总览
高质量的训练数据对于提升模型精调效果至关重要。为了帮助用户准备高质量的训练数据,TI-ONE 平台将内部研发所采用的标准数据构建流程沉淀到了“数据中心/数据构建”的模块,支持用户依据自定义业务场景进行修改得到定制的数据构建 pipeline。
本文以简单的原始数据样本为例,详细展示如何使用 TI-ONE 的“数据构建”模块来生成一份 LLM 大模型精调数据集。
前置要求
物料准备
为了执行“数据构建”流程,您需要准备好如下物料:
原始数据集:请确保您已经将原始数据集下载至本地,或者您具有可访问原始数据集的具体链接;本文假设您使用的是平台提供的样例数据: dataset_preparation_demo.json。
数据构建代码:如您没有特殊需求,您可以直接使用平台内置的数据构建代码,只需要按照您的数据集格式,修改示例代码中的某些字段即可;如内置数据构建代码不能满足您的需求,您也可以自行准备部分构建代码。
如何准备原始训练数据
明确业务诉求
用户需要根据自己的目标或业务需求来准备数据集。通常情况下,使用具有强烈业务属性的数据集在开源基座模型上进行精调,就能比较显著地提升模型在业务上的能力;针对某一种特定的任务场景,准备约几千条高质量精调数据即可让大模型学会这项能力,发挥出良好的效果。
用户也可以使用主流的大模型,提前对自己的业务问题进行批量测试,以此确定该任务场景是否现有大模型已经做得足够好了,甚至比自己准备的数据集中的回答还要出色。如果出现这样的情况,则需要进一步提升精调数据集的质量。
明确高质量训练数据的标准
1. 数据集的问答需要满足自己的需求(例如回答的准确性、逻辑性、风格等),并且答案是绝对正确的,且表达方式尽可能优化到极致:这是因为用户的数据集是用来解决实际问题,并且这些数据是大模型学习过程中的重要依据。大模型会很大程度地去理解用户数据集的回答以及表达风格,并在学习中进行快速地适配。因此一旦用户的数据存在瑕疵,大模型也会把这些瑕疵学到,从而影响最终的效果。
2. 数据集的指令需要多样化。以避免大模型产生对某些短语的过拟合,而忽略了自然语言的实际含义。例如对于一个阅读理解数据集,用户只设计了一种指令“根据以下已知内容,请回答问题并说明原因。已知内容:xxxxx。问题:xxxx”。大模型经过这个数据的精调后很有可能会出现这样的情况,大模型一旦看到“根据以下已知内容”这个短语作为输入,他就自然而然地在回答问题的同时说明原因。因为大模型通过这批数据的学习,很有可能错误地认为“根据以下已知内容”与“回答时要说明原因”是等价的。这样如果用户输入“根据以下已知内容,请回答问题,要求只回复答案,不要做其他解释。已知内容:xxxxx。问题:xxxx”,大模型还是会回复原因。这种针对指令的过拟合现象是需要去避免的,解决办法就是扩充数据集的指令集。
构建流程
新建数据构建任务
在数据中心 > 数据构建模块单击新建任务按钮,然后根据您的业务场景选择数据构建 pipeline;每一套数据构建 pipeline 都对应一套标准化数据处理流程,您可以按需选择。
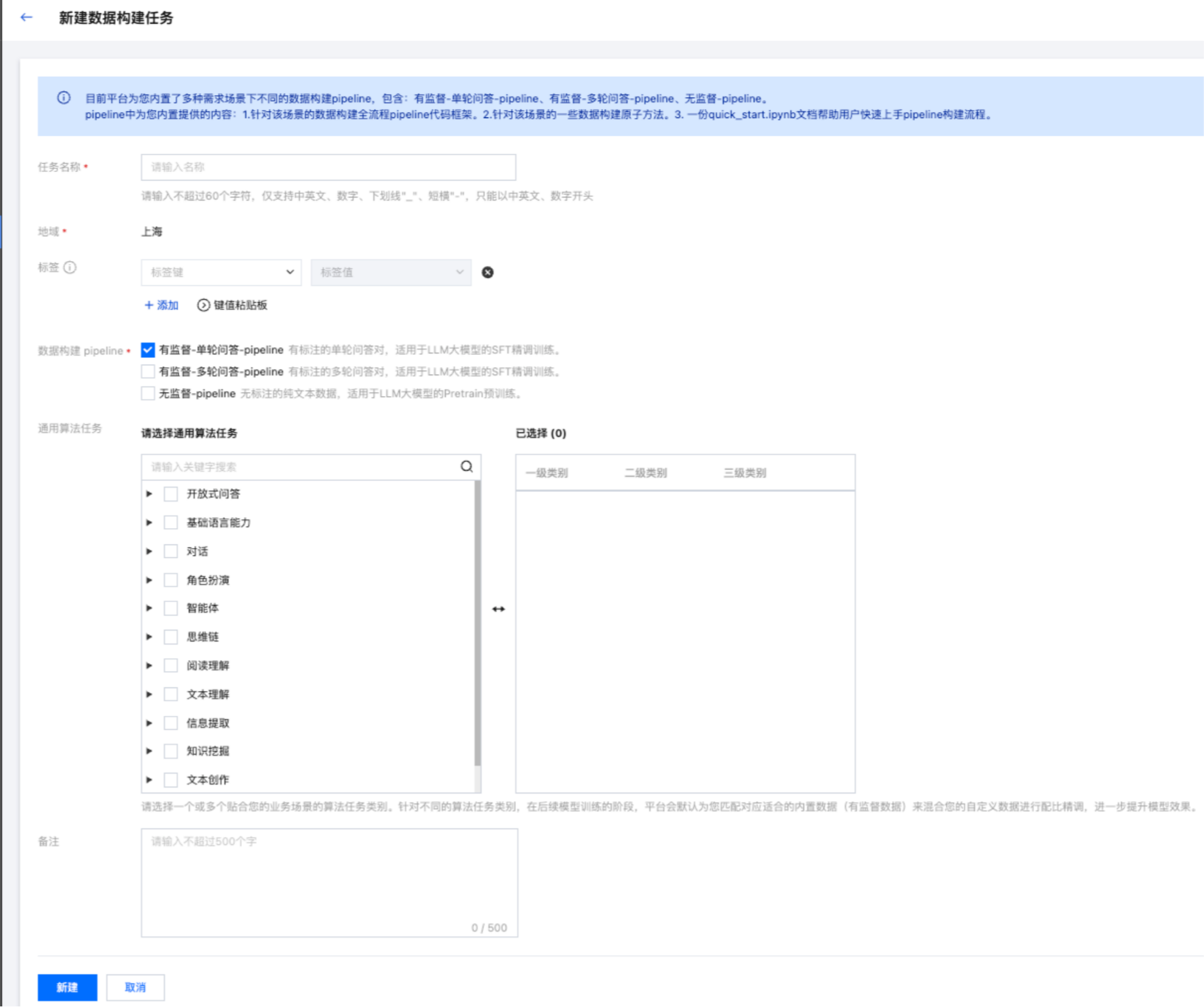
本文提供的样例数据后续是用于“有监督-单轮”的问答训练,所以此处选择 "数据构建pipeline:有监督-单轮问答-pipeline" 。
任务创建完成之后,单击“跳转至对应开发机”即可开始创建(首次创建)或者跳转至数据构建开发机。
关于“通用算法任务”
为了减少您筹备数据集的时间,同时帮助您提升精调效果,平台内置了一些腾讯自有的数据集,您可以依据您的业务场景按需使用。请特别注意: 此部分内置数据,不会参与到本文提及的数据构建流程,但是在您后续使用“训练工坊”模块精调大模型时,平台将在创建训练任务的过程中将您选择的具体业务场景对应的内置数据集按一定比例嵌入您的精调数据集之中,以提升精调效果。如您不需要平台内置数据集,您只要不选择“通用算法任务”中的任何业务场景即可。
新建数据构建开发机
在数据构建的任务列表页面,首次单击“跳转到对应开发机”按钮时,将会触发创建开发机流程。
由于平台内置的数据构建流程中涉及模型调用(需要 CPU 和内存)、以及需要一次性将原始数据读入内存并执行后续处理,因此需要您预留好充足的算力规格;本文以 8C16G 为例,您可以结合原始数据集大小动态调整,但是建议您使用不少于 4C8G 的算力资源执行后续流程。
在创建开发机时,您还需要指定 CFS 信息以存放原始数据集、中间结果以及处理后的数据文件。本文假定您将如下 CFS 目录挂载至
/home/tione/notebook,挂载的 cfs 源路径为:/data/custom/prepare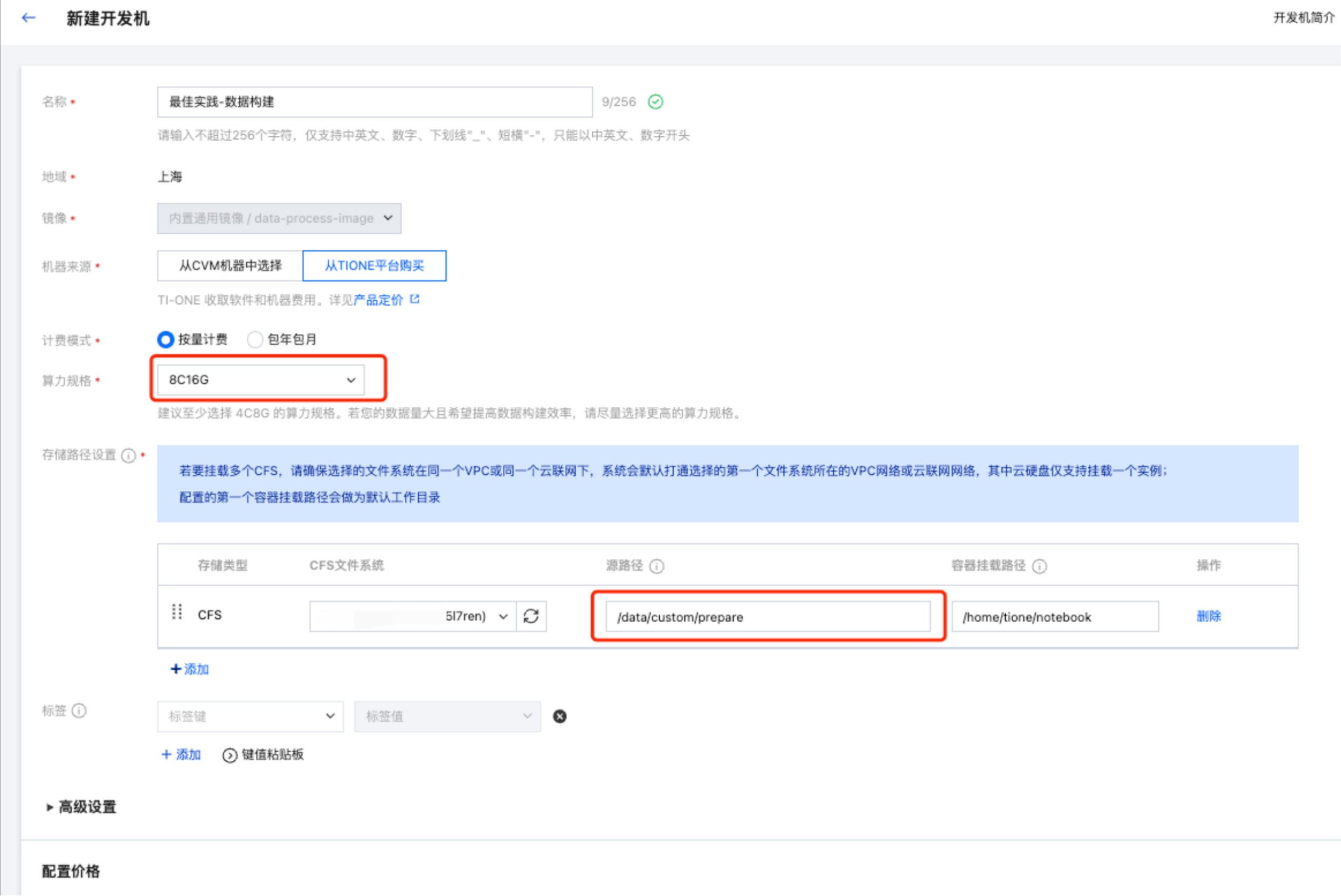
单击确认按钮,返回开发机列表页面,等待开发机创建完处于“运行中”状态后,单击操作 > 打开选择“Jupyter”即可开始数据构建流程。
上传原始数据集
此外,由于平台内置的数据处理 pipeline 依赖您将文件放入指定目录,因此建议您将原始数据集上传至如下目录:
开发机:
/home/tione/notebook/<nb-id>/single_round_qa_pipeline/raw_dataset_files也就是如下的 cfs 目录:
cfs:
/data/custom/prepare/<nb-id>/single_round_qa_pipeline/raw_dataset_files
其中:
-
nb-id 字段代表的是您创建的开发机示例的 ID;您可以在浏览器url输入栏看到当前开发机实例的 ID;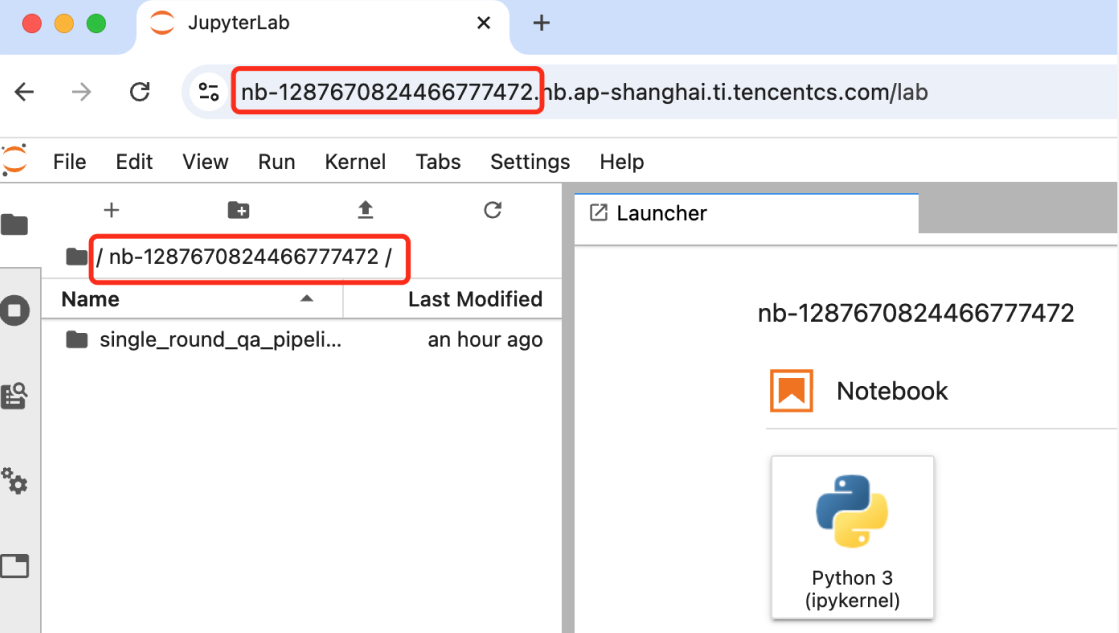
-
single_round_qa_pipeline是有监督单轮问答的脚本路径,如果您选择的是有监督多轮问答pipeline,该目录名为multi_round_qa_pipeline;如果您选择的是无监督-pipeline,该目录名为unsupervised_pipeline。
数据构建
开发机创建完成后,单击打开按钮,进入到前述描述的
/home/tione/notebook/<nb-id>/single_round_qa_pipeline/工作路径下,并打开quick_start.ipynb 之后可看到完整的数据构建步骤。如下图所示。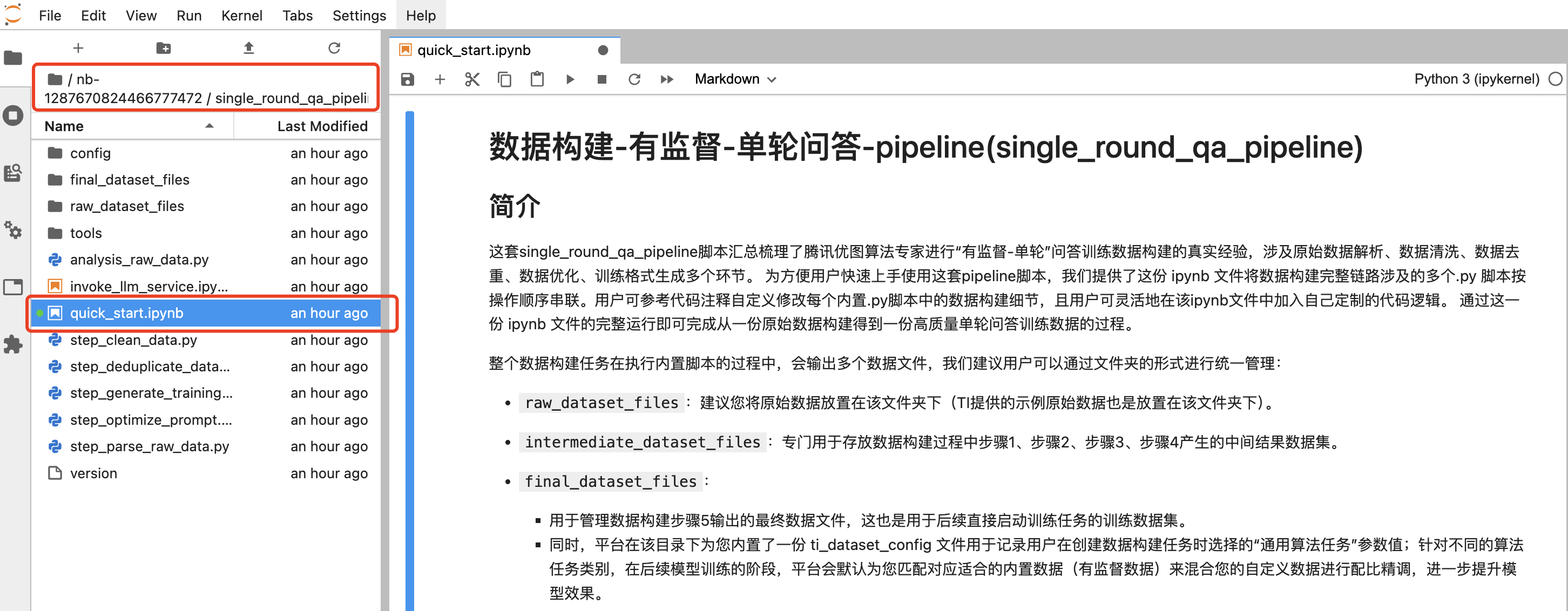
可以看到,整个数据构建流程分为如下步骤:
步骤0:环境初始化:导入必要的 python 包。
步骤1:原始数据解析: 将形式格式不确定的原始数据转换为 tione 平台需要的三元组格式
(system, question, answer),并且输出为 jsonl 文件。步骤2:数据清洗: 依据用户指定配置清洗数据数据,例如数据过滤(去除不满足要求的样本),数据改写(繁简转换,全角半角转换等)。
步骤3:数据去重: 将清洗完之后的数据计算 embedding 相似度并去重。
步骤4:数据优化: 优化训练数据的 prompt,以提升指令理解效果。
步骤5:生成训练数据: 输出必要的训练数据统计分析结果,prompt 长度,response 长度,以及复合训练要求的数据格式。
上述六个步骤中,除了步骤1您必须根据输入数据格式进行修改之外,其他所有步骤都可以默认采用平台设置。
当您觉得平台默认规则构建的数据依然不理想时,您可以根据每个步骤的提示进行针对性的调整和优化,例如:
数据清洗: 可打开
config/clean_config.yaml进行清洗规则配置修改;数据清洗: 可以按照平台要求自定义清洗函数并注册;
数据优化: 可打开
config/instruction_dict.yaml来填充丰富的 instruction 替换规则;
步骤一: 原始数据解析(需要自定义解析函数)
对于本示例中的单轮有监督 PPL,平台后续清洗去重等步骤要求的输入格式为 jsonl 格式,每一行 json 对象都是如下的三元组:
{"instruction": "你是一个聊天机器人,能理解并回答问题", "question": "小徐,下次旅游去崇明吧,那里5A级景区么?", "answer": "倒是有一个,西沙明珠湖景区。"}
因此对于您的原始输入格式(如 json/jsonline/parquet)等格式,您需要编写自定义的解析函数,将原始数据的格式转换成平台要求的格式。
对于原始数据,您指定好您的文件路径后,执行原始数据采样代码块,我们会输出您原始数据的采样格式。


如果您的原始数据是 json 格式或者 jsonline,我们抽样展示部分数据。
如果您的原始数据是 parquet 格式,我们会转成 json 格式之后,再抽样展示部分数据。
在采样了解了原始数据格式之后,您需要将原始数据转换成 TIONE 平台要求的输入格式。对于您的输入文件,我们会解析成多行的 json,并把 json 格式转成 python dict 格式。从您的 json 对应的 dict 格式转成 tione 平台要求的格式需要您自定义
convert_dict_to_tione_format函数来实现您自己的转换逻辑。您可以参考以下代码段进行实现;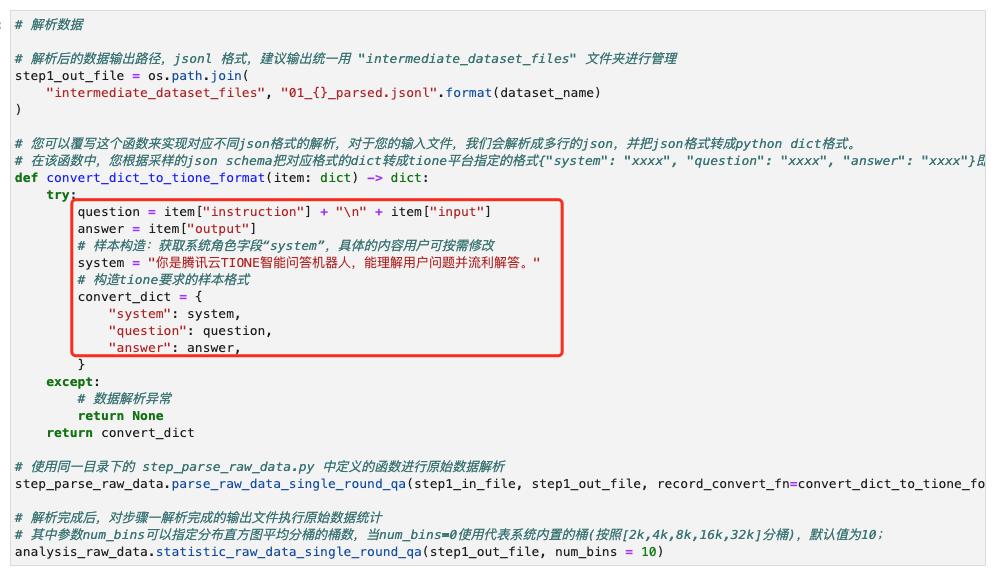
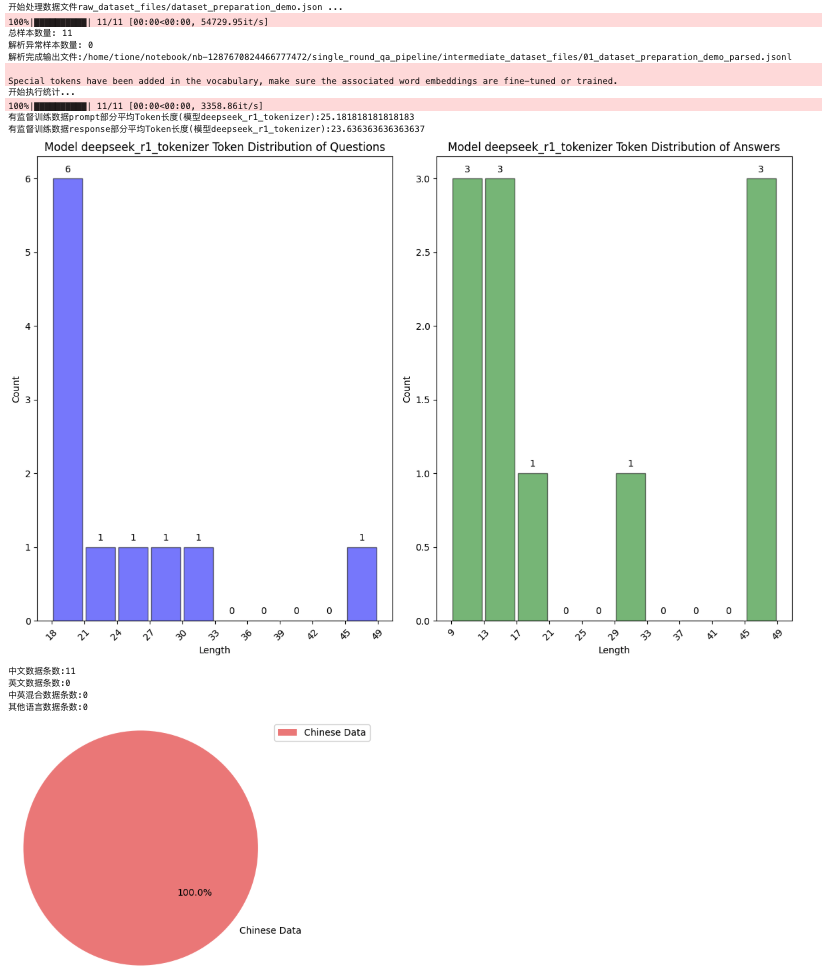
步骤一完成之后,我们会输出原始样本的统计信息,包括样本数量,有监督训练数据 question/answer 字段的长度分布,中英文数据条数统计等信息;
步骤二: 数据清洗(可以自定义清洗规则)
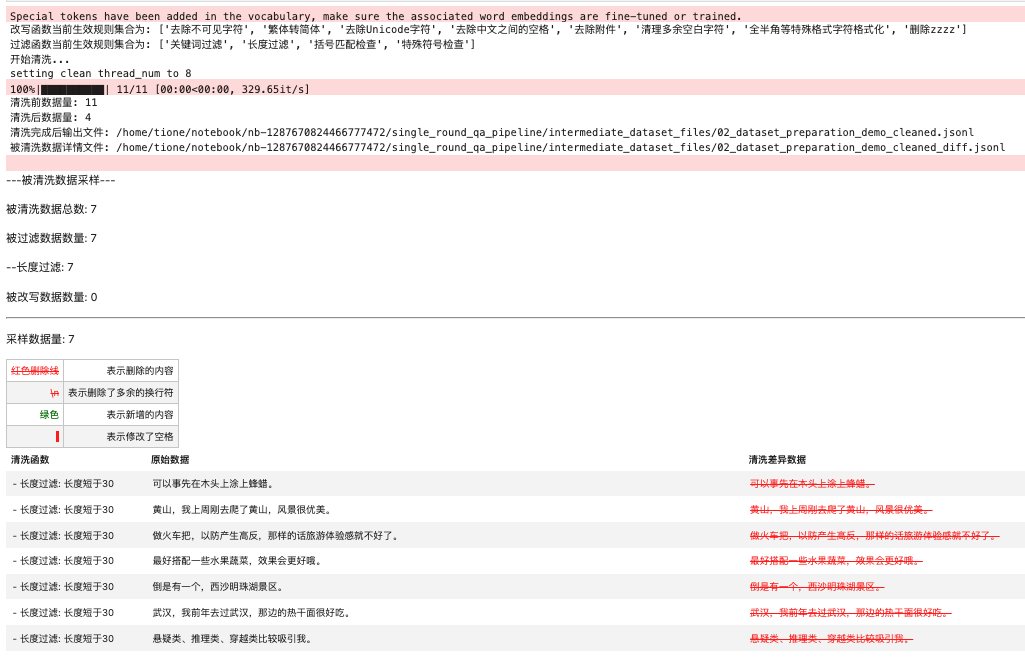
清洗函数分为两类:一类是改写,一类是过滤。默认情况下,平台内置的规则应该能满足很大一部分场景的需求,如果您的场景较为特殊,您也可以通过自定义注册的方式在此处新增您的自定义清洗规则。

清洗流程完成后,我们会输出清洗前后的数据量,并采样部分被清洗数据进行可视化展示,便于您比较清洗规则是否符合预期。
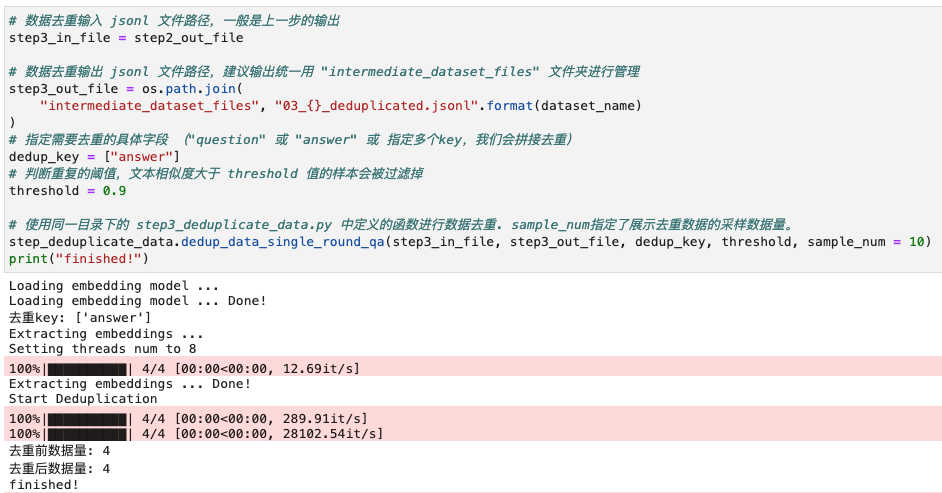
步骤三: 数据去重(不建议修改)
平台内置的数据去重的逻辑比较复杂,耗时也比较长(模型加载与数据计算普遍在5分钟以上)。此部分逻辑比较专业,不建议您自行实现。当然您可以指定需要去重的字段,例如 question/answer。
步骤四: 数据优化(修改配置文件)
您可以按需修改
config/instruction_dict.py自定义场景的 instruction 列表,增加 instruction 的指令丰富度。
数据优化完成后,我们在生成训练数据前,自动统计和采样指定数目的样例数据,执行数据统计脚本,输出数据QA问答对的平均长度,长度分布直方图,和中英文分布的饼图,便于您了解本次数据构建的 pipeline 执行结果是否符合预期。

步骤五: 训练格式生成(不建议修改)
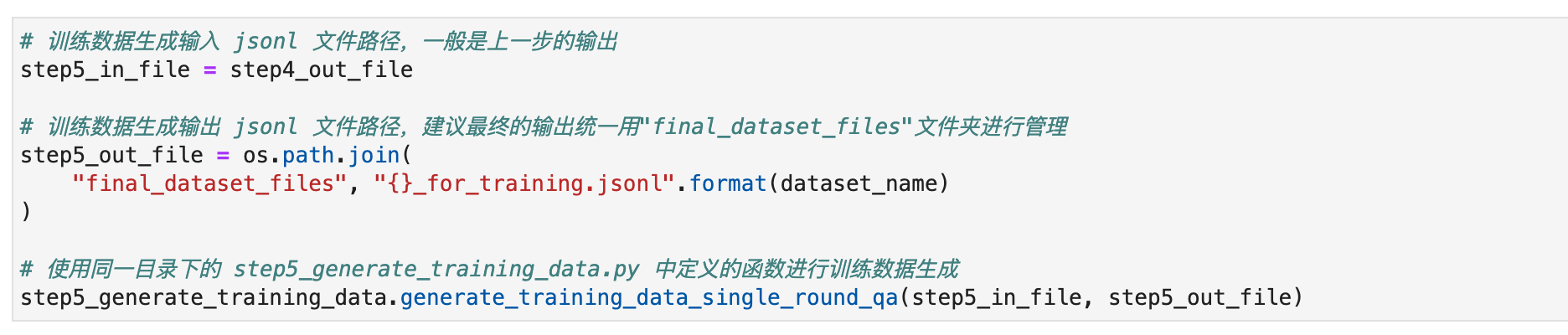
执行完上述所有流程之后,我们就在开发机里的
/home/tione/notebook/<nb-id>/single_round_qa_pipeline/final_dataset_files (也就是 cfs:///data/custom/prepare/<nb-id>/single_round_qa_pipeline/final_dataset_files)里存有构建完之后的数据,您可以在"大模型精调"模块加以使用。
该步骤的输出中包括 cfs 的映射路径,您可以直接在任务式建模中挂载这个 cfs 路径用于训练数据的挂载原路径。

在“大模型精调”模块使用构建好的训练数据



