总览
本文将介绍如何使用 TI-ONE 平台 来一步一步完成 Hunyuan-Large 模型的有监督精调(SFT)全流程,本案例使用 Hunyuan-Large 开源仓库 中附带的约 5000 条汽车领域的 实体抽取数据(下文称为 car_train 数据集)对 Hunyuan-Large-Instruct 模型做实体抽取任务的有监督精调,以让模型的输出格式更加符合这一特定任务的要求。
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "请提取下列文章中包含的车系:\\nbilstein evo s,黑黄涂装,比b14更舒适的绞牙避震 | 酷乐汽车\\n"}, {"role": "assistant", "content": "无"}]}{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "请提取下列文章中包含的车系:\\nbeijingx7燃油版二手车车架号维保查询车辆出险记录是随车不随车主的,这就说明,即使换了投保的保险公司,或是更换车牌号,甚至是出手卖掉,办理车辆过户手续等等,都不能更改和删除车辆的出险记录。\\n"}, {"role": "assistant", "content": "beijingx7"}]}{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "请提取下列文章中包含的车系:\\n奥迪q5l作为豪华品牌中最畅销的suv车型也迎来了降价的命运,目前最高优惠8.47万,性价比还是很高的。\\n"}, {"role": "assistant", "content": "奥迪q5l"}]}{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "请提取下列文章中包含的车系:\\n“居家暖男” 本田cr-v的变与不变\\n"}, {"role": "assistant", "content": "本田cr-v"}]}{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "请提取下列文章中包含的车系:\\nbmw官方认证二手车|骨子里的运动,一如既往\\n"}, {"role": "assistant", "content": "无"}]}
输入:"请提取下列文章中包含的车系:\\n此外,再配上一副多辐式的轮毂设计,为该车带来了不错的运动感。\\n"
精调前输出:"根据提供的文章内容,无法直接提取出具体的车系信息。文章中仅描述了车辆的一些设计特征,如“一副多辐式的轮毂设计”,但并未明确提及车系名称。\\n\\n因此,无法从该段文字中提取出车系。"
精调后输出:"无"
前置准备
为了完成本实践,需要先准备如下资源:
数据集
平台已经在 COS 存储中预置了上述 car_train 数据集,您可以在后续步骤中直接使用。
若您需要精调自有数据集,可以在后续的数据准备流程中自行上传,但是具体数据清洗的配置、训练超参等需要参考本最佳实践文档按实际情况调整,整体操作耗时也会有变化。
算力资源
Hunyuan-Large 模型精调需要使用 GPU 算力资源,推荐机型为 HCCPNV6 机型。本文以对 Hunyuan-Large-Instruct 模型做 LoRA 微调为例,需要最少1台 HCCPNV6 机型算力资源。若您需要对 Hunyuan-Large-Instruct 模型进行全参数 SFT 精调,推荐准备最少8台 HCCPNV6 机型算力资源。
自行购买算力:Hunyuan-Large 模型精调当前支持包年包月算力模式。请参考 资源组管理 指引,请联系客户经理购买 HCCPNV6 机型,然后将已购买的 CVM 添加到 TI-ONE 平台资源组中。添加完毕后,即可在新建任务式建模时选择该资源组。
申请免费算力:如您有 Hunyuan-Large 模型精调的免费测试需求,可通过对接的客户经理或售前架构师申请免费测试算力;如当前没有人员对接,可填写 问卷 登记。我们会尽快联系您了解业务需求,发放免费测试算力,并指导您进行使用。
文件存储
模型精调过程中,数据集和模型 checkpoint 存储都依赖 CFS,请到 CFS 控制台 开通 CFS。备注说明:本文以 CFS 为例进行详细说明,精调内置大模型时也支持挂载 GooseFSx(当机器来源为从 CVM 机器中选择)作为用户自有数据;同时创建开发机也支持挂载 GooseFSx。
由于 Hunyuan-Large 模型文件非常大,为保证训练保存 checkpoint 及后续使用模型部署推理服务和启动评测的速度,推荐使用 Turbo 标准型存储,CFS 实例区别详见 存储类型及规格。请保证购买的 CFS 实例与上述算力资源机器的网络互通。
实践教程
下面我们开始具体的实践教程,本实践主要包括数据准备、模型精调训练、精调后模型部署几个步骤:
1. 数据准备:对原始的数据集进行格式转换,将处理好的数据存放在 CFS 或者 GooseFSx 中,便于后续启动精调训练。使用示例数据按实践教程操作本步骤耗时约5分钟。
2. 模型精调训练:为了便于算力资源受限的用户也能在 TI-ONE 平台体验精调 Hunyuan-Large 模型,本示例对 Hunyuan-Large-Instruct 模型做 LoRA 微调。使用示例数据按实践教程操作本步骤耗时约4~5小时。
3. 精调后模型部署:将精调后的模型部署为在线推理服务,对外提供 API 调用能力,您可以进一步评估模型效果或接入自有的应用。按实践教程操作,本步骤耗时约10~60分钟 (首次部署耗时会偏长,后续视实际 CFS 存储的性能而定)。
步骤一:数据准备
数据准备工作会用到 TI-ONE 平台的【数据中心-数据构建】及【训练工坊-开发机】功能,具体步骤如下:
1.1 创建数据构建开发机实例
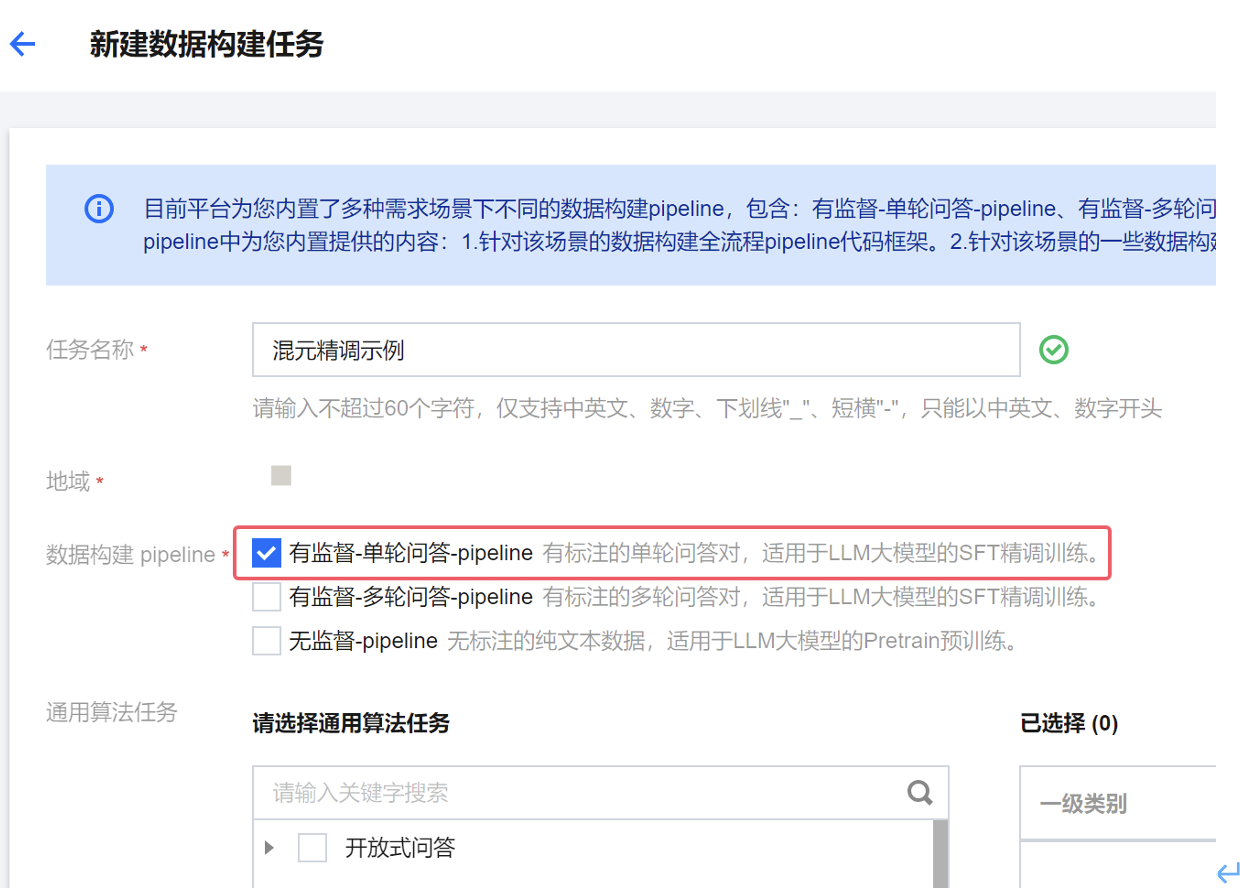
单击跳转到对应开发机按钮。首次跳转开发机 会进入新建开发机页面,这里示例使用按量计费 4C8G 的实例规格,若您有资源组机器,也可以使用包年包月模式选择对应机器,数据构建流程不需要使用 GPU,实例的 CPU 核数越多,数据构建的数据去重步骤速度越快,其他影响不是很大。
1.2 在开发机中进行数据处理
等待开发机实例启动,大概需要2分钟左右,启动完成后实例状态会变为“运行中”,此时在右侧操作栏单击打开,会跳转到实例的 Jupyterlab 页面。
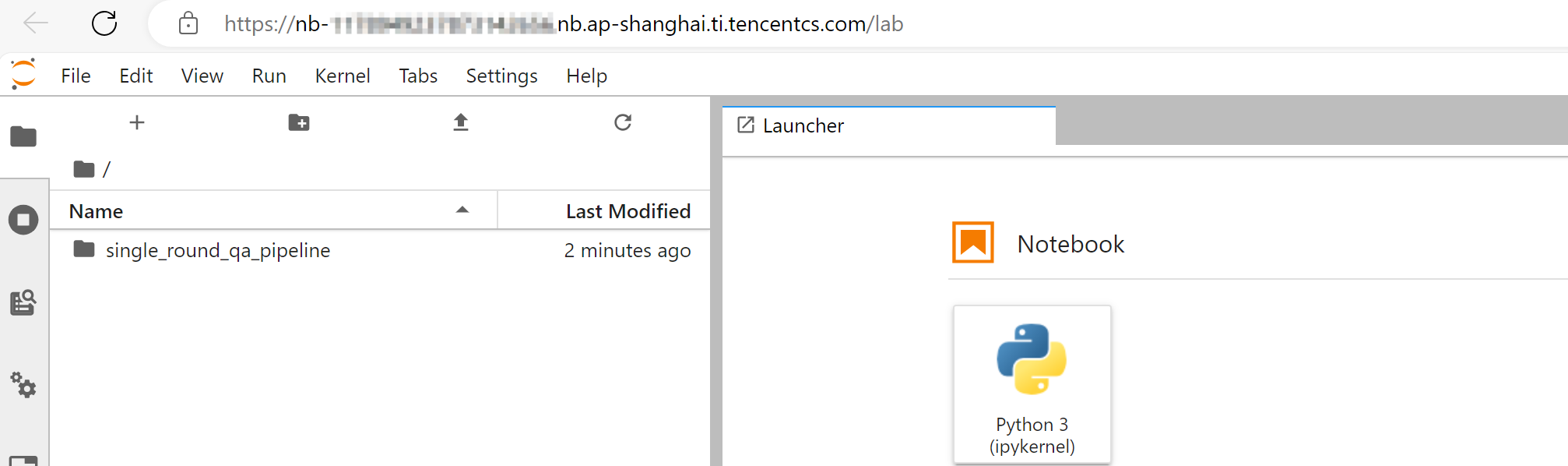
双击进入 single_round_qa_pipeline 目录,打开 quick_start.ipynb 文件,可以打开数据构建指引。
按照指引一步一步操作,首先单击“步骤0:环境初始化”对应的代码块,单击运行:
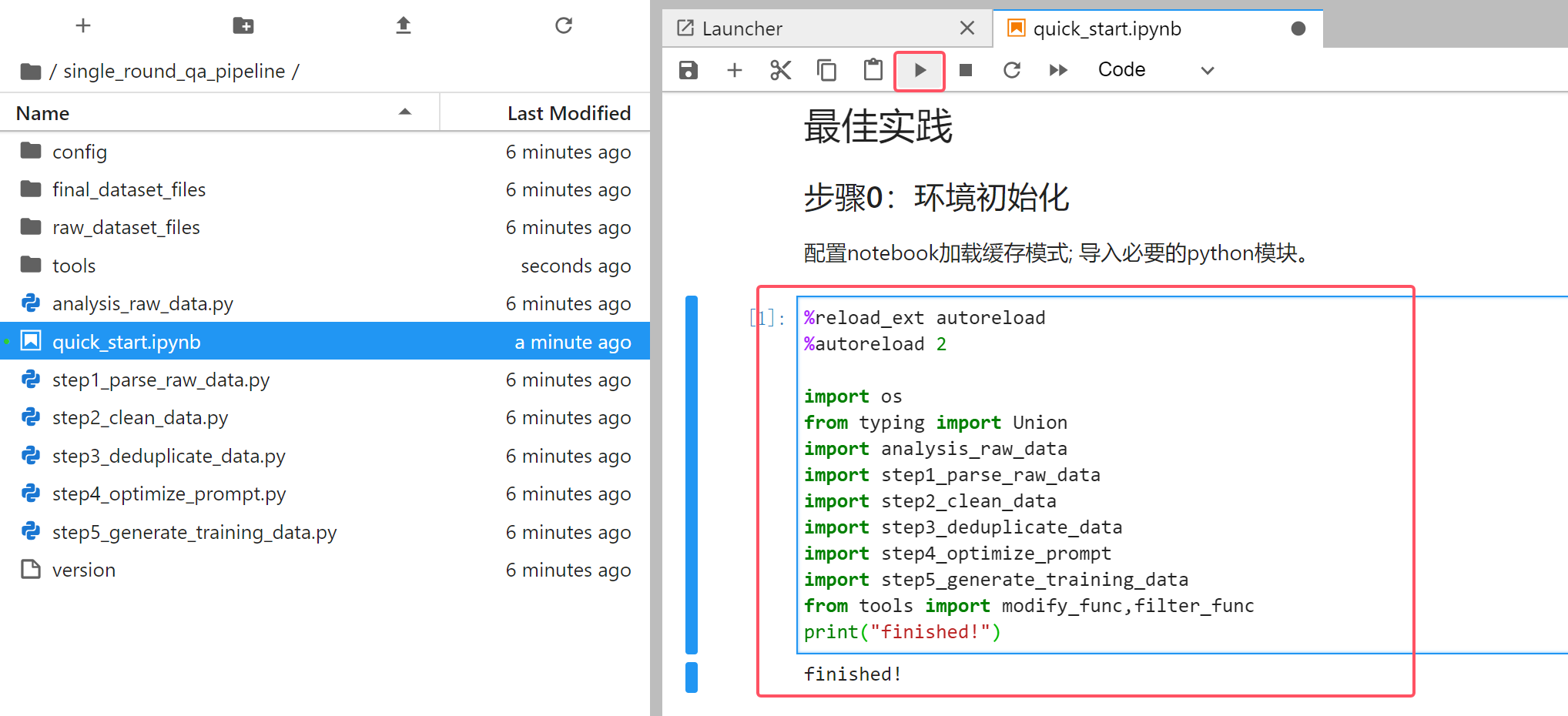
1.2.1 上传数据集
接下来需要上传原始数据集,若您的数据集在本地,且文件不是非常大,可以双击 raw_dataset_files 目录,单击上传按钮将本地的数据集上传上去:
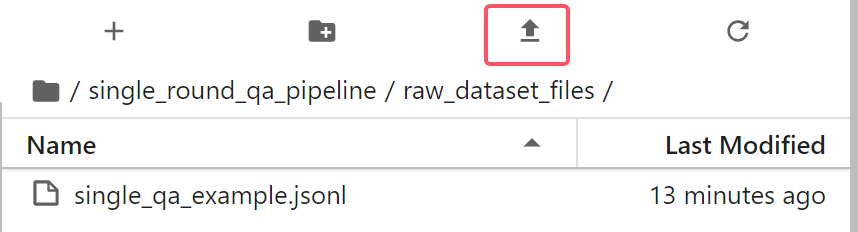
回到
quick_start.ipynb,在“步骤1:原始数据解析”这一步中,修改 input_path 为刚刚的数据集文件名,运行后可以看到原始数据集的样本数及 JSON 结构信息及5条采样数据示例,如图:
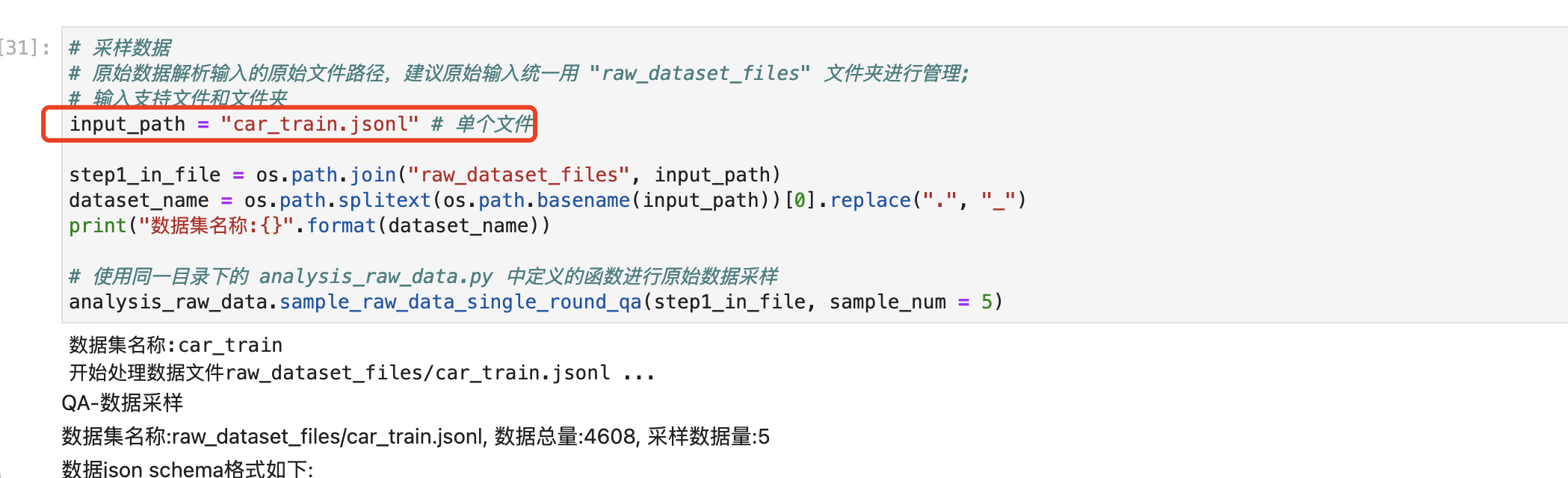

可以看到数据集均为带 system 的单轮对话数据
messages[0]["content"] 字段对应平台要求的 system 字段,messages[1]["content"] 字段对应平台要求的 question 字段,messages[2]["content"] 字段对应平台要求的 answer 字段。我们相应的修改对应代码:question = item["messages"][1]["content"]answer = item["messages"][2]["content"]system = item["messages"][0]["content"]
如图所示:
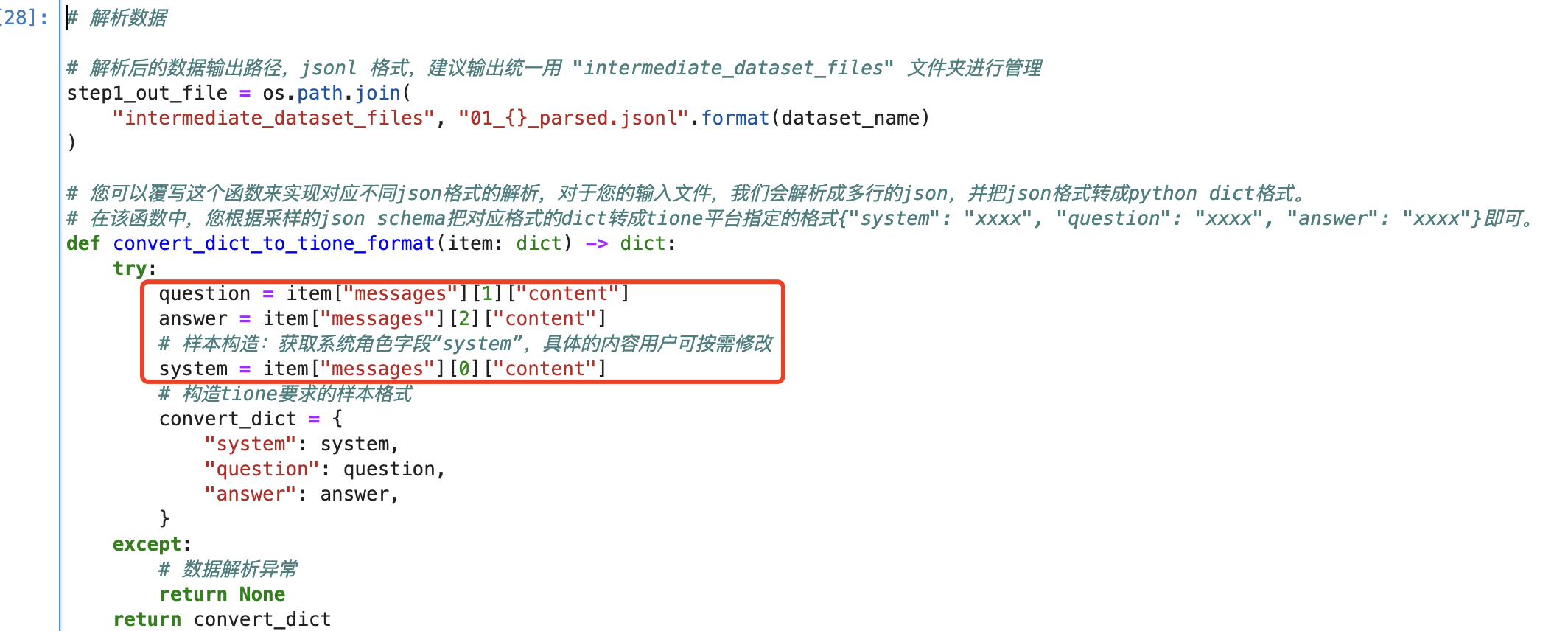
运行后会输出转换后的数据集文件及一些数据分布信息:

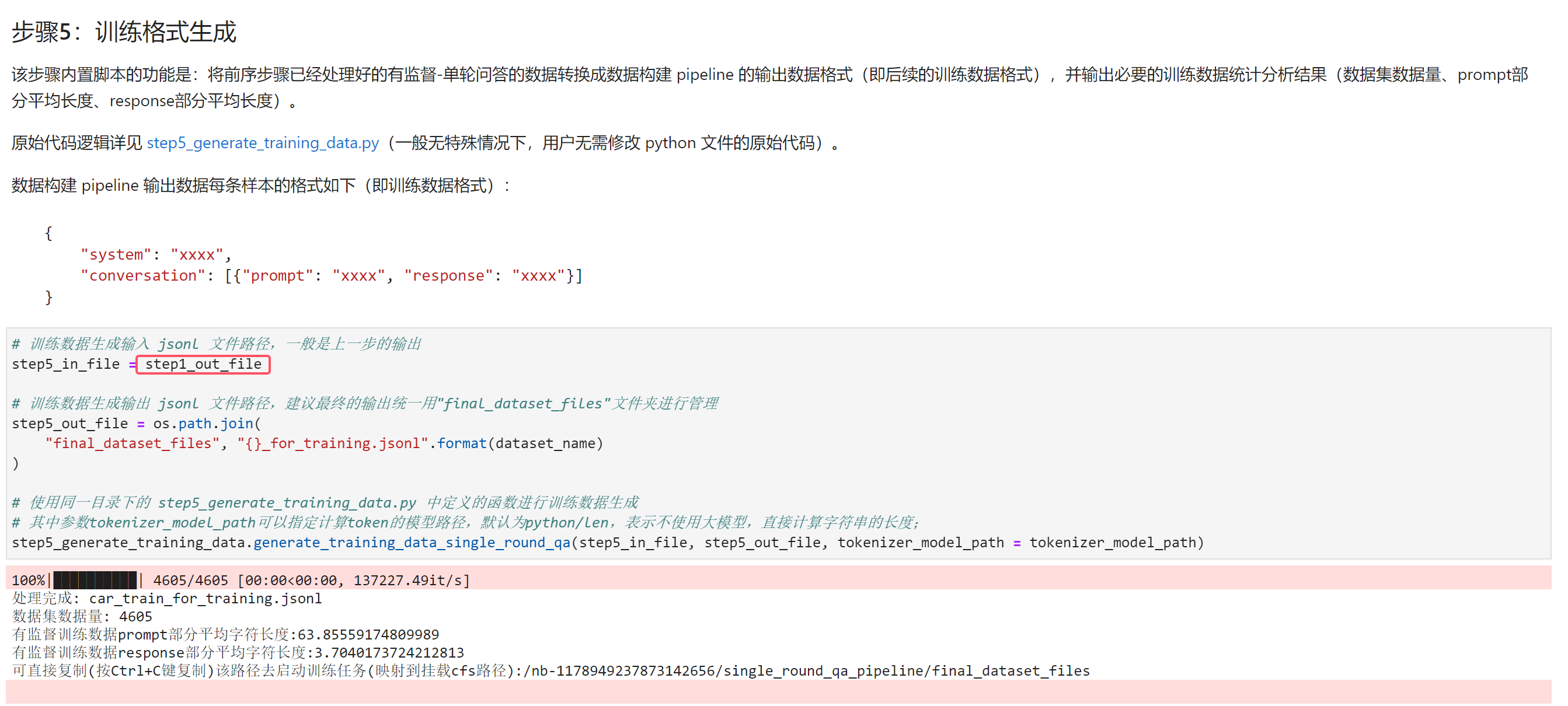
1.2.2 训练格式生成
由于这里的示例数据集已经预先经过数据清洗和去重等工作,因此我们跳过数据构建中的步骤2、3、4,直接来到最后一步训练格式生成,这里我们修改这一步的输入数据为上面第一步的输出(如下图红框所示),执行完后可以拿到最终处理好的数据集在 CFS 或者 GooseFSx 上的路径,我们复制一下这个路径,用于后续模型精调训练时输入用户自有数据的源路径。
步骤二:模型精调训练
模型精调训练步骤会用到 TI-ONE 平台的【大模型广场】和【训练工坊-任务式建模】功能,具体步骤如下:
2.1 启动训练任务
进入 大模型广场 菜单,单击混元大模型下的 Hunyuan-Large 卡片。
单击新建训练任务,会自动跳转到训练工坊 > 任务式建模的新建任务页面,按需填写任务名称。如果使用包年包月的资源组机器,单节点的 GPU、CPU、内存资源尽量用满(PNV6 单节点整机可用 CPU380核,内存2214GB,若整机为空闲状态,推荐填写 CPU380核,内存2214GB;若整机资源被部分占用,可以点击资源组下方可用卡数的查看详情链接,查看资源组内每个节点的可用资源):
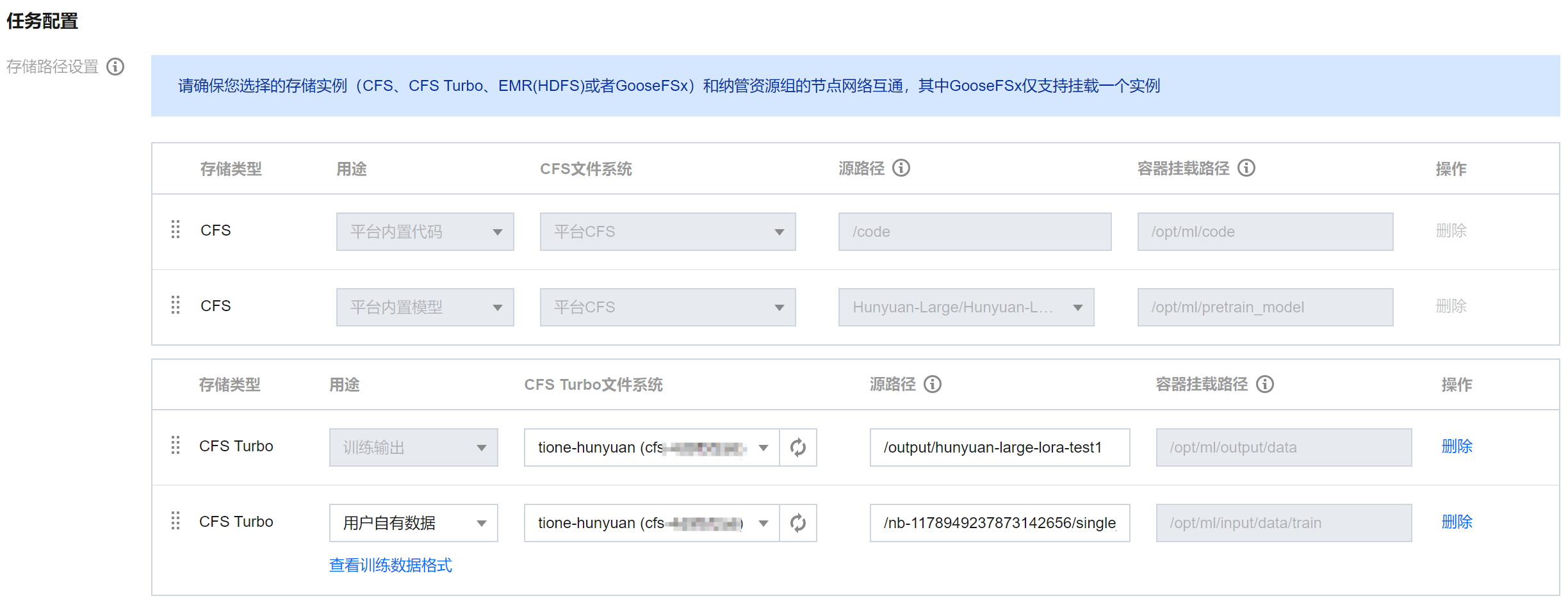
存储路径设置:
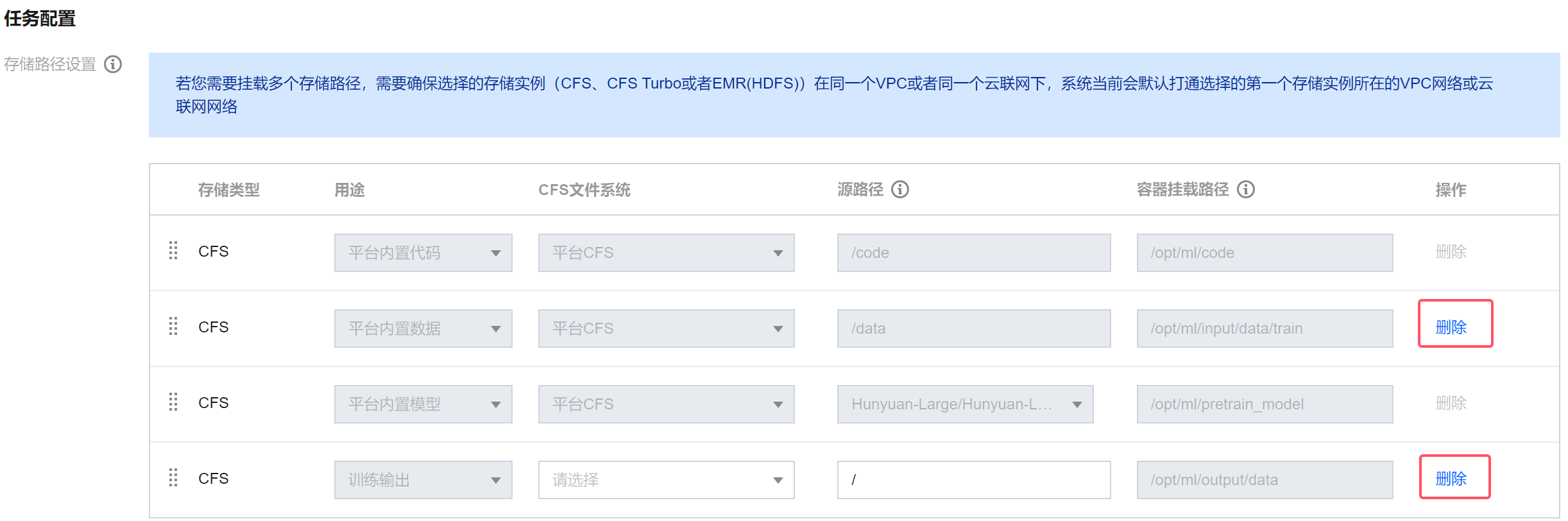
1. 训练数据:这里不使用平台内置数据,单击平台内置数据这一条最右侧的删除,然后添加存储类型为 CFS Turbo 或者 GooseFSx 、用途为"用户自有数据"的一行,CFS 或者 GooseFSx 选择前面数据构建用的 CFS Turbo 或者 GooseFSx,源路径填写 训练格式生成 章节最后复制的路径。
2. 训练输出:这里我们使用 CFS Turbo 存储模型输出,因此先单击原有的训练输出最右侧的删除,然后添加存储类型为 CFS Turbo 、用途为"训练输出"的一行,CFS 选择准备好的 CFS Turbo 实例,源路径填写一个全新的目录或一个已存在的空目录。
调优参数配置建议:
由于这里我们以单机8卡作为示例,全局 BatchSize 较小,这里我们稍稍调大 GradientAccumulationSteps 为 2,启动训练。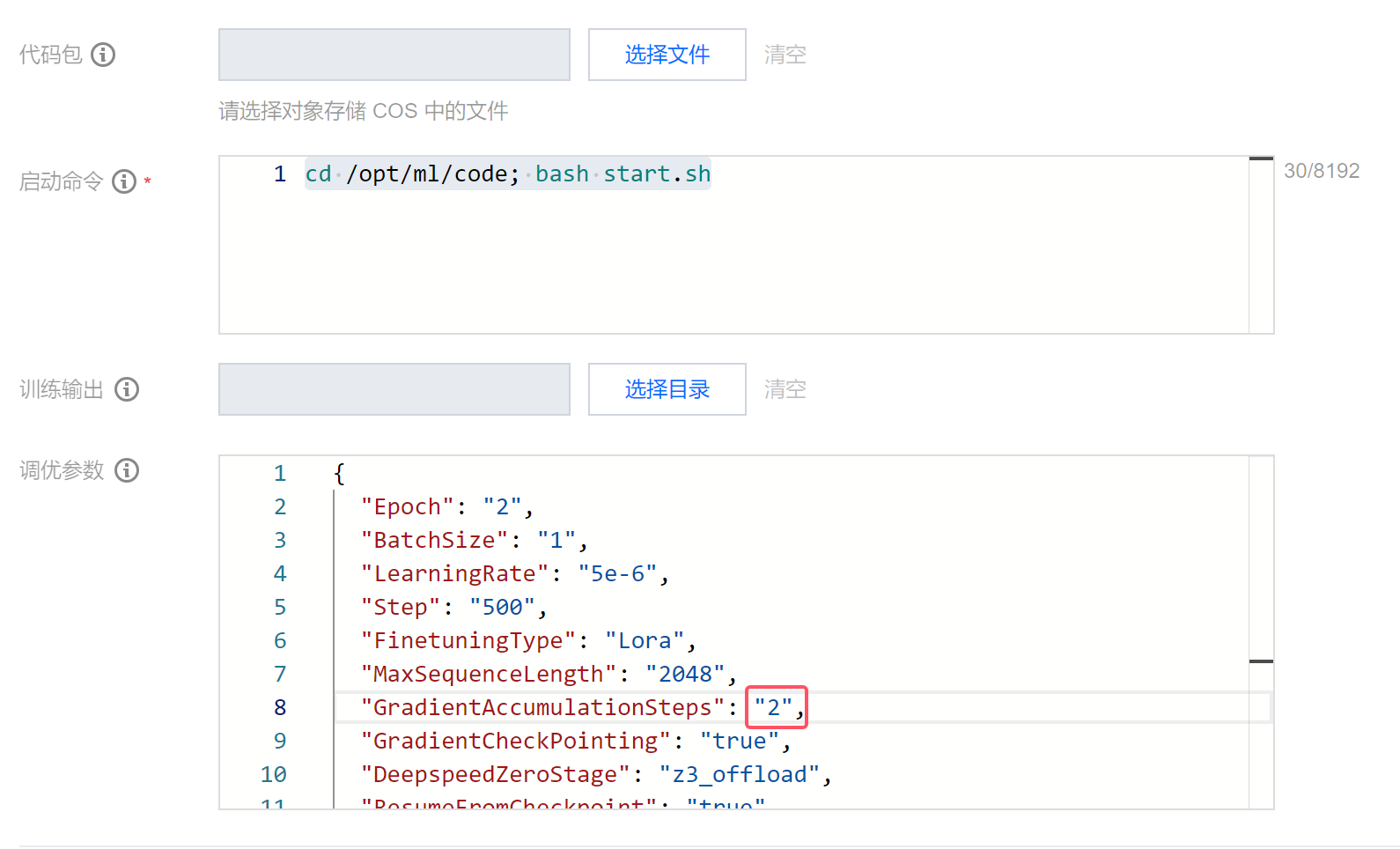
2.2 训练状态观察
训练任务启动后,建议先单击日志观察训练状态(若您启动的是多机分布式训练任务,建议日志页面"节点"下拉框选择 master-0 节点,以免日志过多),训练任务启动后会有以下几个阶段:
1. 加载用户指定的调优参数,打印最终任务使用的超参列表,这里的超参兼容开源 LLaMA-Factory 框架,若您非常清楚实际超参的含义及修改后果,也可以在平台的调优参数中添加平台未预置但是 LLaMA-Factory 0.8.3 版本中有的超参来覆盖最终训练使用的超参。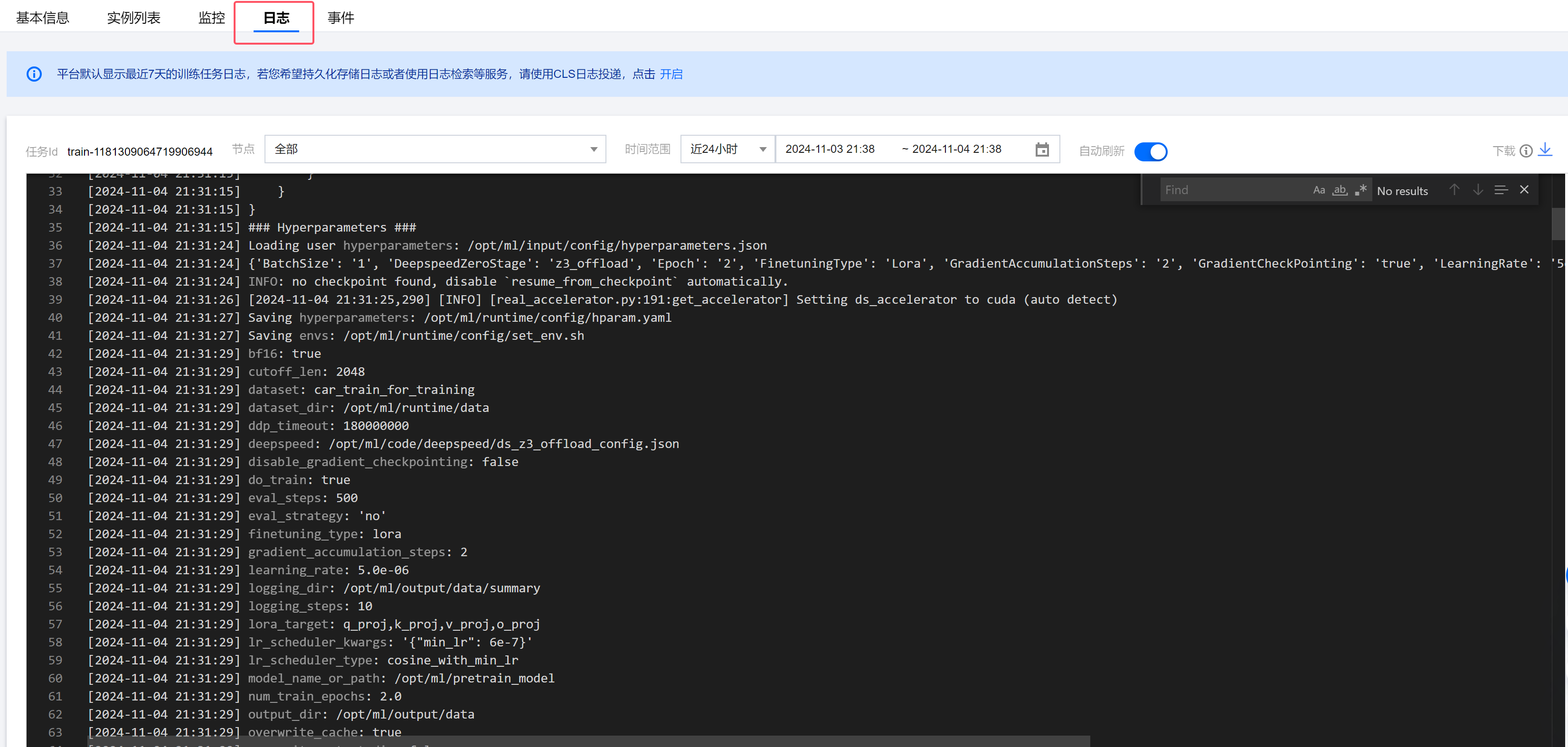
2. 加载数据集,并使用模型的 Tokenizer 和对话模板对数据进行预处理,打印部分数据预处理后的样本。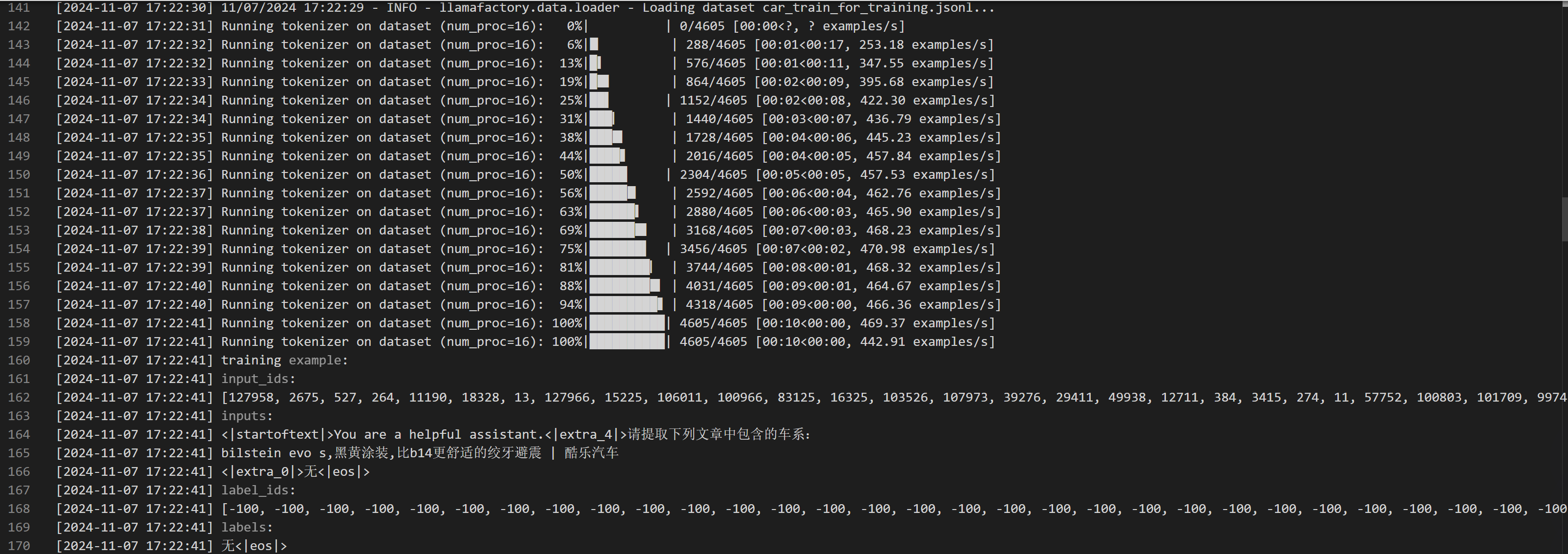
3. 加载预训练模型权重,这一步耗时可能偏长,我们为 Hunyuan-Large 体验机型提供了缓存优化能力。
4. 准备训练,打印 DeepSpeed 一些参数信息及训练任务信息,包括要训练的样本数量、全局 batch size、总迭代步数等信息。
5. 开始训练,打印训练迭代步数、loss、epoch 等进度信息,这里默认每10步打印一次训练信息日志,示例中大概每一步迭代耗时在 25 秒左右。
训练到达指定一定步数或训练完成时,会保存 checkpoint,保存的 checkpoint 可以用于后续启动推理和评测等,下图为保存 checkpoint 的日志。
步骤三:精调后模型部署
本步骤会用到 TI-ONE 平台的【模型服务-在线服务】功能,具体步骤如下:
3.1 部署服务
服务名称可以自定义,其中模型来源选择 CFS 或者 GooseFSx ,并选中模型存储的 CFS 或者 GooseFSx 实例,路径按实际训练输出路径填写,填写到 checkpoint 这一级目录,运行环境选择内置的 LLM / angel-vllm(2.1) 镜像,最低资源需求(按默认开启 NF4 量化):内存 1TB,GPU 显存 320 GB ,例如 A100 * 8 卡或更大显存的机型。
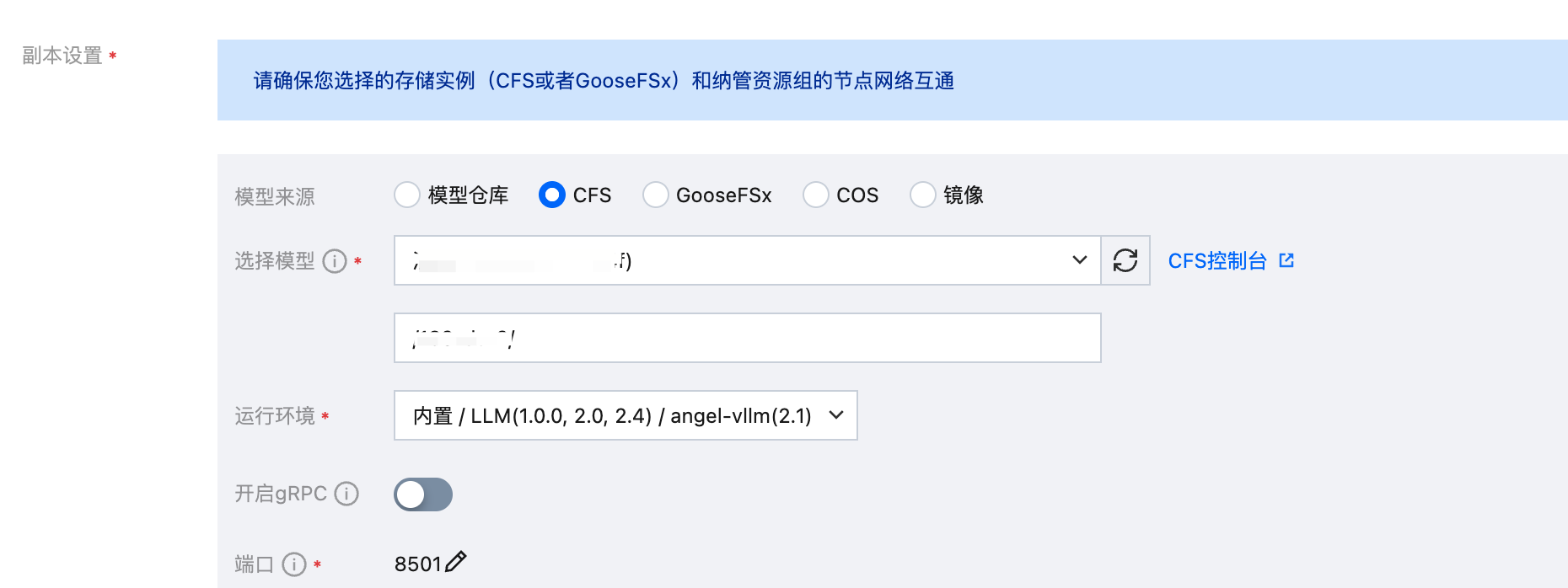
由于本文中使用的精调方式是 LoRA,因此默认保存的 checkpoint 并不是完整模型权重,在推理时需要和原始权重进行合并。通过平台首次启动 LoRA 模型时,服务会进行权重的自动合并,并将合并后的模型保存在模型目录的
merged_model 子目录下,后续重新用该 checkpoint 启动推理服务的话,会自动使用合并后的权重,无需重新合并。如下图日志表示正在合并权重: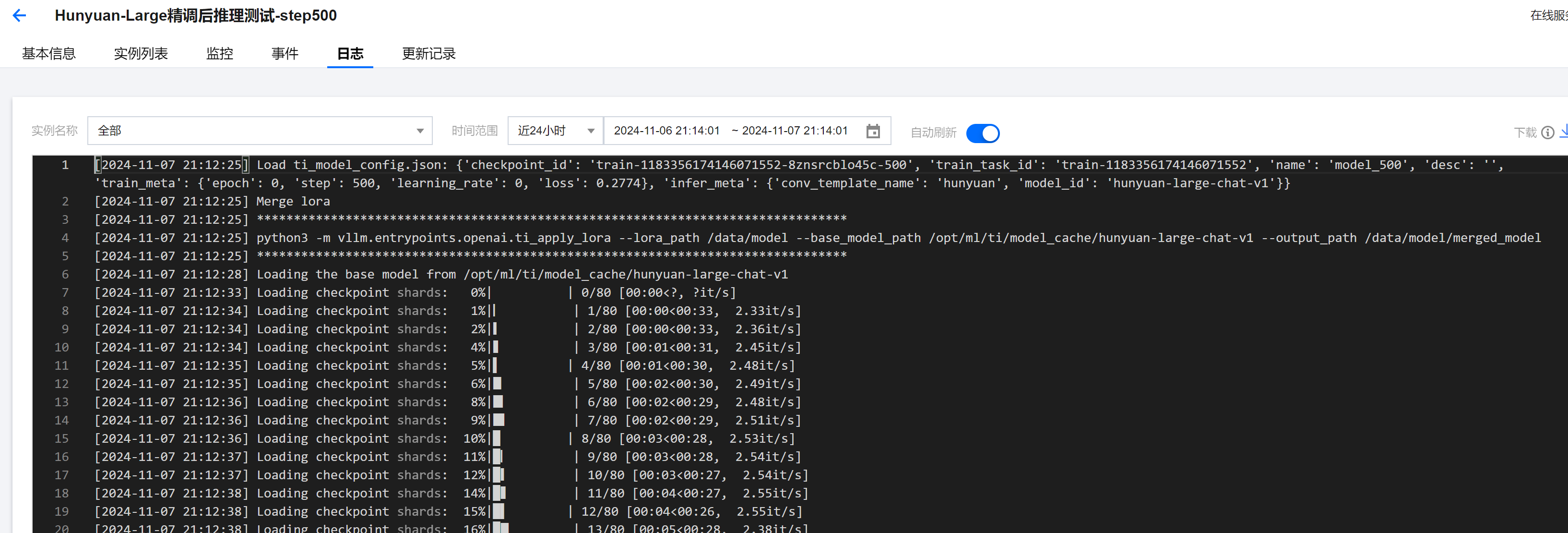
权重合并完成后服务会进入启动流程,当出现以下日志表示模型服务启动完成,此时在线服务的状态会从“就绪中”变为“运行中”。
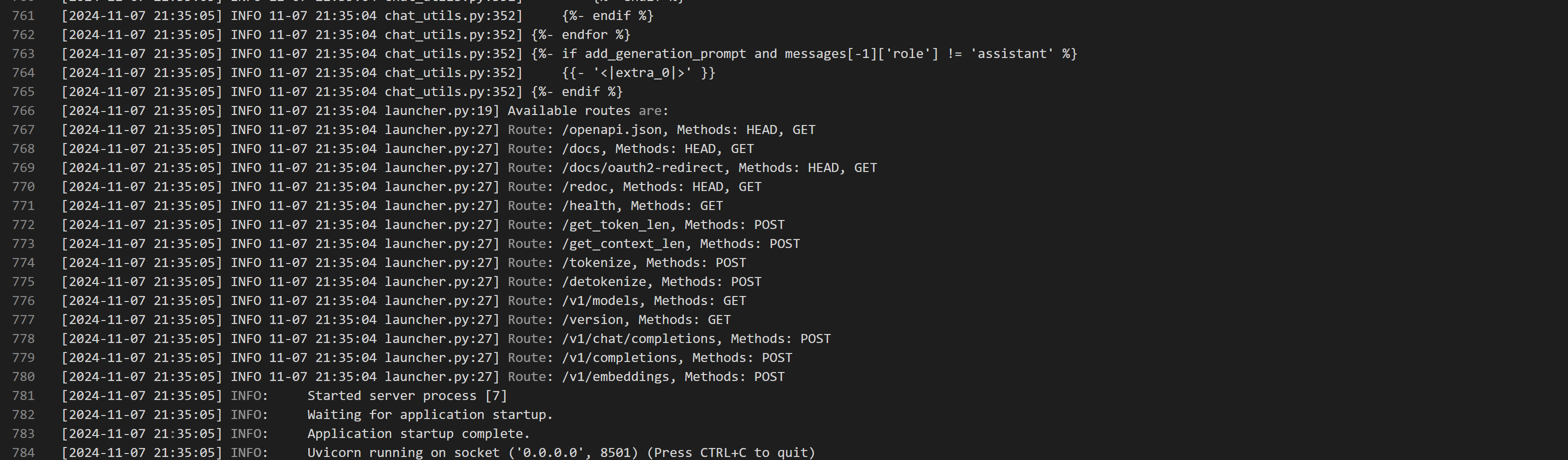
3.2 调用服务
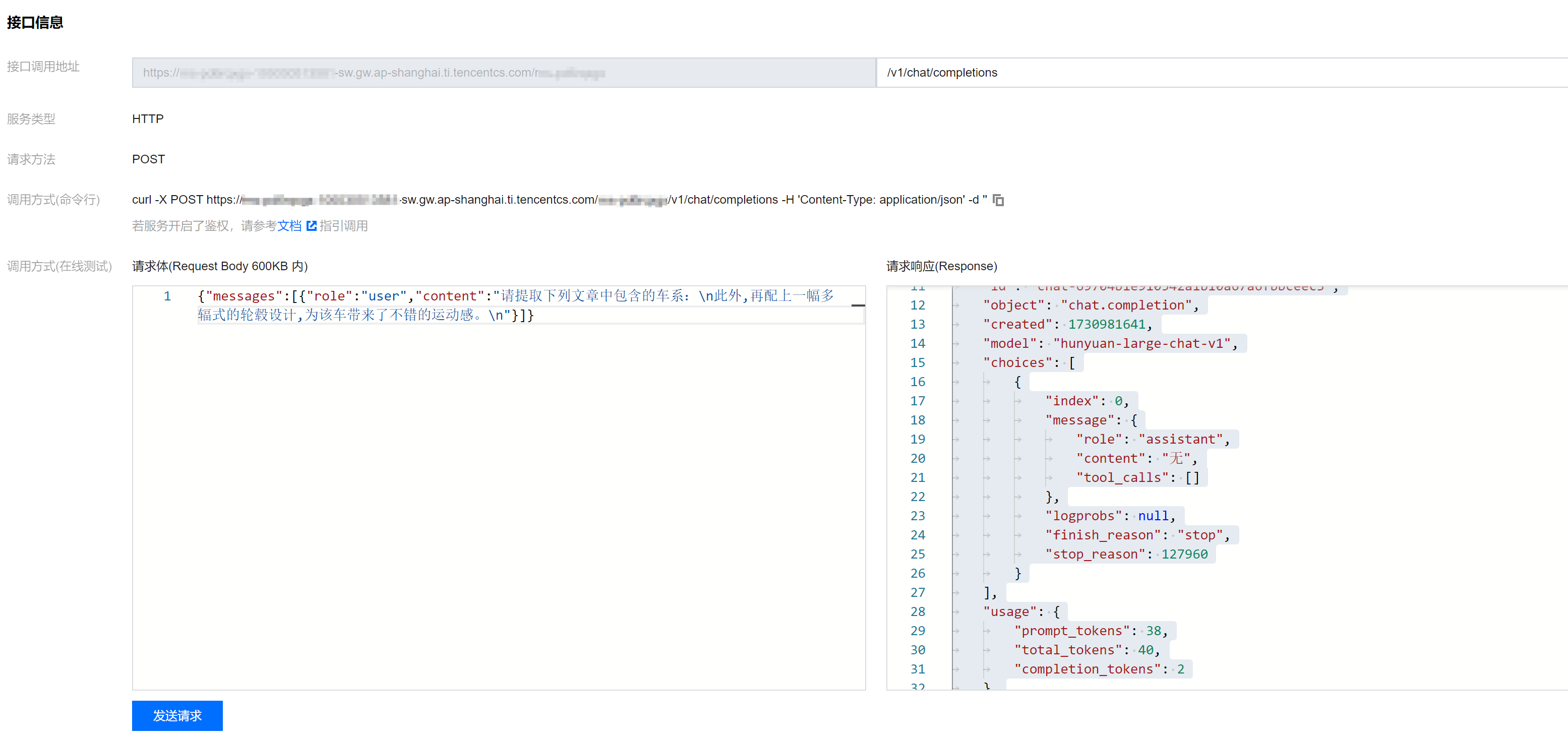
回到上级菜单,单击服务的【服务调用】标签页面:

在接口调用地址处输入
/v1/chat/completions然后输入请求体,接口格式兼容目前流行的 OpenAI Chat Completions 接口,如图所示,我们可以拿 Hunyuan-Large 开源项目里带的 car_test.json 测试集抽几条样本试验一下,例如请求体为:
{"messages":[{"role":"user","content":"请提取下列文章中包含的车系:\\n此外,再配上一幅多辐式的轮毂设计,为该车带来了不错的运动感。\\n"}]}
如图所示:
您也可以直接使用 OpenAI SDK 或者其他大模型应用框架如 Dify、LangChain 等接入 TI-ONE 平台在线服务的 API,endpoint 填写 TI-ONE 平台的接口调用地址后面加
/v1即可。若您需要开启类似 OpenAI API key 的鉴权,可以在服务启动时增加环境变量 VLLM_API_KEY 为你需要设置的 API_KEY,并在调用时指定即可。附录
使用 Tensorboard 可视化训练过程
有可能直接通过训练任务的日志观察训练指标不够直观,此时我们也可以使用平台提供的 Tensorboard 功能来更加可视化地观察训练过程,指引如下:
单击训练任务右侧操作一栏中的 Tensorboard 按钮。


单击跳转,稍等片刻会跳转到任务对应的 tensorboard 页面,如下图所示:
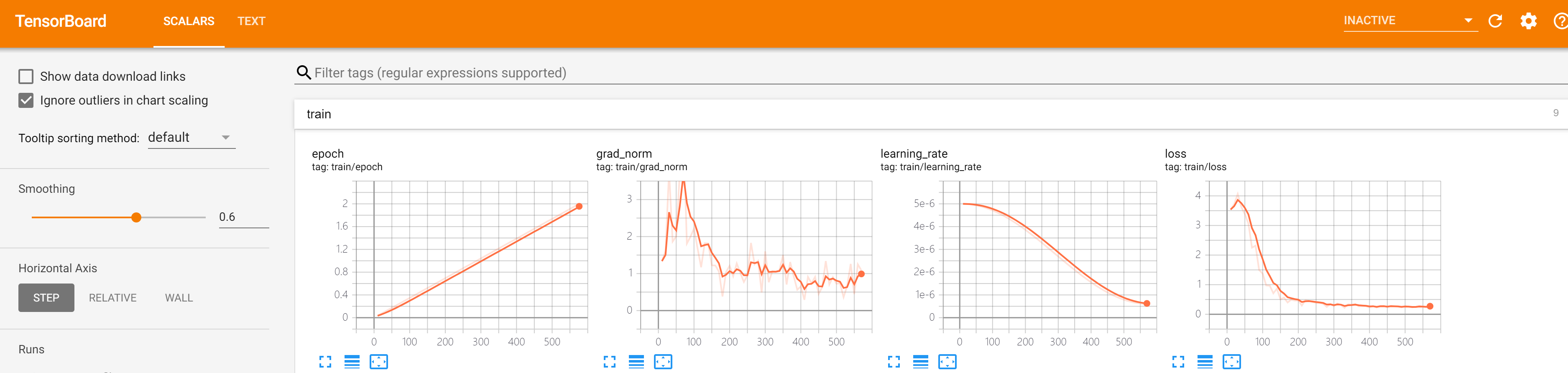
可以观察任务的学习率、loss 等变化曲线,若 loss 收敛情况良好,一般没有太大问题。若您的数据在实际精调时 loss 收敛情况不好,可能需要具体分析,可以参照下面的 训练调参指引 进行一些调参优化。
训练调参指引
Hunyuan-Large 模型学习能力很强,在小规模训练数据上可能会有过拟合问题。平台默认参数为推荐参数,可以先跑 2 个 epoch 观察下训练 loss 曲线收敛情况再做调整,建议如下:
超参调整建议
Epoch:训练轮次推荐取值 2~3,MoE 模型拟合能力强,建议不要超过 5,避免过拟合。
BatchSize:默认为 1,不建议随意调大,否则容易出现显存不足问题,显存富余较多时再考虑调整。
LearningRate:学习率建议在 5e-6~1e-4 范围内调整,可以视实际情况调整:
如果训练 loss 收敛太快,或者出现明显震荡,说明可能学习率偏大。
如果训练 loss 收敛太慢,或者收敛值很高,说明可能学习率偏小。
如果训练 loss 收敛值小于 0.1,可能存在过拟合风险,建议尝试调小学习率或 Epoch。
如果训练 loss 收敛值大于 1,可能训练还不够充分,建议尝试调大学习率或 Epoch。
Step:表示每隔多少步迭代保存一次 checkpoint,建议根据训练的总迭代步数调整。
FinetuningType:若机器资源很少,选择 "LoRA";若机器资源足够,希望达到更高的模型精调性能上限或者训练数据集较大,推荐选择 "Full"。
MaxSequenceLength:建议根据实际训练集数据 token 长度调整,超长的数据会被截断影响效果。
GradientAccumulationSteps:梯度累积步数会影响全局 BatchSize,全局 BatchSize = 训练卡数 * GradientAccumulationSteps * 单卡 BatchSize,建议全局 BatchSize 在 32 或 64 左右,同时尽量保证总迭代步数不要太少(推荐500步以上)。
训练数据建议
如果训练起始 loss 非常高,例如大于 10,可能是数据存在问题,或者使用的 Tokenizer 或对话模板错误等,建议仔细排查;偏高的起始 loss 一般说明训练数据与基座模型的训练数据区别较大。
为避免过拟合,增加样本多样性,可以考虑加入一些通用数据一起训练,如平台数据构建内置的一些算法场景数据。
本文使用的数据仅为示例数据,实际业务中使用的训练数据可能更加复杂,可以综合结合数据的特点及其他开源模型的精调经验来调整训练超参。
推理镜像特性说明
内置 angel-vllm(2.1) 推理镜像使用了腾讯自研优化的 Tilearn Angel-vLLM 框架进行了推理加速,其在开源 vLLM 框架基础上额外支持了以下亮点特性:
NF4(NormalFloat)量化:相比开源 vllm 的实现,无需做模型转换,在保持量化精度的同时充分利用 GPU 资源实现了推理性能的大幅提升,且对 Hunyuan-Large 这样的混合专家模型(MoE)进行了特定优化。
Lookahead 并行解码:相比开源实现,无需额外的小模型或模型头,可以做到并行解码的结果和非并行解码的结果一致,对于输出文本中有大部分在输入文本中都出现过(例如 RAG 场景),或是大量请求中有相似的请求或答案的情况下有明显的加速效果。
您可以在部署在线服务时在【高级设置】这里配置相应环境变量来开启对应功能:
QUANTIZATION:量化模式,我们为 Hunyuan-Large 模型默认开启了"ifq_nf4"量化模式,以适配更多机型部署。您也可以手动指定量化模式,例如 NVIDIA Hopper 系列机型使用"fp8"量化模式;
USE_LOOKAHEAD:默认为"0",设置为"1"表示开启 Lookahead 并行解码。
NUM_SPECULATIVE_TOKENS:默认为"6",表示 Lookahead 并行解码一次解码长度,若实际需要支持的并发数较大,可以调小此值,并发数小,可以调大此值。
MAX_MODEL_LEN:模型上下文长度,我们默认调小了此参数到最大 8192,以适配更多机型部署,您可以手动修改此值。



