功能概述
流量接入,又称域名接入,是指将大模型业务域名以 CNAME 解析或 CLB 监听器挂载的方式对接到 WAF,使访问大模型接口的 HTTP/HTTPS(含 SSE 流式)流量经过 WAF 检测。完成接入后,无需修改业务代码,即可在 WAF 控制台对该域名下的大模型接口统一配置算力消耗、提示词注入、内容安全、敏感信息识别等策略。
接入便捷:通过修改 DNS 解析或挂载 CLB 监听器完成接入,业务代码一般无需调整。
SSE 流式支持:针对大模型的 Server-Sent Events 长连接场景,提供专属 SSE 协议接入能力。
与 CLB 打通:已使用腾讯云 CLB(七层负载均衡)的用户,可较为便捷地将 CLB 后端流量接入 WAF 并启用大模型安全。
会话级聚合:基于会话标识(Session ID)聚合多轮对话上下文,支持上下文相关的检测与限流。
操作场景
本文介绍如何通过流量接入方式将大模型业务接入 WAF 大模型安全模块,并完成会话标识和大模型防护路径两项基础业务参数配置,使 WAF 能够正确识别大模型流量并开展安全检测。
适用场景:
大模型业务部署在独立域名下,可以修改 DNS 解析或已使用腾讯云 CLB
希望在不改动业务代码的前提下统一管理大模型安全策略
业务场景以纯文本对话为主(暂无图片等多模态检测需求)
不适用场景(请改用 SDK/API 接入):
大模型业务部署在腾讯云外或自建 AI Agent,不希望迁移域名
需要多模态(图片)内容安全检测
需要使用安全代答能力
前提条件
操作步骤
目前大模型安全模块支持 SaaS 型 WAF 和 CLB 型 WAF 开启接入。
步骤一:确认域名已接入 WAF
若业务域名尚未接入 WAF,请先完成域名接入:
SaaS 型 WAF:参见 接入 SaaS 型 WAF。
云原生 型 WAF:参见 接入云原生型 WAF。
说明:
若大模型使用 SSE(Server-Sent Events)协议进行业务交互,WAF 将能对算力消耗、请求内容和响应内容进行安全检测。如果大模型未使用 SSE 协议,目前仅支持对算力消耗和请求内容进行安全检测。
步骤二:配置会话标识
大模型业务拦截需要针对单个用户维度进行风险识别和拦截,实现在同一 IP 下区分不同用户的处置。因此需要配置会话标识(Session ID)。
1. 登录 WAF 控制台,在左侧导航栏选择大模型安全 > 防护配置。
2. 在防护配置页面,选择已接入的目标域名,单击会话标识设置进行配置。
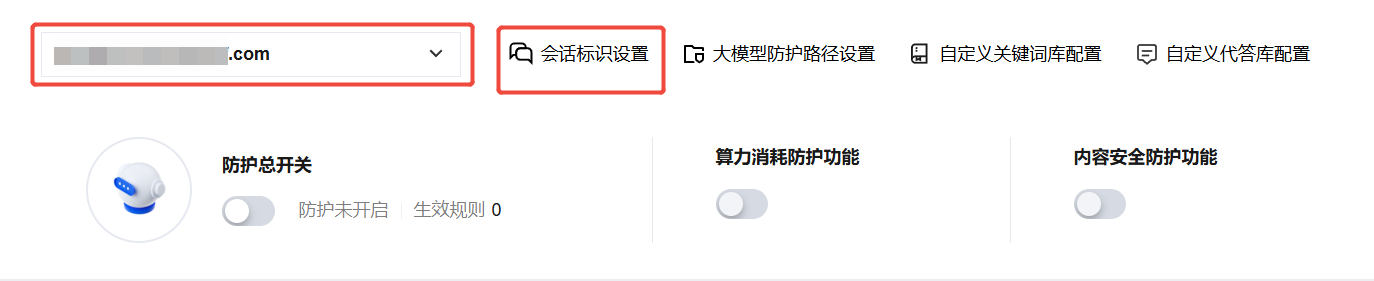
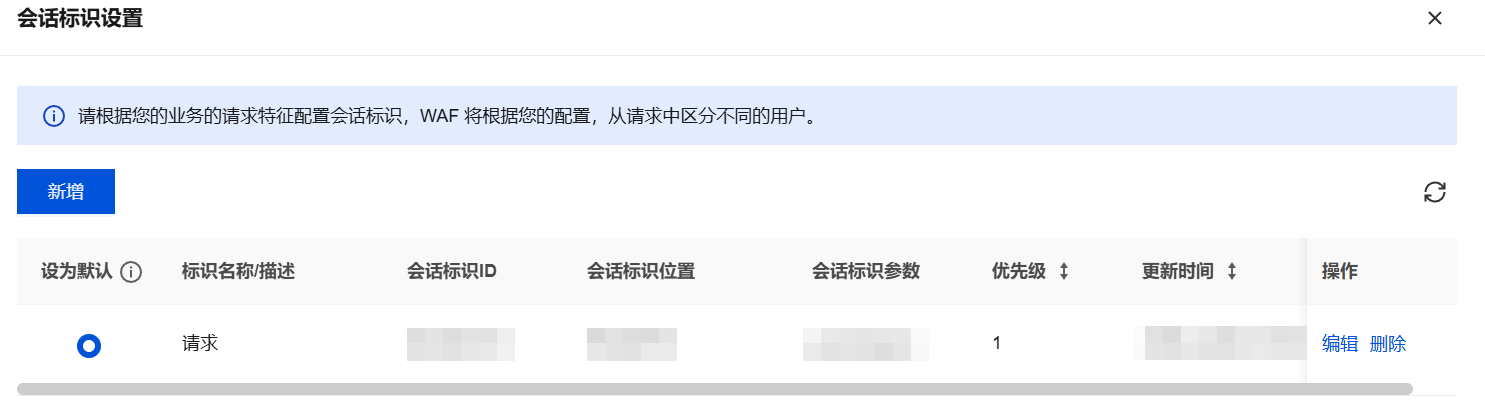
3. 在会话标识设置页面,单击新增,新增一个会话标识提取配置。
说明:
会话标识应为可持续记录的 Token ID,例如登录后的 Set-Cookie 的值。
4. 在新增会话标识窗口中,配置相关参数,单击确定。
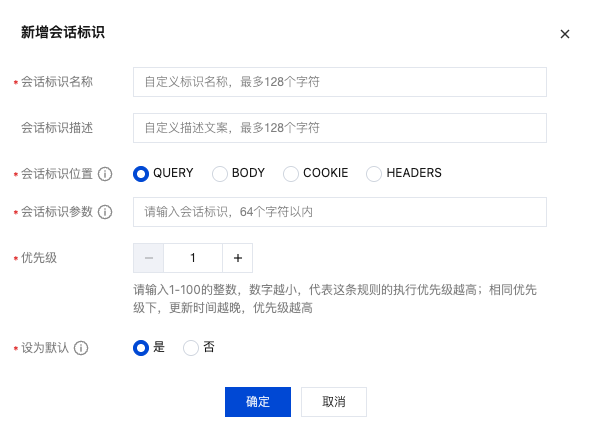
字段名称 | 说明 |
会话标识位置 | 指定识别特定位置(QUERY、BODY、COOKIE 或 HEADERS)的参数名作为会话标识,以该参数名对应的值作为会话 ID。 |
会话标识参数 | 取值标识,以.字符分隔各个层级的参数,示例如下: test:识别 JSON 字符串中 test 参数的值为会话 ID。 test1.test2:识别 JSON 字符串中 test1包含的 test2参数的值为会话 ID。 除了 HEADERS 以外,其余配置均需要区分字母大小写。 |
优先级 | 支持输入1-100的整数,数字越小优先级越高,优先匹配对应设置的会话标识。优先级相同时,更新时间越晚越优先。 |
设置默认 | 支持设置默认会话标识,设置默认后,则在创建安全策略时默认使用该会话标识配置进行提取。 |
说明:
配置完成后,会话标识将显示在会话标识设置列表中。可以在列表中查看、编辑或删除已配置的会话标识。
步骤三:配置大模型防护路径
由于不同大模型的防护路径及其对应的 Prompt 和 Response 字段位置各不相同,需要明确 WAF 应从哪个路径和字段提取内容进行匹配。因此,需要为接入的大模型业务定义具体的防护路径。
1. 登录 WAF 控制台,在左侧导航栏选择大模型安全 > 防护配置。
2. 在防护配置页面,选择已接入的目标域名,单击大模型防护路径设置进行配置。
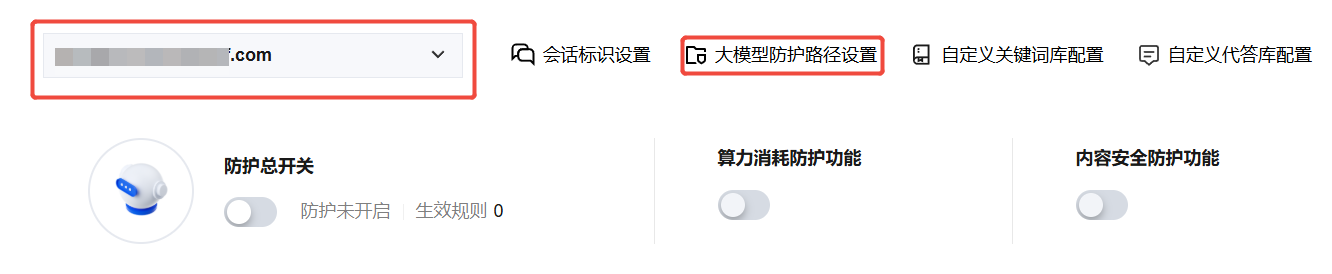
3. 单击新增,设置大模型防护路径。
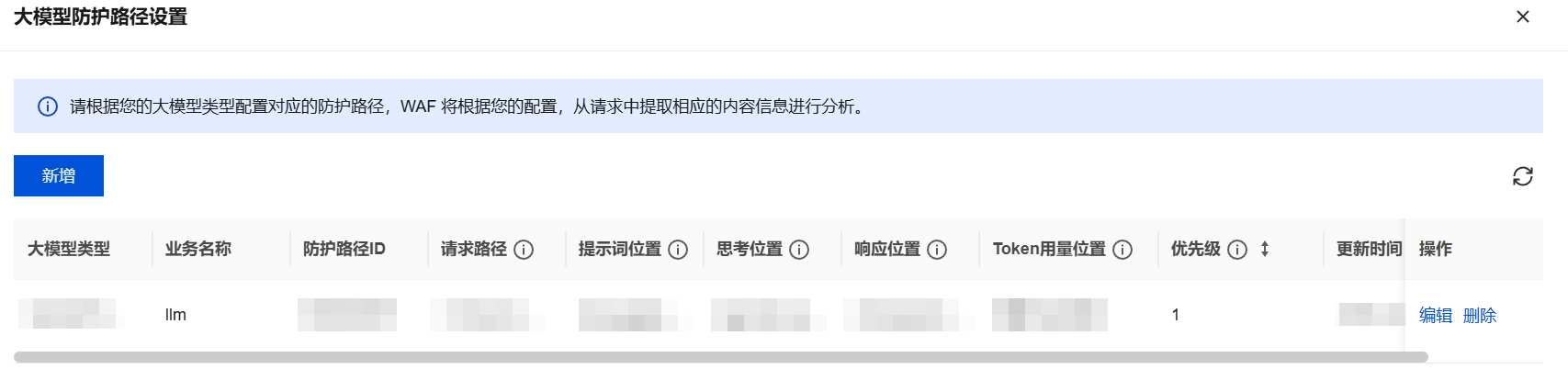
4. 在新增大模型防护路径窗口中,配置相关参数,单击确定。
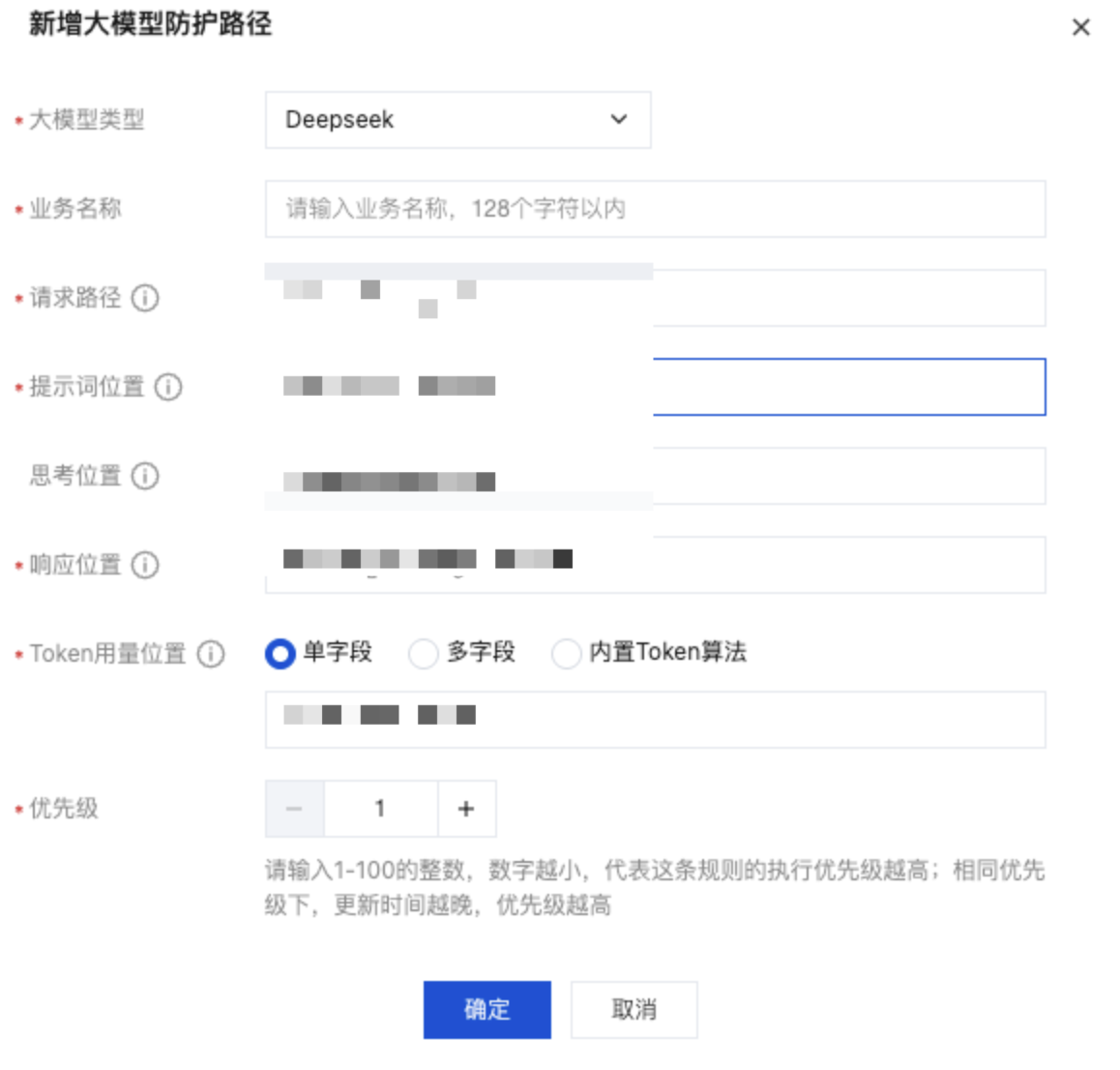
字段名称 | 说明 |
大模型类型 | 系统内置了部分标准的大模型路径参数,根据自己的大模型后端服务类型选择填充,或者选择自定义填充。 |
大模型业务名称 | 限制 128 个字符,输入大模型业务名称,用于在规则配置页展示和选择。 |
请求路径 | 配置大模型业务的请求路径,例如 /v1/chat。限制 128 个字符。 |
提示词位置 | 配置大模型业务的提示词字段,可使用参数名或数组形式。例如: 配置 prompt表示提取 prompt 的参数值;配置 content.0.prompt表示提取 content 数组第一个元素的 prompt 参数值;配置 content|@reverse|0.prompt表示提取 content 数组的最后一个元素的 prompt 参数值。限制为 128 个字符。 说明: 未开启连续对话检测时,输入格式为 content.0.prompt(检测第一个)或 content|@reverse|0.prompt(检测最后一个)。 开启连续对话检测时,输入格式为 content.#.prompt(从第一个开始检测)或 content.#reverse.prompt(倒序,从最后一个开始检测)。 |
连续对话内容检测 | 开启后,WAF 将根据配置的提示词位置提取最新 N 轮的 prompt 内容,发送给 prompt 注入检测模型进行检测。任意一轮对话命中即视为攻击。默认关闭。 |
最大检测对话轮数 | 设置连续对话内容检测的最大轮数,范围 1-20,默认为 5。仅在连续对话内容检测开启后生效。 |
思考位置 | 如果大模型业务为思考大模型,请在此配置大模型业务的思考内容字段。支持参数名或数组形式,例如: 配置 thinking 则提取 thinking 参数值内容; 配置 content.0.thinking 则提取 content 数组第一个元素的 thinking 参数值内容; 配置 content|@reverse|0.thinking 则提取 content 数组最后一个元素的 thinking 参数值内容。 字符限制为 128 个。 |
响应位置 | 配置大模型业务的响应内容字段,支持参数名或数组形式。例如: 配置 response,提取 response 的参数值; 配置 content.0.response,提取 content 数组第一个元素的 response 参数值; 配置 content|@reverse|0.response,提取 content 数组最后一个元素的 response 参数值。 限制 128 个字符。 |
Token 用量位置 | 配置客户的大模型业务的 token 用量对应的字段,限制 128 个字符,可以选择三种配置方式: 内置 token 算法:当选择此方案时,调用 WAF 内置算法计算 token。 单字段:当选择此方案时,读取每个请求中该字段的值并汇总计算总 token 量值。 多字段:当选择此方案时,读取每个请求中的请求和响应两个字段的值,并加起来,作为单次请求的总 token 值。 |
优先级 | 配置优先级,优先级逻辑:请输入1-100的整数,数字越小,代表这条规则的执行优先级越高;相同优先级下,更新时间越晚,优先级越高。 |
说明:
配置完成后,大模型防护路径将显示在大模型防护路径设置列表中。WAF 会根据配置的路径和字段提取大模型交互内容进行安全检测。
后续步骤
完成后,可以进行以下操作:
配置防护策略:前往 大模型安全 > 防护配置页面 配置算力消耗防护规则和内容安全防护规则。
查看安全日志:前往 大模型安全 > 日志审计页面 查看大模型安全模块的检测和拦截记录。
流量接入示例
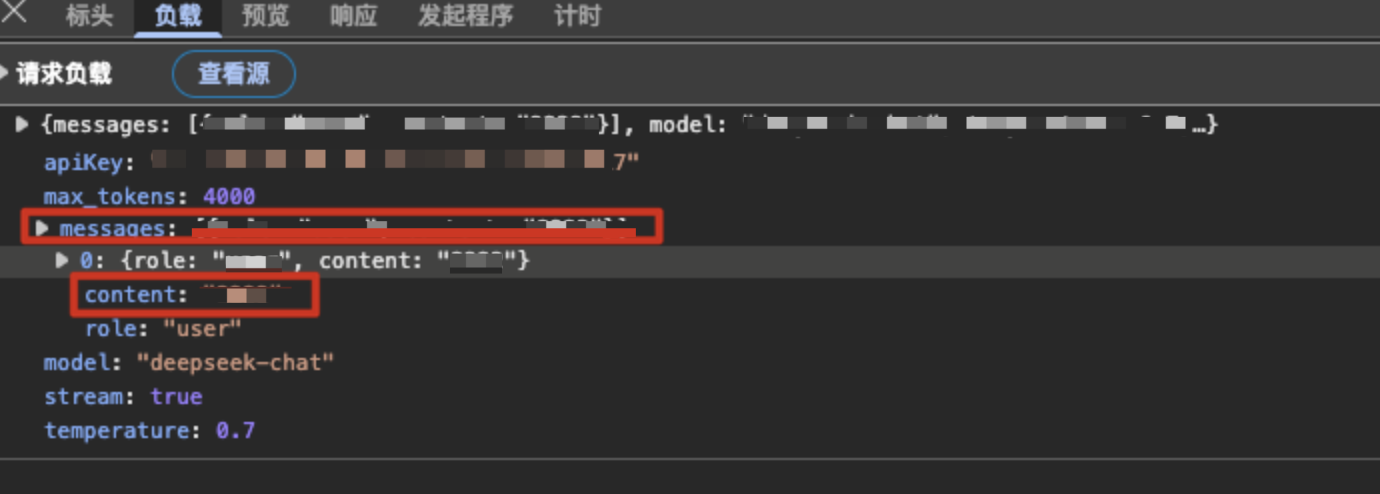
1. 根据前端大模型的交互路径配置防护路径,可以通过浏览器开发者工具(按 F12 键打开)查看业务前端对应的请求和响应数据。例如,Demo 业务中对应请求、响应和 Token 用量的字段分别如下:
请求
响应
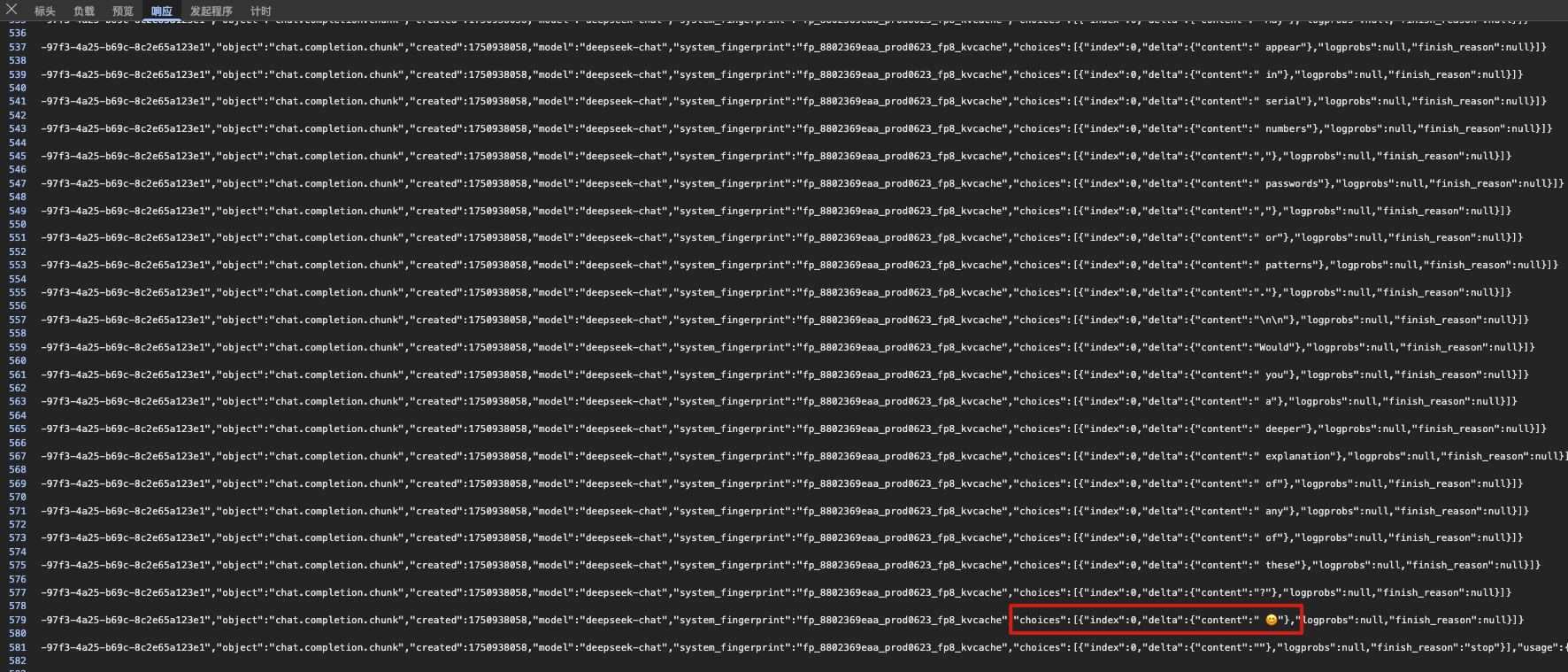
Token 消耗量:为单字段总消耗量。

2. 在 大模型安全 > 防护配置页面,单击大模型防护路径设置,则对应的大模型防护路径配置如下:
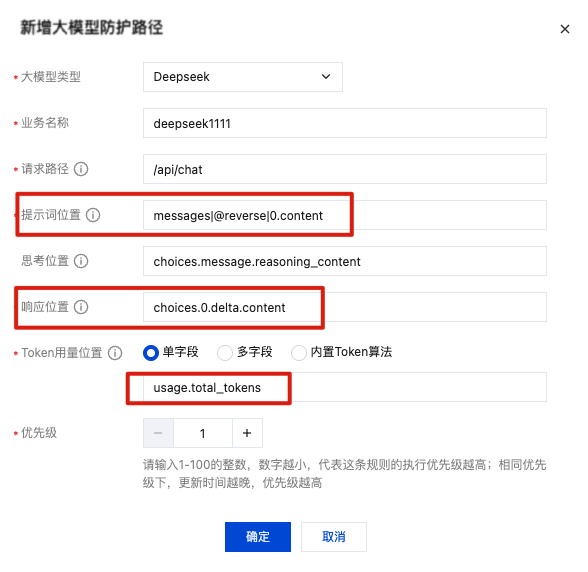
字段名称 | 说明 |
提示词位置 | 配置值为 messages\\|@reverse\\|0.content。含义为请求负载中 messages 数组最新一个元素中(倒序)的 content 字段的值。 |
响应位置 | 配置值为 choices.0.delta.content。含义为响应 data 中 choices 数组的第一个元素 delta 对象中 content 字段的值。 |
Token 用量位置 | 配置值为 usage.total_tokens。含义为用 usage 对象中 total_tokens 字段的值作为 Token 消耗量的计算值。 |



