总览
本文以 qwen2-0.5b-instruct 为例,展示如何使用 TI-ONE 平台精调用户自定义大模型,并通过在线服务将精调后的模型推理部署。这里我们使用到的训练框架为开源 LLaMA-Factory,并对 qwen2-0.5b-instruct 进行全参 sft 微调,最后使用平台内置镜像 Angel-vLLM 对训练后的模型进行推理部署。
前置要求
申请 CFS 或者 GooseFSx:在自定义大模型精调过程中训练数据、模型、代码等使用到的存储可以为 CFS 或者 GooseFSx ,所以需要您首先申请 CFS 或者 GooseFSx,详情请查看 文件存储-创建文件系统及挂载点 或者 数据加速器 GooseFS。
操作步骤
物料准备
说明:
目前 TI-ONE 平台不支持在控制台直接进行数据上传操作,为了解决此问题,需要创建一个运维开发机以挂载 CFS 或者 GooseFSx 并使用开发机服务进行上传或下载大模型、训练代码等文件。
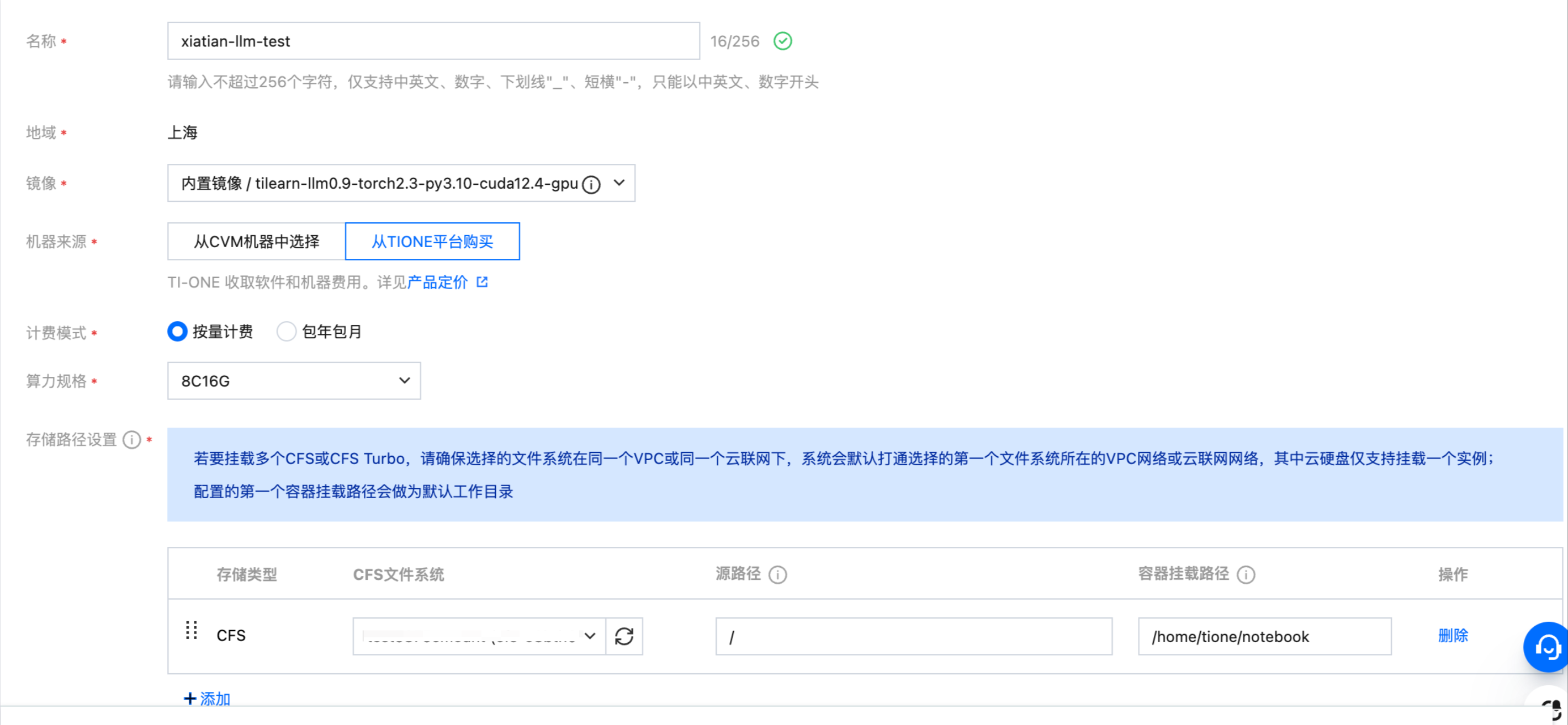
单击训练工坊 > 开发机 > 新建按钮,创建调试训练代码用的开发机,
镜像:选择任意内置镜像即可,本开发机实例仅用于下载模型文件以及训练代码。
机器来源:选择从 TIONE 平台购买按量计费模式,若您需要从 CVM 机器中选择或包年包月,请参考 资源组简介 管理您的机器资源。
计费模式:选择按量计费或包年包月均可,平台支持的计费规则请您查看 计费概述。
存储配置:选择 CFS 或者 GooseFSx 文件系统,名称为上文前置要求中申请配置好的 CFS 或者 GooseFSx,路径默认为根目录 /,用于指定保存用户自定义大模型位置。
其它设置:默认不需要填写。
最终开发机服务配置如下:
模型文件
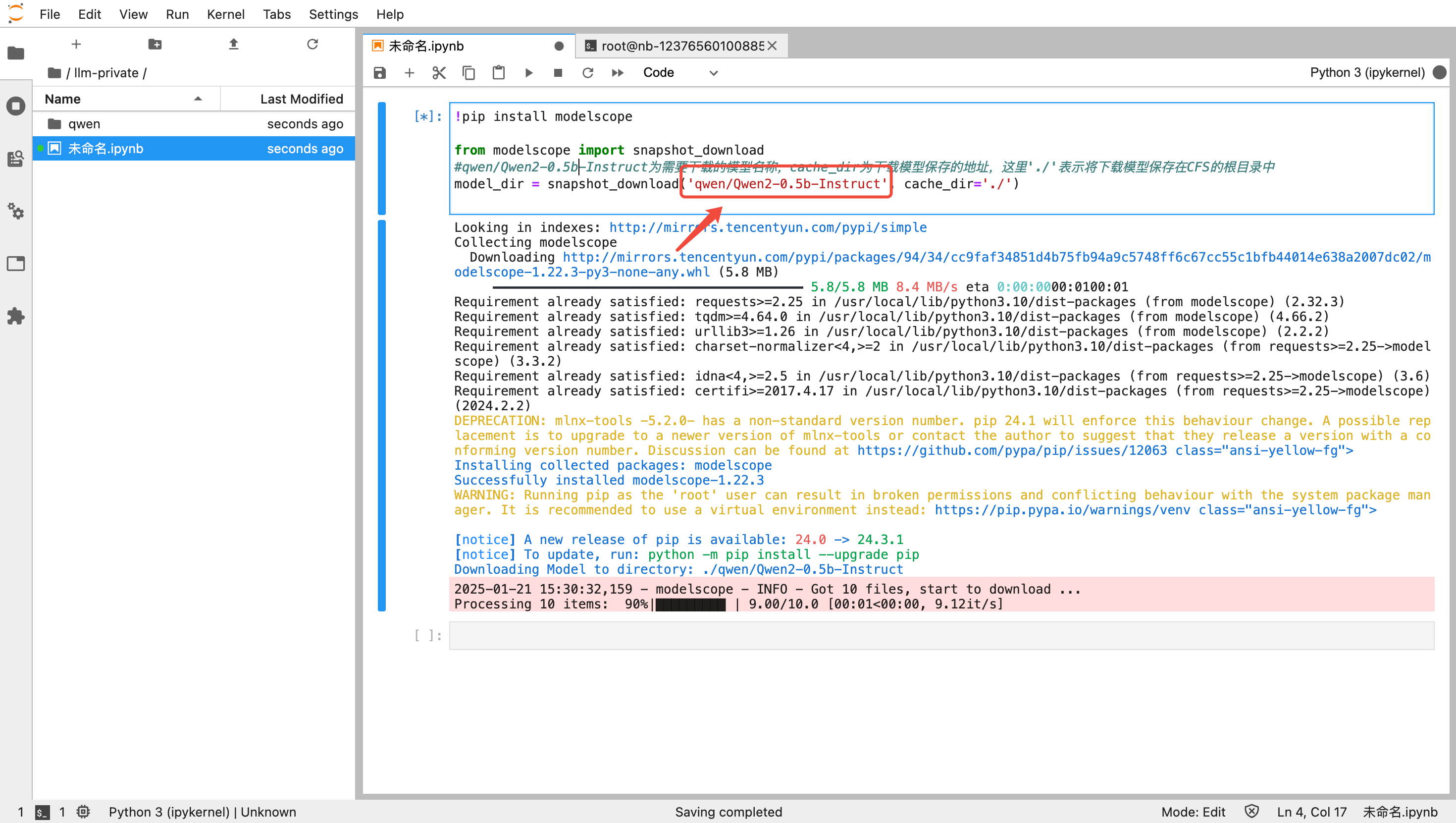
新建成功后,单击开发机 > Python3(ipykernel) 通过脚本下载所需模型;您可在 魔搭社区 或 Hugging Face 检索需要用到的大模型,通过社区中 Python 脚本自行下载模型并保存到 CFS 中,本文以 Qwen2-0.5B-Instruct 模型为例,下载代码如下:
!pip install modelscopefrom modelscope import snapshot_download#qwen/Qwen2-0.5b-Instruct为需要下载的模型名称,cache_dir为下载模型保存的地址,这里'./'表示将下载模型保存在CFS挂载目录的根目录中model_dir = snapshot_download('qwen/Qwen2-0.5b-Instruct', cache_dir='./')
说明:
指定下载模型的地址 cache_dir 在后续任务是建模中的位置为挂载开发机的 path+cache_dir,例如:挂载开发机的路径为 /dir1,cache_dir 为 /dir2,则文件在 CFS 中的位置为 /dir1/dir2。
复制上述下载脚本并更换需要下载的模型后,粘贴到新建的 ipynb 文件中,单击运行按钮,即可开始下载模型。
训练代码
下载 LLaMA-Factory 代码
直接通过 git clone 下载到 CFS 中,单击 Terminal 输入如下命令,如果需要用最新代码,请使用 main 分支。
git clone -b v0.9.2 https://github.com/hiyouga/LLaMA-Factory.git
如果您创建时打开了"SSH 连接",您还可以使用 scp 将本地物料上传至开发机。
scp -r -P <port> Qwen2-0.5B-Instruct root@host:/home/tione/notebook/workspace
Tips: 如您的文件由 git 下载,您可以尝试删除目录下的 .git 目录,可减少上传的文件,提升上传速度。
修改训练配置文件
进入 LLaMa-Factory/examples/train_full 目录,复制 qwen2vl_full_sft.yaml 重命名为 qwen2_full_sft.yaml 并编辑相应内容。
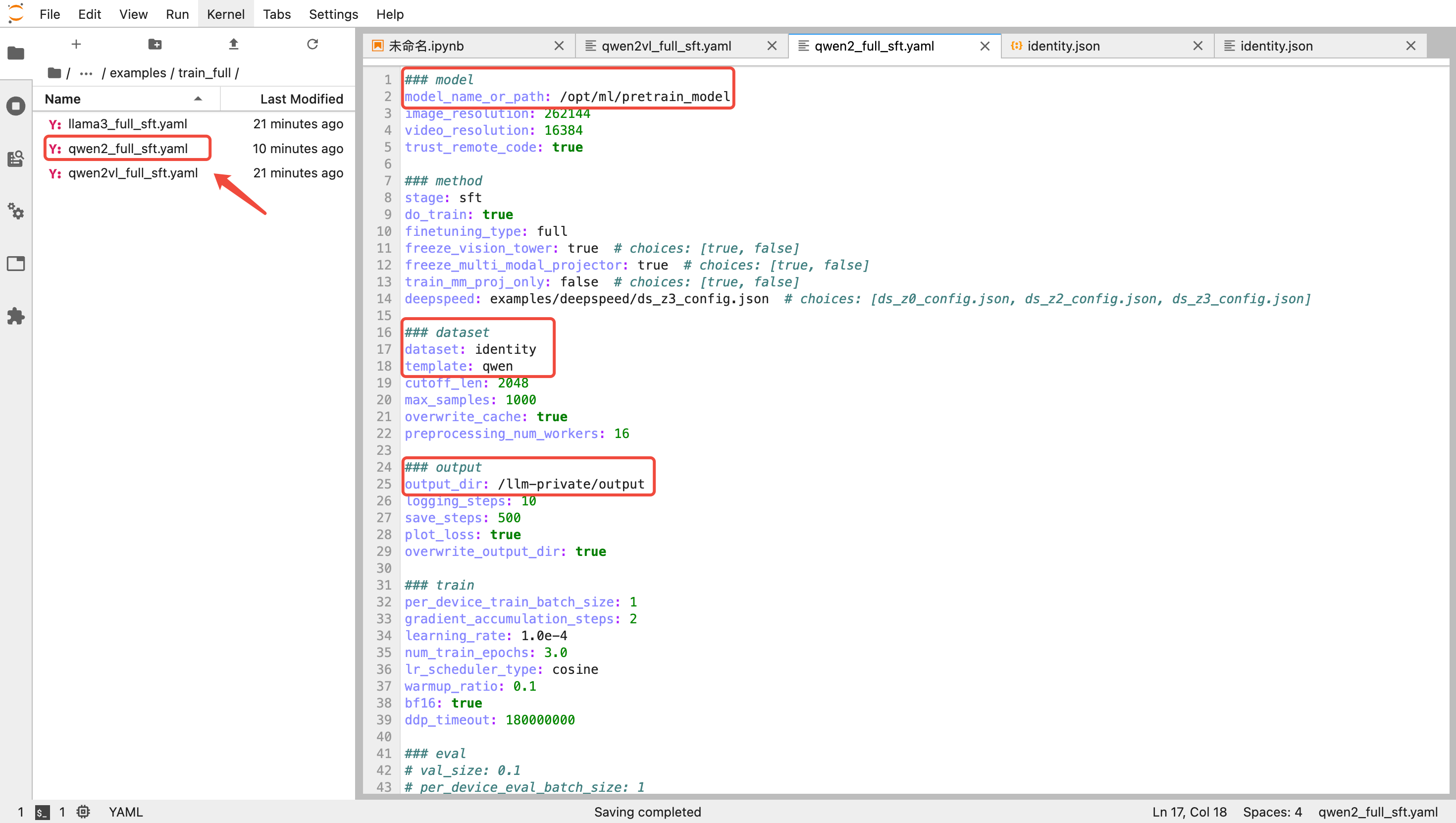
训练使用的参考数据集在 LLaMa-Factory/data 下,这里用到的数据集为 identity.json (您可将其中的"{{name}}"和"{{author}}"替换以验证精调效果),下面为主要需要修改的超参内容,您也可以根据官方文档按需调整:
# 预训练模型路径model_name_or_path: /opt/ml/pretrain_model# 训练数据dataset:identitytemplate:qwen# 训练输出路径output_dir: /llm-private/output# 训练轮数(为了快速验证可以适当调小)num_train_epochs: 3.0
说明:
这里的目录对应到后续任务式建模相关容器挂载目录。
若需要自定义数据集,请修改 dataset 字段,并进入 LLaMa-Factory/data 目录修改 dataset_info.json 文件配置对应的数据集信息。
若需要修改其他训练参数,请自行修改。
若模型较小,容易过拟合,建议调小 learning_rate。
创建启动脚本
在 LLaMA-Factory 目录内创建一个 start.sh 文件,作为训练启动脚本,内容如下:
#!/bin/bashTRAIN_CONFIG=$1DISTRIBUTED_ARGS="--nproc_per_node ${NPROC_PER_NODE:-$(nvidia-smi -L | wc -l)} \\--nnodes ${WORLD_SIZE:-1} \\--node_rank ${RANK:-0} \\--master_addr ${MASTER_ADDR:-127.0.0.1} \\--master_port ${MASTER_PORT:-23456}"set -extorchrun $DISTRIBUTED_ARGS src/train.py $TRAIN_CONFIG
上述启动脚本兼容任务式建模分布式训练启动。
任务式建模启动精调任务
创建训练任务
单击训练工坊 > 任务式建模 > 创建任务按钮,训练镜像选择一开始准备的镜像,训练模式选择“DDP”,资源配置按需选择。如果需要多机分布式训练,可以选择8卡并配置节点数大于1。
训练镜像:选择内置镜像 /PyTorch/tilearn-llm0.9-torch2.3-py3.10-cuda12.4-gpu,该镜像已默认配置了大模型训练运行时环境。
机器来源:请参考 开发机 > 算力资源。
算力规格:请合理选择训练资源,如果需要多机分布式训练,可以选择8卡并配置节点数大于1。
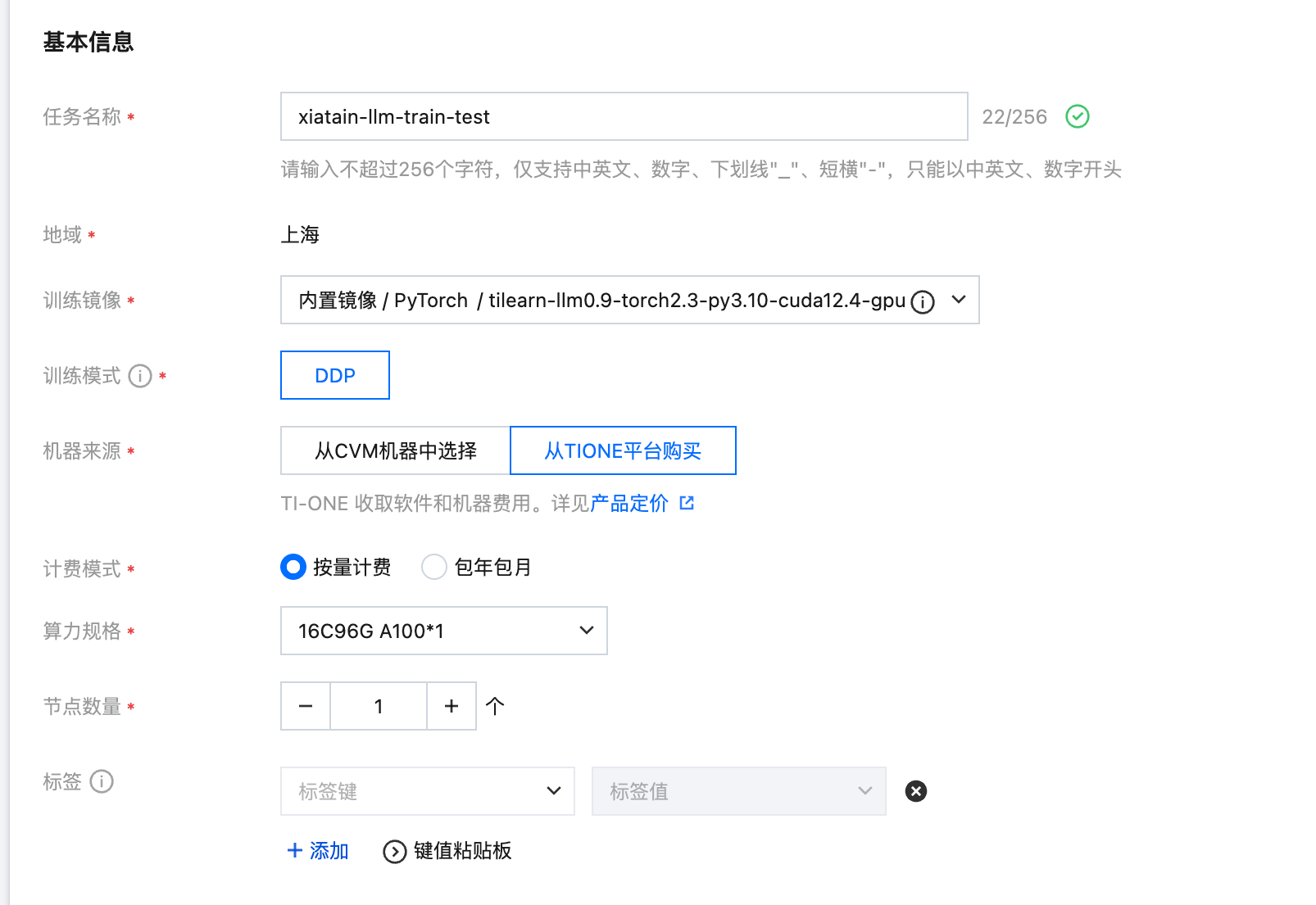
存储路径配置:这里需要挂载的内容有训练代码、预训练模型与训练输出路径,其中容器的挂载路径对应上文训练配置文件中的相关参数(您也可将训练代码、预训练模型与训练输出放在同一个大目录下,并将根目录挂入容器,最后修改启动命令 cd 到 LLaMA-Factory 下即可)。
启动命令:(由于 LLaMA-Factory 主分支依赖比较高版本的 transformers 库,因此我们在启动命令中在线升级平台训练镜像的对应第三方库版本,最终写入如下启动命令):
cd /opt/ml/codepip3 install -r requirements.txt -i https://mirrors.tencentyun.com/pypi/simplebash start.sh examples/train_full/qwen2_full_sft.yaml
查看训练状态
任务启动后,可以单击日志查看训练日志等信息。
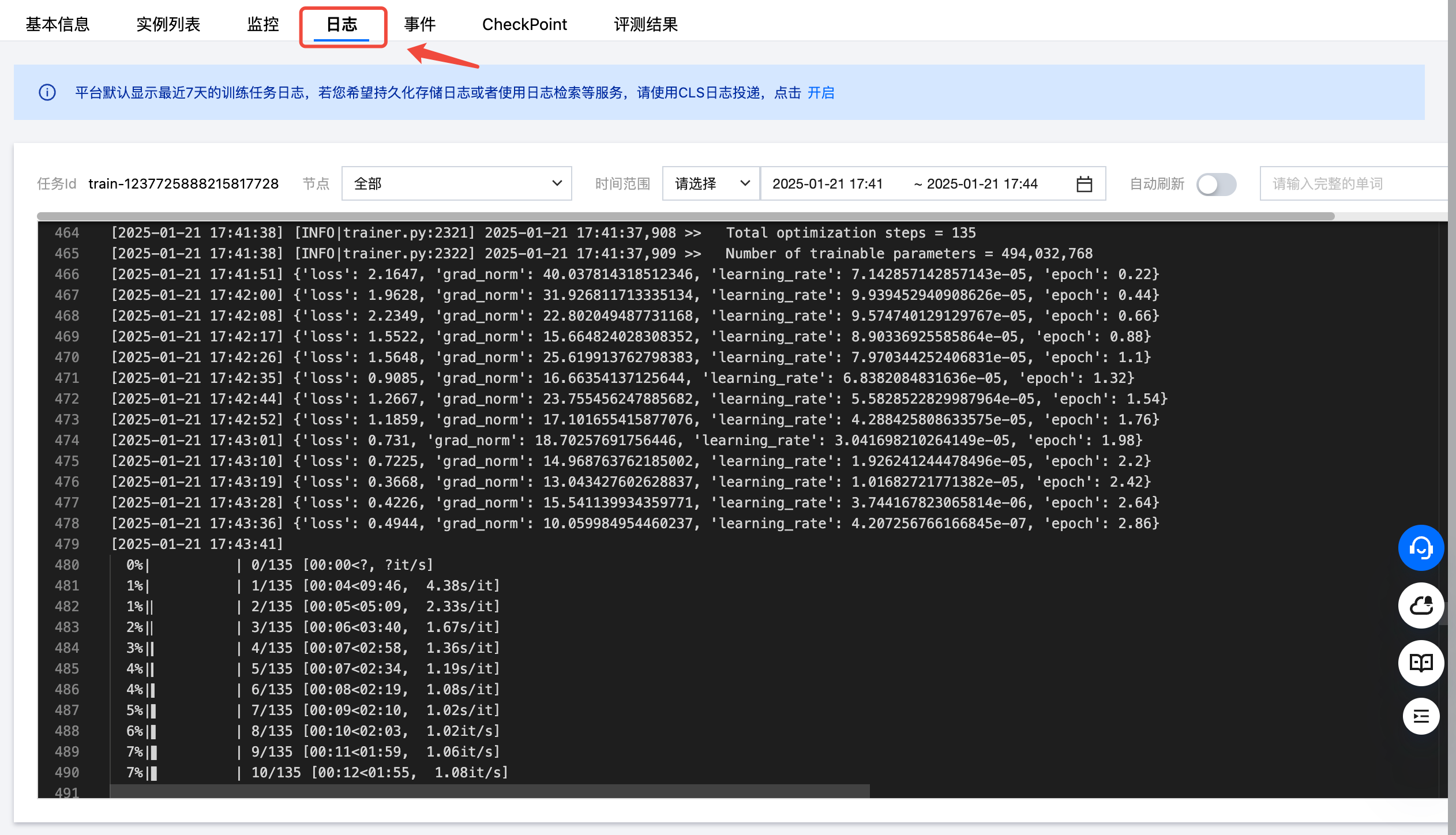
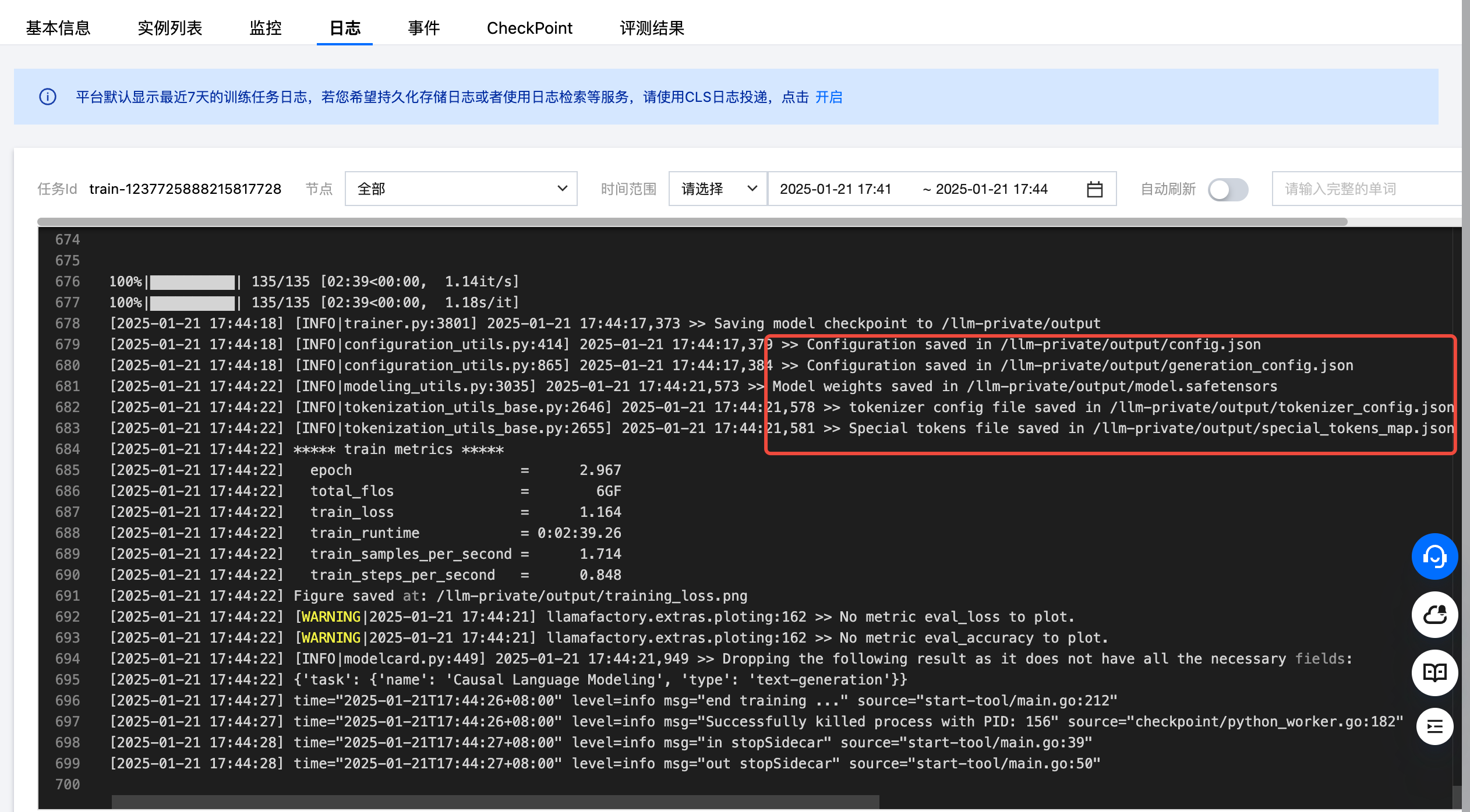
训练结束后,会将最终的 checkpoint 保存到挂载的输出目录 /project/output 中,该目录用于后续部署精调后的模型。
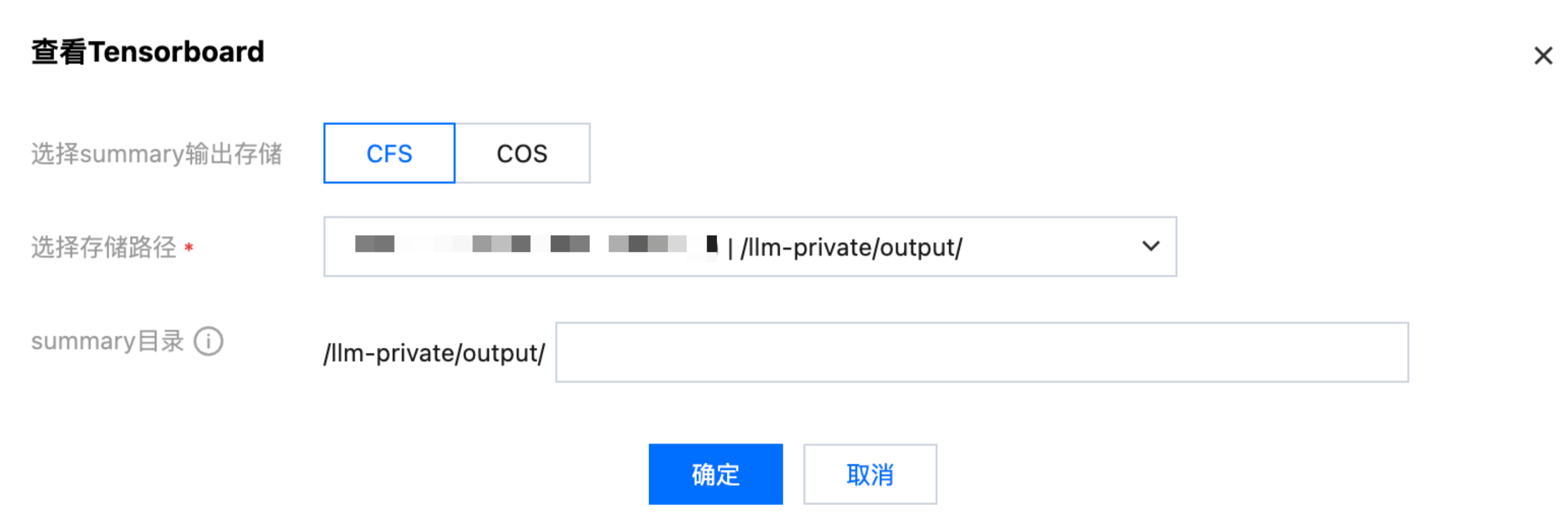
此外,您还可以单击"任务列表 > 操作栏中的 Tensorboard 按钮",配置 Tensorboard 任务,路径为 CFS 中模型训练的输出路径 /project/output。
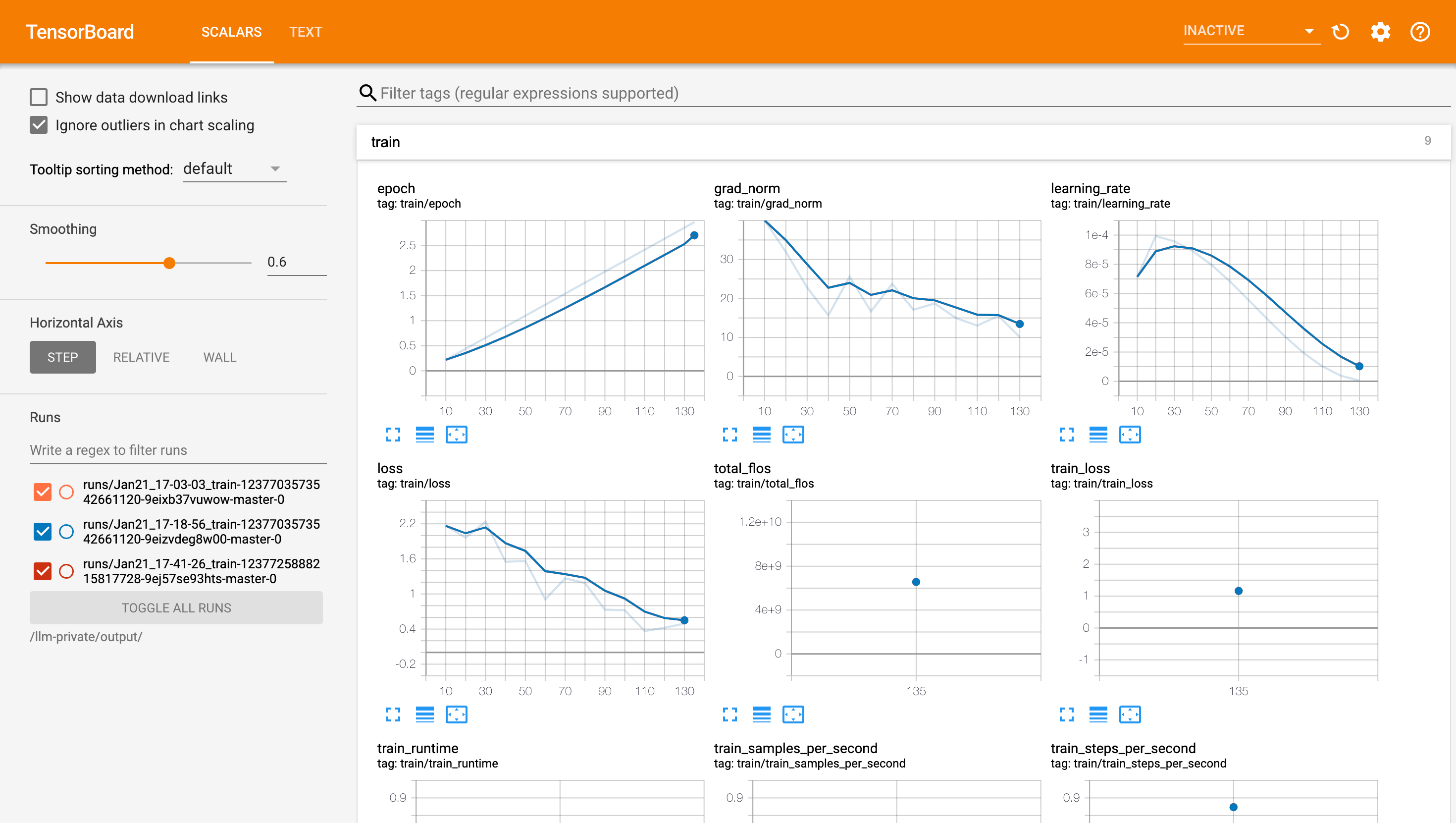
确定后即可查看训练过程损失梯度等状态。
精调后部署模型
部署服务
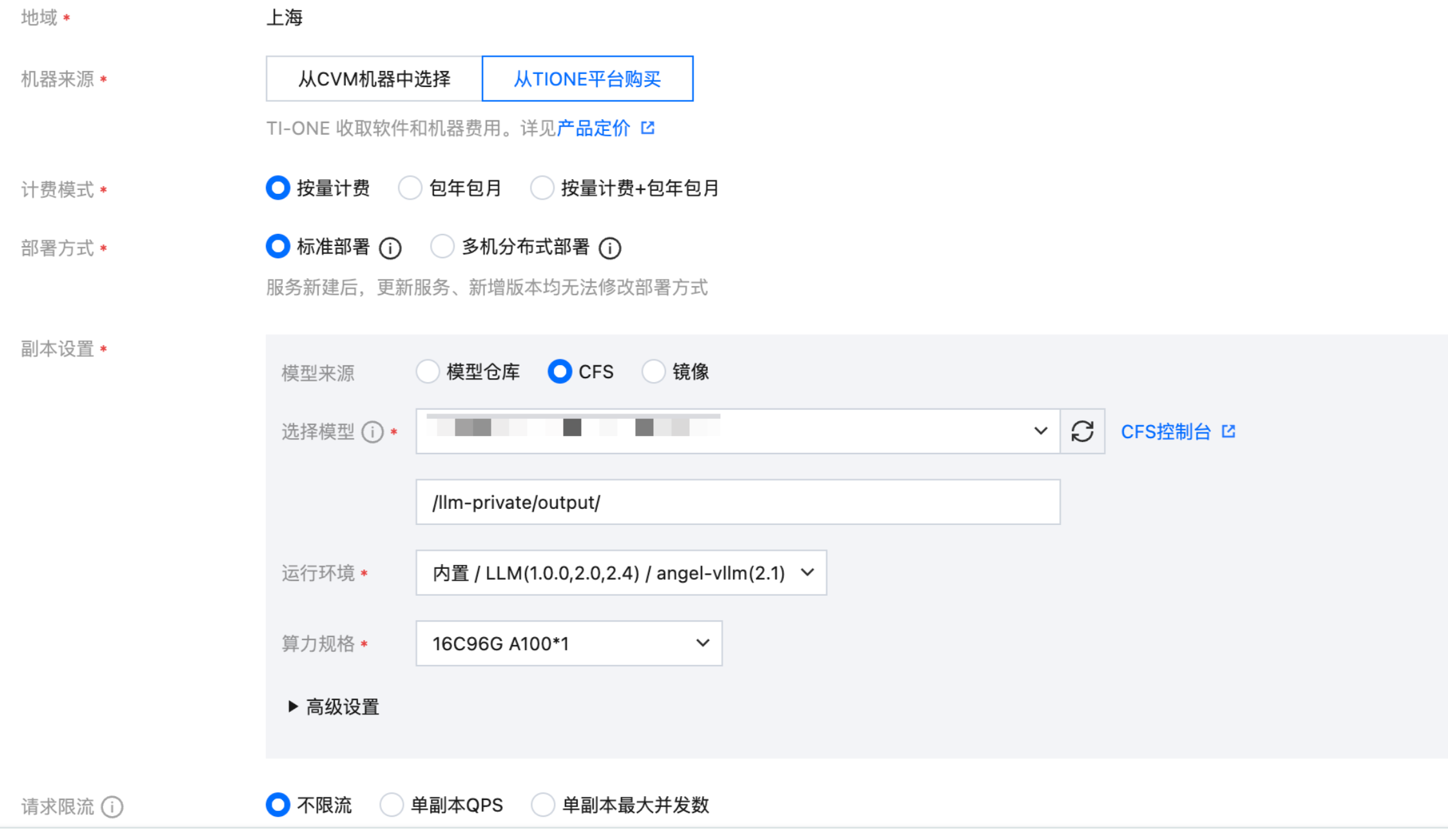
进入模型服务 > 在线服务 > 新建服务按钮。
服务名称:自定义即可。
模型来源:选择 CFS,并选中模型存储的 CFS 实例,路径按实际训练输出路径填写,若需要选择其中的某一个 checkpoint,则填写到 checkpoint 这一级目录。
运行环境:选择内置的 LLM / angel-vllm(2.1) 镜像。
说明:
平台内置训练镜像,包含了 常见的训练需要的软件,理论上可以支持绝大部分 HuggingFace 大模型。如平台内置镜像无法满足您的需求,您可以提单联系我们;此外,您也可以在平台内置镜像的基础上安装您需要的软件包 并保存为自定义镜像。此时,您可以在镜像选择页面选择您预先制作好的镜像用于训练。在此种场景下,建议您先在开发机页面确保镜像能正确启动训练任务,然后再在任务式建模里选择使用。制作训练镜像时,请注意遵循平台 自定义镜像制作规范。
算力规格:根据实际的模型大小或拥有的资源情况选择,大模型推理时需要的机器资源与模型的参数量相关,推荐参考 推理资源要求 来评估。
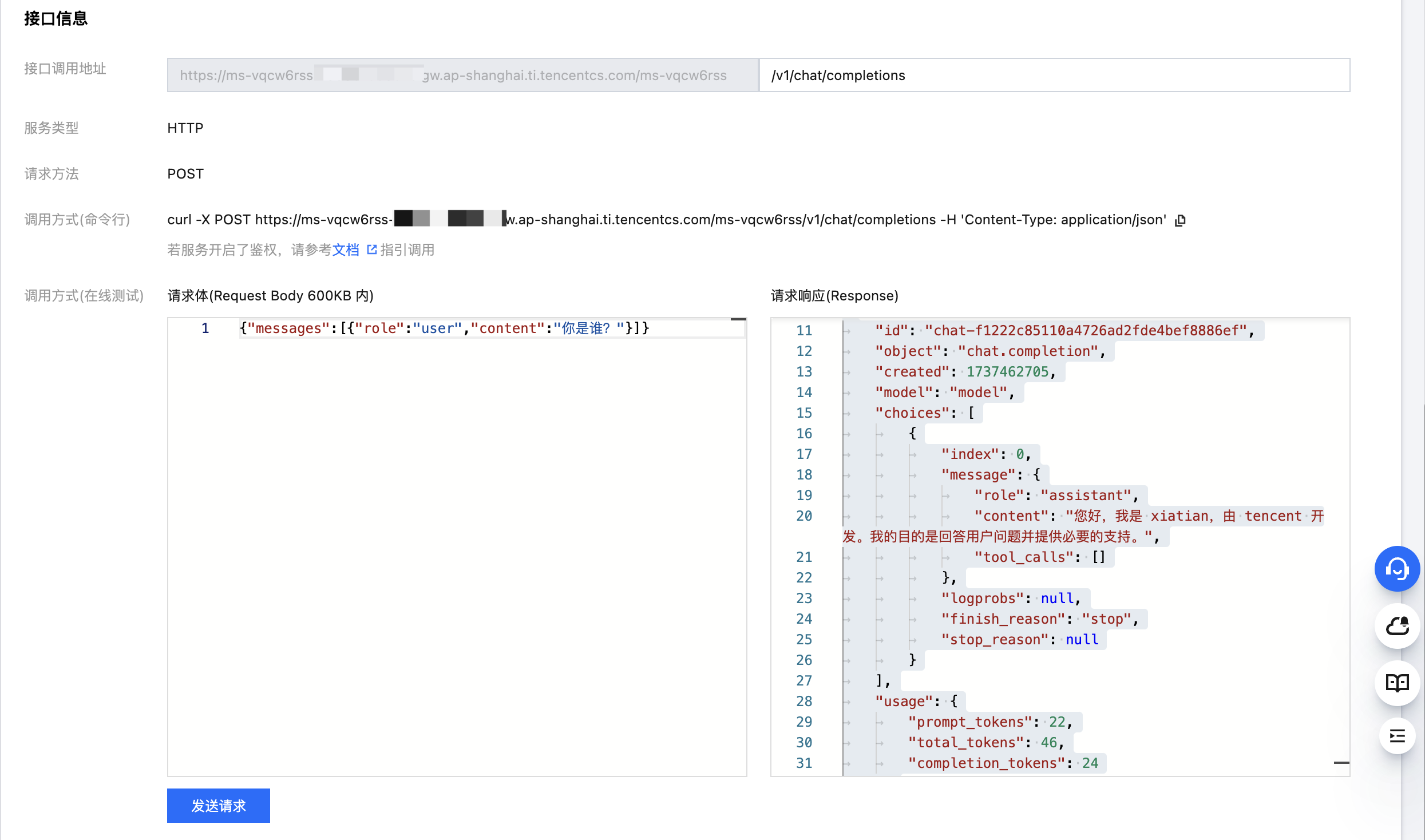
调用服务——在线体验
回到上级菜单,单击服务的服务调用标签页面:在接口调用地址处输入 /v1/chat/completions 然后输入请求体,接口格式兼容目前流行的 OpenAI Chat Completions 接口,如图所示:
调用服务——本地测试脚本
本地测试脚本:
说明:
需要修改调用地址并准备测试数据。
# -*- coding: UTF-8 -*-import timeimport requestsimport argparseimport jsonfrom concurrent.futures import ThreadPoolExecutor, as_completeddef generate(prompt, log_stream=False):start = time.time()header = {"content-type": "application/json",}# print(prompt,type(prompt))data = {"messages": [{"role":"user","content":prompt}], "temperature": 0.7,"max_tokens": 256,}result = requests.post(f"{args.server}/v1/chat/completions",headers=header,json=data,stream=True )response = ""for part in result.iter_lines():if part:if "content" in part.decode("utf-8"):print(part.decode("utf-8"))content = json.loads(part.decode("utf-8"))["choices"][0]["message"]["content"] # 字符串过滤 data: 之后转成 json 格式再取文本response += contentif log_stream:print(content, end = "", flush = True)if log_stream:print()end = time.time()return {"prompt": prompt, "generated_text": response, "time_cost": end - start}def main():# 准备测试集prompts = []with open(args.test_data, "r", encoding="utf8") as data:for line in data.readlines():line_dict = json.loads(line.strip())prompt = line_dict['question']prompts.append(prompt)# 或者使用几个简单的测试样例:prompts = ["你好!","你是谁?"]task_list = []t1 = time.time()with ThreadPoolExecutor(max_workers=args.concurrency) as executor:for prompt in prompts:task_list.append(executor.submit(generate, prompt, args.verbose))for item in as_completed(task_list):result = item.result()print(result)total_time = time.time() - t1req_per_sec = len(prompts) / total_timeprint(f"total_time={total_time:.4f}s, requests/s={req_per_sec:.4f}")if __name__ == '__main__':parser = argparse.ArgumentParser()# 调用地址换为在线服务的地址parser.add_argument("-s", "--server", type=str, default="https://ms-xxxxxxxx-yyyyyy.cs.com/ms-xxxxxxx", help="推理服务地址")parser.add_argument("-d", "--test-data", type=str, default="./test.jsonl", help="测试jsonl文件")parser.add_argument("-c", "--concurrency", type=int, default=4, help="请求并发数")parser.add_argument("-v", "--verbose", action="store_true", help="打印流式详情")args = parser.parse_args()main()
回答示例:
{'prompt': '你是谁?', 'generated_text': '您好,我是 xiatian,一个由 tencent 开发的人工智能助手,我可以帮人们解决各种语言相关的问题和任务。', 'time_cost': 1.1000895500183105}total_time=1.1006s, requests/s=0.9086



