概述
DeepSeek-R1 满血版模型参数是 671B(6710 亿参数),为了充分发挥其性能,推荐使用 SGLang 进行部署。SGLang 是性能强悍的 AI 大模型部署工具,与 DeepSeek 官方合作并专门针对 DeepSeek 进行了深度优化,也是 DeepSeek 官方推荐的部署工具。
本文将基于 SGLang 在 TKE 集群上部署满血版 DeepSeek-R1 模型,提供最佳实践的部署示例。
镜像说明:
官方镜像托管在 DockerHub,且体积较大,在 TKE 环境中,默认提供免费的 DockerHub 镜像加速服务。中国大陆用户也可以直接从 DockerHub 拉取镜像,但速度可能较慢,尤其是对于较大的镜像,等待时间会更长。为提高镜像拉取速度,建议将镜像同步至 容器镜像服务 TCR,并在 YAML 文件中替换相应的镜像地址,这样可以显著加快镜像的拉取速度。
机型与部署方案
由于满血版的 DeepSeek-R1 参数量较大,需要使用较大显存且支持 FP8 的大规格 GPU 实例,目前合适的机型规格包括 HCCPNV6.96XLARGE2304(高性能计算集群)和 PNV6.32XLARGE1280 / PNV6.96XLARGE2304(GPU 云服务器),推荐的部署方案是用两台该机型的节点组建 GPU 集群来运行满血 DeepSeek-R1,如果对并发和性能要求不高,也可以单台部署。
以下是这几种规格的核心参数:
规格 | RDMA | CPU 核心数 | 内存(GB) | GPU 卡数 |
PNV6.32XLARGE1280 | 不支持 | 128 | 1280 | 8 |
PNV6.96XLARGE2304 | 不支持 | 384 | 2304 | 8 |
HCCPNV6.96XLARGE2304 | 支持 (3.2Tbps) | 384 | 2304 | 8 |
注意:
这些规格的实例目前处于邀测阶段,且资源紧张,需联系您的销售经理开通使用并协调资源。
选型建议
两台组建 GPU 集群来运行满血 DeepSeek-R1,建议选择
HCCPNV6.96XLARGE2304,因为支持 RDMA,可显著提升 DeepSeek 运行性能,生成速度约为 600~700 token/s。单台部署无需 RDMA,优先考虑
PNV6.32XLARGE1280 和 PNV6.96XLARGE2304 以节约成本,生成速度约为 20~40 token/s。操作步骤
购买 GPU 服务器
说明:
对于 PNV6.32XLARGE1280 和 PNV6.96XLARGE2304 的这两种规格,架构选择异构计算才能看到;对于 HCCPNV6.96XLARGE2304 的规格,架构选择高性能计算集群才能看到,且要先提前创建高性能计算集群,详情请参见 创建高性能计算集群。
创建 TKE 集群
地域:选择购买的 GPU 服务器所在地域。
集群类型:选择 TKE 标准集群。
Kubernetes 版本:需要大于等于1.28(多机部署依赖的 LWS 组件的要求),建议选最新版。
VPC:选择购买的 GPU 资源所在的 VPC。
添加 GPU 节点
通过 添加已有节点 的方式将购买到的 GPU 服务器加入 TKE 集群。其中,系统镜像选择
TencentOS Server 3.1 (TK4) UEFI | img-39ywauzd,驱动和 CUDA 选择最新版本。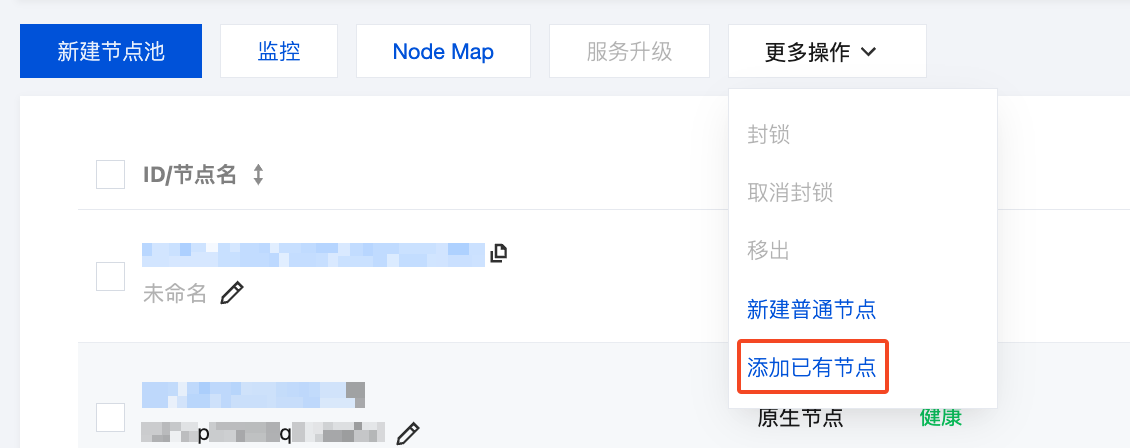
准备存储与模型文件
满血版 DeepSeek-R1 体积较大,为加快模型下载和加载速度,建议使用性能最强的存储,本文给出本地存储和 CFS-Trubo 共享存储两种方案的示例。
CFS-Turbo 共享存储
安装 CFS 插件
1. 在集群列表中,单击集群 ID,进入集群详情页。
2. 选择左侧菜单栏中的组件管理,在组件页面单击新建。
3. 在新建组件管理页面中勾选 CFSTurbo(腾讯云高性能并行文件系统)。
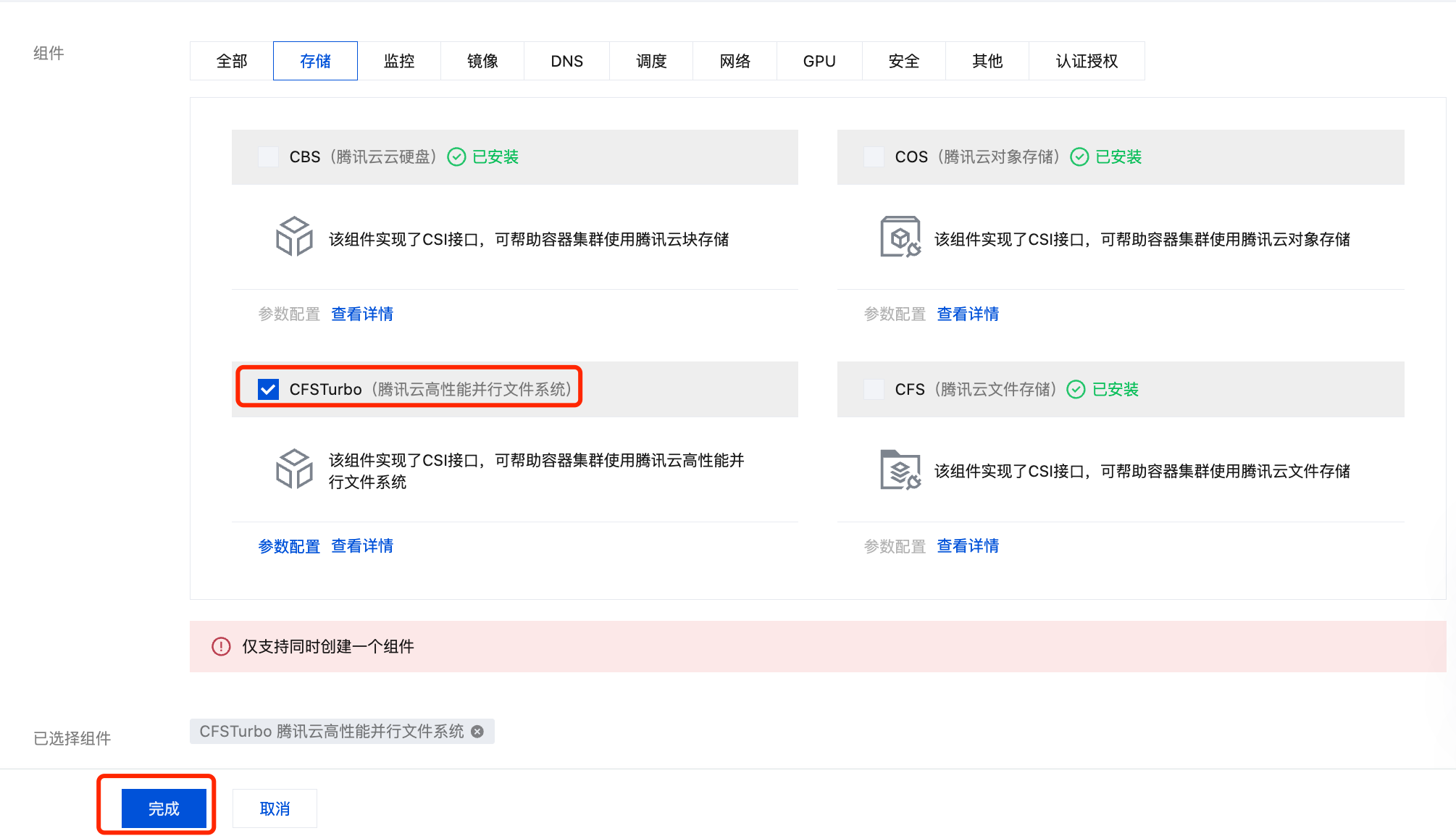
4. 单击完成即可创建组件。
创建 CFS-Turbo 实例
1. 登录 CFS 控制台,单击创建来新建一个 CFS-Turbo 实例。
2. 文件系统类型选择 Turbo 系列的:
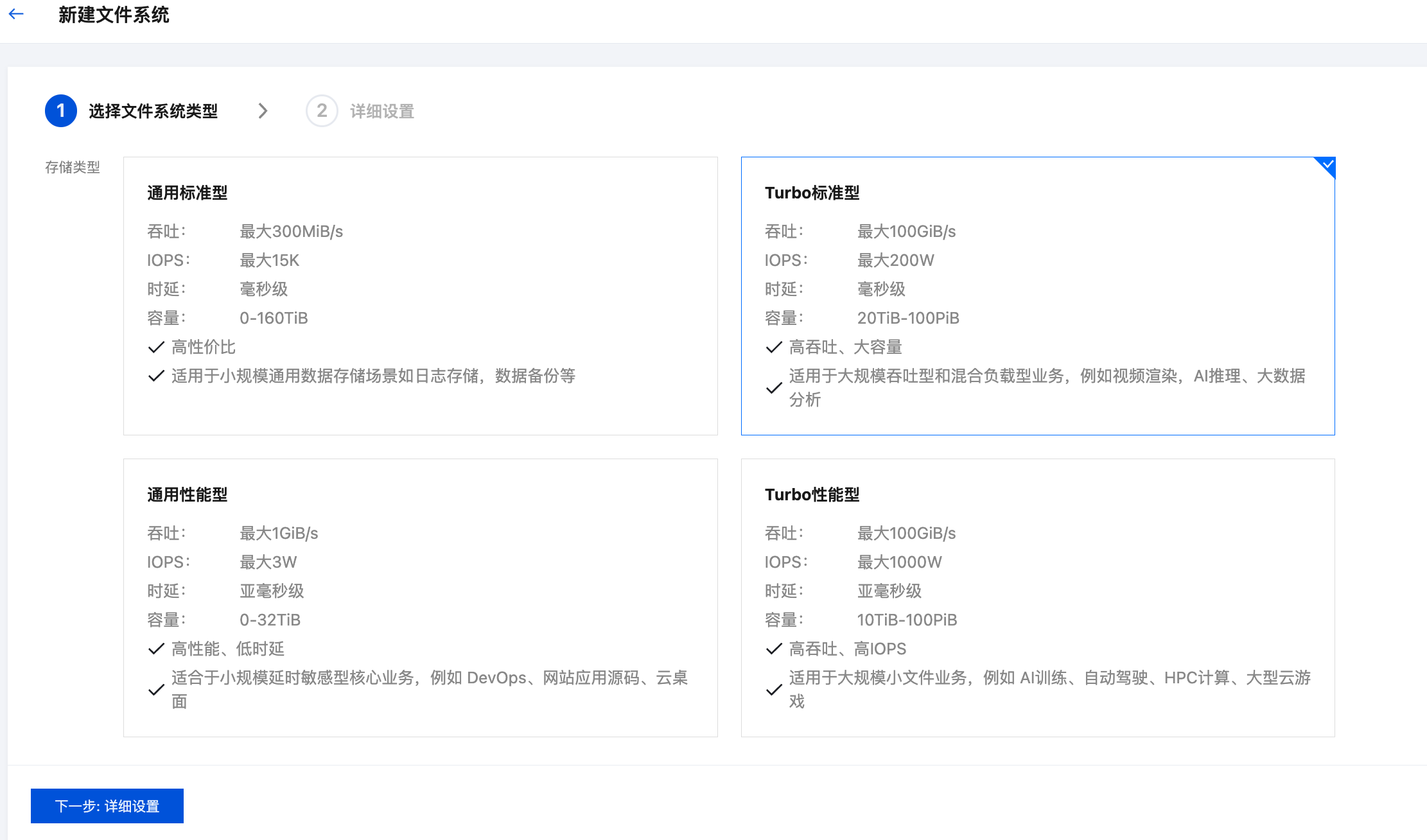
3. 地域选择 TKE 集群所在地域。
4. 可用区选择 GPU 节点池所在可用区(降低时延)。
5. 网络类型如果选云联网网络,需确保 TKE 集群所在 VPC 已加入该云联网中;如果选VPC 网络,则需选择 TKE 集群所在 VPC,子网选与 GPU 节点池在同一个可用区的子网。
6. 单击立即创建。
新建 StorageClass
新建一个后续使用 CFS 存储大模型的 PVC,可通过控制台或 YAML 创建。
1. 在集群列表中,单击集群 ID,进入集群详情页。
2. 选择左侧菜单栏中的存储,在 StorageClass 页面单击新建。
3. 在新建存储页面,根据实际需求,创建 CFS-Turbo 类型的 StorageClass。如下图所示:
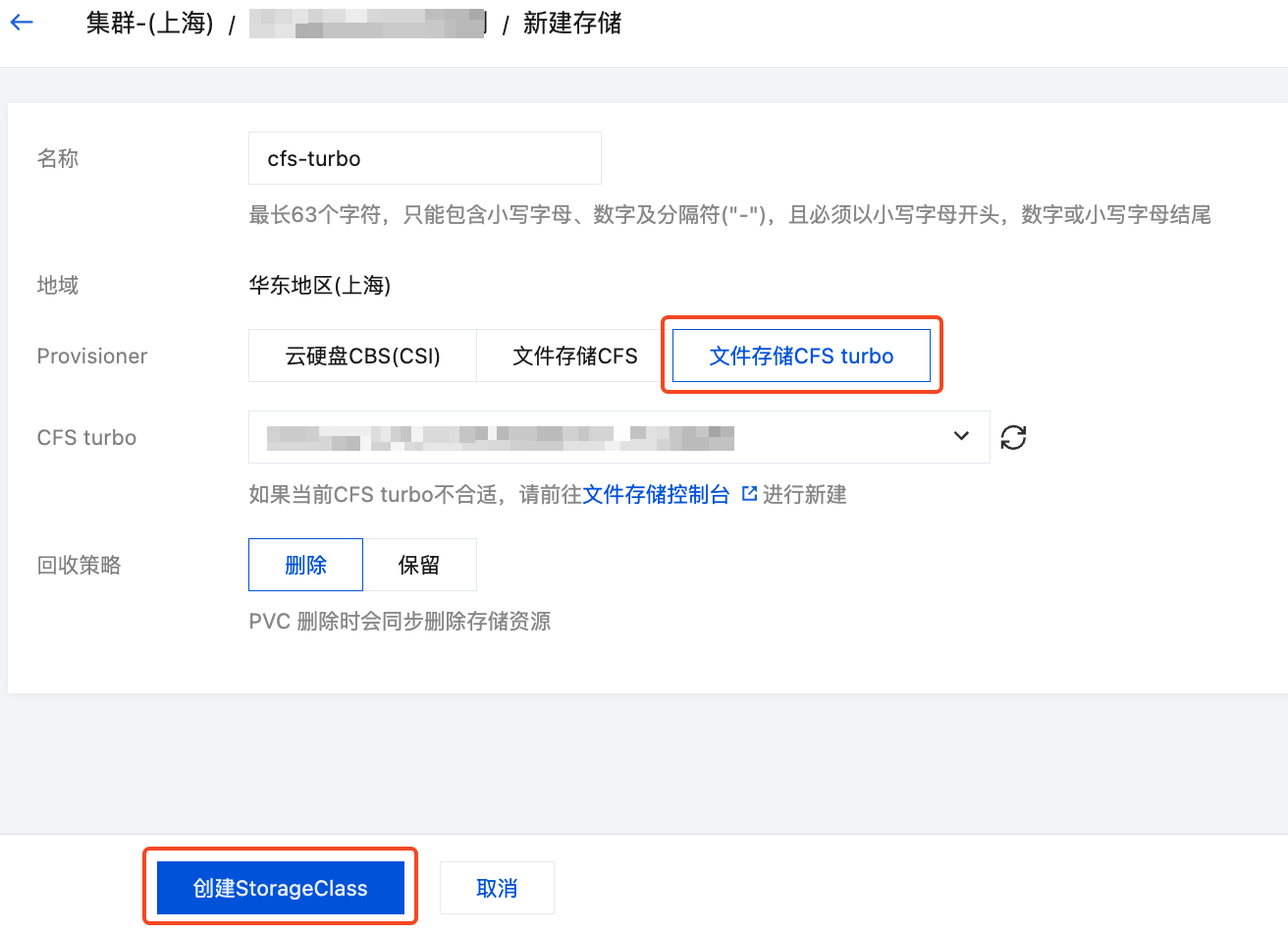
名称:请输入 StorageClass 名称,本文以 “cfs-turbo” 为例。
Provisioner:选择 “文件存储CFS turbo”。
CFS turbo:选择前面创建 CFS-Turbo 实例步骤中创建出来的 CFS-Turbo 的实例。
注意:
fsid 替换为前面步骤新建的 CFS-Turbo 实例的挂载点 ID(在实例的挂载点信息页面可查看,注意不是 cfs-xxx 的 ID)。host 替换为前面步骤新建的 CFS-Turbo 实例的IPv4地址(同样也在挂载点信息页面可查看)。apiVersion: storage.k8s.io/v1kind: StorageClassmetadata:name: cfs-turboprovisioner: com.tencent.cloud.csi.cfsturboreclaimPolicy: DeletevolumeBindingMode: Immediateparameters: # 注意替换 fsid 和 hostfsid: 564b8ef1host: 11.0.0.7
创建 PVC
创建一个使用 CFS-Turbo 的 PVC,用于存储 AI 大模型,可通过控制台或 YAML 创建。
1. 在集群列表中,单击集群 ID,进入集群详情页。
2. 选择左侧菜单栏中的存储,在 PersistentVolumeClaim 页面单击新建。
3. 在新建存储页面,创建存储大模型的 PVC。如下图所示:
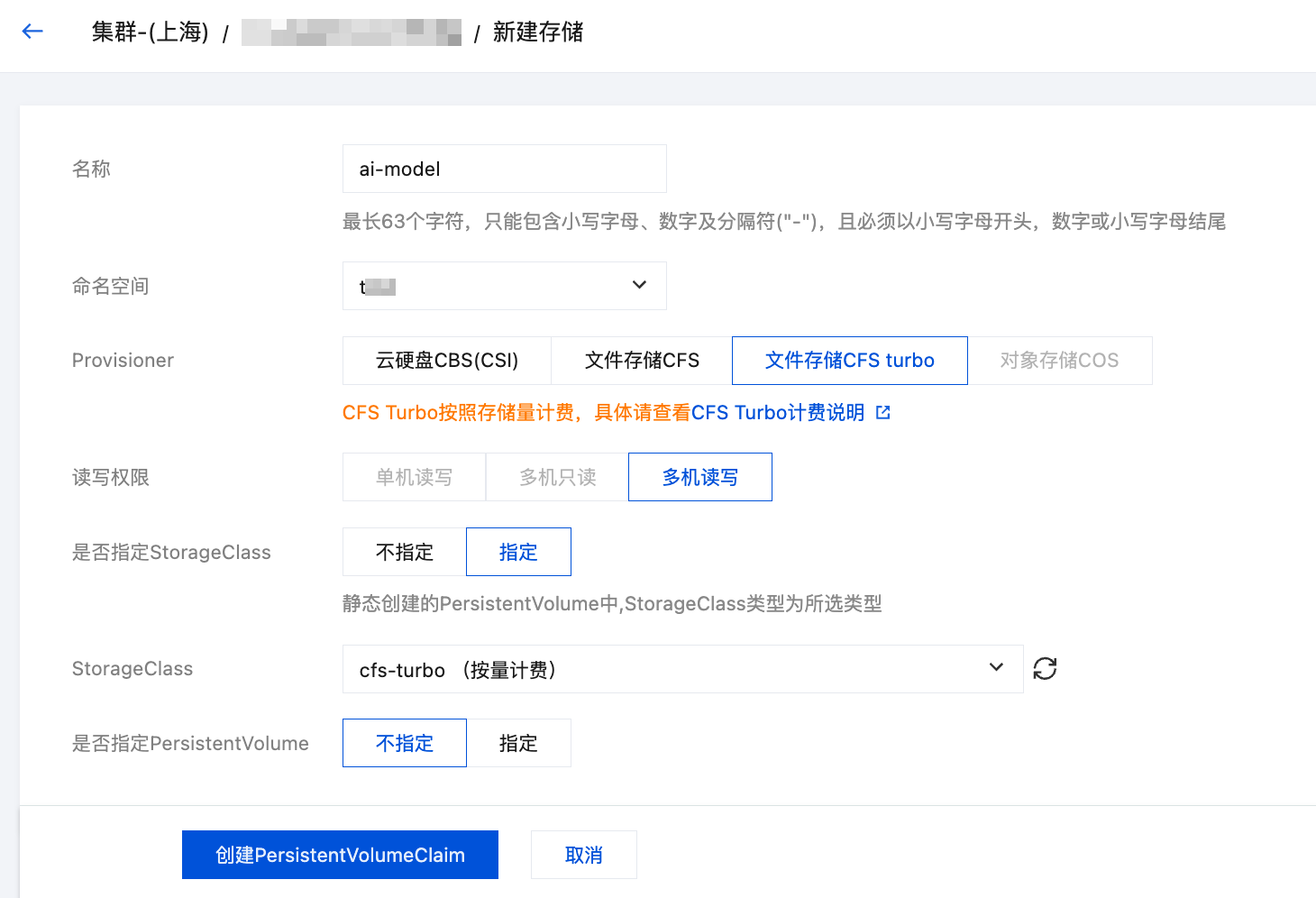
名称:请输入 PVC 名称,本文以 “ai-model” 为例。
命名空间:SGLang 将要被部署的命名空间。
Provisioner:选择 “文件存储 CFS turbo”。
是否指定 StorageClass:选择 “指定”。
StorageClass:选择前面新建的 StorageClass 的名称。
是否指定 PersistentVolume:选择 “不指定”。
注意:
注意替换
storageClassName 为新建 StorageClass 步骤中配置的名称。apiVersion: v1kind: PersistentVolumeClaimmetadata:name: ai-modellabels:app: ai-modelspec:storageClassName: cfs-turboaccessModes:- ReadWriteManyresources:requests:storage: 700Gi
使用 Job 下载大模型文件
创建一个 Job 用于下载大模型文件到 CFS:
注意:
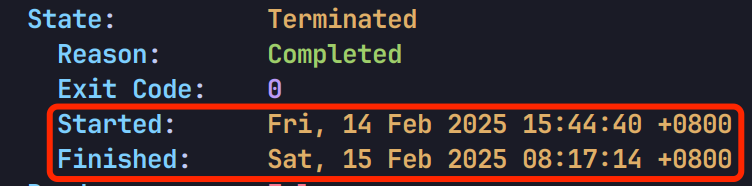
满血版的 DeepSeek-R1 是 671B 的大模型,一共 642G,下载耗时可能较长,实测在上海下载 ModelScope 上的模型文件,100Mbps 的云服务器带宽,耗时 16 个多小时:
apiVersion: batch/v1kind: Jobmetadata:name: download-modellabels:app: download-modelspec:template:metadata:name: sglanglabels:app: download-modelspec:containers:- name: sglangimage: lmsysorg/sglang:latestcommand:- modelscope- download- --local_dir=/data/model/DeepSeek-R1- --model=deepseek-ai/DeepSeek-R1volumeMounts:- name: datamountPath: /data/modelvolumes:- name: datapersistentVolumeClaim:claimName: ai-modelrestartPolicy: OnFailure
CFS-Turbo 的 PVC 挂载到
/data 目录,存储下载的模型文件。--local_dir 指定模型文件下载目录。--model 指定 ModelScope 模型库 中的模型名称,满血版的 DeepSeek-R1 模型名称为 deepseek-ai/DeepSeek-R1。本地存储
如果使用本地存储大模型,可以创建一个下载模型文件的 DaemonSet,相当于给每个节点都下发一个下载 Job:
apiVersion: apps/v1kind: DaemonSetmetadata:name: download-modellabels:app: download-modelspec:selector:matchLabels:app: download-modeltemplate:metadata:labels:app: download-modelspec:restartPolicy: OnFailure # 默认 Always,改成 OnFailure 避免重复下载nodeSelector:nvidia-device-enable: "true" # 只让 GPU 节点下载containers:- name: sglangimage: lmsysorg/sglang:latestcommand:- modelscope- download- --local_dir=/data/model/DeepSeek-R1- --model=deepseek-ai/DeepSeek-R1volumeMounts:- name: modelmountPath: /data/modelvolumes:- name: modelhostPath:path: /data/modeltype: DirectoryOrCreate
安装 LWS 组件
注意:
如果只使用单机部署的方案,无需安装 LWS 组件,可跳过此步骤。
安装到集群中:
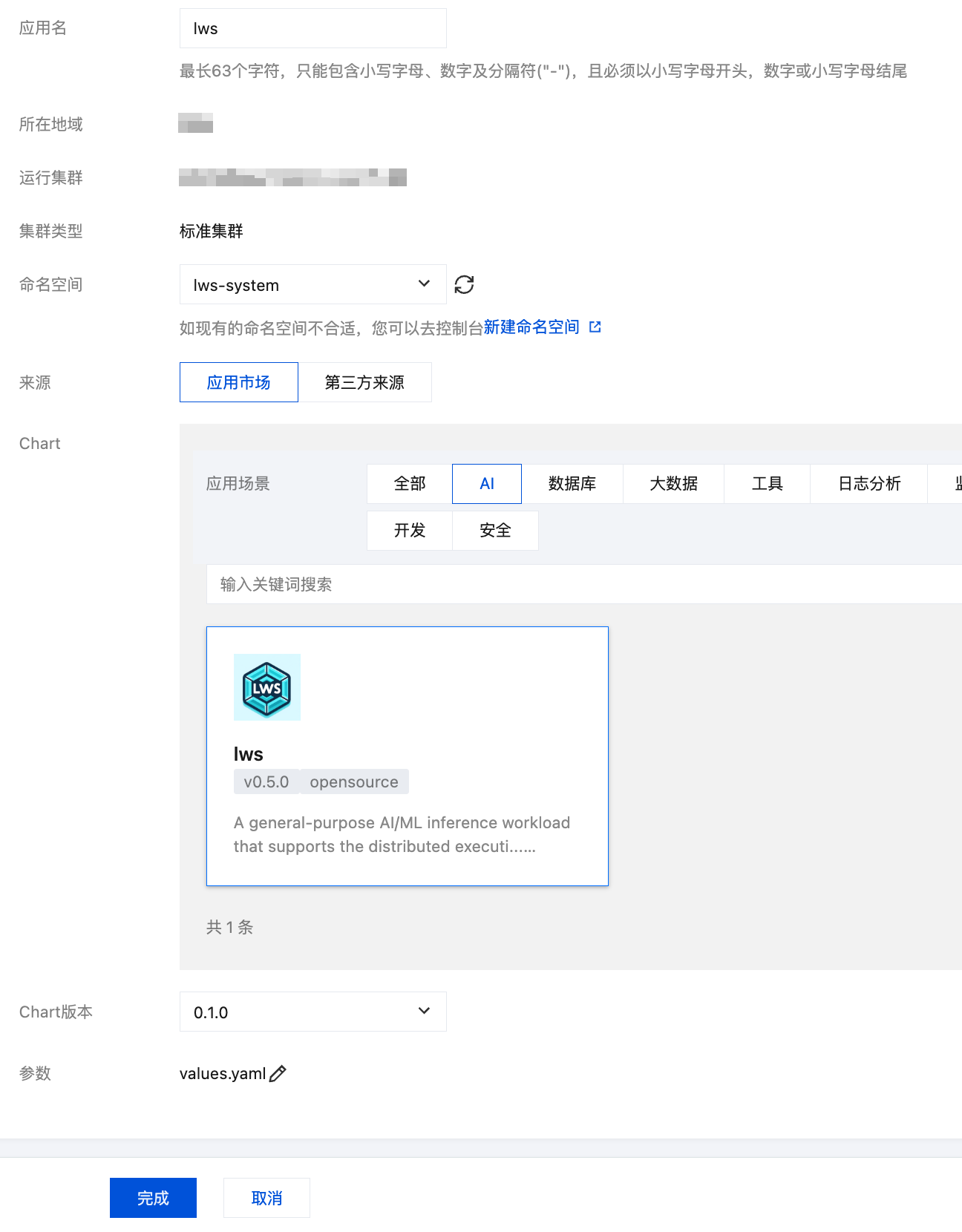
应用名:建议填
lws。命名空间:建议使用
lws-system(新建命名空间)。说明:
需要注意的是,官方默认使用镜像是
registry.k8s.io/lws/lws,该镜像在中国大陆环境无法直接下载,可替换镜像地址为 docker.io/k8smirror/lws,该镜像为 lws 在 DockerHub 上的 mirror 镜像,长期自动同步,可放心使用(TKE 环境可直接拉取 DockerHub 的镜像),也可以同步到自己的 TCR 或 CCR 镜像仓库,提高镜像下载速度。部署 DeepSeek-R1
使用本文指定的机型,每台有 8 张 GPU 算卡,单机部署也能成功运行,如果并发和吞吐要求较高,建议使用双机集群部署。
下面提供单机和双机两种部署方式的示例。
双机集群部署
使用
LeaderWorkerSet 部署满血版的 DeepSeek-R1 双机集群(2 台 8 卡的 GPU 节点,1 个 leader 和 1 个 worker):apiVersion: leaderworkerset.x-k8s.io/v1kind: LeaderWorkerSetmetadata:name: deepseek-r1spec:replicas: 1leaderWorkerTemplate:size: 2restartPolicy: RecreateGroupOnPodRestartleaderTemplate:metadata:labels:role: leaderspec:hostNetwork: true # 如果使用 HCCPNV6 机型,支持 RDMA,需要使用 HostNetwork 才能让 RDMA 生效。hostPID: truednsPolicy: ClusterFirstWithHostNet # 如果使用 HostNetwork,默认使用节点上 /etc/resolv.conf 中的 dns server,会导致 LWS_LEADER_ADDRESS 指定的域名解析失败,所以 dnsPolicy 指定为 ClusterFirstWithHostNet 以便使用 coredns 解析。containers:- name: leaderimage: lmsysorg/sglang:latestenv:- name: LWS_WORKER_INDEXvalueFrom:fieldRef:fieldPath: metadata.labels['leaderworkerset.sigs.k8s.io/worker-index']- name: TOTAL_GPUvalue: "16"- name: MODEL_DIRECTORYvalue: "DeepSeek-R1"- name: MODEL_NAMEvalue: "DeepSeek-R1"- name: API_KEYvalue: ""command:- bash- -c- |set -xMODEL_DIRECTORY="${MODEL_DIRECTORY:-MODEL_NAME}"EXTRA_ARGS=""if [[ "$API_KEY" != "" ]]; thenEXTRA_ARGS="--api-key $API_KEY"fiexec python3 -m sglang.launch_server \\--model-path /data/model/$MODEL_DIRECTORY \\--served-model-name $MODEL_NAME \\--nnodes $LWS_GROUP_SIZE \\--tp $TOTAL_GPU \\--node-rank $LWS_WORKER_INDEX \\--dist-init-addr $LWS_LEADER_ADDRESS:5000 \\--log-requests \\--enable-metric \\--allow-auto-truncate \\--watchdog-timeout 3600 \\--disable-custom-all-reduce \\--trust-remote-code \\--host 0.0.0.0 \\--port 30000 $EXTRA_ARGSresources:limits:nvidia.com/gpu: "8" # 每台节点 8 张 GPU 卡,每个 Pod 独占 1 台节点。ports:- containerPort: 30000volumeMounts:- mountPath: /dev/shmname: dshm- mountPath: /data/modelname: datavolumes:- name: dshmemptyDir:medium: Memory- name: datapersistentVolumeClaim:claimName: ai-modelworkerTemplate:spec:hostNetwork: true # worker 与 master 保持一致hostPID: truednsPolicy: ClusterFirstWithHostNet # worker 与 master 保持一致containers:- name: workerimage: lmsysorg/sglang:latestenv:- name: LWS_WORKER_INDEXvalueFrom:fieldRef:fieldPath: metadata.labels['leaderworkerset.sigs.k8s.io/worker-index']- name: TOTAL_GPUvalue: "16"- name: MODEL_DIRECTORYvalue: "DeepSeek-R1"- name: MODEL_NAMEvalue: "DeepSeek-R1"command:- bash- -c- |set -xMODEL_DIRECTORY="${MODEL_DIRECTORY:-MODEL_NAME}"exec python3 -m sglang.launch_server \\--model-path /data/model/$MODEL_DIRECTORY \\--served-model-name $MODEL_NAME \\--nnodes $LWS_GROUP_SIZE \\--tp $TOTAL_GPU \\--node-rank $LWS_WORKER_INDEX \\--dist-init-addr $LWS_LEADER_ADDRESS:5000 \\--log-requests \\--enable-metric \\--allow-auto-truncate \\--watchdog-timeout 3600 \\--disable-custom-all-reduce \\--trust-remote-coderesources:limits:nvidia.com/gpu: "8" # 每台节点 8 张 GPU 卡,每个 Pod 独占 1 台节点。volumeMounts:- mountPath: /dev/shmname: dshm- mountPath: /data/modelname: datavolumes:- name: dshmemptyDir:medium: Memory- name: datapersistentVolumeClaim:claimName: ai-model---apiVersion: v1kind: Servicemetadata:name: deepseek-r1-apispec:type: ClusterIPselector:leaderworkerset.sigs.k8s.io/name: deepseek-r1role: leaderports:- name: apiprotocol: TCPport: 30000targetPort: 30000
apiVersion: leaderworkerset.x-k8s.io/v1kind: LeaderWorkerSetmetadata:name: deepseek-r1spec:replicas: 1leaderWorkerTemplate:size: 2restartPolicy: RecreateGroupOnPodRestartleaderTemplate:metadata:labels:role: leaderspec:hostNetwork: true # 如果使用 HCCPNV6 机型,支持 RDMA,需要使用 HostNetwork 才能让 RDMA 生效。hostPID: truednsPolicy: ClusterFirstWithHostNet # 如果使用 HostNetwork,默认使用节点上 /etc/resolv.conf 中的 dns server,会导致 LWS_LEADER_ADDRESS 指定的域名解析失败,所以 dnsPolicy 指定为 ClusterFirstWithHostNet 以便使用 coredns 解析。containers:- name: leaderimage: lmsysorg/sglang:latestenv:- name: LWS_WORKER_INDEXvalueFrom:fieldRef:fieldPath: metadata.labels['leaderworkerset.sigs.k8s.io/worker-index']- name: TOTAL_GPUvalue: "16"- name: MODEL_DIRECTORYvalue: "DeepSeek-R1"- name: MODEL_NAMEvalue: "DeepSeek-R1"- name: API_KEYvalue: ""command:- bash- -c- |set -xMODEL_DIRECTORY="${MODEL_DIRECTORY:-MODEL_NAME}"EXTRA_ARGS=""if [[ "$API_KEY" != "" ]]; thenEXTRA_ARGS="--api-key $API_KEY"fiexec python3 -m sglang.launch_server \\--model-path /data/model/$MODEL_DIRECTORY \\--served-model-name $MODEL_NAME \\--nnodes $LWS_GROUP_SIZE \\--tp $TOTAL_GPU \\--node-rank $LWS_WORKER_INDEX \\--dist-init-addr $LWS_LEADER_ADDRESS:5000 \\--log-requests \\--enable-metric \\--allow-auto-truncate \\--watchdog-timeout 3600 \\--disable-custom-all-reduce \\--trust-remote-code \\--host 0.0.0.0 \\--port 30000 $EXTRA_ARGSresources:limits:nvidia.com/gpu: "8" # 每台节点 8 张 GPU 卡,每个 Pod 独占 1 台节点。ports:- containerPort: 30000volumeMounts:- mountPath: /dev/shmname: dshm- mountPath: /data/modelname: datavolumes:- name: dshmemptyDir:medium: Memory- name: datapersistentVolumeClaim:claimName: ai-modelworkerTemplate:spec:hostNetwork: true # worker 与 master 保持一致hostPID: truednsPolicy: ClusterFirstWithHostNet # worker 与 master 保持一致containers:- name: workerimage: lmsysorg/sglang:latestenv:- name: LWS_WORKER_INDEXvalueFrom:fieldRef:fieldPath: metadata.labels['leaderworkerset.sigs.k8s.io/worker-index']- name: TOTAL_GPUvalue: "16"- name: MODEL_DIRECTORYvalue: "DeepSeek-R1"- name: MODEL_NAMEvalue: "DeepSeek-R1"command:- bash- -c- |set -xMODEL_DIRECTORY="${MODEL_DIRECTORY:-MODEL_NAME}"exec python3 -m sglang.launch_server \\--model-path /data/model/$MODEL_DIRECTORY \\--served-model-name $MODEL_NAME \\--nnodes $LWS_GROUP_SIZE \\--tp $TOTAL_GPU \\--node-rank $LWS_WORKER_INDEX \\--dist-init-addr $LWS_LEADER_ADDRESS:5000 \\--log-requests \\--enable-metric \\--allow-auto-truncate \\--watchdog-timeout 3600 \\--disable-custom-all-reduce \\--trust-remote-coderesources:limits:nvidia.com/gpu: "8" # 每台节点 8 张 GPU 卡,每个 Pod 独占 1 台节点。volumeMounts:- mountPath: /dev/shmname: dshm- mountPath: /data/modelname: datavolumes:- name: dshmemptyDir:medium: Memory- name: datahostPath:path: /data/modeltype: DirectoryOrCreate---apiVersion: v1kind: Servicemetadata:name: deepseek-r1-apispec:type: ClusterIPselector:leaderworkerset.sigs.k8s.io/name: deepseek-r1role: leaderports:- name: apiprotocol: TCPport: 30000targetPort: 30000
说明:
nvidia.com/gpu 为单机 GPU 卡数,本文示例中为 8 卡(leader 和 worker 保持一致)。leaderWorkerTemplate.size 为单个 GPU 集群的节点数,2 表示两个节点组成的 GPU 集群(1 个 leader 和 1 个 worker)。replicas 为 GPU 集群数量,这里是 1 个 GPU 集群,如需扩容,准备好节点资源后,调整此数量即可。TOTAL_GPU 为单个 GPU 集群的 GPU 总卡数(节点数量 * 单机 GPU 卡数),本文示例中为 16 卡。MODEL_DIRECTORY 为模型文件的子目录路径。MODEL_NAME 为模型名称,API 调用将使用此模型名称进行交互。leader 和 worker 的环境变量需一致,如需调整记得将 leader 和 worker 的 template 都做相同的修改。
如果使用支持 RDMA 的机型,需使用 HostNetwork 才能让 RDMA 生效。
Service 中
leaderworkerset.sigs.k8s.io/name 指定的是 lws 的名称。涉及 OpenAI API 地址配置的地方(如 OpenWebUI),指向这个 Service 的地址(如
http://deepseek-r1-api:30000/v1)。部署完成后,如果需要扩容,可以通过调高
replicas 来增加 GPU 集群数量(前提是已准备好新的 GPU 节点资源)。单机部署
使用
Deployment 部署单机满血版的 DeepSeek-R1:apiVersion: apps/v1kind: Deploymentmetadata:name: deepseek-r1labels:app: deepseek-r1spec:selector:matchLabels:app: deepseek-r1replicas: 1strategy:type: Recreatetemplate:metadata:labels:app: deepseek-r1spec:containers:- name: sglangimage: lmsysorg/sglang:latestenv:- name: TOTAL_GPUvalue: "8"- name: MODEL_DIRECTORYvalue: "DeepSeek-R1"- name: MODEL_NAMEvalue: "DeepSeek-R1"- name: API_KEYvalue: ""command:- bash- -c- |set -xMODEL_DIRECTORY="${MODEL_DIRECTORY:-MODEL_NAME}"EXTRA_ARGS=""if [[ "$API_KEY" != "" ]]; thenEXTRA_ARGS="--api-key $API_KEY"fiexec python3 -m sglang.launch_server \\--model-path /data/model/$MODEL_DIRECTORY \\--served-model-name $MODEL_NAME \\--tp $TOTAL_GPU \\--log-requests \\--enable-metric \\--allow-auto-truncate \\--watchdog-timeout 3600 \\--disable-custom-all-reduce \\--trust-remote-code \\--mem-fraction-static 0.9 \\--max-running-request 8 \\--host 0.0.0.0 \\--port 30000 $EXTRA_ARGSresources:limits:nvidia.com/gpu: "8"ports:- containerPort: 30000readinessProbe:httpGet:path: /healthport: 30000periodSeconds: 5volumeMounts:- name: datamountPath: /data/model- name: shmmountPath: /dev/shmvolumes:- name: datapersistentVolumeClaim:claimName: ai-model- name: shmemptyDir:medium: MemoryrestartPolicy: Always---apiVersion: v1kind: Servicemetadata:name: deepseek-r1-apispec:type: ClusterIPselector:app: deepseek-r1ports:- name: apiprotocol: TCPport: 30000targetPort: 30000
apiVersion: apps/v1kind: Deploymentmetadata:name: deepseek-r1labels:app: deepseek-r1spec:selector:matchLabels:app: deepseek-r1replicas: 1strategy:type: Recreatetemplate:metadata:labels:app: deepseek-r1spec:containers:- name: sglangimage: lmsysorg/sglang:latestenv:- name: TOTAL_GPUvalue: "8"- name: MODEL_DIRECTORYvalue: "DeepSeek-R1"- name: MODEL_NAMEvalue: "DeepSeek-R1"- name: API_KEYvalue: ""command:- bash- -c- |set -xMODEL_DIRECTORY="${MODEL_DIRECTORY:-MODEL_NAME}"EXTRA_ARGS=""if [[ "$API_KEY" != "" ]]; thenEXTRA_ARGS="--api-key $API_KEY"fiexec python3 -m sglang.launch_server \\--model-path /data/model/$MODEL_DIRECTORY \\--served-model-name $MODEL_NAME \\--tp $TOTAL_GPU \\--log-requests \\--enable-metric \\--allow-auto-truncate \\--watchdog-timeout 3600 \\--disable-custom-all-reduce \\--trust-remote-code \\--mem-fraction-static 0.9 \\--max-running-request 8 \\--host 0.0.0.0 \\--port 30000 $EXTRA_ARGSresources:limits:nvidia.com/gpu: "8"ports:- containerPort: 30000readinessProbe:httpGet:path: /healthport: 30000periodSeconds: 5volumeMounts:- name: datamountPath: /data/model- name: shmmountPath: /dev/shmvolumes:- name: datahostPath:path: /data/modeltype: DirectoryOrCreate- name: shmemptyDir:medium: MemoryrestartPolicy: Always---apiVersion: v1kind: Servicemetadata:name: deepseek-r1-apispec:type: ClusterIPselector:app: deepseek-r1ports:- name: apiprotocol: TCPport: 30000targetPort: 30000
说明:
nvidia.com/gpu 和 TOTAL_GPU 都是单机 GPU 卡数,本文示例中为 8 卡。replicas 为 DeepSeek-R1 副本数,1 个副本占用 1 台 GPU 节点。MODEL_DIRECTORY 为模型文件的子目录路径。MODEL_NAME 为模型名称,API 调用将使用此模型名称进行交互。由于是单机部署,无需 RDMA,也无需使用 HostNetwork。
单机部署配置了
--mem-fraction-static和 --max-running-request 参数,用于避免显存不足导致 SGLang 启动失败。涉及 OpenAI API 地址配置的地方(如 OpenWebUI),指向这里创建的 Service 的地址(如
http://deepseek-r1-api:30000/v1)。部署完成后,如果需要扩容,可以通过调高
replicas 来增加 DeepSeek-R1 副本数(前提是准备好新的 GPU 节点资源)。验证 API
Pod 成功跑起来后用 kubectl exec 进入 leader Pod,使用 curl 测试 API:
curl -v http://127.0.0.1:30000/v1/completions -H 'X-API-Key: ******' -H "Content-Type: application/json" -d '{"model": "DeepSeek-R1","prompt": "你是谁?","max_tokens": 100,"temperature": 0}'
常见问题
如何对外暴露 API ?
通常对外暴露 API 一般会配置 API 密钥,配置方法是修改本文示例中的 YAML,将密钥配置到
API_KEY 环境变量中。如果希望将 API 对外暴露,最简单的是直接修改 DeepSeek 的 Service 类型为 LoadBalancer,TKE 会自动为其创建公网 CLB 将 API 暴露到公网:
apiVersion: v1kind: Servicemetadata:name: deepseek-r1-apispec:type: LoadBalancerselector:leaderworkerset.sigs.k8s.io/name: deepseek-r1role: leaderports:- name: apiprotocol: TCPport: 30000targetPort: 30000
apiVersion: v1kind: Servicemetadata:name: deepseek-r1-apispec:type: LoadBalancerselector:app: deepseek-r1ports:- name: apiprotocol: TCPport: 30000targetPort: 30000
如果需要更灵活的方式暴露,例如配置证书通过 HTTPS 协议暴露,或者与其他服务共用网关入口,可以通过 Ingress 或 Gateway API 来暴露,示例:
注意:
apiVersion: gateway.networking.k8s.io/v1kind: HTTPRoutemetadata:name: deepseek-apispec:parentRefs:- group: gateway.networking.k8s.iokind: Gatewaynamespace: envoy-gateway-systemname: deepseekhostnames:- "deepseek.your.domain"rules:- backendRefs:- group: ""kind: Servicename: deepseek-r1-apiport: 30000
说明:
1.
parentRefs 引用定义好的 Gateway(通常一个 Gateway 对应一个 CLB)。2.
hostnames 替换为您自己的域名,确保域名能正常解析到 Gateway 对应的 CLB 地址。3.
backendRefs 指定 DeepSeek 的 Service。apiVersion: networking.k8s.io/v1kind: Ingressmetadata:name: deepseek-apispec:rules:- host: "deepseek.your.domain"http:paths:- path: /pathType: Prefixbackend:service:name: deepseek-r1-apiport:number: 30000
说明:
1.
host 替换为您自己的域名,确保域名能正常解析到 Ingress 对应的 CLB 地址。2.
backend.service 指定 DeepSeek 的 Service。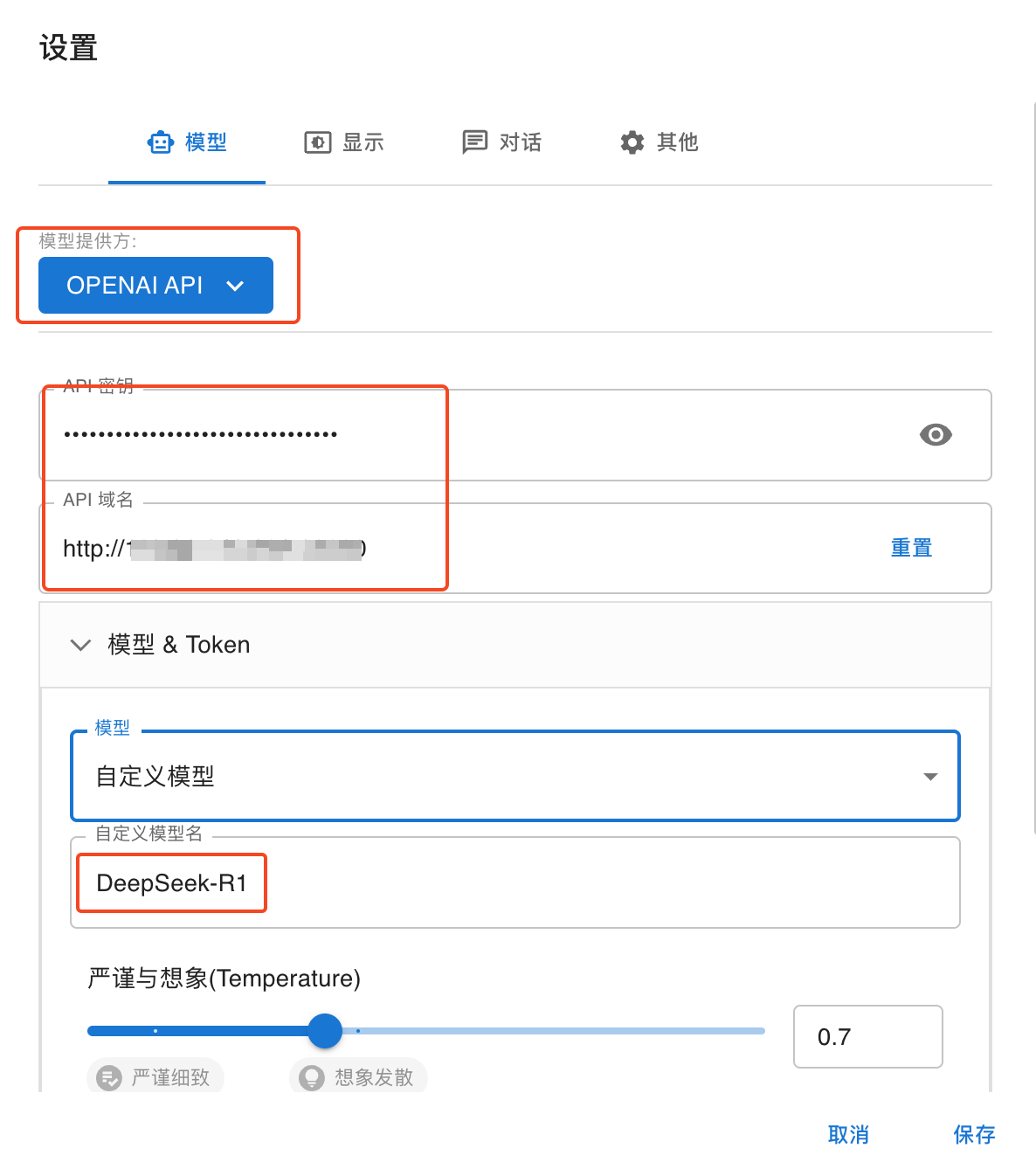
说明:
模型提供方: 由于 SGLang 兼容 OpenAI 的 API,所以选择 OPENAI API。
API 密钥:填写 DeepSeek-R1 部署时指定的 API KEY(
API_KEY 环境变量)。API 域名:用 DeepSeek-R1 最终被暴露出来的外部地址。
模型:填写 DeepSeek-R1 部署时指定的模型名称(
MODEL_NAME 环境变量)。如何使用 OpenWebUI 与模型对话?
SGLang 提供了兼容 OpenAI 的 API,部署 OpenWebUI 时,如不需要 Ollama API 可禁用掉,再配置下 OpenAI 的 API 地址,指向 DeepSeek-R1 的地址即可。
ollama:enabled: falseopenaiBaseApiUrl: "http://deepseek-r1:30000/api/v1"
如果通过 YAML 部署 OpenWebUI,需配置下 Pod 环境变量,示例:
env:- name: OPENAI_API_BASE_URLvalue: http://deepseek-r1:30000/api/v1 # vllm 的地址- name: ENABLE_OLLAMA_API # 禁用 Ollama API,只保留 OpenAI APIvalue: "False"



