duplicate:表不做聚合也没有主键,适合存储明细数据。
索引
Doris 支持的索引类型有:
BloomFilter 索引:适用于高基数列,且查询条件大多是 in 和 = 的过滤。详细介绍及用法参见 BloomFilter 索引。
Bitmap 索引:主要适用于大量相同值的列。详细介绍及用法参见 Bitmap 索引。
预聚合
采用 MOLAP 思想,将查询时计算量前置到查询前。Doris 支持的预聚合有:
Rollup 索引:即建表时 Aggregate 和 Unique 模型中的 ROLLUP。详细介绍及用法参见 Rollup 索引。
物化视图:主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。建好物化视图后,在数据变化时 Doris 会自动维护物化视图。详细介绍及用法参见 物化视图。
其它优化
缓存表/分区:将表或分区的数据缓存到内存中,加速查询。详细介绍及用法参见 缓存表或分区到内存。
Colocation Join: 用户通过设置Colocation Join Group,为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,加速查询。详细介绍及用法参见 Colocation Join。
Bucket Shuffle Join: 为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询。介绍及用法参见 Bucket Shuffle Join。
Runtime Filter: 为某些 Join 查询在运行时动态生成过滤条件,来减少扫描的数据量,避免不必要的 I/O 和网络传输,从而加速查询。介绍及用法参见 Runtime Filter。
各优化手段都有各自适用的场景和前置条件,您可根据自己需求自由组合。