本文将为您介绍如何创建加工任务。
前提条件
已开通日志服务,创建源日志主题、并成功采集到日志数据。
已 创建目标日志主题。建议目标日志主题为空主题,便于加工好的数据写入。
确保当前操作账号拥有配置数据加工任务的权限,请参见 CLS 访问策略模板。
操作步骤
1. 登录 日志服务控制台,在左侧导航栏中选择数据加工。
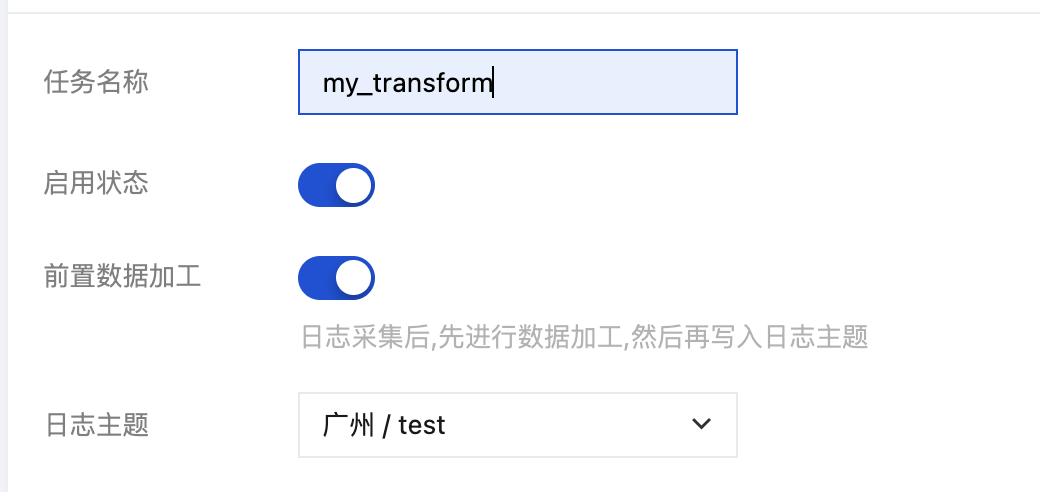
2. 单击新建。配置基本信息:
前置数据加工的价值:
在前置加工中做日志过滤,可有效降低日志索引流量、索引存储量、日志存储量。
前置数据加工的使用场景:
日志采集至 CLS,需要先进行数据加工(过滤、结构化),再写入日志主题。例如:日志主题名为"test",使用 LogListener 采集了数据,现需将 loglevel="Error"的日志写入"test",其余的日志不上报,那么可以创建一个前置数据加工任务"my_transform"来完成。

说明:
每个日志主题仅能配置一个前置加工任务。
前置加工暂不支持分发日志到多个固定日志主题,或动态日志主题。因此您无法在前置加工任务中使用 log_output 和 log_auto_output 函数。
若您新增/修改了采集配置,会导致采集的数据发生变化,因此需要同时调整前置加工的加工语句。
前置加工任务和非前置的加工任务不支持互转。
配置项:
配置项 | 说明 | |
任务名称 | 数据加工任务的名称,示例:my_transform。 | |
启用状态 | 任务启动/停止,默认启动。 | |
前置数据加工 | 打开开关。 前置数据加工的功能入口: 入口1:在新建数据加工任务时,打开前置数据加工的开关。 入口2:您也可以在 采集配置 页面底部,单击数据加工,进入前置数据加工编辑页面。 | |
日志主题 | 指定前置加工结果写入的日志主题。 | |
关联外部数据 | 地域:云 MySQL 所在地域 云数据库 MySQL 实例:请在下拉菜单中勾选 用户名/密码:输入您的数据库用户名/密码。数据加工仅需查询权限,无需编辑及删除权限,配置方式请参见 云数据库 MySQL 修改账号权限。请妥善保管账号信息,不要泄露。 别名:您的 MySQL 的别名,您将在 res_rds_mysql 中使用该别名作为参数。 | |
数据加工服务日志 | 数据加工任务运行日志,保存在 cls_service_log 服务日志主题(免费),数据加工任务监控图表中的告警功能依赖该日志主题,默认开启。 | |
上传加工失败日志 | 开启后,加工失败的日志,将写入目标主题;关闭该选项后,会丢弃加工失败的日志。 | |
加工失败日志字段名 | 如您选择将加工失败的日志写入目标日志主题,失败日志将保存在该字段中,字段名默认为 ETLParseFailure。 | |
高级配置 | 添加环境变量:添加数据加工任务运行时的环境变量。 例如添加一对变量,名称 ENV_MYSQL_INTERVAL,值 300,然后您可在 res_rds_mysql 函数中,使用 refresh_interval=ENV_MYSQL_INTERVAL,任务将解析为 refresh_interval=300。 | |
非前置数据加工主要用于日志分发的场景:
分发至固定日志主题的使用场景。
用于分发的目标日志主题确定的场景。示例:将源日志主题中的 loglevel= warning 日志输出到名称为 WARNING 的日志主题,将 loglevel=error 日志输出到名称为 ERROR 的日志主题,将 loglevel=info 的日志输出到名称为 INFO 的日志主题。请参见 log_output 函数。
分发至动态日志主题的使用场景。
用于分发目标日志主题较多或者无法确定的场景。示例:您的日志中有一个名为"AppName "的 Key (字段), 这个字段由于业务的原因,会随着时间不断的新增 Value,而您需要按照"AppName"来分发日志,适合使用此选项。请参见 log_auto_output 函数。

配置项:
配置项 | 说明 |
任务名称 | 数据加工任务的名称,例如 my_transform。 |
启用状态 | 任务启动/停止,默认启动。 |
前置数据加工 | 关闭开关。 |
源日志主题 | 数据加工任务的数据源。 |
关联外部数据 | 地域:云 MySQL 所在地域。 云数据库 MySQL 实例:请在下拉菜单中勾选。 用户名/密码:输入您的数据库用户名/密码。数据加工仅需查询权限,无需编辑及删除权限,配置方式请参见 云数据库 MySQL 修改账号权限。请妥善保管账号信息,不要泄露。 别名:您的 MySQL 的别名,您将在 res_rds_mysql 中使用该别名作为参数。 |
加工时间范围 | 指定数据加工处理的日志范围。 注意: 仅处理日志主题生命周期内的数据。 |
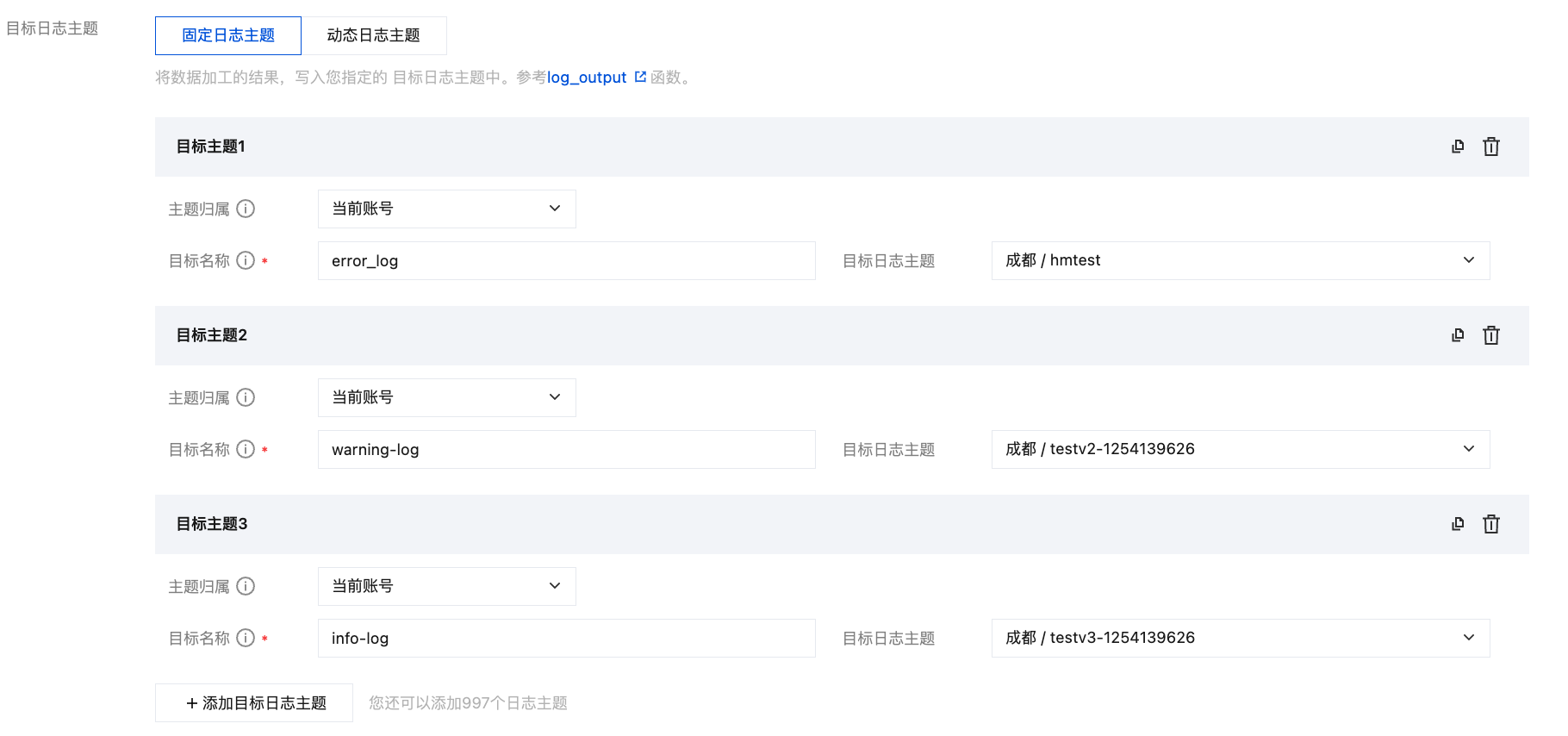
目标日志主题 | 选择固定日志主题: 日志主题:数据加工结果的输出目标,可配置为1个或多个。 目标主题归属: 可选择当前账号/其他主账号的日志主题。 加工结果写入当前账号的日志主题。 加工结果写入其他主账号的日志主题 。例如 A 账号的源日志主题,经过加工之后,写入 B 账号的日志主题,需要 B 账号在 CAM(访问管理)侧配置访问 角色,配置完成之后,由 A 账号将角色 ARN 和外部 ID 填写到 CLS 控制台,方将加工结果写入 B 账号的日志主题。配置角色的步骤如下:1. 新建角色。账号 B 登录 CAM 角色管理页面。 1.1 新建跨账号访问策略,策略名称例如:cross_account,策略语法参考如下: 说明: 示例中的授权按照最小权限的原则,resource 配置为仅可以将加工结果写入 B 账号(100012345678) 在广州地域的日志主题(主题 ID 为 ab3456-123a-56bc-d789-abc654321),请您按照实际情况进行授权。
1.2 新建角色,选择腾讯云账户角色载体,云账号类型选择其他主账号,然后输入 A 账号的 ID,例如100012345678,勾选开启校验并配置外部 ID,例如:Hello123。 1.3 配置角色策略,配置角色的访问策略,选择第一步配置好的访问策略 cross_account(示例)。 1.4 保存该角色,例如:A_ds-cross-account_B。 2. 为角色配置载体。在 CAM 角色列表中找到 A_ds-cross-account_B(示例),单击该角色,选中下方的角色载体 > 管理载体 > 添加产品服务 > 选中日志服务,然后单击更新。 可以看到当前角色的载体是两个:一个是 A 账号,另一个是 cls.cloud.tencent.com(CLS 日志服务)。 3. A 账号登录 CLS,填入角色 ARN 和外部 ID。 该两项信息需 B 账号来提供: B 账号在 CAM 角色列表中找到角色 A_ds-cross-account_B(示例),单击可查看该角色的 RoleArn,例如 qcs::cam::uin/10001234567:roleName/A_ds-cross-account_B。 在角色载体中可看到外部 ID,例如 Hello123。 注意: 填写角色 ARN、外部 ID 时,注意不要输入多余的空格,会导致权限校验失败。 跨账号写入目标日志主题,会在 B 账号下产生日志写流量费用。数据加工的费用计入 A 账号。 目标名称:例如在源日志主题中,将 loglevel= warning 日志输出到日志主题 A,将 loglevel=error 日志输出到日志主题 B,将 loglevel=info 的日志输出到日志主题 C。您可将日志主题 A、B、C 的目标名称分别配置为 warning、error、info。 |
数据加工服务日志 | 数据加工任务运行日志,保存在 cls_service_log 服务日志主题(免费),数据加工任务监控图表中的告警功能依赖该日志主题, 默认开启。 |
上传加工失败日志 | 开启后,加工失败的日志,将写入目标主题,关闭该选项后,会丢弃加工失败的日志。 |
加工失败日志字段名 | 如您选择将加工失败的日志写入目标日志主题,失败日志将保存在该字段中,字段名默认为 ETLParseFailure。 |
高级配置 | 添加环境变量:添加数据加工任务运行时的环境变量。 例如添加一对变量,名称 ENV_MYSQL_INTERVAL,值 300,然后您可在 res_rds_mysql 函数中,使用 refresh_interval=ENV_MYSQL_INTERVAL,任务将解析为 refresh_interval=300。 |
配置项 | 说明 |
任务名称 | 数据加工任务的名称,例如 my_transform。 |
启用状态 | 任务启动/停止,默认启动。 |
前置数据加工 | 关闭开关。 |
源日志主题 | 数据加工任务的数据源。 |
关联外部数据 | 地域:云 MySQL 所在地域。 云数据库 MySQL 实例:请在下拉菜单中勾选。 用户名:输入您的数据库用户名。 密码:输入您的数据库密码。 别名:您的 MySQL 的别名,您将在 res_rds_mysql 中使用该别名作为参数。 |
加工时间范围 | 指定数据加工处理的日志范围。 注意: 仅处理日志主题生命周期内的数据。 |
目标日志主题 | 选择动态日志主题。无需配置目标日志主题,会按照指定的字段值,自动生成。 |
超限处理 | 创建兜底日志集、日志主题并将日志写入兜底主题(创建任务时创建)。 兜底日志集:auto_undertake_logset,单地域单账号下一个。 兜底日志主题:auto_undertake_topic_$(数据加工任务名称)。例如用户创建了两个数据加工任务 etl_A 和 etl_B,那么会产生两个兜底主题:auto_undertake_topic_etl_A、auto_undertake_topic_etl_B。 丢弃日志数据:不创建兜底主题,直接丢弃日志。 |
数据加工服务日志 | 数据加工任务运行日志,保存在 cls_service_log 服务日志主题(免费),数据加工任务监控图表中的告警功能依赖该日志主题,默认开启。 |
上传加工失败日志 | 开启后,加工失败的日志,将写入目标主题,关闭该选项后,会丢弃加工失败的日志。 |
加工失败日志字段名 | 如您选择将加工失败的日志写入目标日志主题,失败日志将保存在该字段中,字段名默认为 ETLParseFailure。 |
高级配置 | 添加环境变量:添加数据加工任务运行时的环境变量 例如添加一对变量,名称 ENV_MYSQL_INTERVAL,值 300,然后您可在 res_rds_mysql 函数中,使用 refresh_interval=ENV_MYSQL_INTERVAL,任务将解析为 refresh_interval=300。 |
3. 配置完成后单击下一步。
4. 编辑/调试加工语句。在页面左下方,您可以看到原始日志和测试数据两个标签,页面右下方是加工结果。支持通过对比原始/测试数据和加工结果,来调试您的加工语句。
原始日志:系统会自动加载原始日志数据,默认100条。
测试数据:系统随机加载的原始数据,可能无法满足您的调试需求,那么您可在原始数据页签,单击加入测试数据,将原始日志加入到测试数据中,然后在测试数据页签,修改这些数据,使其满足您的调试需求。
您可选择语句模式或交互模式来编写加工语句。
方法一:使用 AI 生成加工语句(推荐)
单击原始日志右上角的 AI 图标,可将该原始日志加入到日志服务 AI 助手的对话框,然后用自然语言描述您的加工需求,例如“保留 Loglevel=Error 的日志”,“对该日志进行结构化”,然后单击发送图标,AI 助手会给出加工的语句,您可复制该语句到加工语句编辑框。如果 AI 给出的语句不准确,您可通过多轮对话来获取准确的加工语句,举例说明如下。
原始日志中的待加工的日志:
{"content": "[2021-11-24 11:11:08,232][328495eb-b562-478f-9d5d-3bf7e][INFO] curl -H 'Host: ' http://abc.com:8080/pc/api -d {\\"version\\": \\"1.0\\",\\"user\\": \\"CGW\\",\\"password\\": \\"123\\"}"}
和 AI 多轮对话:
对话轮次 | 用户问题 | AI 助手答复 |
第一轮对话 | 结构化该日志 |
|
第二轮对话 | content 不是标准 JSON,使用 ext_json 报错了,您把 content 中的 json 部分先提取出来,然后再从 json 中提取节点 |
|
加工结果:
{"level":"INFO","password":"123","requestid":"328495eb-b562-478f-9d5d-3bf7e","time":"2021-11-24 11:11:08,232","user":"CGW","version":"1.0"}
方法二:手动编写语句
您可在编辑加工语句页面切换至交互模式。
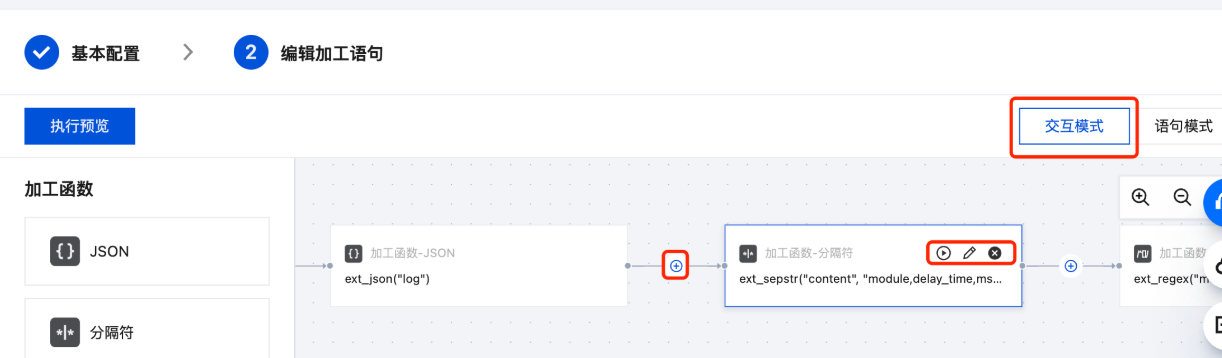
添加可视化函数:单击
调试可视化函数:单击可视化函数右上角的▶️。
删除可视化函数:单击可视化函数右上角的 X。
编辑可视化函数:单击可视化函数右上角的 
当前支持的可视化函数如下:
函数大类 | 可视化函数名称 | 使用场景 |
提取键值 | JSON:从 JSON 节点中提取字段和字段值 分隔符:根据分隔符提取字段值,需要用户填字段名 正则:根据正则公式提取字段值,需要用户填写字段名 | 日志结构化 |
日志处理 | 过滤日志:配置过滤日志的条件(多个条件为 OR 的关系)。例如字段 A 存在,或者字段 B 不存在,则过滤掉该条日志。 分发日志:配置分发日志的条件 例如 status="error"且 message 中包含 "404"的,分发至 A 主题 例如 status="running"且 message 中包含 "200"的,分发至 B 主题 保留日志:配置保留日志的条件 | 删除/保留日志 |
字段处理 | 删除字段 重命名字段 | 删除/重命名字段 |
完成 DSL 加工语句的编写后,单击页面左上角执行预览或者断点调试(交互模式下为可视化函数右上角的▶️),运行和调试 DSL 函数。运行结果会在右侧展示,您可以根据运行结果,调整 DSL 语句,直到满足您的需求。
5. 单击确定,提交数据加工任务。



