功能介绍
集群事件中包含事件列表和事件策略。
事件列表:记录集群发生的关键变化事件或异常事件。
事件策略:支持根据业务情况自定义事件监控触发策略,已开启监控的事件可设置前往云可观测平台配置事件告警。
查看事件列表
1. 登录弹性 MapReduce 控制台>EMR on TKE 集群,在集群列表中单击对应的集群 ID/名称进入集群详情页。
2. 在集群详情页中选择监控大盘 > 集群事件 > 事件列表,可直接查看当前集群所有操作事件。
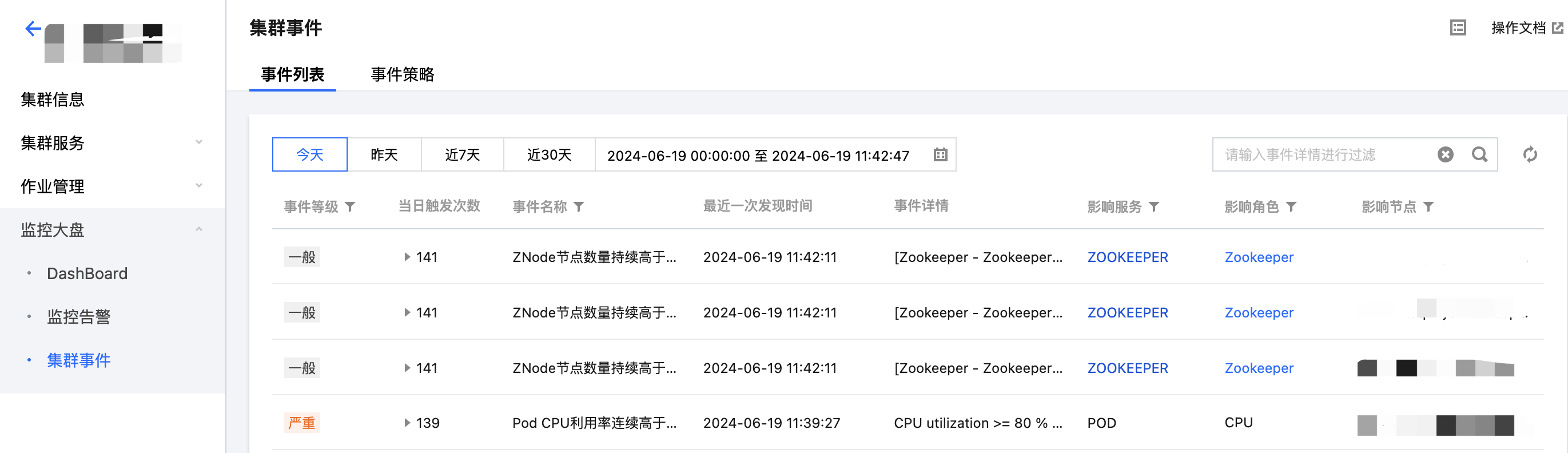
严重程度说明如下:
致命:节点或服务的异常事件,人工干预处理,否则服务不可用,这类事件可能持续一段时间。
严重:暂时未造成服务或节点不可用问题,属于预警类,如果一直不处理会产生致命事件。
一般:记录集群发生的常规事件,一般无需特别处理。
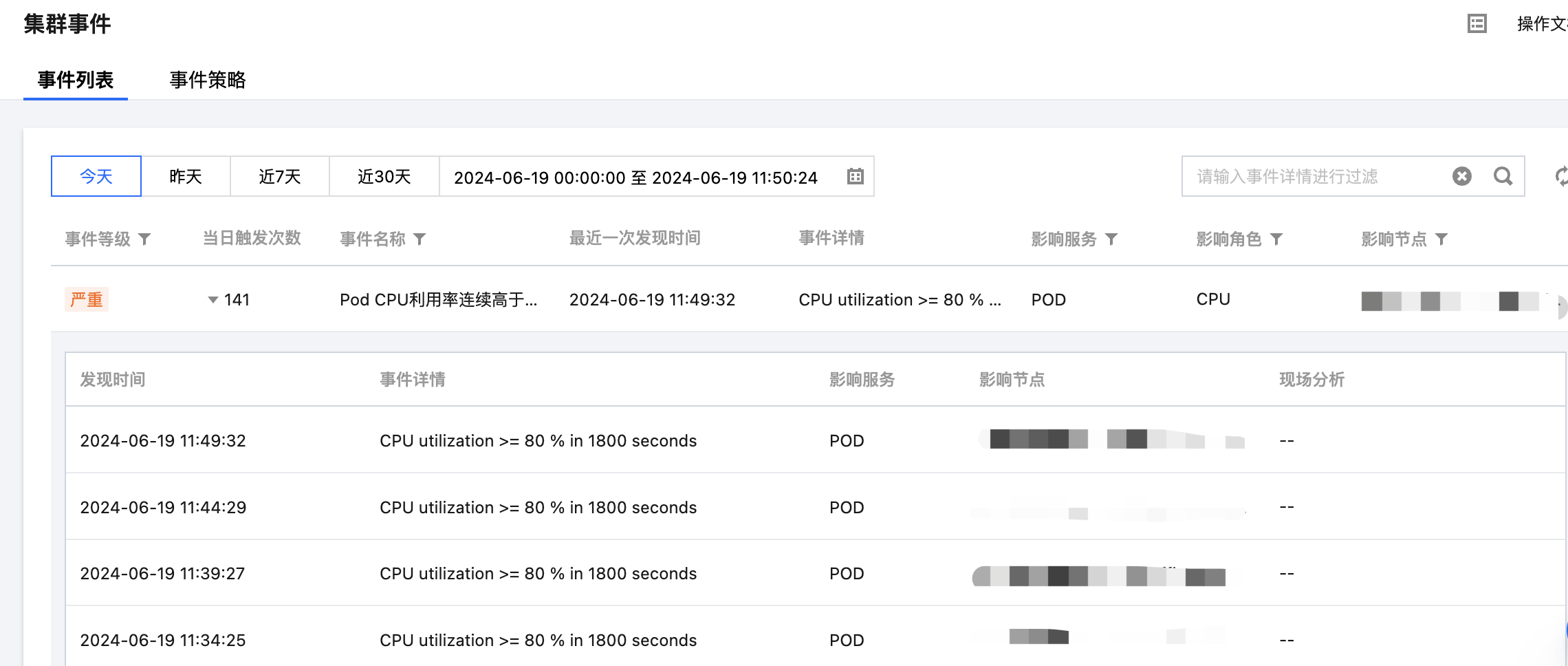
3. 单击当日触发次数列值可查看事件的触发记录,同时可查看事件记录相关指标。
设置事件策略
1. 登录弹性 MapReduce 控制台 > EMR on TKE 集群,在集群列表中单击对应的集群 ID/名称进入集群详情页。
2. 在集群详情页中选择集群监控 > 集群事件 > 事件策略,可以自定义设置事件监控触发策略。
3. 事件配置列表包含:事件名、事件发现策略、严重程度(致命/严重/一般)、开启监控,支持修改和保存。

4. 事件发现策略分两类:一类事件为系统固定策略事件,不支持用户修改;另一类事件会因客户业务标准的不同而变化,支持用户设置。
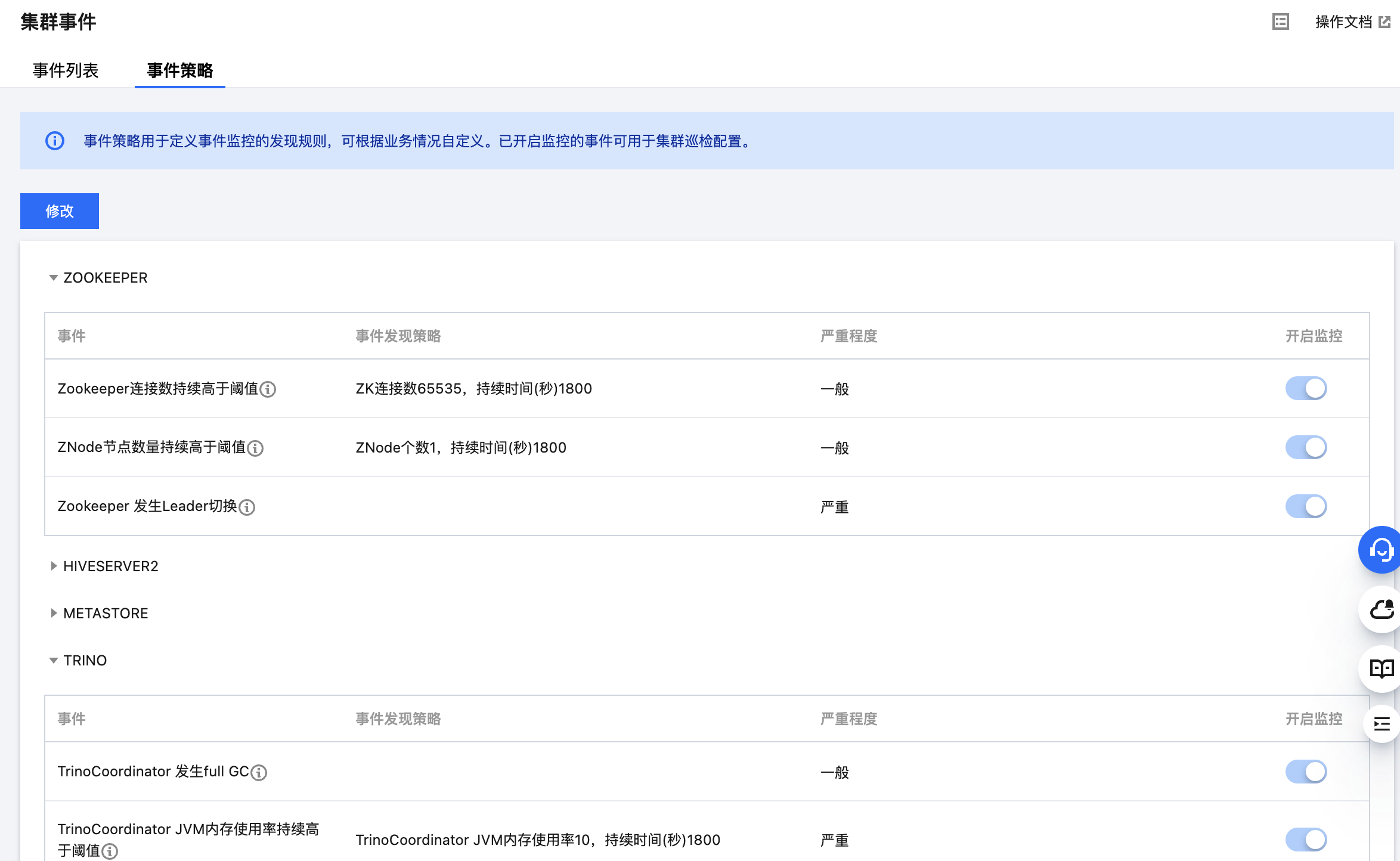
5. 事件策略可自定义是否开启事件监控,已开启监控的事件才支持在云可观测平台中配置事件告警。部分事件默认开启,部分事件默认开启且不可关闭。具体规则如下:
类别 | 事件名称 | 事件含义 | 建议&措施 | 默认值 | 严重程度 | 允许关闭 | 默认开启 |
节点 | CPU 利用率连续高于阈值 | 机器 CPU 利用率 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=85, t=1800 | 严重 | 是 | 是 |
| 内存使用率持续高于阈值 | 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=85, t=1800 | 严重 | 是 | 是 |
HiveServer2 | HiveServer2 发生 full GC | HiveServer2 发生 full GC | 参数调优 | m=5, t=300 | 严重 | 是 | 是 |
| HiveServer2 JVM 内存使用率持续高于阈值 | HiveServer2 JVM 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 HiveServer2 堆内存大小 | m=85, t=1800 | 严重 | 是 | 是 |
HiveMetaStore | HiveMetaStore 发生 full GC | HiveMetaStore 发生 full GC | 参数调优 | m=5, t=300 | 一般 | 是 | 是 |
Zookeeper | Zookeeper 连接数持续高于阈值 | Zookeeper 连接数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=65535, t=1800 | 一般 | 是 | 否 |
| ZNode 节点数量持续高于阈值 | ZNode 节点数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=2000, t=1800 | 一般 | 是 | 否 |
| Zookeeper 发生 leader 切换 | Zookeeper 发生 leader 切换 | 通过 Zookeeper 服务日志进行排查 | - | 严重 | 是 | 是 |
Trino | PrestoSQL 当前失败节点数量持续高于阈值 | PrestoSQL 当前失败节点数量>=m,持续时间t秒(300<=t<=604800) | 人工排查 | m=1, t=1800 | 严重 | 是 | 是 |
| PrestoSQL 当前资源组排队资源持续高于阈值 | PrestoSQL 资源组排队任务>=m,持续时间 t秒(300<=t<=604800) | 参数调优 | m=5000, t=1800 | 严重 | 是 | 是 |
| PrestoSQL 每分钟失败查询数量超过阈值 | PrestoSQL 失败查询数量 >=m | 人工排查 | m=1, t=1800 | 严重 | 是 | 否 |
| PrestoSQLCoordinator 发生full GC | PrestoSQLCoordinator 发生full GC | 参数调优 | - | 一般 | 是 | 否 |
| PrestoSQLCoordinator JVM 内存使用率持续高于阈值 | PrestoSQLCoordinator JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 PrestoSQLCoordinator 堆内存大小 | m=0.85, t=1800 | 严重 | 是 | 是 |
| PrestoSQLWorker 发生 full GC | PrestoSQLWorker 发生 full GC | 参数调优 | - | 一般 | 是 | 否 |
| PrestoSQLWorker JVM 内存使用率持续高于阈值 | PrestoSQLWorker JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 PrestoSQLWorker 堆内存大小 | m=0.85, t=1800 | 严重 | 是 | 否 |