Hue 是一个开源的 Apache Hadoop UI 系统,由 Cloudera Desktop 演化而来,最后 Cloudera 公司将其贡献给 Apache 基金会的 Hadoop 社区,它是基于 Python Web 框架 Django 实现的。通过使用 Hue 我们可以在浏览器端的 Web 控制台上与 Hadoop 集群进行交互来分析处理数据,例如操作 HDFS 上的数据、运行 MapReduce Job、执行 Hive 的 SQL 语句和浏览 HBase 数据库等。
访问 Hue WebUI
使用 Hue 组件管理工作流时,请先登录 Hue 控制台页面,具体步骤如下:
1. 登录 EMR 控制台,单击对应集群 ID/名称,进入集群详情页面,然后单击集群服务。
2. 在列表页找到 Hue 组件,单击 WebUI 访问地址进入 Hue 页面。
3. 首次登录 Hue 控制台页面,请使用 hadoop 账号,密码为创建集群时提供的密码。
注意
EMR-V2.5.0及以前版本、EMR-V3.1.0及以前版本未集成 OpenLDAP ,需要在首次以 root 账号登录 Hue 控制台,参考 社区官方文档 于 WebUI 新建账号。EMR 产品的组件启动账号为 hadoop,历史版本建议首次登录 Hue 控制台后,新建 hadoop 账号,后续可以通过 hadoop 账号来提交作业。
用户权限管理
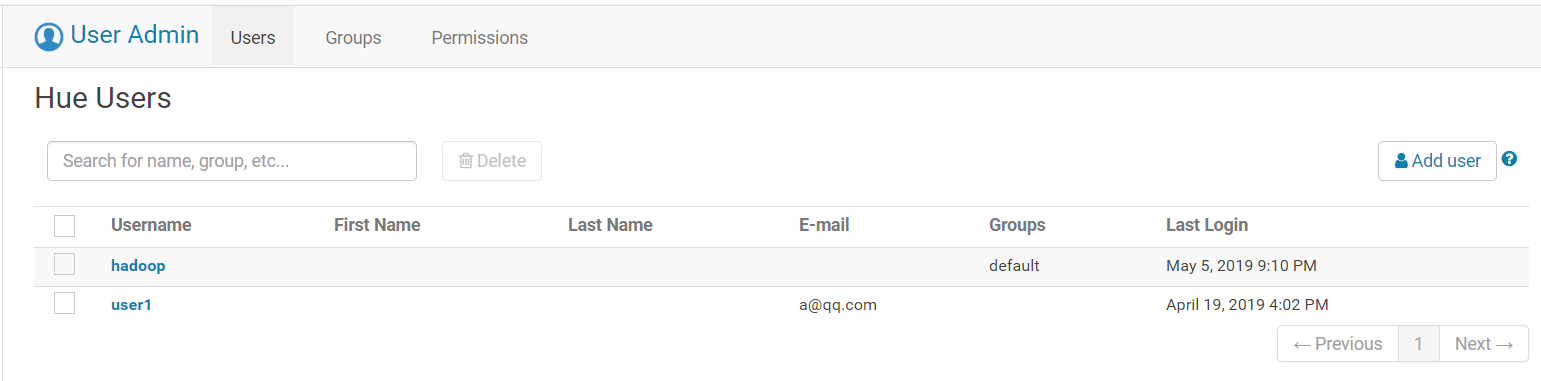
1. 添加用户。
1.2 如果您的集群部署了 Ranger,添加新用户后,需要手动触发 ranger-ugsync-site.xml 的配置下发,重启 EnableUnixAuth 服务进行用户同步,具体操作步骤可参考 用户管理。然后进入 Ranger WebUI 设置新用户访问权限。
1.3 在列表页找到 Hue 组件,单击 WebUI 访问地址进入 Hue 页面,完成新用户登录及使用。
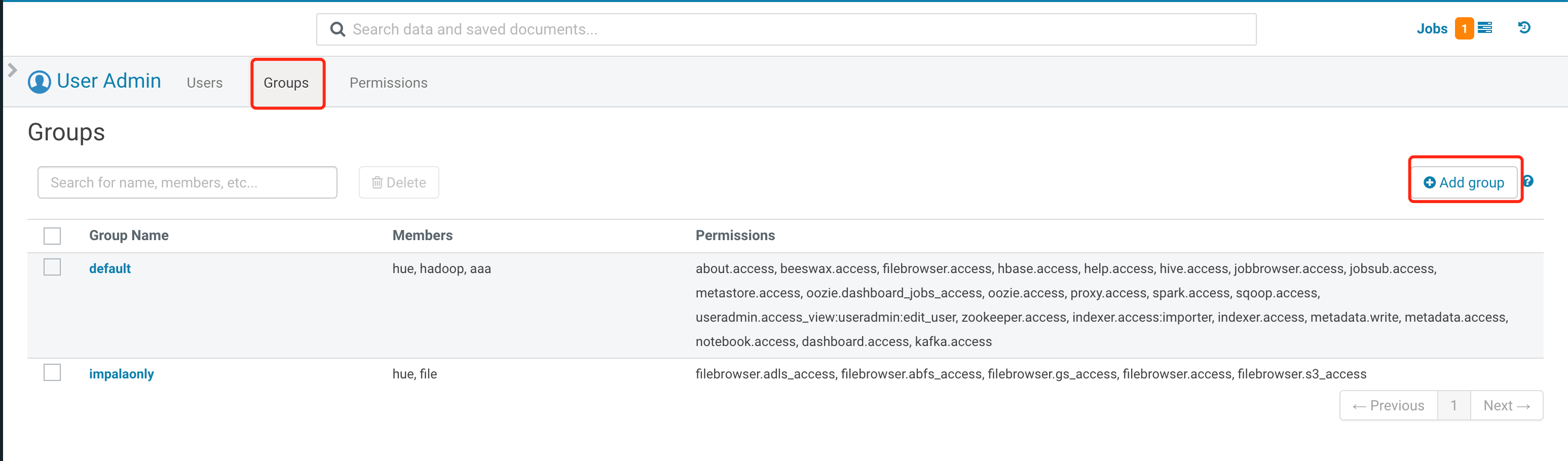
2. 权限控制。
hue 通过将不同的权限添加到组,用户通过加入不同的组获得对应权限。
2.1 单击用户管理页面上方的 Groups,然后单击右侧的 Add group。
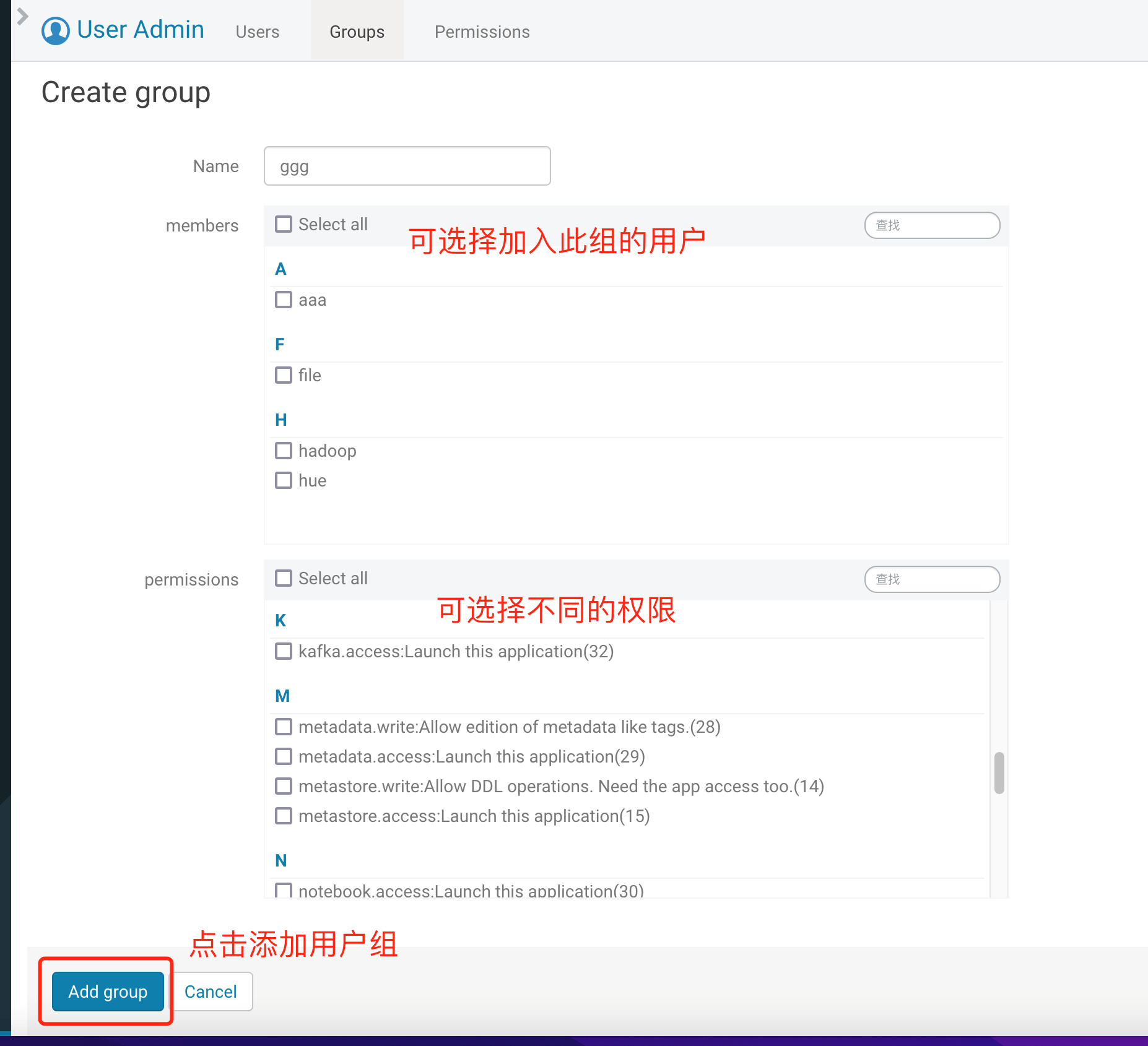
2.2 填写用户组信息,可勾选目标用户加入此组,并勾选此用户组的权限,单击下方的 Add Group。
数据导入
Hue 支持4种导入方式:本地文件、HDFS 上的文件、外部数据库以及人工导入。
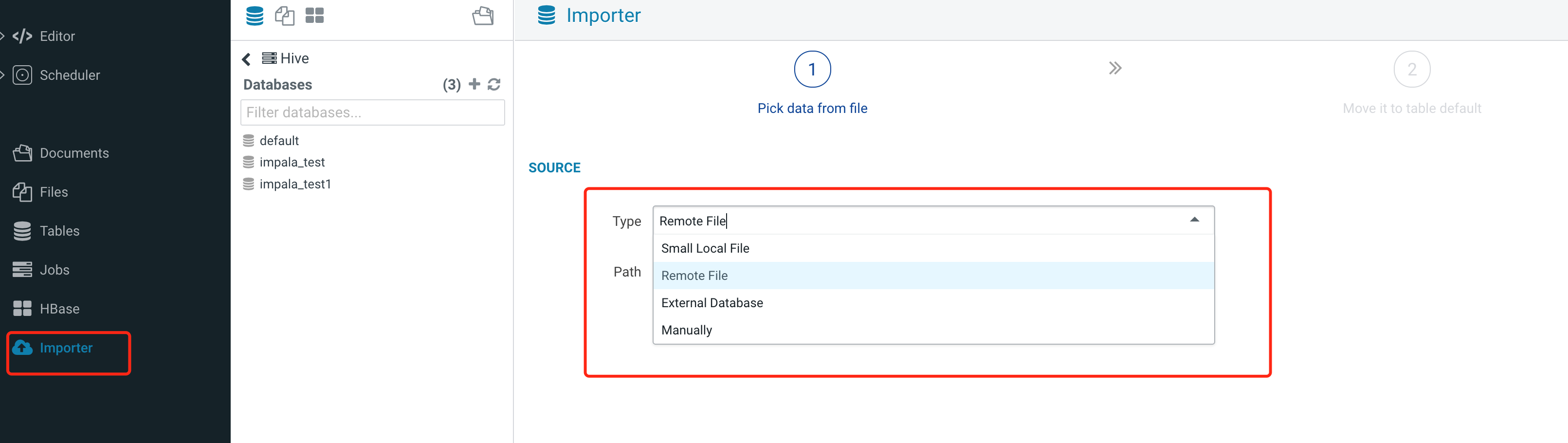
1. 本地文件导入。
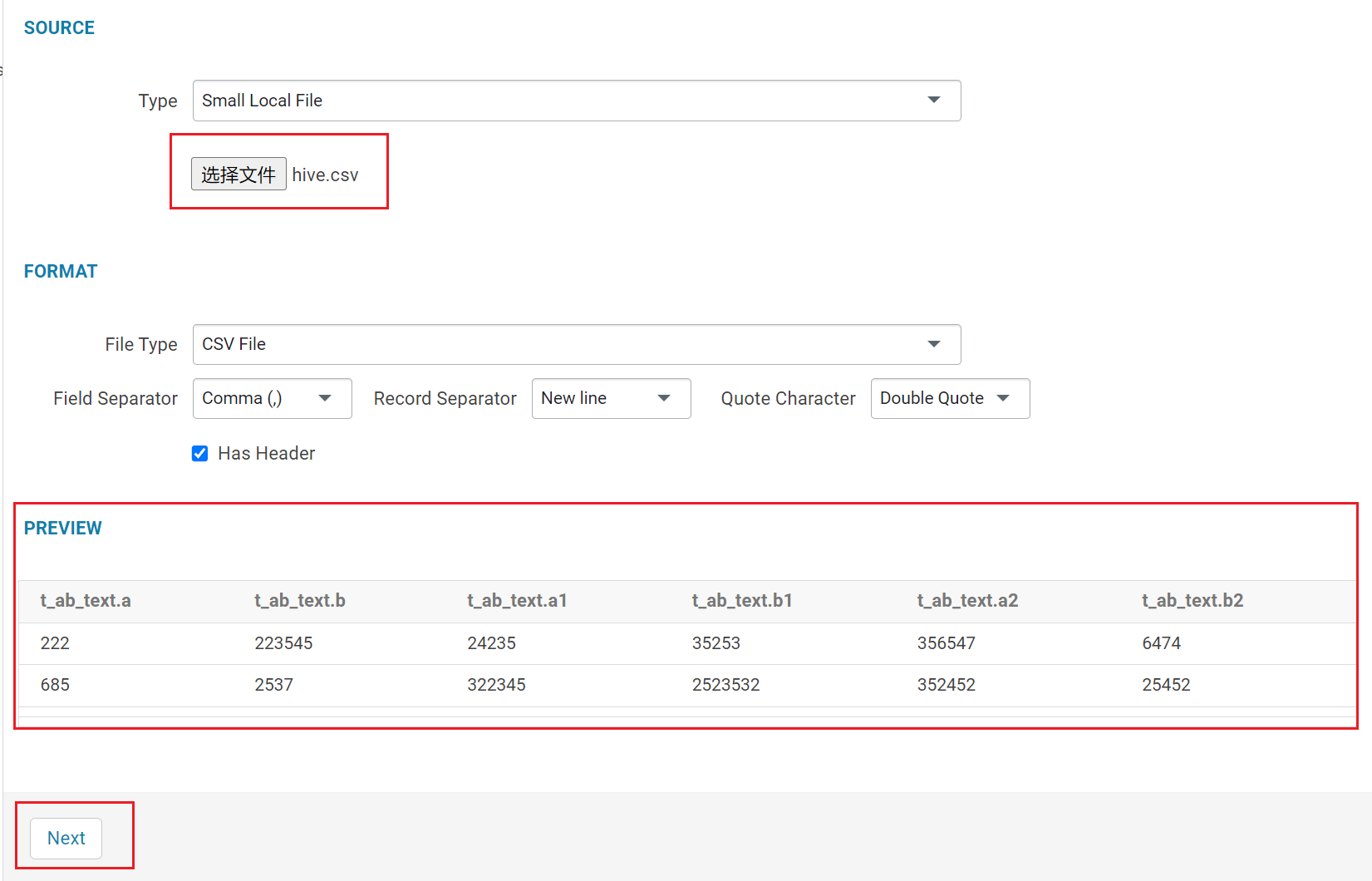
1.1 单击选择文件,hue 会自动识别出分隔符并生成预览,单击 Next 导入到表。
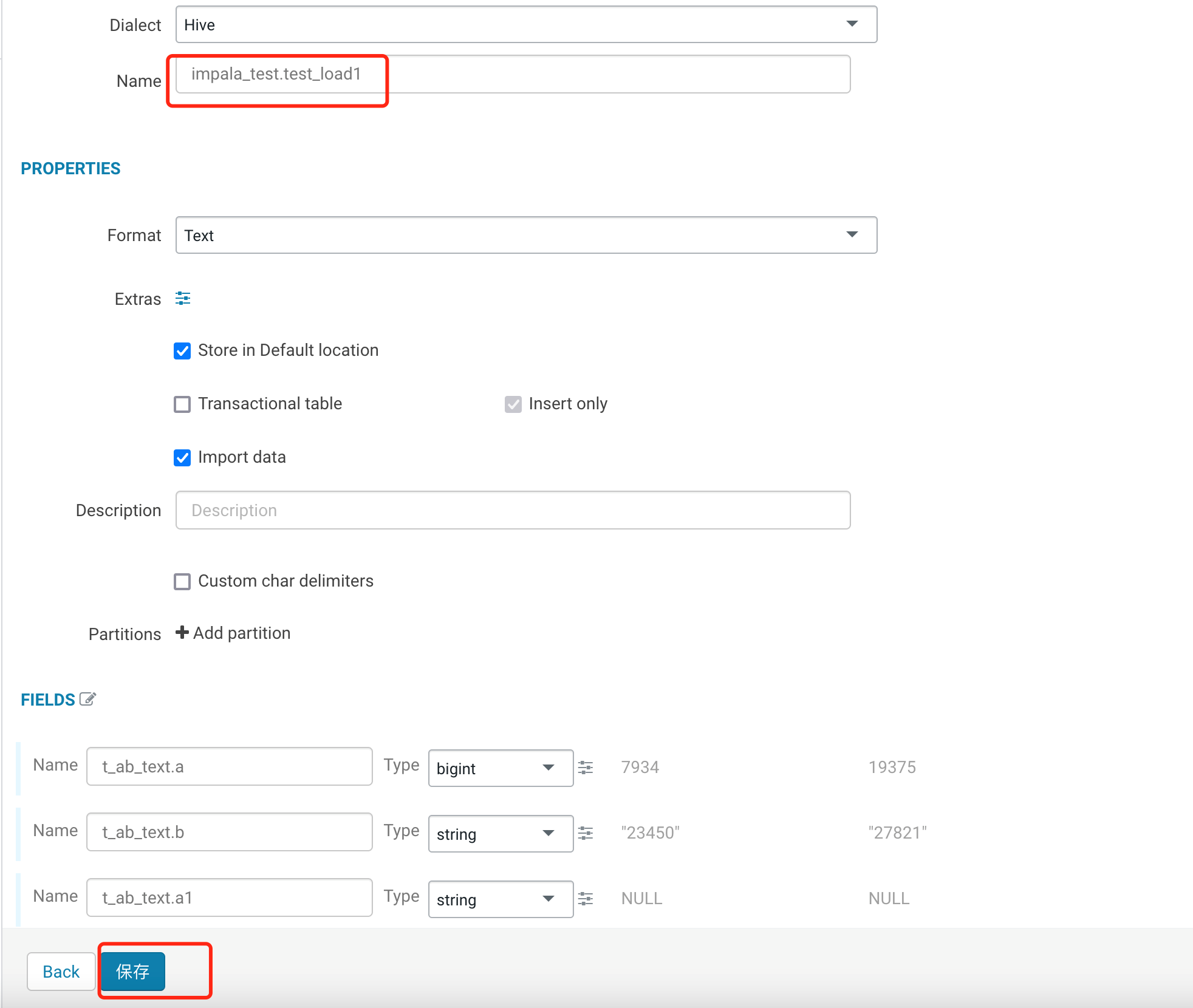
1.2 填写需要导入的表信息等,单击保存。
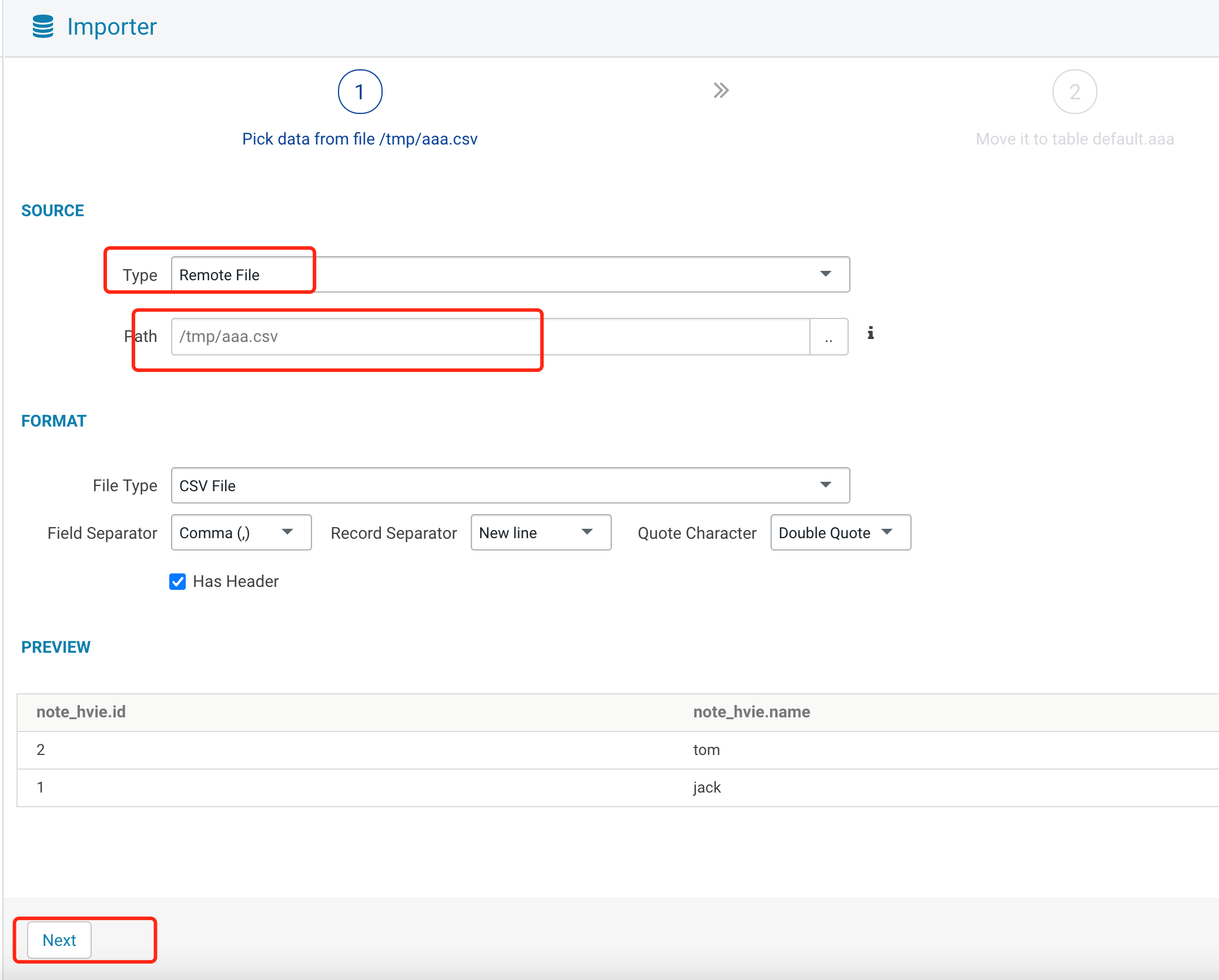
2. HDFS 文件导入。
2.1 选择 HDFS 上的 csv 文件。
2.2 填写需要导入的表信息等,单击保存。
3. 外部数据库 External Database.
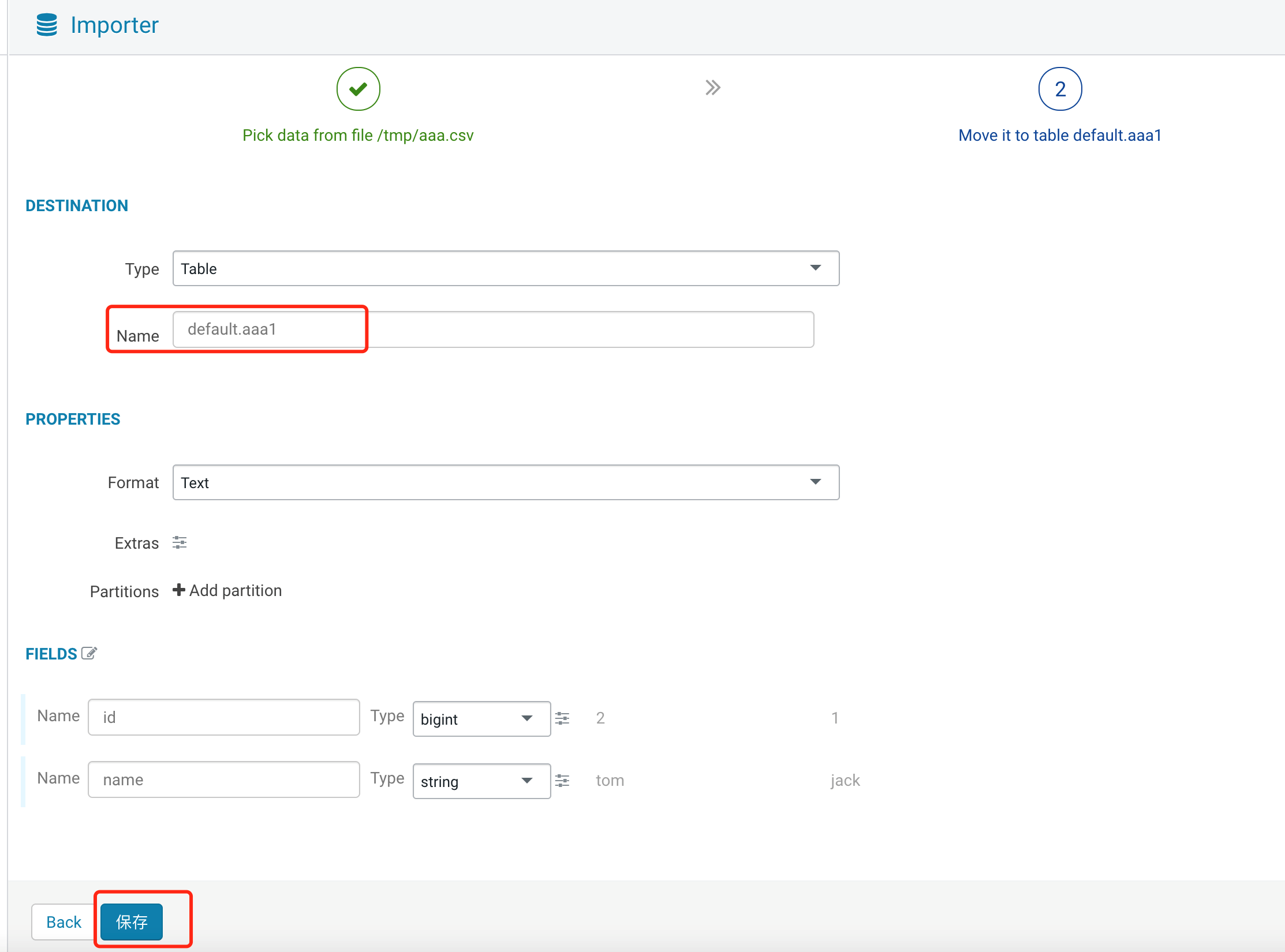
3.1 填写外部数据库信息,单击 Test Connection 获取到数据库信息,选择库和表后单击 Next。
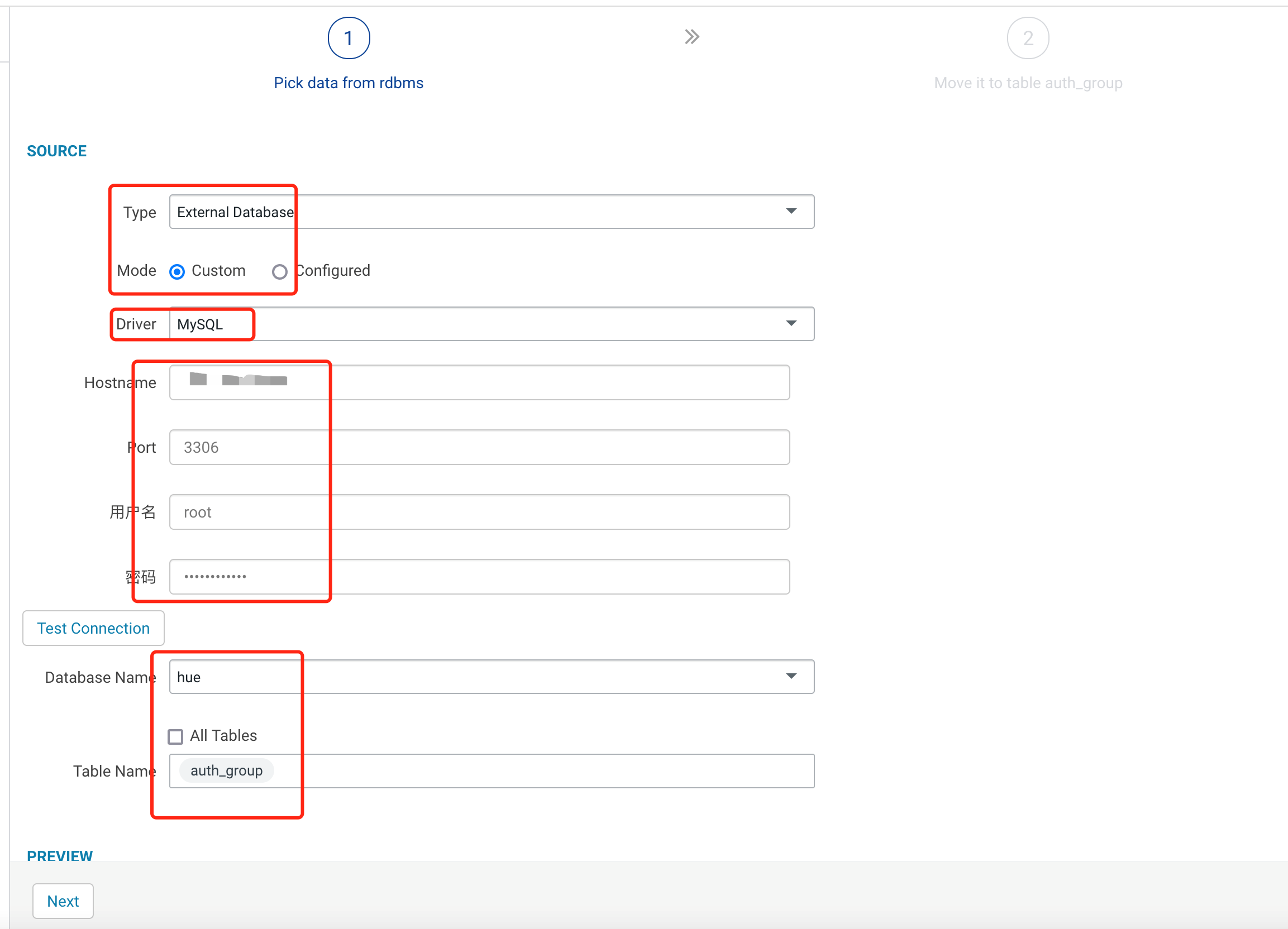
3.2 填写需要导入的目的表信息,并单击 lib 选择 mysql 驱动,然后单击保存。
Job 管理
单击左侧的 Jobs标签,即可进入任务管理页面,单击上方的各个任务类型标签,可进行查看管理。
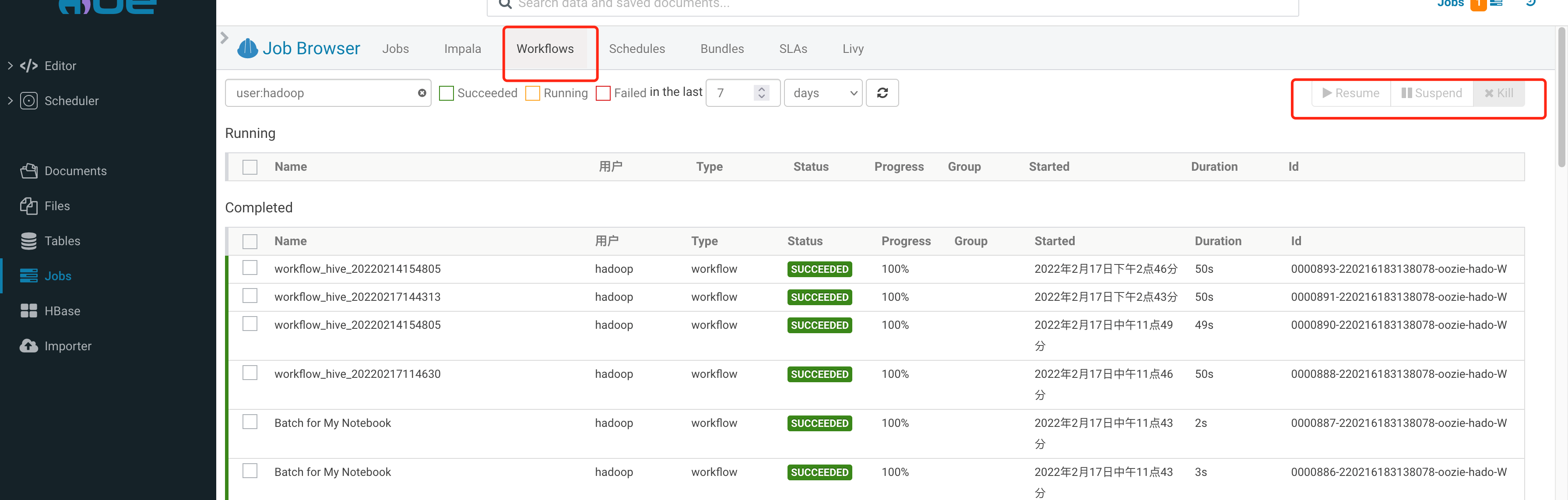
Table 管理
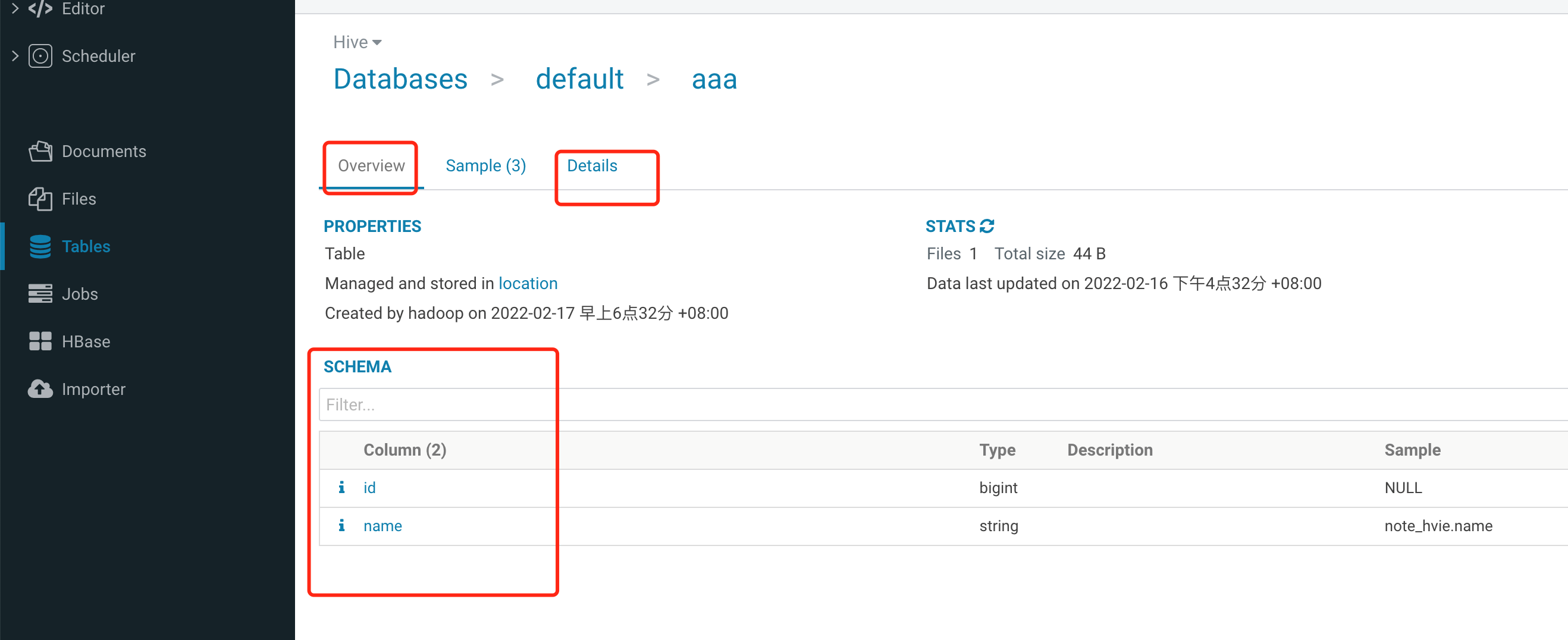
1. 单击左侧的 Tables 进入到 Table 管理页面,可以查看到基本的数据库信息。
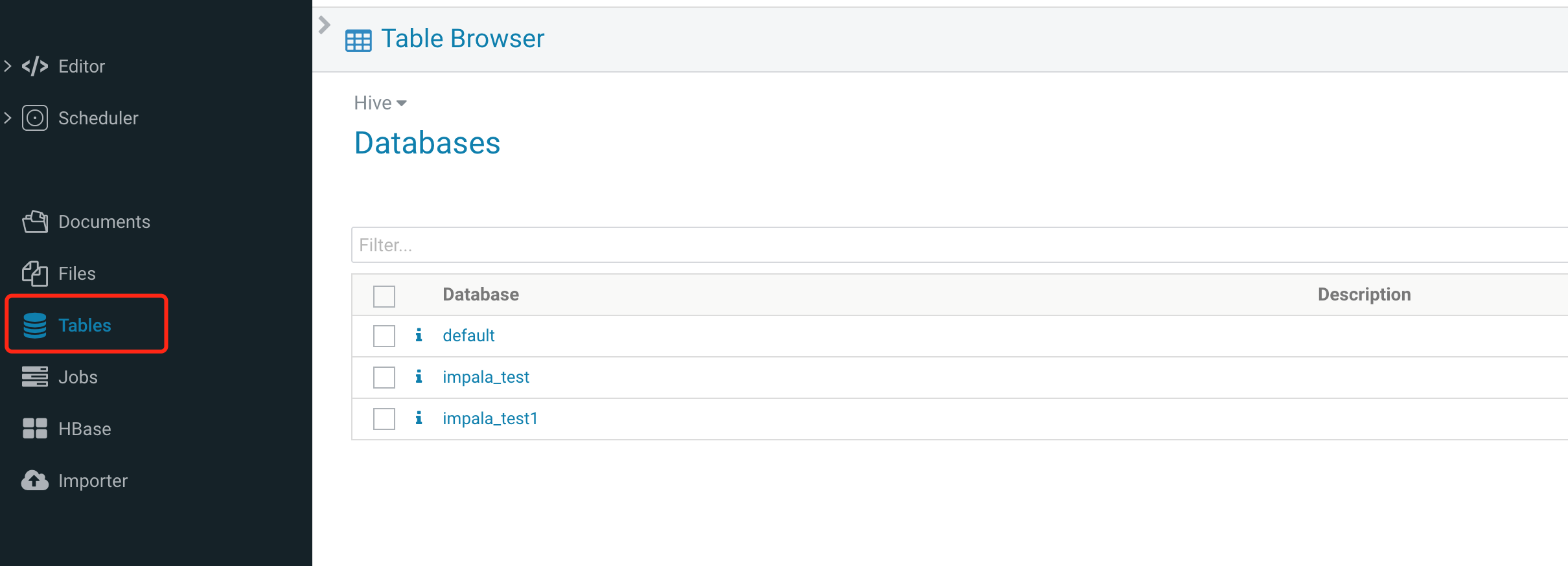
2. 单击其中一个数据库,可查看此数据库的表。
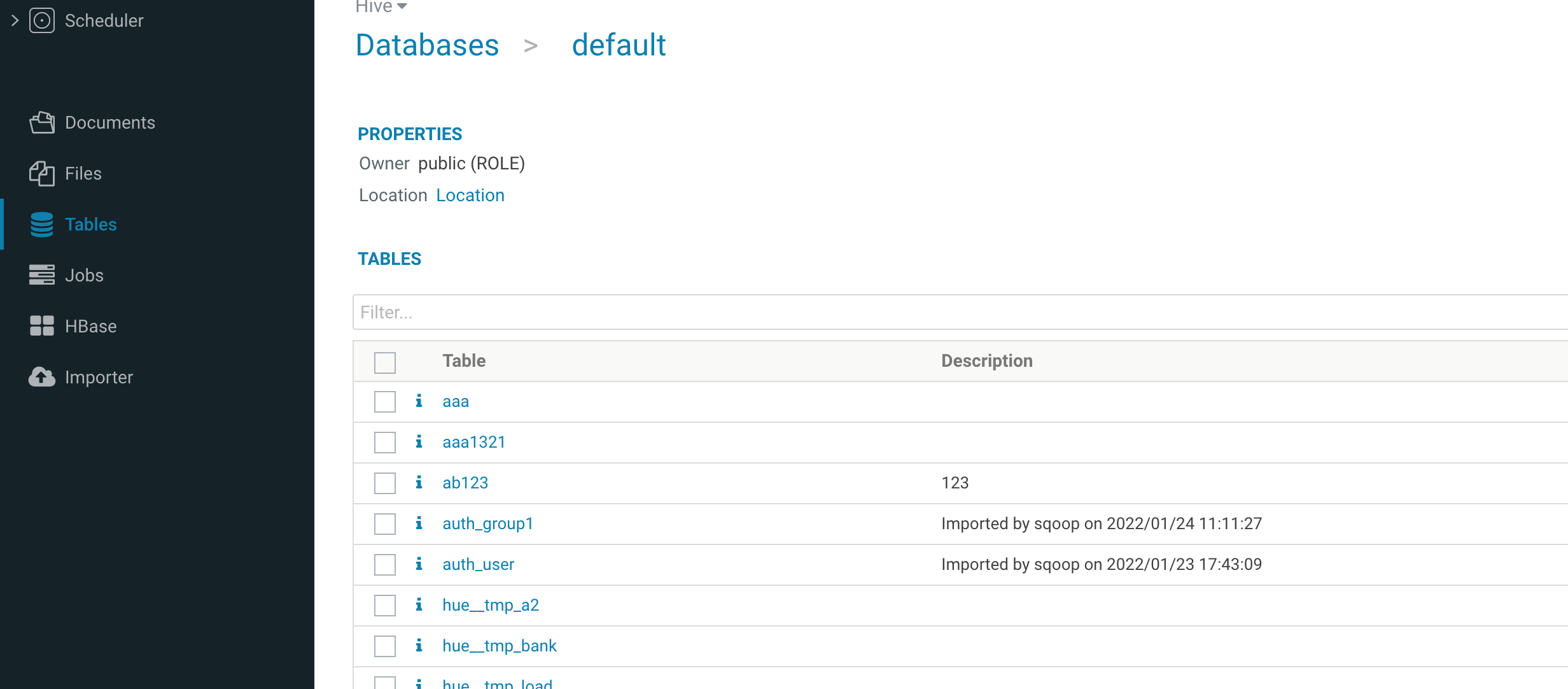
3. 单击各个表,可以查看表的具体详细信息。