本教程演示如何使用腾讯云向量数据库(Tencent Cloud VectorDB)AI 套件一站式文档检索方案进行相似性检索,结合 LLM 大模型,构建专属知识库问答服务的方法。
背景信息
大语言模型(LLM)作为自然语言处理(NLP)服务领域的核心技术,具有丰富的服务能力,但其训练数据主要涵盖普适知识和一般常识性知识,在处理特定领域(如医疗保健、金融、科技等)的知识时存在局限性。为了扩展 LLM 的知识范畴,使其能够理解并获取训练范围之外的特定领域知识,可以通过特定的提示构造来引导 LLM 在回答特定领域问题时理解意图,并根据注入的领域知识做出回答。
检索增强生成(RAG)技术融合了信息检索和语言生成模型,通过检索外部知识库中的相关信息,并将其作为提示输入给 LLM,以增强模型的逻辑推理和生成能力,从而返回更准确、全面的知识型答案。腾讯云向量数据库的 AI 套件能够解析和检索多种文本文件,包括难以处理的 PDF 图文内容,有效支持构建基于 RAG 的高质量图文知识库应用,帮助客户快速实现信息的深入理解和高效检索。
实现思路
基于腾讯云向量数据库的 AI 套件对知识库文件进行上传、拆分和向量化,将文件和向量化数据存储于数据库中。借助腾讯云向量数据库的 Embedding 功能,将用户提出的问题转化为向量,在向量数据库中进行相似性检索,找出与问题相似度最高的语料。最后,将用户提出的问题和相似性检索的上下文语料进行组装,送入 LLM 大模型,进行逻辑匹配,生成问题答案。实现方案,如下图所示。
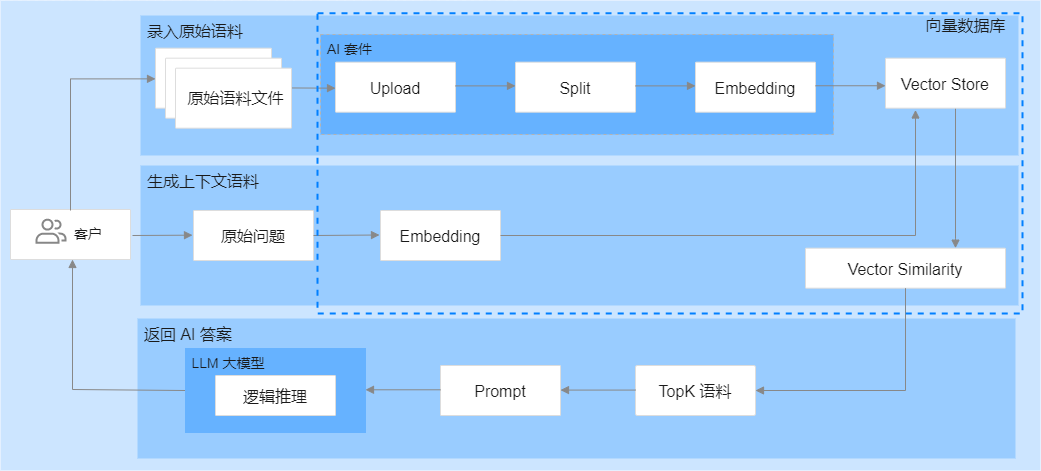
腾讯云向量数据库的 AI 套件提供了一套完整的一站式向量检索方案,包括数据切割和 Embedding 服务,无需自行编写拆分和向量化相关代码,减少了算法工程投入,极大简化了整个实现过程,降低了业务接入门槛。同时,相似性检索的上下文语料可以更有效地指导 LLM 大模型生成更精准的答案,进一步提升回答的准确性。并且,腾讯云向量数据库采用了灵活的存储策略,可根据实际变化的需求,及时优化更新知识库,保证了系统的稳定性。
LLM 大模型
腾讯云向量数据库(Tencent Cloud VectorDB)分别结合 DeepSeek、混元和百川等模型可以高效地搭建 RAG 知识问答系统。每种模型都有其独特的优势,用户可以根据具体业务需求选择合适的模型进行集成。
大模型 | 说明 |
基于 Python 代码,通过调用百川的 HTTP API 接口,并结合向量数据库,搭建一套在命令窗口内进行交互的 RAG 知识问答系统。 |



