概述
本文介绍容器服务 TKE 的日志功能,包括日志采集、存储、查询等功能的使用方法,并结合实际应用场景给出建议。您可结合自身业务实际,参考本文开展日志采集实践。
说明:
技术架构
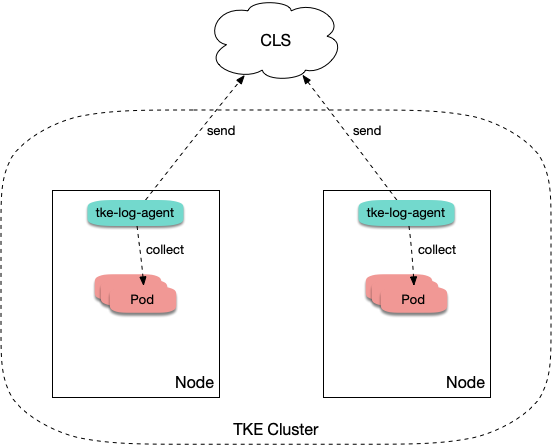
TKE 集群开启日志采集后,tke-log-agent 作为 DaemonSet 部署在每个节点上。该组件根据采集规则采集节点上容器的日志,并上报至日志服务 CLS,由 CLS 进行统一存储、检索与分析。示意图如下:
采集类型使用场景
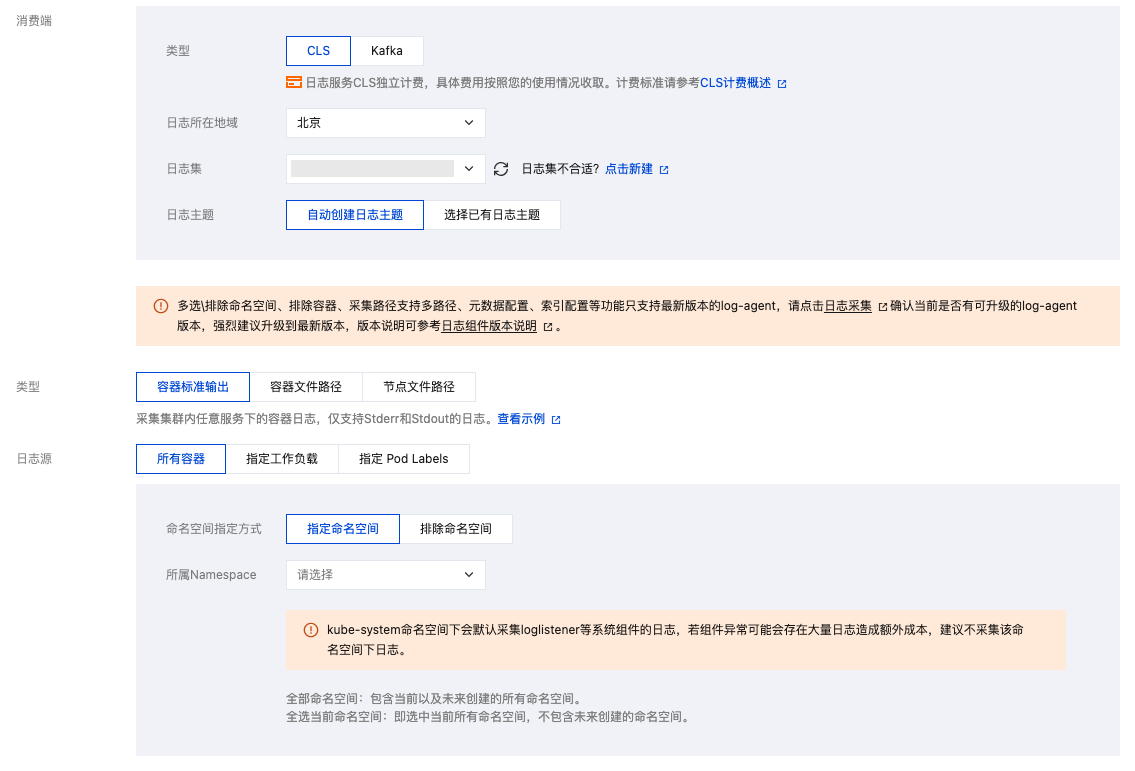
在使用 TKE 日志采集功能时,需要在新建日志采集规则时确定采集的目标数据源。TKE 支持三种采集类型:采集标准输出、采集容器内文件和采集宿主机文件。请参考下文了解各类型使用场景及建议:
采集标准输出
采集标准输出是将 Pod 内容器日志输出到标准输出,日志内容由容器运行时(docker 或 containerd)管理。此方式最简单,推荐选择。具备以下优势:
不需要额外挂载 volume。
可直接通过
kubectl logs 查看日志内容。 业务无需关注日志轮转,容器运行时会对日志进行存储和自动轮转,避免因个别 Pod 日志量大将磁盘写满。
无需关注日志文件路径,可以使用较统一的采集规则,用更少的采集规则数量覆盖更多的工作负载,减少运维复杂度。
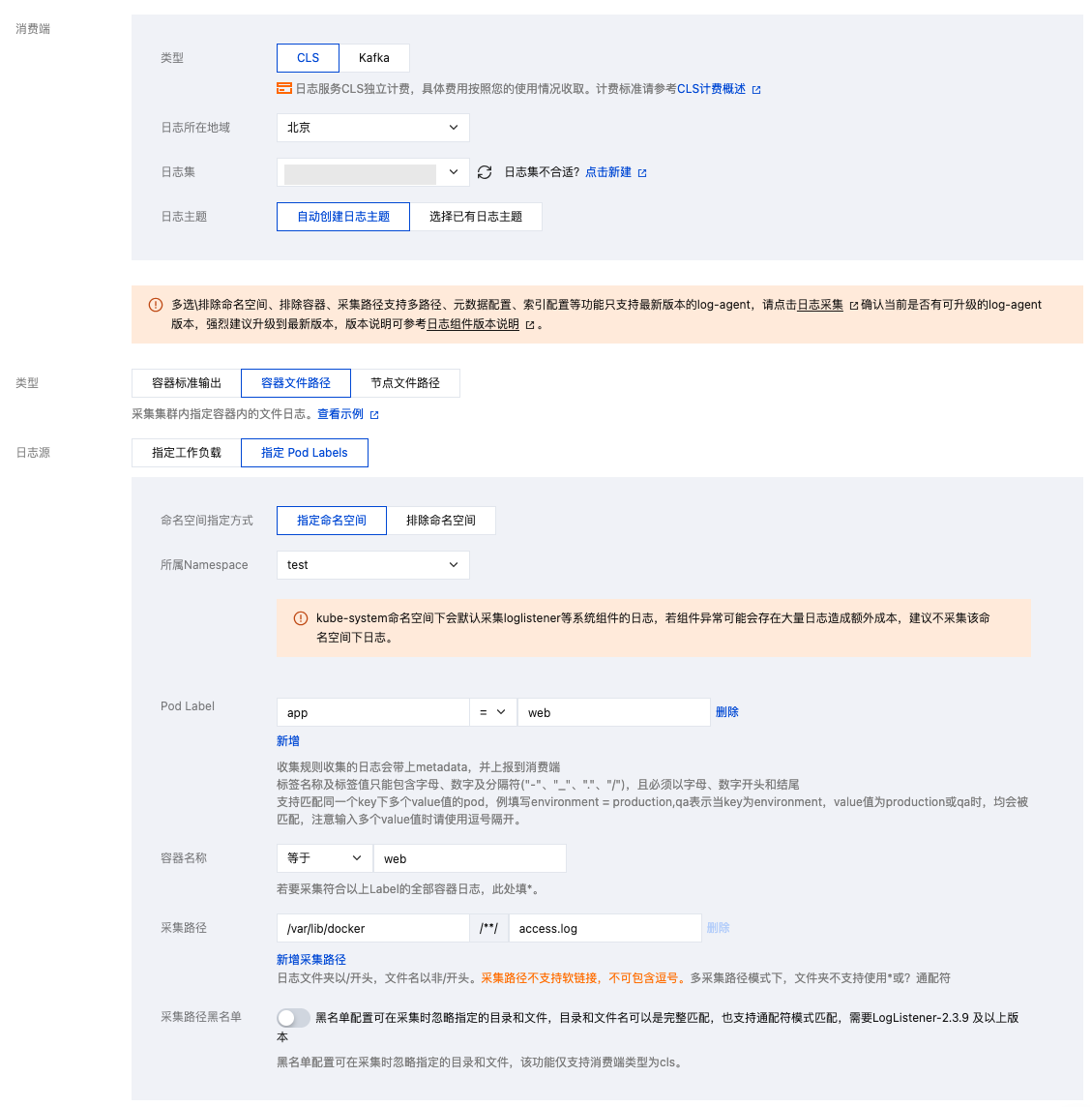
采集容器内的文件
通常业务会使用写日志文件的方式来记录日志,当使用容器运行业务时,日志文件被写在容器内。请了解以下事项:
若日志文件所在路径未挂载 volume:日志文件会被写入容器可写层,落盘到容器数据盘里,通常路径是
/var/lib/docker。建议挂载 volume 至该路径,避免与系统盘混用。容器停止后日志会被清理。 若日志文件所在路径已挂载 volume:日志文件会落盘到对应 volume 类型的后端存储,通常用 emptyDir。容器停止后日志会被清理,运行期间日志文件会落盘到宿主机的
/var/lib/kubelet 路径下,此路径通常没有单独挂盘,即会使用系统盘。由于使用了日志采集功能,有统一存储的能力,不推荐再挂载其它持久化存储来存日志文件(例如云硬盘 CBS、对象存储 COS 或共享存储 CFS)。大部分开源日志采集器需给 Pod 日志文件路径挂载 volume 后才可采集,而 TKE 的日志采集无需挂载。若将日志输出到容器内的文件,则无需关注是否挂载 volume。采集配置示例如下图所示,如何配置请参见 采集容器内文件日志。
采集宿主机上的文件
若业务需将日志写入日志文件,但期望在容器停止后仍保留原始日志文件作为备份,避免采集异常时日志完全丢失。此时可以给日志文件路径挂载 hostPath,日志文件会落盘到宿主机指定目录,并且容器停止后不会清理日志文件。由于不会自动清理日志文件,可能会发生 Pod 调度走再调度回来,日志文件被写在相同路径,从而重复采集的问题。采集分以下两种情况:
文件名相同:
例如,固定文件路径
/data/log/nginx/access.log。此时不会重复采集,采集器会记住之前采集过的日志文件的位点,只采集增量部分。 文件名不同:
通常业务用的日志框架会按照一定时间周期自动进行日志轮转,一般是按天轮转,并自动为旧日志文件进行重命名,加上时间戳后缀。如果采集规则里使用了
* 为通配符匹配日志文件名,则可能发生重复采集。日志框架对日志文件重命名后,采集器则会认为匹配到了新写入的日志文件,就又对其进行采集一次。 说明:
通常情况下不会发生重复采集,若日志框架会对日志进行自动轮转,建议采集规则不要使用通配符
* 来匹配日志文件。 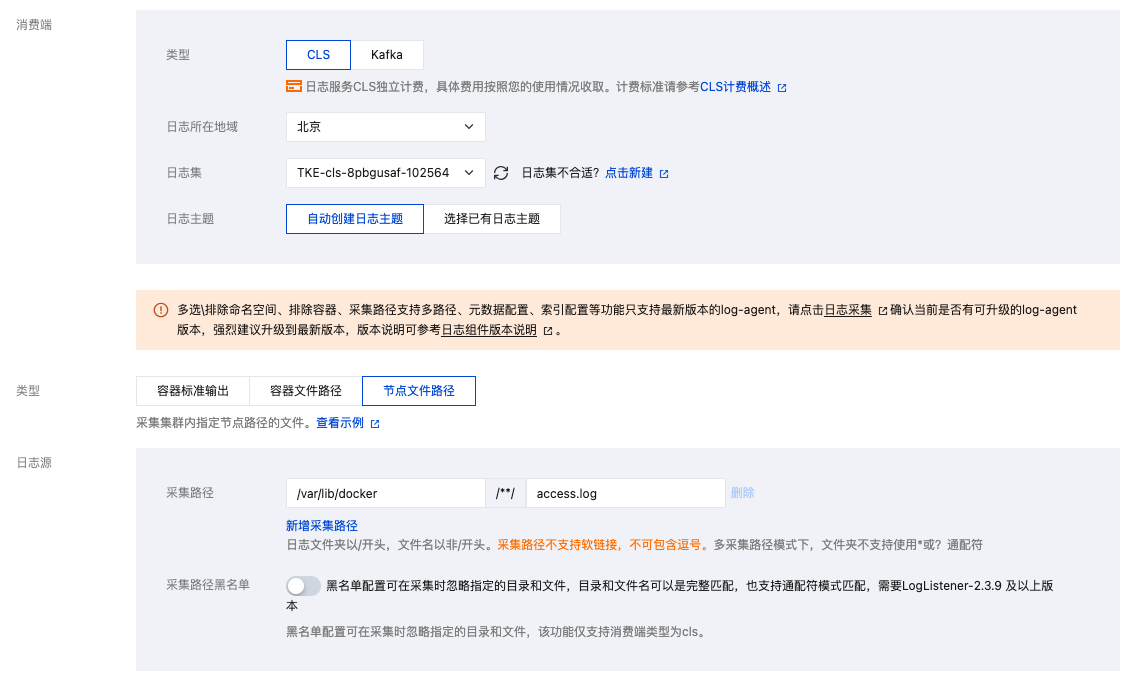
日志输出
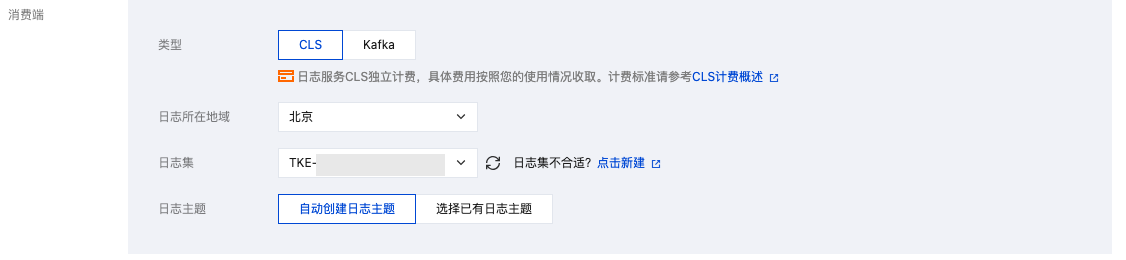
TKE 日志采集与云上的 CLS 日志服务集成,日志数据也将统一上报到日志服务。CLS 通过日志集和日志主题来对日志进行管理,日志集是 CLS 的项目管理单元,可以包含多个日志主题。一般将同一个业务的日志归为同一日志集,同一业务中的同一类的应用或服务使用相同日志主题。在 TKE 中,日志采集规则与日志主题一一对应。TKE 创建日志采集规则时选择消费端,则需要指定日志集与日志主题。其中,日志集通常提前创建完成,日志主题通常选择自动创建。如下图所示:
配置日志格式解析
在创建日志采集规则时,需配置日志的解析格式,便于后续检索。请参考以下内容,对应实际情况进行配置。
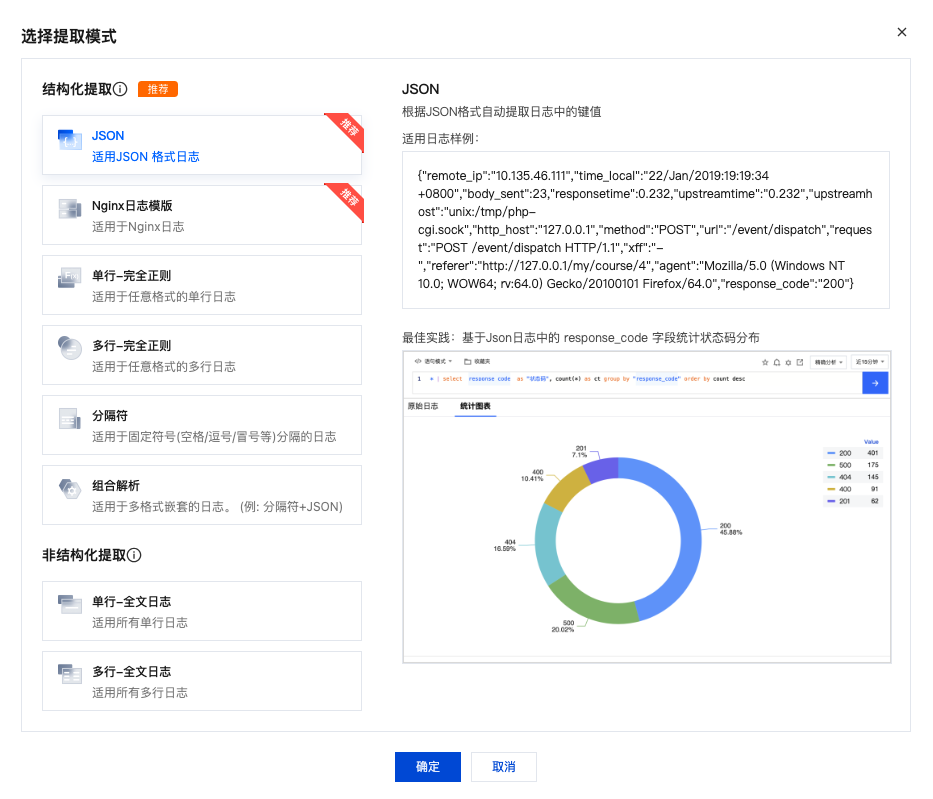
选择提取模式
TKE 支持 JSON、Nginx、单行-完全正则、多行-完全正则、分隔符、组合解析提取等模式。如下图所示:
解析模式 | 说明 | 相关文档 |
单行全文 | 一条日志仅包含一行的内容,以换行符 \\n 作为一条日志的结束标记,每条日志将被解析为键值为 CONTENT 的一行完全字符串,开启索引后可通过全文检索搜索日志内容。日志时间以采集时间为准。 | |
多行全文 | 指一条完整的日志跨占多行,采用首行正则的方式进行匹配,当某行日志匹配上预先设置的正则表达式,就认为是一条日志的开头,而下一个行首出现作为该条日志的结束标识符,也会设置一个默认的键值 CONTENT,日志时间以采集时间为准。支持自动生成正则表达式。 | |
单行 - 完全正则 | 指将一条完整日志按正则方式提取多个 key-value 的日志解析模式,您需先输入日志样例,其次输入自定义正则表达式,系统将根据正则表达式里的捕获组提取对应的 key-value。支持自动生成正则表达式。 | |
多行 - 完全正则 | 适用于日志文本中一条完整的日志数据跨占多行(例如 Java 程序日志),可按正则表达式提取为多个 key-value 键值的日志解析模式,您需先输入日志样例,其次输入自定义正则表达式,系统将根据正则表达式里的捕获组提取对应的 key-value。支持自动生成正则表达式。 | |
JSON | JSON 格式日志会自动提取首层的 key 作为对应字段名,首层的 value 作为对应的字段值,以该方式将整条日志进行结构化处理,每条完整的日志以换行符 \\n 为结束标识符。 | |
Nginx 日志模板 | 适用于 Nginx 日志。 | - |
分隔符 | 指一条日志数据可以根据指定的分隔符将整条日志进行结构化处理,每条完整的日志以换行符 \\n 为结束标识符。日志服务在进行分隔符格式日志处理时,您需要为每个分开的字段定义唯一的 key,无效字段即无需采集的字段可填空,不支持所有字段均为空。 | |
组合解析 | 当您的日志结构太过复杂,涉及多种解析模式,单种解析模式(如 Nginx 模式、完整正则模式、JSON 模式等)无法满足日志解析需求时,您可以使用 LogListener 组合解析格式解析日志,此模式支持用户在控制台输入代码(JSON 格式)用来定义日志解析的流水线逻辑。您可添加一个或多个 Loglistener 插件处理配置,Loglistener 会根据处理配置顺序逐一执行。 |
配置过滤内容
可选择过滤无需使用的日志信息,降低成本。
若使用 “JSON”、“分隔符”或“完全正则”的提取模式,日志内容会进行结构化处理,可以通过指定字段来对要保留的日志进行正则匹配。如下图所示:

若使用“单行文本”和“多行文本”的提取模式,由于日志内容没有进行结构化处理,无法指定字段来过滤,通常直接使用正则来对要保留的完整日志内容进行模糊匹配。如下图所示:
注意:
匹配内容需使用正则而不是完整匹配。例如,需仅保留
a.test.com 域名的日志,匹配的表达式应为 a\\.test\\.com 而不是 a.test.com。 
自定义日志时间戳
每条日志都需要具备主要用于检索的时间戳,可在检索时选择时间范围。默认情况下,日志的时间戳由采集的时间决定,您也可以进行自定义,选择某个字段作为时间戳,在有些场景下会更加精确。例如,在创建采集规则前,服务已运行一段时间,若不设置自定义时间格式,采集时会将之前的旧日志的时间戳设置为当前的时间,导致时间不准确。
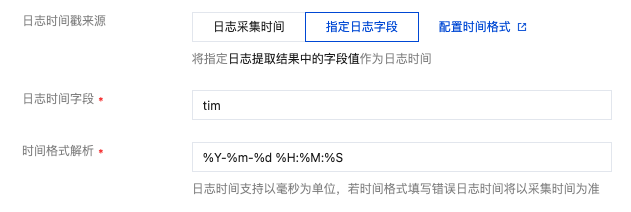
“单行文本”和“多行文本”提取模式不会对日志内容进行结构化处理,无字段可指定为时间戳,即不支持此功能。其他提取模式均支持此功能,选取需作为时间戳的字段名称并配置时间格式。例如,使用日志的
time 字段作为时间戳,其中一条日志 time 的值为 2020-09-22 18:18:18,时间格式即可设置为 %Y-%m-%d %H:%M:%S。如下图所示:注意:
日志服务时间戳目前支持精确到秒,若业务日志的时间戳字段精确到毫秒,则将无法使用自定义时间戳,只能使用默认的采集时间作为时间戳。
查询日志
完成日志采集规则配置后,采集器会自动开始采集日志并上报到 CLS。您可在 日志服务控制台 的检索分析中查询日志,选择日志主题 > 索引配置 > 编辑,开启索引后支持 Lucene 语法。有以下几类索引:
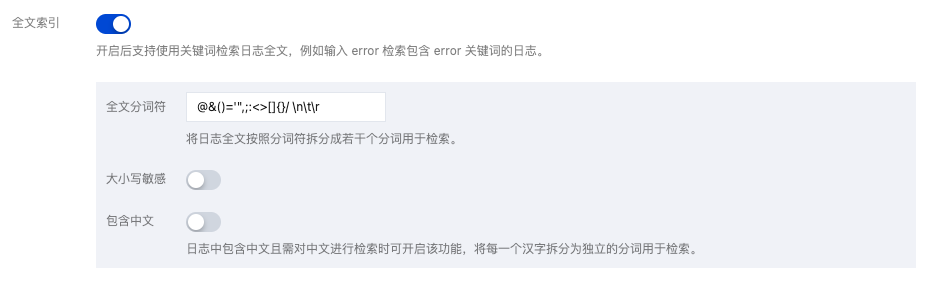
全文索引。用于模糊搜索,不用指定字段。如下图所示:
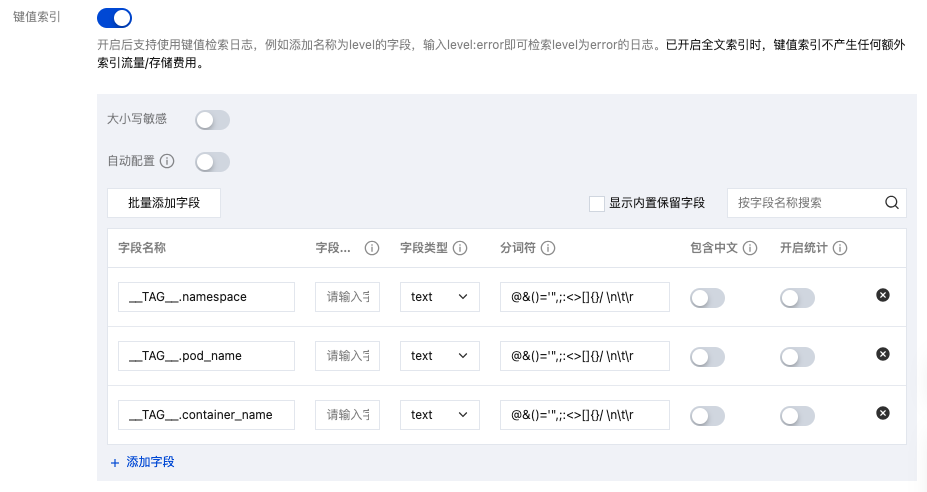
键值索引。索引结构化处理过的日志内容,可以指定日志字段进行检索。如下图所示:
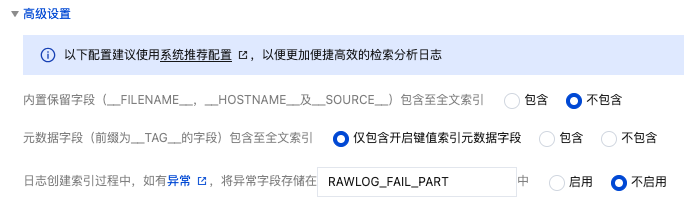
元字段索引。上报日志时额外自动附加的一些字段。例如 pod 名称、namespace 等,方便检索时指定这些字段进行检索。如下图所示:
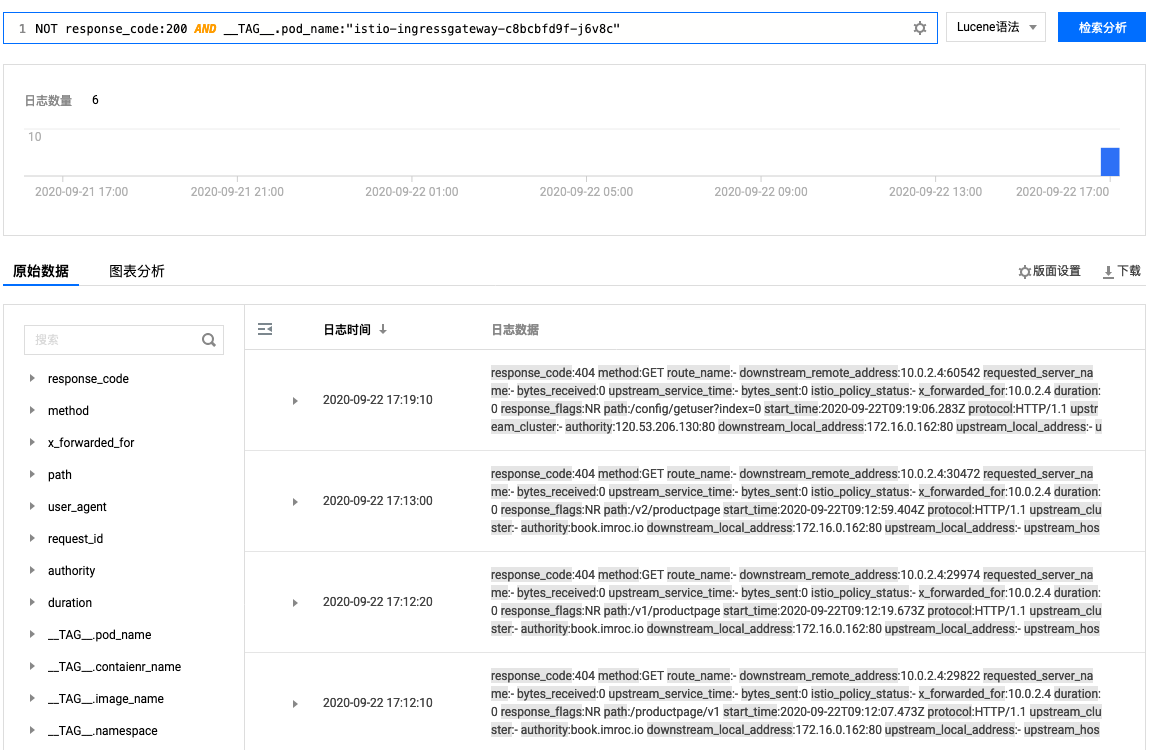
查询示例如下图所示:
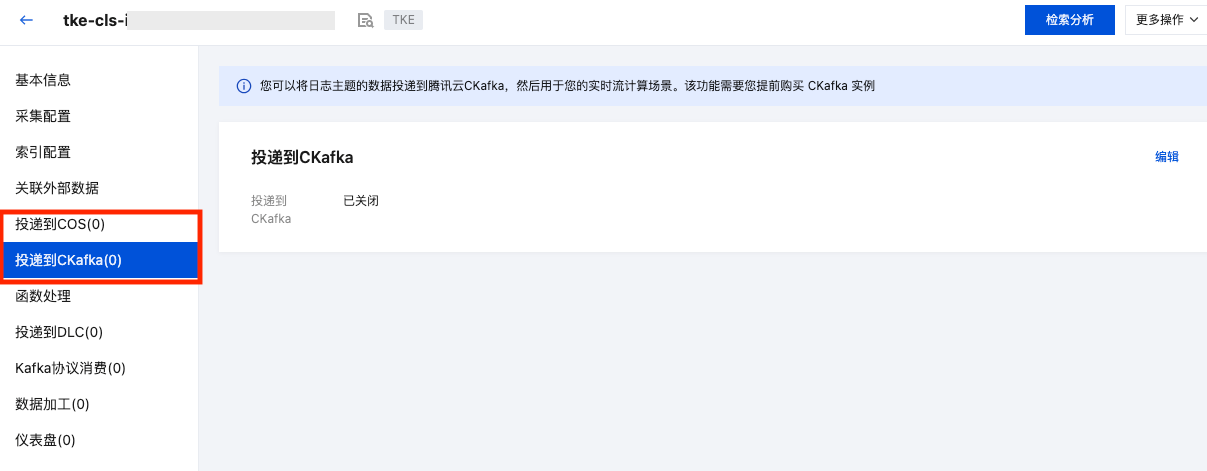
投递日志至 COS 及 CKafka
CLS 支持将日志投递到对象存储 COS 和消息队列 CKafka,您可在日志主题里进行设置。如下图所示:
可用于以下场景:
需对日志数据进行长期归档存储。日志集默认存储7天的日志数据,可以调整时长。数据量越大,成本就越高,通常只保留几天的数据,如果需要将日志存更长时间,可以投递到 COS 进行低成本存储。
需要对日志进行进一步处理(例如离线计算),可以投递到 COS 或 CKafka,由其它程序消费来处理。
参考资料
容器服务:日志采集用法指引
日志服务:配置时间格式
日志服务:投递至 COS
日志服务:投递至 CKafka



