Spark之逻辑处理流程(二)
原创
【往期链接】:
前言
本文参考许利杰老师的《大数据处理框架Apache Spark设计与实现》,在这里记录一下相关的笔记,补充了一些个人理解,如有不对还请指正。参考链接:https://github.com/JerryLead/SparkInternals
2.1 Spark逻辑处理流程概览
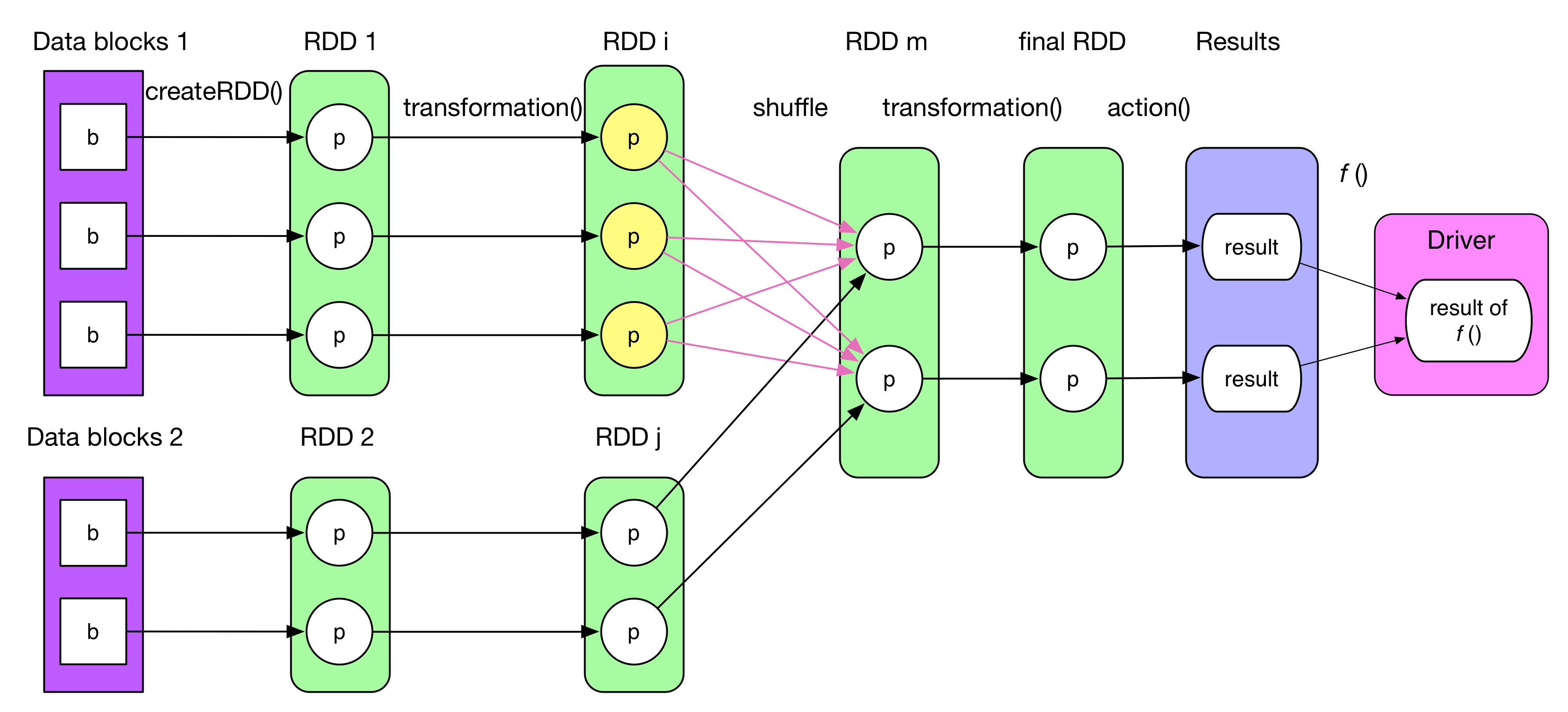
逻辑处理流程(Logical plan)上一章有提到过,本章将对其详细讲解。总的来说,逻辑处理流程可以分成四个部分:
- 数据源(Data Block):也就是数据从哪来,比如说HDFS、k-y形式的HBase等。
- 数据模型:简单说就是可以理解成抽象的数据类型。比如在MapReduce里面是<K,V>record,Spark对这里改进了一下,也就是RDD(Resilient Distributed Datasets)。本质上是一个抽象类。和ArrayList这些数据类型相比,RDD主要两点区别:
- 只是一个逻辑概念。简单说就是如果用户没cache(),内存中不会存RDD,计算完就消失。而ArrayList等这些数据结构都是会常驻内存。
- 可以包含多个分区。毕竟Spark是处理分布式计算的,肯定得支持多个分区。
- 数据操作:也就是我们可以对RDD干嘛。简单说分成两种操作,一个是transformation(),一个是action():
- transformation():顾名思义就是把RDD变来变去,这里注意的是,RDD本身不能修改,也就是说每次transformation完是生成一个新的,之前那个不会动。(结合前面看也就是说如果不cache()的话,transformation()完之前那个RDD就没了)
- action():就是计算最后的结果。action()会触发Spark提交Job,也就是真正开始执行。比如count()一下,show()一下。(所以在使用过程中需要注意,如果前面RDD或者Dataframe没有cache(),后面又反复count()、show()的话就会重复计算。)
- 计算处理结果:通常分布式的计算结果分为两种:
- 不需要在Driver端计算:比如直接将结果保存分布式文件系统(HDFS这种)。
rdd.save("hdfs://xxxxx")。 - 需要在Driver端计算:比如count()这种,需要先使用task统计每个RDD中的partiton的元素个数,然后汇聚给Driver最后再加起来算一下。
- 不需要在Driver端计算:比如直接将结果保存分布式文件系统(HDFS这种)。
2.2 Spark逻辑流程生成方法
对于Spark来说,需要有一套通用的方法,能够将应用程序自动转化成确定性的逻辑处理流程,也就是RDD之间的数据依赖关系。因此,需要解决一下三个问题:
- 如何产生R5DD,产生什么样的RDD?
- RDD之间的数据依赖关系怎么建立?
- RDD中的数据怎么计算?
2.2.1 如何产生RDD,产生什么样的RDD?
通常来说,进行transformer操作的时候就会生成RDD。这里同样的会有两种情况:
- 一个transformer只创建一个RDD。比如map(func)等一些简单的操作。
- 一个transformer创建多个RDD。比如join()、distinct()等较复杂的动作,中间会产生多个RDD,但是最后只会返回一个用户。
以下展示了一些常用的Transformation()会生成的RDD:
Transformation | Generated RDDs | Compute() |
|---|---|---|
map(func) | MappedRDD | iterator(split).map(f) |
filter(func) | FilteredRDD | iterator(split).filter(f) |
flatMap(func) | FlatMappedRDD | iterator(split).flatMap(f) |
mapPartitions(func) | MapPartitionsRDD | f(iterator(split)) |
mapPartitionsWithIndex(func) | MapPartitionsRDD | f(split.index, iterator(split)) |
sample(withReplacement, fraction, seed) | PartitionwiseSampledRDD | PoissonSampler.sample(iterator(split)) BernoulliSampler.sample(iterator(split)) |
pipe(command, [envVars]) | PipedRDD | |
union(otherDataset) | 生成多个RDD | |
intersection(otherDataset) | 生成多个RDD | |
distinct([numTasks])) | 生成多个RDD | |
groupByKey([numTasks]) | 生成多个RDD | |
reduceByKey(func, [numTasks]) | 生成多个RDD | |
sortByKey([ascending], [numTasks]) | 生成多个RDD | |
join(otherDataset, [numTasks]) | 生成多个RDD | |
cogroup(otherDataset, [numTasks]) | 生成多个RDD | |
cartesian(otherDataset) | 生成多个RDD | |
coalesce(numPartitions) | 生成多个RDD | |
repartition(numPartitions) | 生成多个RDD |
2.2.2 如何建立RDD之间的数据依赖关系?
上面说到,transformation()之后会生成一堆RDD,接下来的问题就是这些RDD之间的数据依赖关系是怎么样的。总的来说可以分为两大类:窄依赖(NarrowDependency)、宽依赖(ShuffleDependency)。而区分这两种依赖的依据是:生成的child RDD的各个分区是否完全依赖parent RDD的每个分区的整体或者是一部分,如果是依赖每个分区的一个整体则是窄依赖;如果是只依赖每个分区的一部分则是宽依赖。之所以要划分 NarrowDependency 和 ShuffleDependency 是为了生成物理执行图。
1)窄依赖(NarrowDependency)
- 一对一依赖(OneToOneDependency)(1:1)
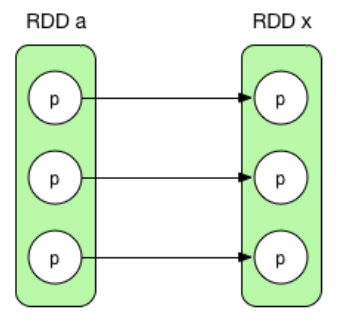
一对一映射关系,比如map()、filter()。
- 区域依赖(RangeDependency)(1:1)
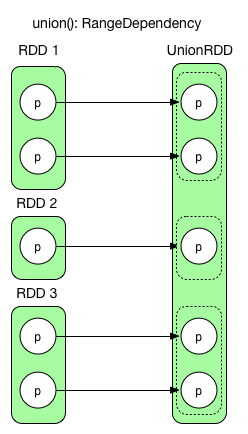
可以理解为区域化一对一,比如union(),如上图所示。
- 多对一依赖(非官方定义,属于NarrowDependency)(N:1)
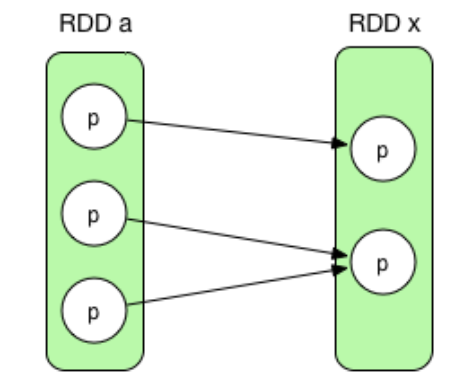
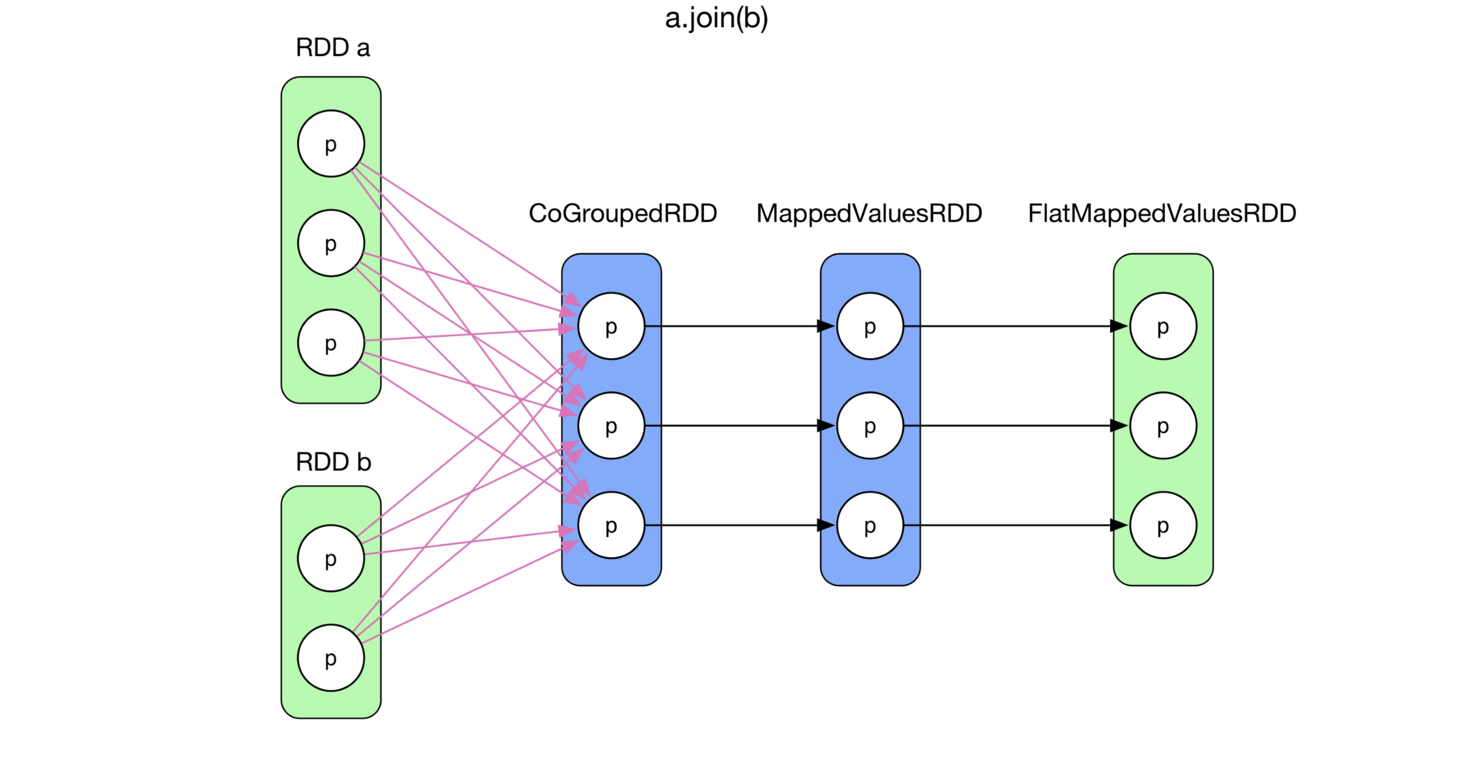
表示一个child RDD中的分区依赖多个parent RDD中的分区,比如join()、cogroup()。下图就是一个join()的例子,join() 将两个 RDD聚合在一起。首先进行 cogroup(),得到<K, (Iterable[V1], Iterable[V2])>类型的 MappedValuesRDD,然后对 Iterable[V1] 和 Iterable[V2] 做笛卡尔集,并将集合 flat() 化。
- 多对多依赖(非官方定义,属于NarrowDependency)(N:N)
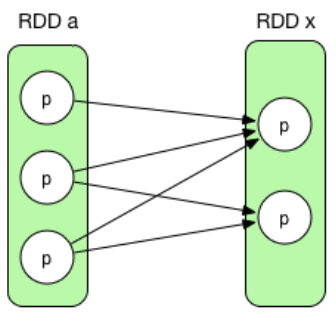
表示一个child RDD中的分区依赖多个parent RDD中的分区,同时一个parent RDD依赖多个child RDD。常见的是cartesian()
2)宽依赖(ShuffleDependency)
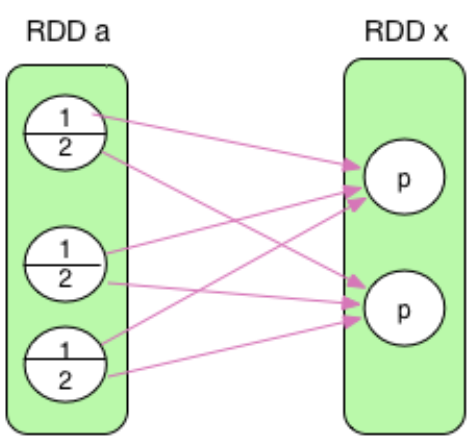
宽依赖也可以理解成“部分依赖”,宽依赖跟 MapReduce 中 shuffle 的数据依赖相同(mapper 将其 output 进行 partition,然后每个 reducer 会将所有 mapper 输出中属于自己的 partition 通过 HTTP fetch 得到)。从上图可以看出来,宽依赖的child RDD的分区只会依赖parent RDD的一部分。
为什么要区分窄依赖和宽依赖呢?主要是为了在执行时,窄依赖可以在同一个阶段进行流水线(pipline)操作,不需要进行shuffle。而宽依赖顾名思义,是需要shuffle的。此外就是这么区分的话便于实现。
2.2.3 RDD中的数据怎么计算
上面说了RDD之间的依赖,现在要说每个RDD的每个分区里面,数据(record)又是怎么计算的。Spark的大多数transformation()都是类似映射函数的,具有固定的计算方式,称之为“控制流”。
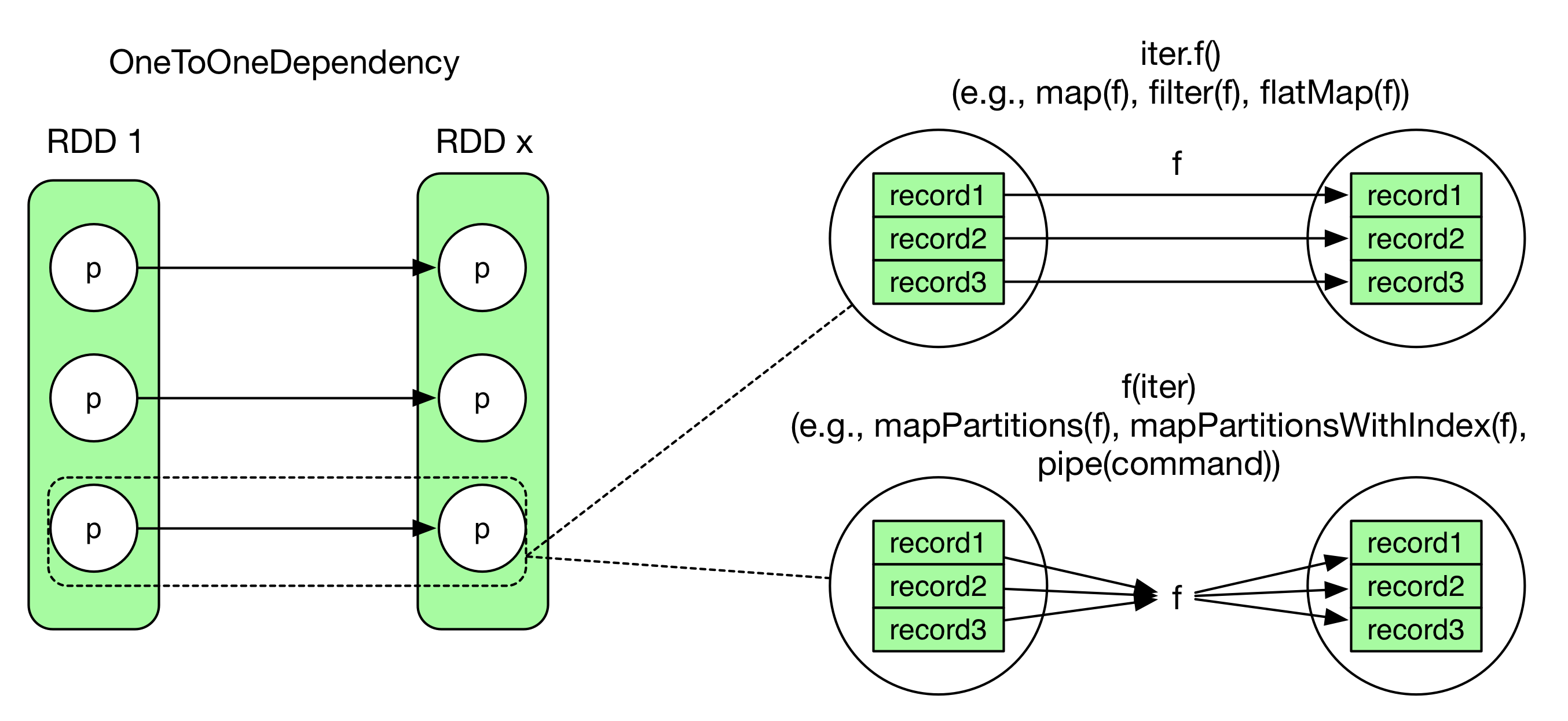
下图举了两个例子,虽然二者在数据依赖上都是一对一依赖(OneToOneDependency),但是二者的func的“控制流“不一样:
- map(fuc):就是读一个record,处理一个record,再把处理完的吐出来
- mapPartitions(fuc):则是对分区内所有的record处理完之后再集中输出。(类似MapReduce里面的map()和cleanup()函数)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。