「最佳实践」通过ES的机器学习功能,实现一站式NLP语义聚合
原创
「最佳实践」通过ES的机器学习功能,实现一站式NLP语义聚合
原创
Rassyan
修改于 2024-05-14 10:05:19
修改于 2024-05-14 10:05:19
引言
随着腾讯云ES 8.8.1及其后续版本8.11.3、8.13.3的推出,腾讯云ES在人工智能、向量搜索和自然语言处理(NLP)等领域功能得到了显著的增强。这些新功能为开发者提供了更多的可能性,尤其是在处理复杂的NLP任务时。本文将探讨如何利用腾讯云ES的机器学习功能,实现一站式的NLP语义聚合,并通过demo来实践来这一过程。
语义聚合的挑战
语义聚合,就是将多个文档中的文本,从表达意义上进行归类。举个简单的例子来理解,比如“我爱中国”,“我喜欢钻研技术”,都属于积极表述,而“我讨厌雨天”,“我很生气”,都属于消极的表述。
ES传统的文本聚合方法依赖于文本中的共同value或term,而表述各异的文本几乎不存在相同的value,即便对text字段开启fielddata,利用不同文档分词后会产生相同的term,这种归类方式仅仅是表面的词汇聚类,也无法达成语义上的聚合归类。
我们知道,通过将文本转换为向量表示,我们可以捕捉到文本的语义信息,利用这些信息ES可以进行更加精准的搜索。那么聚合呢?用于存储向量化的字段类型dense_vector是不支持聚合的。这是因为向量字段不同于传统的文本、数值型字段,不同的原文的embedding向量几乎不会有相同的取值,密集向量类型的值的分布是“稀疏”的,这使得对其进行聚合既缺乏意义,也在技术上难以实现。
利用ES机器学习功能的最佳实践
ES的机器学习功能提供了一种解决方案。从官方这篇文档,Classify text,可以了解到ES的机器学习功能,除了支持向量化模型推理外,还支持文本分类模型的推理。那么利用这一点,我们可以使用文本分类模型对文本数据打上语义“标签”,从而使传统的ES聚合能力得以应用于语义聚合。
我们动手尝试一个demo,在Hugging Face上查找Text Classification类的模型,比如这个情感分析的文本分类模型,它可以推理一段文字的情感表达类型。
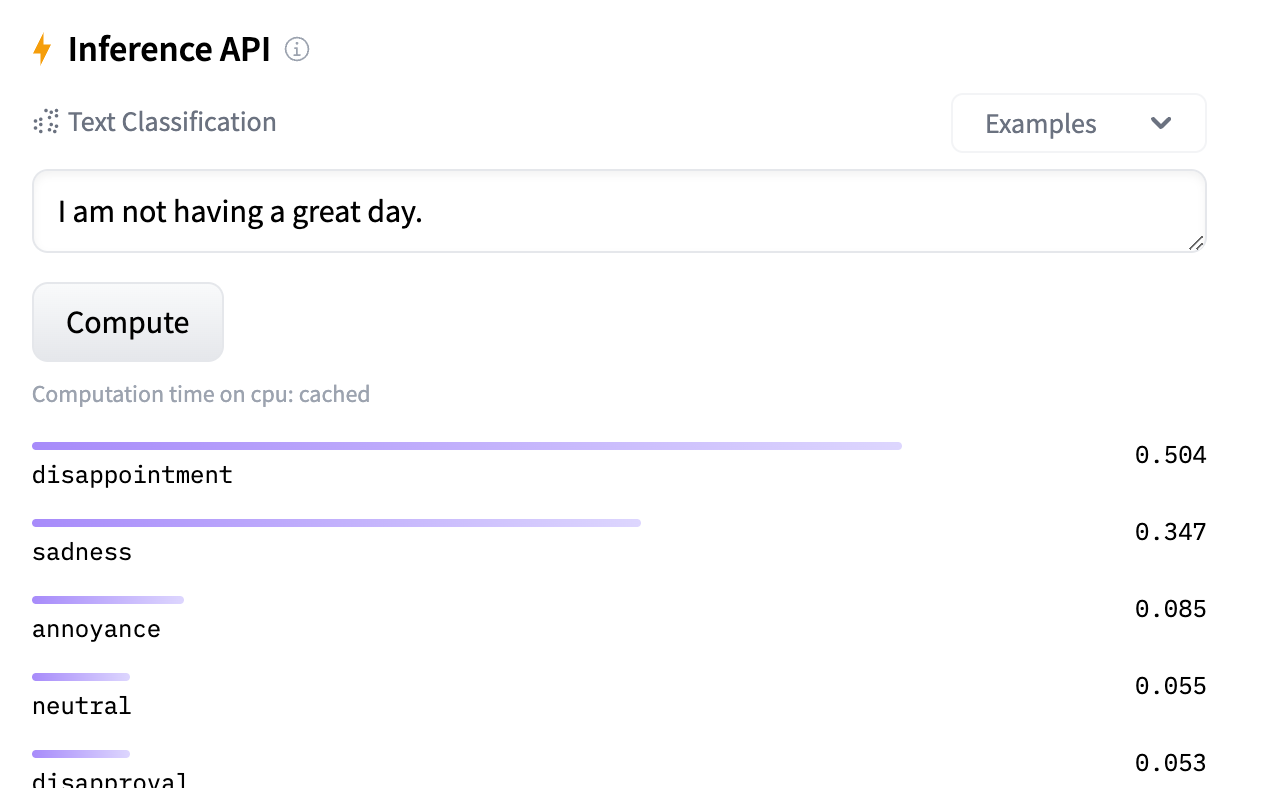
我们通过eland工具,将该模型导入ES,在可以访问公网的机器上执行 docker run -it -e HF_ENDPOINT=https://hf-mirror.com --rm docker.elastic.co/eland/eland eland_import_hub_model --url http://9.99.64.21:9200 -u elastic -p elastic_123 --hub-model-id SamLowe/roberta-base-go_emotions --start --insecure --task-type text_classification,从Hugging Face上拉取模型导入ES。

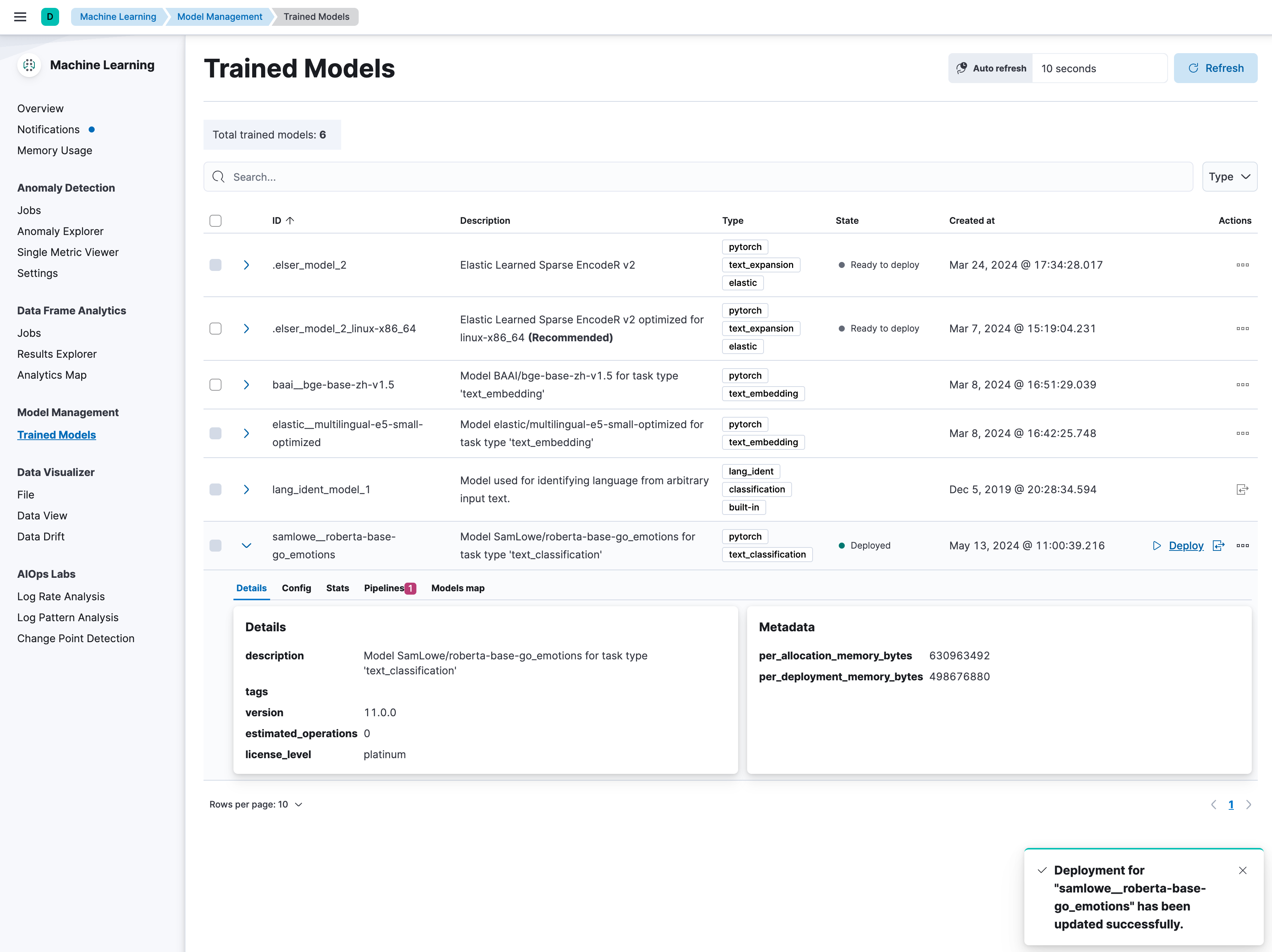
导入模型后,在Kibana的模型管理页面中,可以看到该模型,我们直接点击Deploy对该模型进行部署。
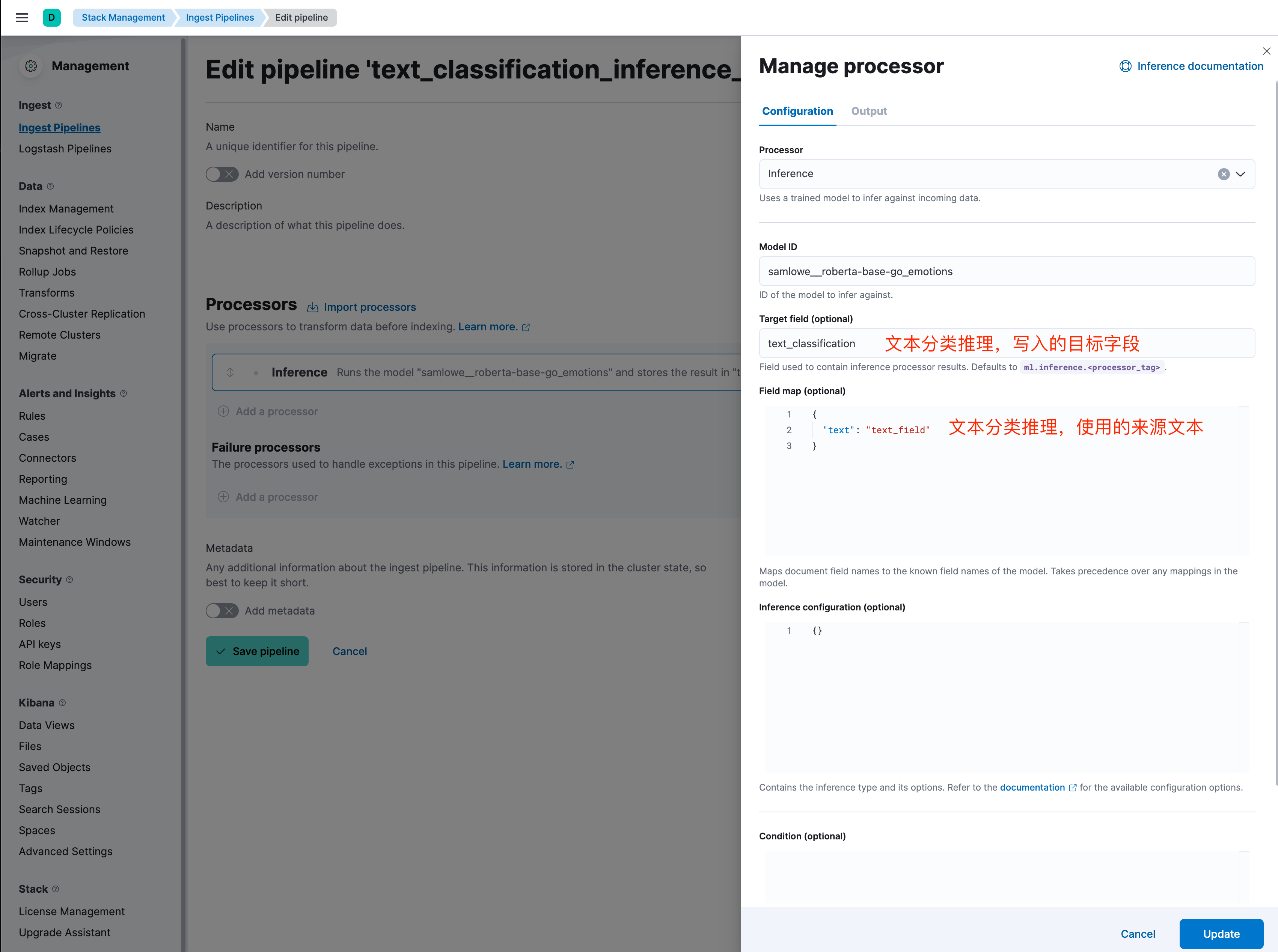
同样在Kibana的Ingest Pipelines管理页面,我们可以定义一个用于“文本分类”的推理管道,按照图示简单填写即可。这个管道将在数据写入时自动应用模型,为文本数据添加语义标签。
创建一个demo用的索引。
PUT text_classification_demo
{
"mappings": {
"dynamic_templates": [
{
"message": {
"match": "text",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2048,
"type": "keyword"
}
},
"type": "text"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
},
"settings": {
"index": {
"refresh_interval": "1s",
"number_of_shards": "2"
}
}
}结合Hugging Face上开源的测试集,我们简单编写一个python脚本,将文本数据批量写入ES索引,并指定推理管道。安装python依赖pip install datasets elasticsearch,demo代码如下。
import json
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
from elasticsearch.helpers import BulkIndexError
from datasets import load_dataset
dataset = load_dataset("go_emotions", "simplified", split='train')
es_username = 'elastic'
es_password = 'elastic_123' # 修改ES密码
es_host = '9.99.64.21' # 修改ES HOST
es_port = 9200
es = Elasticsearch(
hosts=[{'host': es_host, 'port': es_port, 'scheme': 'http'}],
basic_auth=(es_username, es_password),
)
def prepare_data(dataset):
for doc in dataset.select(range(40000)):
yield {
'_index': 'text_classification_demo',
'_id': doc['id'],
'_source': json.dumps(doc)
}
def bulk_insert(data, chunk_size=100):
try:
success, _ = bulk(es, data, chunk_size=chunk_size, stats_only=True,
pipeline="text_classification_inference_pipeline",
request_timeout=600)
print(f"Successfully indexed {success} documents.")
except BulkIndexError as e:
print(f"{len(e.errors)} document(s) failed to index.")
for error in e.errors:
print("Error details:", error)
bulk_insert(prepare_data(dataset))运行脚本,我们会从Hugging Face的测试集中拉取40000条文本,通过_bulk的方式,指定ingest pipeline为我们刚刚定义的text_classification_inference_pipeline,将数据写入ES的text_classification_demo索引。

数据写入后,可以看到JSON source如图所示,扩充了我们通过pipeline推理得到的标签。
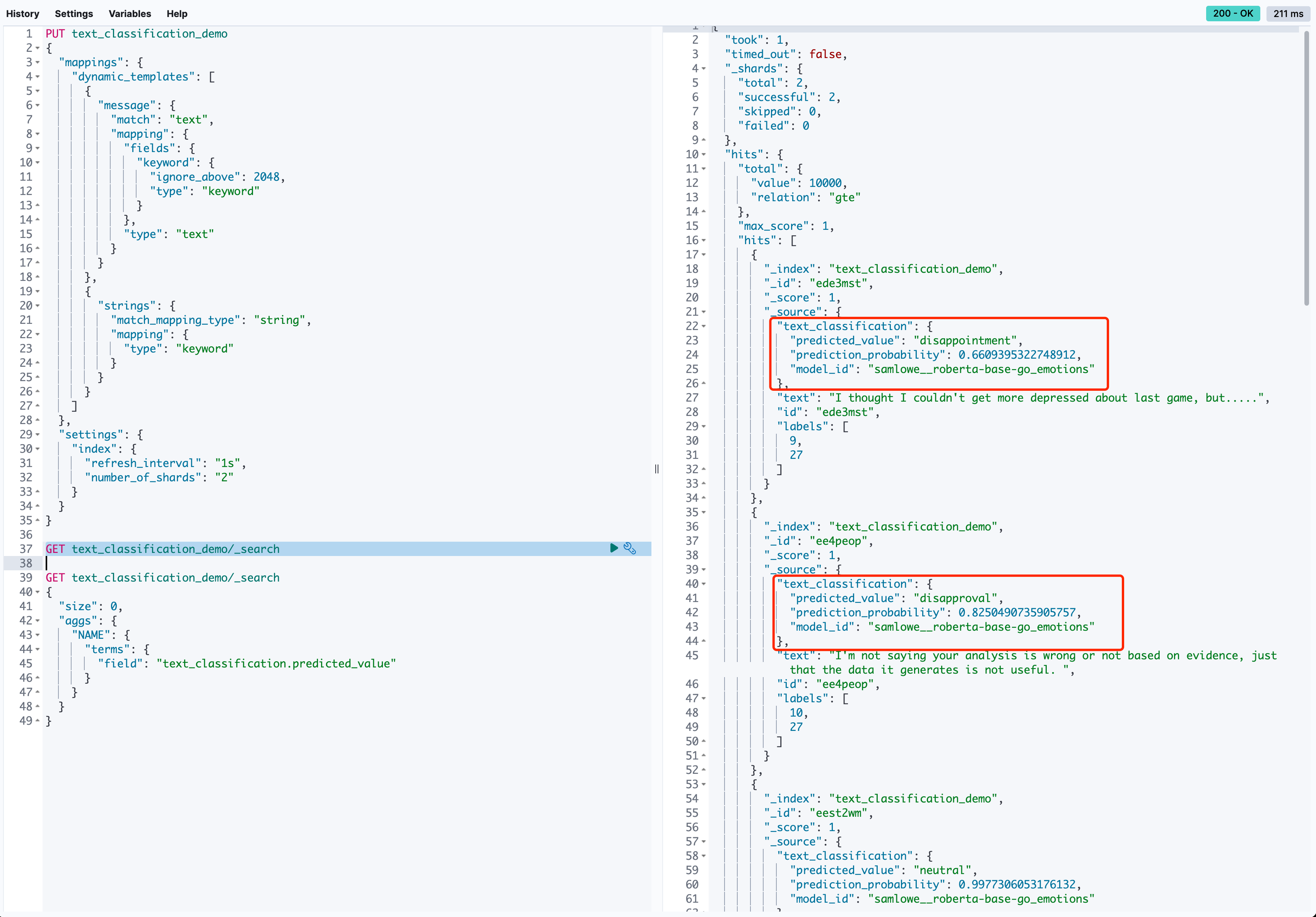
对语义标签字段进行聚合查询,可以看到测试集中表述各异的不同文本,在情绪语义上得到了良好的分类。至此,我们得到了文档的语义聚合结果。
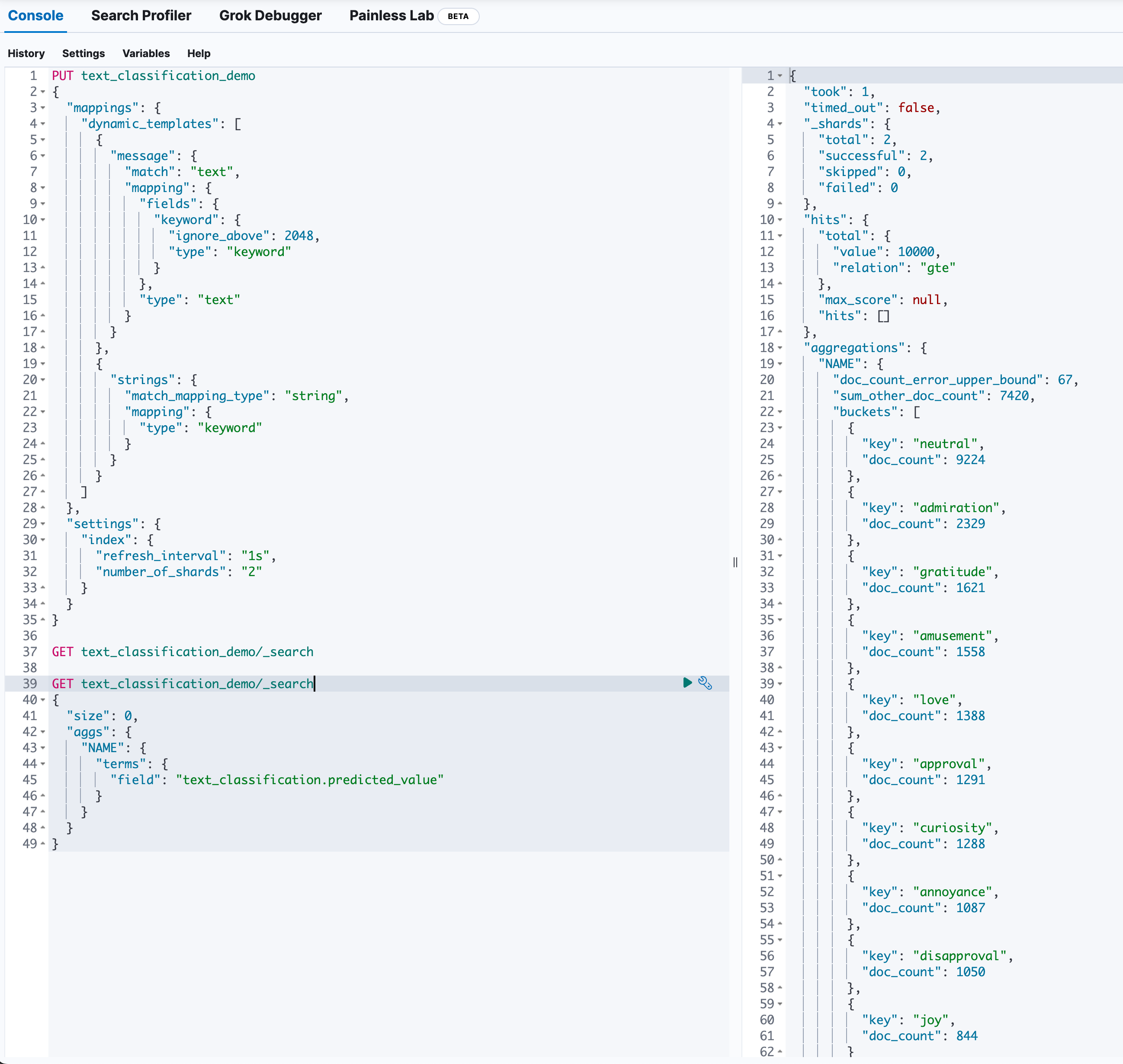
进一步,也可以利用Kibana的可视化工具,对聚合结果进行可视化分析,从而更直观地理解文本数据的语义分布。
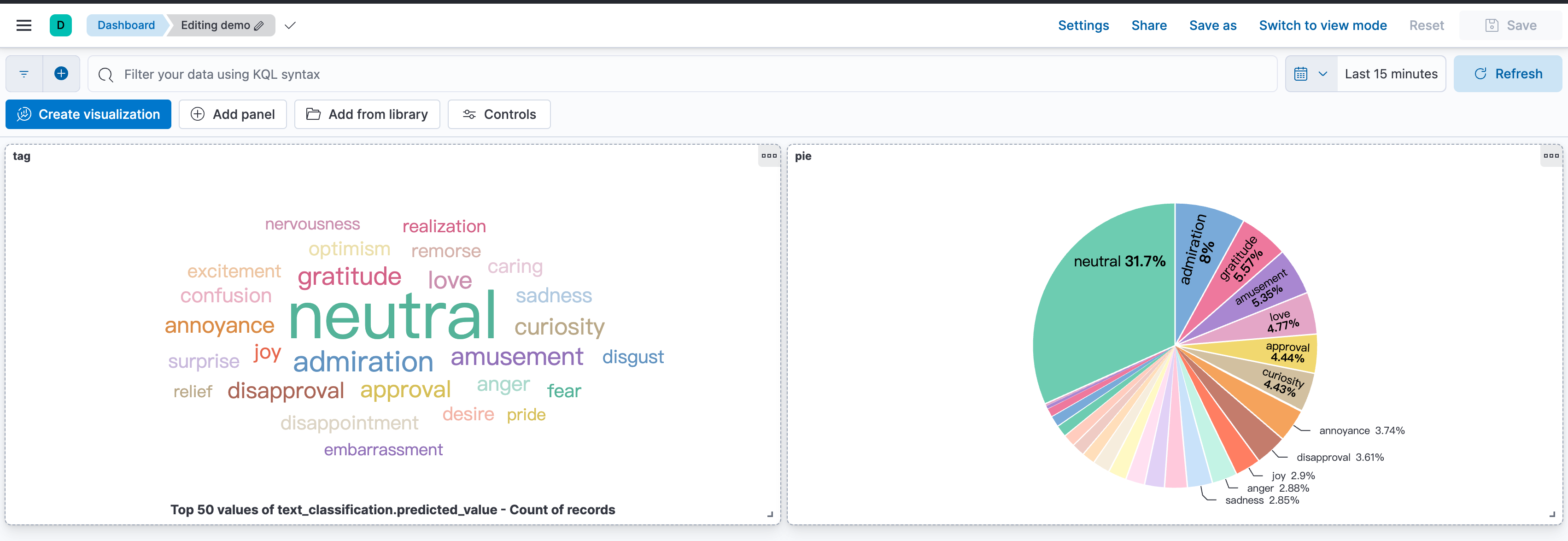
引申
文本分类模型
如果场景简单,如本次demo,使用开源的文本分类模型就可以实现。针对具体业务的场景,需要贴合业务的文本分类模型,可能需要根据具体业务场景定制化文本分类模型。这可能涉及到模型的训练或微调,以确保语义标签的准确性和覆盖范围。ES支持以下类型的NLP模型:
- BERT
- BART
- DPR bi-encoders
- DistilBERT
- ELECTRA
- MobileBERT
- RoBERTa
- RetriBERT
- MPNet
- SentenceTransformers bi-encoders with the above transformer architectures
- XLM-RoBERTa
结合向量搜索
文本的向量化表示,也可以通过ingest pipeline推理得到。如果绑定多个pipeline,我们可以得到字段更丰富的索引,结合向量搜索、文本搜索、混合搜索的能力,语义搜索和聚合也都能更加的灵活。
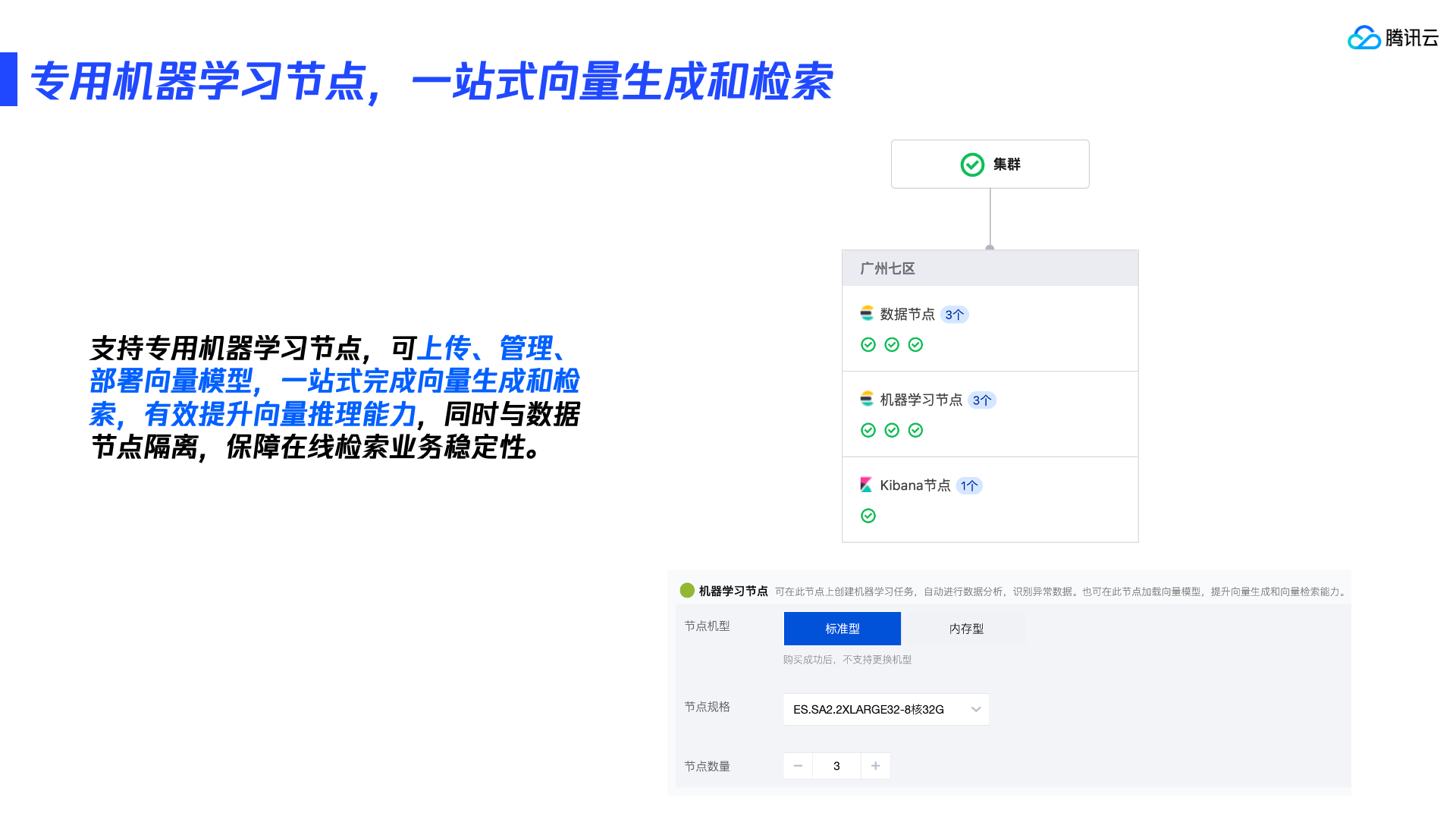
机器学习节点
在腾讯云ES中,支持选用专用的机器学习节点,可以将推理与读写进行资源性的隔离,满足生产环境业务所需的稳定性和易运维性。当然,在测试验证阶段,或要求不高的业务中,也可以不选择专用的机器学习节点,腾讯云ES的数据节点会默认包含机器学习节点的角色。
总结
我们通过ES的机器学习能力,使用文本分类的NLP模型,在ES中一站式地完成了复杂文本的语义聚合能力。这一过程简化了NLP模型的集成,使得ES开发者可以更加专注于应用开发,而不必关注和维护底层的实现细节。
关键步骤
- 选型/微调/训练,适合的文本分类模型
- 将模型以text_classification的类型导入es
- 配置inference pipeline(ingest pipeline)
- 指定ingest pipeline进行数据写入
- 对语义推理字段,进行聚合查询
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号