LLM推理加速
Angel-vLLM 是腾讯云 AI 加速团队基于开源 vLLM 深度优化的推理加速框架。在保持和社区 vLLM 相同使用接口和完全兼容社区 vLLM 功能的同时,具备如下特点:
第一,功能更丰富。相比 vLLM 社区开源版本,Angel-vLLM 提供了 INT8,INT4 在线量化,KV Cache INT8 量化,lookahead 并行解码,PP+TP 模型并行等功能(部分功能需要0.4.2或更新版本框架支持)。
第二,性能更强大。相比 vLLM 社区开源版本,Angel-vLLM 量化不仅节省显存,也可以降低延迟,提升吞吐。lookahead 并行解码经过实际业务打磨,在 RAG 场景提升明显。
第三,精度更对齐。Angel-vLLM 生成结果经过大量上线业务检验,可以做到和 HuggingFace 生成结果完全对齐或精度保持基本不变。
Angel-vLLM 一键式模型量化加速
支持多种自研量化加速方案,包括:
int8 weight-only 量化
int8 smoothquant 量化
int4 weight-only 量化
结合自研 int8 kv-cache 量化技术,在保持算法效果无明显下降情况下,大幅提升推理性能,降低部署成本。
使用方法
相比原始推理代码,只需要额外配置 quantization 和 kv_cache_dtype 两个参数:
# 加载大模型from vllm import LLMmodel = LLM(model=args.model,trust_remote_code=True,quantization=args.quantization, # "ifq代表int8 weight-only量化,ifq_int4代表int4 weight-only量化,smoothquant代表int8 smoothquant量化,默认None代表不使用量化加速"kv_cache_dtype=args.kv_cache_dtype, # "int8代表使用int8精度压缩kv-cache,默认auto代表不使用kv-cache量化"dtype=torch.float16)# 定义采样参数sampling_params = SamplingParams(top_k=50, top_p=0.8, max_tokens=args.output_len)# 推理outputs = model.generate(prompt_token_ids=input_ids, sampling_params=sampling_params)
备注:
ifq 量化下,输入为原始 fp16 模型,在模型加载过程中完成量化。
ifq_int4 和 smoothquant 量化下,输入为 PTQ 校准后的模型。
kv-cache 量化当前仅在 smoothquant 下支持。
加速效果
参考落地业务典型使用场景,性能测试配置:
Prompt 长度:1000
输出 Token 数:100
并发数:8
硬件:A800、A100、PNV5b、A10
模型参数量:70B,13B,7B
性能测试数据:


Angel-vLLM lookahead 并行解码
将 vLLM 推理代码改造成使用 lookahead 并行解码,只需要添加3个参数。
例如,原始推理代码如下:
sampling_params = SamplingParams(seed = 10, top_k=50, use_beam_search = False)llm = LLM(model = model_path,enforce_eager = True,quantization = None)output = llm.generate(prompts, sampling_params = sampling_params)
改造成使用 lookahead 并行解码,只需要添加三个选项:
llm = LLM(model = model_path,enforce_eager = True,use_lookahead = True, #开启lookahead并行解码use_v2_block_manager = True, #lookahead并行解码需要使用block_manager v2num_speculative_tokens = 12, #一次并行解码长度,单BS可以设置成12, 多BS可以适当降低一次解码长度,例如设置成8或6quantization = None) #并行解码也支持int8量化,以及smoothquant量化,设置quantization='ifq' or 'smoothquant'打开相应量化。模型量化使用方法参考模型量化部分。
lookahead 解码在客服 RAG 场景(输入1000左右,输出100左右)性能测试数据:
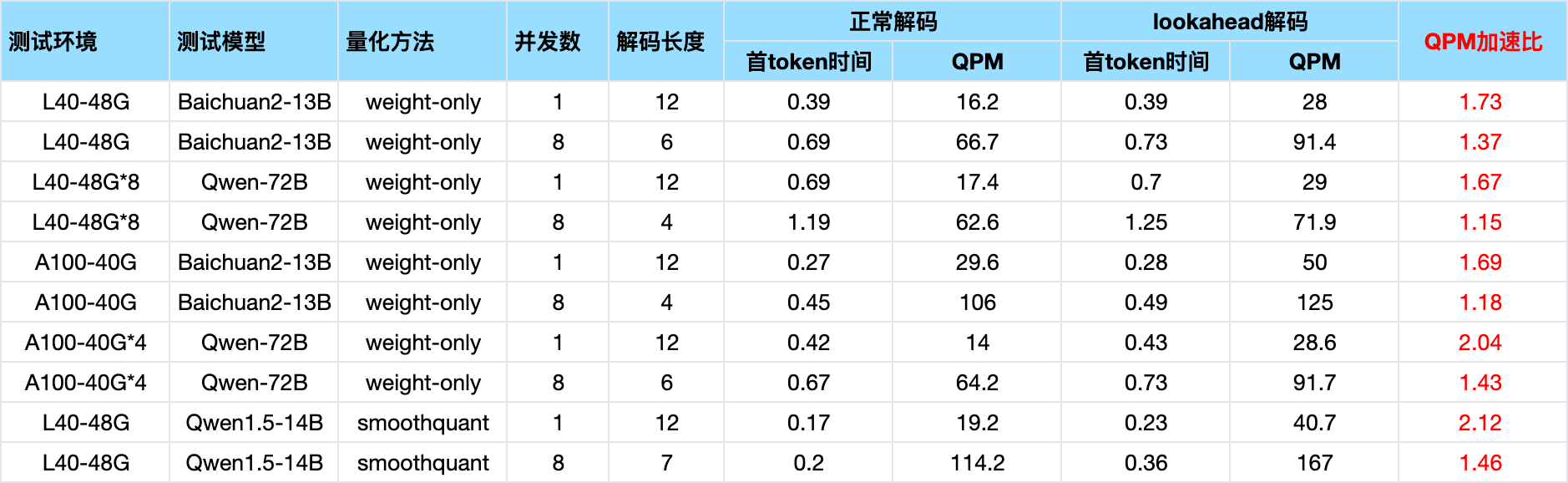
Angel-vLLM NGram 并行解码
将 vLLM 推理代码改造成使用 NGram 并行解码,可以通过添加如下选项开启 NGram 并行解码能力:
llm = LLM(model = model_path,enforce_eager = True,use_v2_block_manager = True,num_speculative_tokens = 12,ngram_prompt_lookup_max = 12,ngram_prompt_lookup_min = 2,speculative_model = "[ngram]",quantization = None)
NGram 通过单次请求的数据对未生成 Token 进行匹配填充。
相比开源实现,Angle-vLLM NGram 解码可以做到生成结果和 HF 完全对齐。
Angel 文生图加速



