本文档旨在提供用户有关如何处理 GPU 实例异常的指引,以帮助用户快速诊断和解决 GPU 实例相关的问题。以下是一些排查和处理建议,可用于处理部分常见的 GPU 实例问题。
系统状态检测
对于 GPU 服务器建议用户维持较新的GPU驱动版本、禁用 nouveau 模块、打开 GPU 驱动内存常驻模式并配置开机自启动。
对于 GPU 服务器,建议进行以下配置:
维持较新的、正确的 GPU 驱动版本。
禁用 nouveau 模块。
打开 GPU 驱动内存常驻模式并配置开机自启动。
GPU 故障后,建议在官网控制台重启机器看看是否可以恢复。
检查 GPU 驱动
GPU 驱动下载注意事项:
从 NVIDIA 官方文档 官方高级驱动搜索 | NVIDIA 选择正确的 GPU 型号。
对于64位 Linux OS 建议直接选择 Linux 64-bit。
选择 NVIDIA 推荐/认证的驱动。
禁用 nouveau 模块
nouveau 是 NVIDIA 显卡的开源驱动程序,会与 NVIDIA 官方 GPU 驱动发生冲突,需要在系统上禁用 nouveau 模块。
以下命令没有任何输出表示 nouveau 模块已经禁用:
[root@localhost ~]# lsmod | grep -i nouveau
以下输出表示 nouveau 模块没有禁用:
[root@localhost ~]# lsmod | grep -i nouveau nouveau 1662531 0 mxm_wmi 13021 1 nouveau wmi 19086 2 mxm_wmi,nouveau i2c_algo_bit 13413 1 nouveau video 24538 1 nouveau drm_kms_helper 176920 2 nouveau,vmwgfx ttm 99555 2 nouveau,vmwgfx drm 397988 6 ttm,drm_kms_helper,nouveau,vmwgfx i2c_core 63151 5 drm,i2c_piix4,drm_kms_helper,i2c_algo_bit,nouveau
禁用 nouveau 模块的方法参考如下:
# CentOS 7# 编辑或新建 blacklist-nouveau.conf 文件[root@localhost ~]# vim /usr/lib/blacklist-nouveau.confblacklist nouveauoptions nouveau modeset=0# 执行如下命令并重启系统使内核生效[root@localhost ~]# dracut -f[root@localhost ~]# shutdown -ry 0
配置 GPU 驱动内存常驻模式
打开 GPU 驱动内存常驻模式可以减少 GPU 掉卡、GPU 带宽降低、GPU 温度监测不到等诸多问题。建议打开 GPU 驱动内存常驻模式并配置开机自启动。
GPU驱动内存常驻模式检查常用方法:
nvidia-smi 输出中 Persistence-M 状态为 On。
示例:
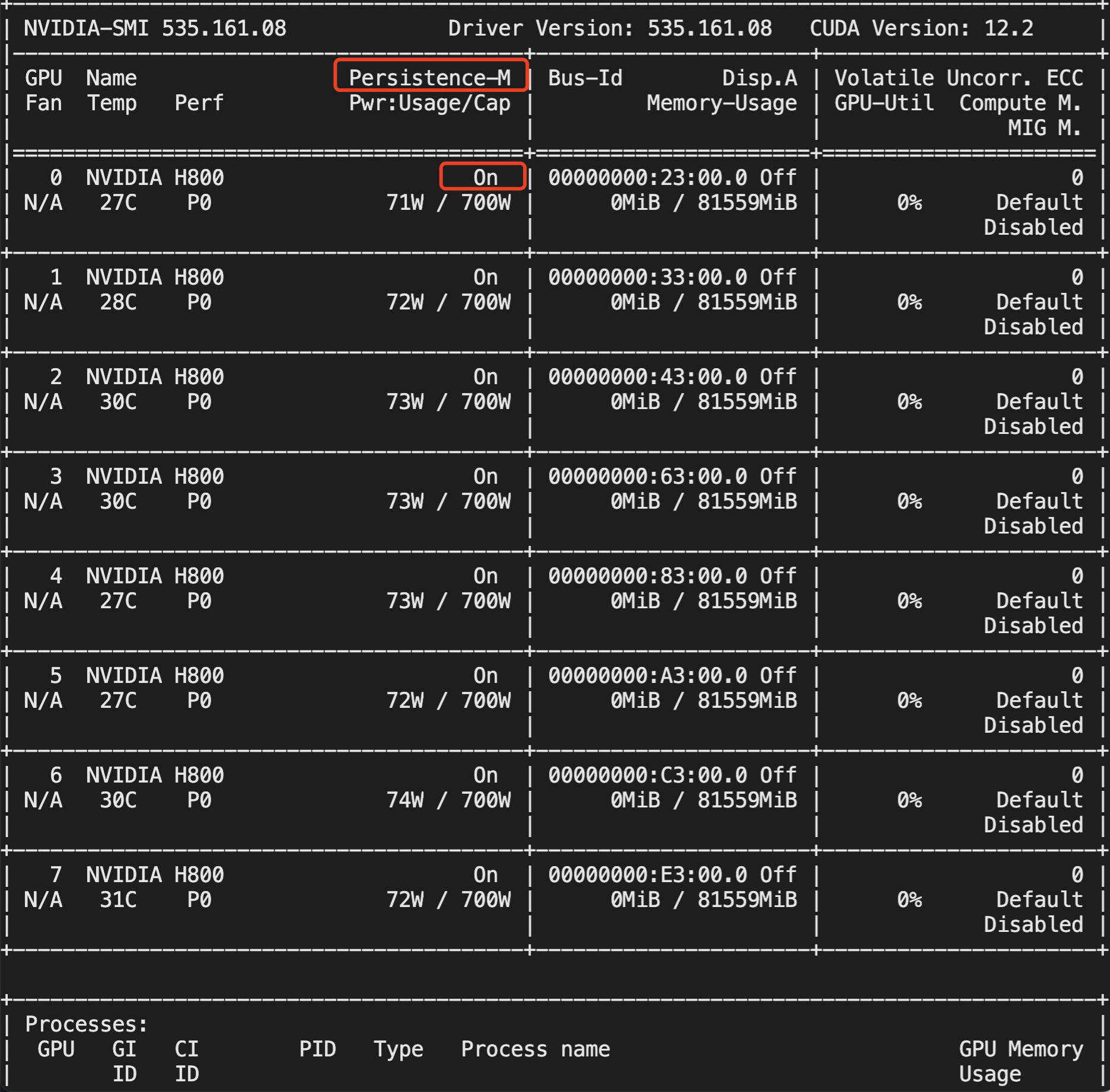
nvidia-bug-report.log 中,Persistence Mode 为 Enabled。
示例:
GPU 00000000:08:00.0Product Name : Tesla V100Product Brand : TeslaDisplay Mode : EnabledDisplay Active : DisabledPersistence Mode : Enabled
GPU 驱动内存常驻模式开启方法如下:
[root@localhost ~]# nvidia-smi -pm 1
# 以下命令对较新版本的GPU驱动有效 [root@localhost ~]# nvidia-persistenced --persistence-mode
开机自启动配置:
# vim /etc/rc.d/rc.local # 在文件中添加一行 # nvidia-smi -pm 1 # 赋予/etc/rc.d/rc.local文件可执行权限 # chmod +x /etc/rc.d/rc.local # 重启系统进行验证
获取 GPU 序列号
获取实例所有的 GPU 序列号:
# nvidia-smi -q | grep -i serial Serial Number : 0324018045603 Serial Number : 0324018044864 Serial Number : 0324018027716 Serial Number : 0323918059881
获取指定 id 的 GPU 序列号:
# nvidia-smi -q -i 0 | grep -i serial Serial Number : 0324018045603
GPU 常见故障
GPU 不识别
GPU 识别状态检测时,首先要确保 lspci 命令识别所有 GPU,其次确保 nvidia-smi 命令识别所有 GPU。
lspci 检查 GPU 识别情况
输入以下命令确保所有 GPU 识别正常,并且每个 GPU 末尾标识为(rev a1);若输出信息末尾为(rev ff),表示 GPU 异常。
lspci | grep -i nvidia
示例:
#如下命令表示识别到4个GPU,且末尾标识为(rev a1)的GPU状态正常;41:00.0 GPU末尾标识为(rev ff),表示该GPU状态异常。~]# lspci | grep -i nvidia3e:00.0 3D controller: NVIDIA Corporation Device 1db8 (rev a1)3f:00.0 3D controller: NVIDIA Corporation Device 1db8 (rev a1)40:00.0 3D controller: NVIDIA Corporation Device 1db8 (rev a1)41:00.0 3D controller: NVIDIA Corporation Device 1db8 (rev ff)
nvidia-smi 检查 GPU 识别情况
输入以下命令检查 GPU 识别情况:
nvidia-smi
示例:用 nvidia-smi 命令看到的 GPU 卡数量与实际不一致,如下图所示,8 块 GPU 卡的实例用 nvidia-smi 命令看到只有 7 块 GPU 卡。
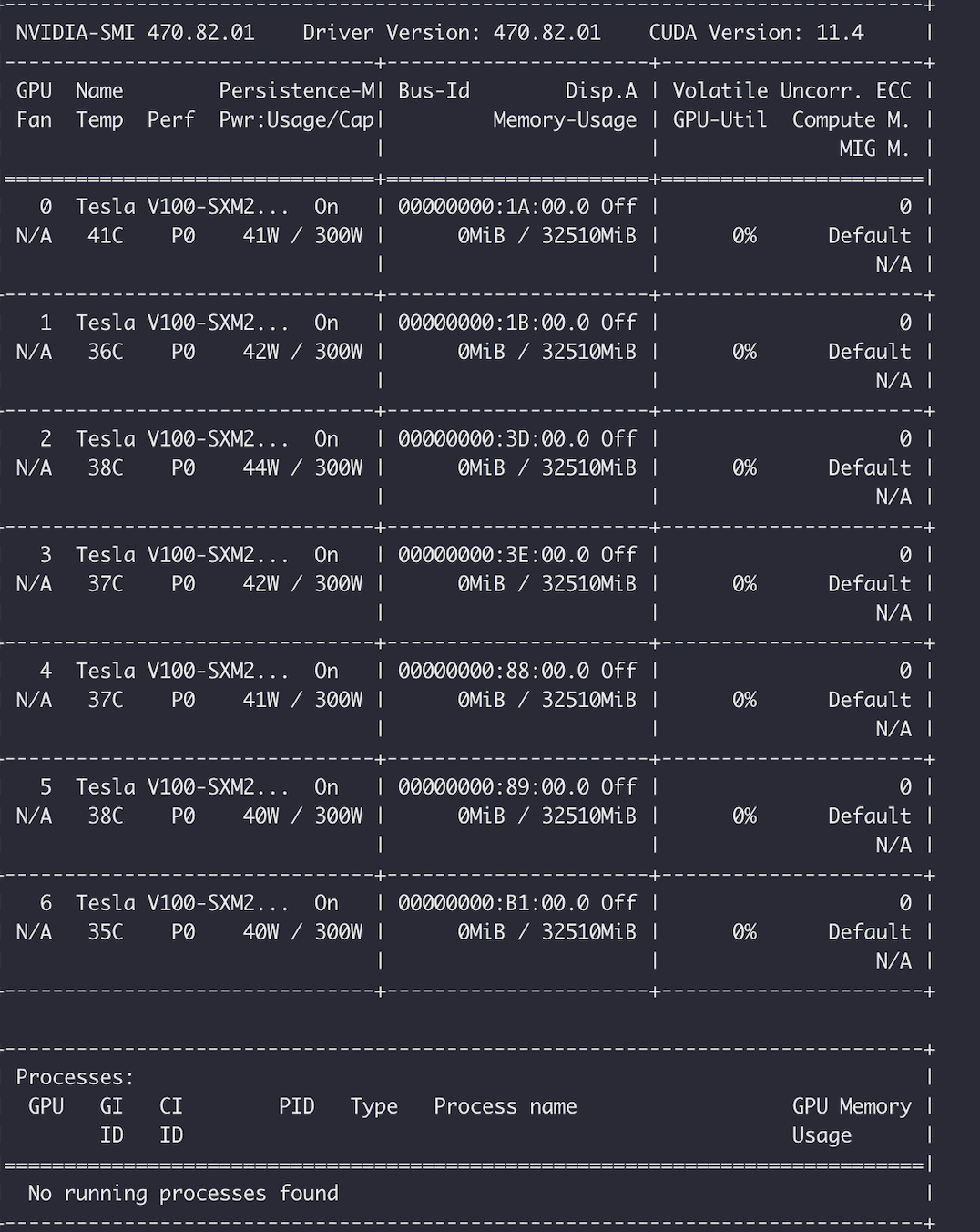
说明:
建议重启实例尝试是否可以恢复;若重启后无法恢复,仍出现 GPU 状态异常,请联系平台为您排查处理。
GPU 带宽异常
需要确保 GPU 当前带宽与额定带宽一致且为 x16。可以使用 lspci 命令或 nvidia-smi 命令进行 GPU 带宽检查。
lspci 命令
查询额定带宽:
lspci -vvd 10de: | grep -i Lnkcap:
查询当前带宽:
lspci -vvd 10de: | grep -i Lnksta:
nvidia-smi 命令检查
nvidia-smi -q | grep -i -A 2 'Link width'#输出示例:[root@localhost ~]# nvidia-smi -q | grep -i -A 2 'Link width'Link WidthMax : 16xCurrent : 16x--Link WidthMax : 16xCurrent : 16x--
nvidia-smi --format=csv --query-gpu=index,name,serial,gpu_bus_id,pcie.link.width.current#输出示例:[root@localhost ~]# nvidia-smi --format=csv --query-gpu=index,name,serial,gpu_bus_id,pcie.link.width.currentindex, name, serial, pci.bus_id, pcie.link.width.current0, Tesla P40, 1321020022261, 00000000:04:00.0, 161, Tesla P40, 1320220073456, 00000000:05:00.0, 162, Tesla P40, 1320220073723, 00000000:08:00.0, 163, Tesla P40, 1320220073383, 00000000:09:00.0, 164, Tesla P40, 1320220073482, 00000000:85:00.0, 165, Tesla P40, 1320220073313, 00000000:86:00.0, 166, Tesla P40, 1320220073379, 00000000:89:00.0, 167, Tesla P40, 1320220073579, 00000000:8A:00.0, 16
说明:
通常为硬件问题,请联系平台为您排查处理。
GPU retired pages 计数检查
NVIDIA GPU ECC RMA 标准
说明:
对于 GPU retired pages 计数,满足以下任一条件或 nvidia fieldiag 检测 fail 均可联系平台进行 GPU 更换。
Retired Pages参数中:
30天内产生的 Double Bit ECC ≥5。
质保期内 Double Bit ECC ≥10。
质保期内 Double Bit ECC+Single Bit ECC ≥ 60。
retired pages 查询方法
# 指定GPU id查询某一块GPU的ECC计数:[root@localhost ~]# nvidia-smi -i <target gpu> -q -d PAGE_RETIREMENT ... Retired pages Single Bit ECC : 2 Double Bit ECC : 0 Pending : No# 查询所有GPU的ECC计数:[root@localhost ~]# nvidia-smi -q -d PAGE_RETIREMENT# 如输出Pending 的标志为No表示所有ECC报错地址空间已经被屏蔽,报错地址空间后续不会再被软件程序调用,不会再影响程序运行;# Yes 表示有需要被屏蔽的ECC报错地址,需要重启系统或重置GPU使其变为No。
# 该方法只能查看retired pages计数,无法查看retired pages是否已经被屏蔽# 查询某一块GPU的ECC计数:[root@localhost ~]# nvidia-smi -q -i 0 | grep -i 'bit ecc' Single Bit ECC : 0 Double Bit ECC : 0# 查看所有GPU的retired pages计数:[root@inspur ~]# nvidia-smi -q | grep -i 'bit ecc' Single Bit ECC : 0 Double Bit ECC : 0 Single Bit ECC : 1 Double Bit ECC : 0
# 该方法可以查看所有retired pages的产生时间,便于判断是否满足nvidia RMA标准。# 该方法需要较新的GPU驱动版本支持,否则无法查看retired pages产生时间。[root@localhost ~]# nvidia-smi -i <target gpu> --query-retired-pages=gpu_name,gpu_bus_id,gpu_serial,retired_pages.cause,retired_pages.timestamp --format=csv
处理建议
若 GPU retired pages 计数满足 NVIDIA RMA 标准则联系平台进行硬件更换。
若 GPU retired pages 计数不满足 NVIDIA RMA 标准,需要检查当前报错的地址空间是否被屏蔽,即 Pending :No,否则可重启系统或重置 GPU 屏蔽报错地址后再次测试程序运行情况;屏蔽报错地址后程序仍受 ECC 报错影响,进行 fieldiag 检测,测试 FAIL 则联系平台进行 GPU 更换。
对于 Volatile 和 Aggregate 条目下出现的 GPU ECC 报错,可使用 nvidia-smi -p 0/1 进行清除。
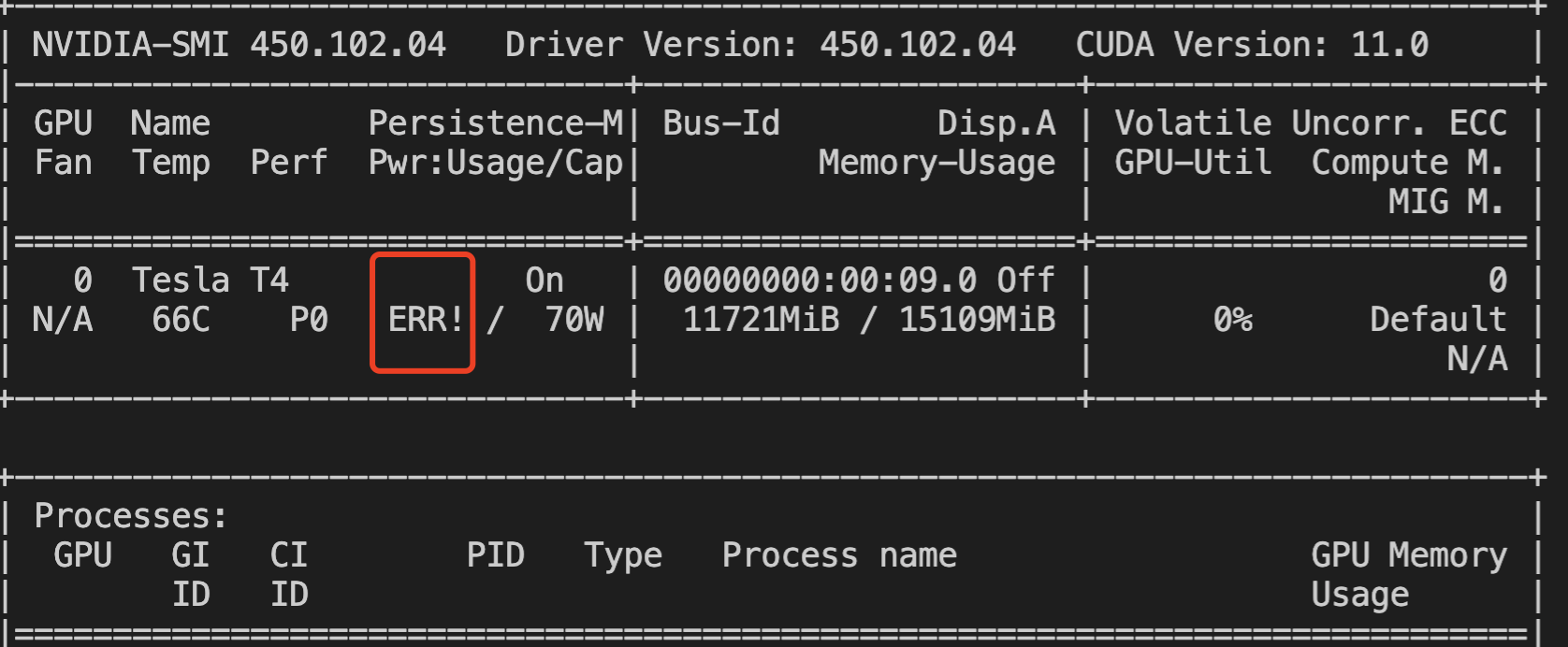
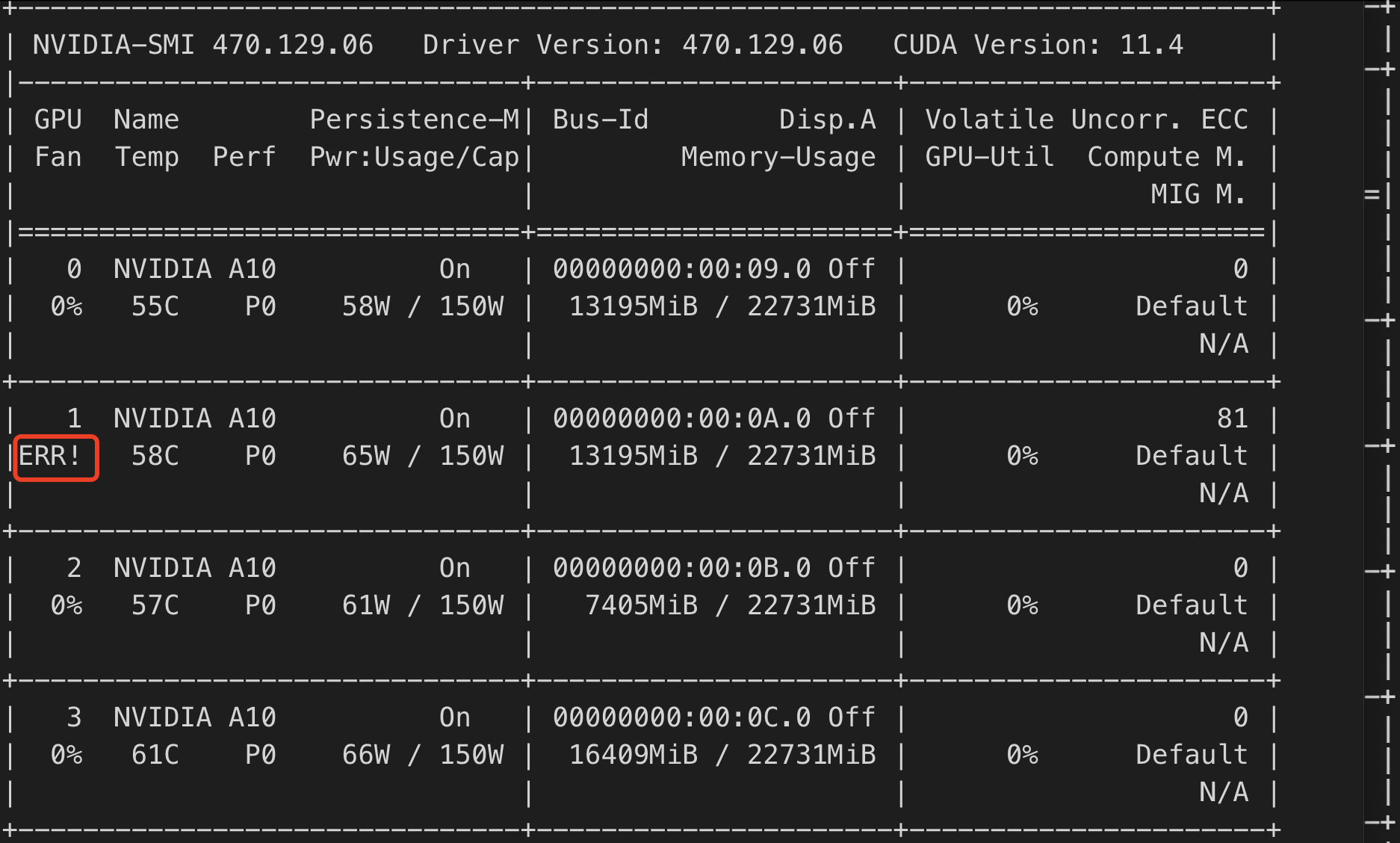
GPU ERR! 报错检查
GPU 运行过程中会出现风扇、功率等 ERR! 报错,可以通过检查 nvidia-smi 输出中是否包含 ERR! 报错判断。
功率 ERR!报错示例:
风扇 ERR! 报错示例:
也可以通过 nvidia-bug-report 日志中的 Fan Speed 或 Power Draw 字段是否为 Unknown Error 来判断。
说明:
升级 GPU 驱动至较新版本后,重启系统进行观察。若重启后问题仍存在请联系平台为您排查处理。
Xid 错误
Xid 消息是 NVIDIA 驱动程序向操作系统的内核日志或事件日志打印的错误报告。Xid 消息表示发生了 GPU 错误,通常是由于驱动程序对 GPU 编程不正确或发送到 GPU 的命令被损坏。常见Xid事件及处理建议请参见 常见 Xid 事件的处理方法。
若以上状态检测和常见故障无法解决问题,请联系平台工程师协助排查处理。



