下载性能测试包
性能测试可以参见我们提供的性能测试包。
解压
tar -zxvf taco_llm_demo.tar.gzcd taco_llm_demo
初始化环境
下载数据集、参考模型等。
#!/bin/bash# 需要在有外网的环境下,先下载对应的测评需要用到的数据集 如果本目录有了,则忽略wget -c https://taco-1251783334.cos.ap-shanghai.myqcloud.com/llm/data/ShareGPT_V3_unfiltered_cleaned_split.jsonwget -c https://taco-1251783334.cos.ap-shanghai.myqcloud.com/llm/data/c4_sample.jsonlwget -c https://taco-1251783334.cos.ap-shanghai.myqcloud.com/llm/data/medical_dialogue.jsonwget -c https://taco-1251783334.cos.ap-shanghai.myqcloud.com/llm/data/github_sample.jsonl# 下载参考模型Llama-2-7b-hf,注意更多模型可以在huggingface下载或者找我们接口人看cos是否已经有wget -c https://taco-1251783334.cos.ap-shanghai.myqcloud.com/llm/llama/llama-2/Llama-2-7b-hf.tar
注意:
如果客户自己有数据集也可以在相关的脚本中调整、如果有相同的数据集,也可以不用再下载。
在线场景性能测试
运行 server 端
bash taco_bench_server.sh taco_llm
可以直接执行 server 端脚本,后面附加一个框架名称,例如 taco_llm。启动该脚本的目的是创建一个server端的等待任务,待 client 请求处理。
server 脚本中关键参数:大多数参数可参照本文中的在线模型进行配置。以下是更多参数配置的说明:
chat_template="./llama.jinja" # chat配置的模板路径,包里已经包含# 设置prompt参数SYSTEM_PROMPT_LENGTH=0tgt_max_len=300 # 请求生成的最大长度NUM_PROMPT_PRE_TGT=5 # 每个并发请求数NUM_TGT=1 # 每秒并发数#设置服务器参数host="127.0.0.1" # 服务器地址port="8007" # 服务端口max_num_batched_tokens=10240 # 表示每次执行推理时支持最长的处理token数,多个batch一次处理的token总数。max_num_seqs=32 # 后端支持最大的batch数
运行 client 端
bash taco_bench_client.sh taco_llm
client 脚本中关键参数:大多数参数可以参考本文中提到的在线模型。更多参数配置的说明如下:
DATASET_PATH="./ShareGPT_V3_unfiltered_cleaned_split.json" # 数据集路径MODEL_PATH="/models/Llama-2-7b-hf" # 模型路径tp=1 # 需要的GPU卡数量TOKENIZER_PATH=$MODEL_PATH# 设置prompt参数SYSTEM_PROMPT_LENGTH=0tgt_max_len=300 # 请求生成的最大长度NUM_PROMPT_PRE_TGT=5 # 每个并发请求数NUM_TGT=1 # 每秒并发数# 设置输出长度output_len=100 # 设置每个请求最大输出数量#设置服务器参数 # 服务端地址,需要和server配套backend=${1}host="127.0.0.1"port="8007"ENABLE_PREFIX_CACHE=true # true/false: 打开/关闭 Auto Prefix Cache功能ENABLE_CACHE_OFFLOAD=true # true/false: 打开/关闭 Cache Offload功能ENABLE_HIT_CNT=true # true/false: Cache命中情况打印ENABLE_LOOKAHEAD=false # true/false: 打开/关闭 lookahead功能
结果
我们将结果根据相关指标存储在本地的 results 目录中。
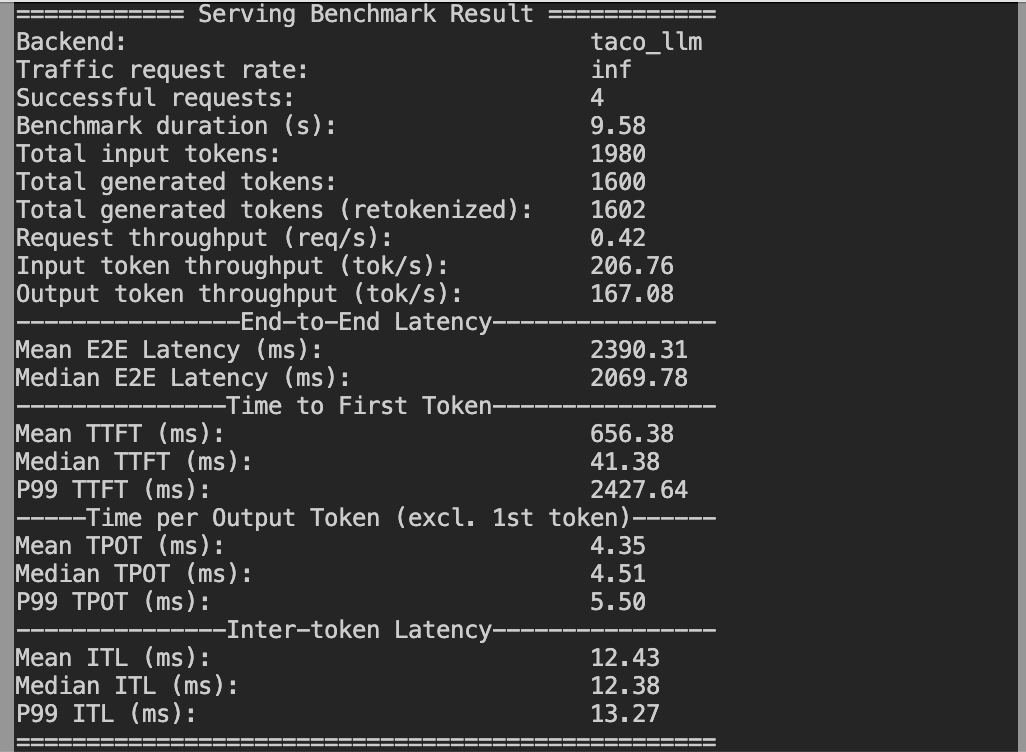
taco_llm_demo/results/**.csv
csv 表格结果如下:

一键测试
客户也可以使用一个脚本完成 server/client 端测评部署并直接得到结果
bash taco_bench.sh taco_llm
注意:
实际上,这个脚本将上述的 server 端和 client 端两个脚本合并,在启动 server 端后等待10秒,然后启动 client 端。



