腾讯主导 Apache 开源项目: InLong(应龙)数据入湖原理分析
腾讯主导 Apache 开源项目: InLong(应龙)数据入湖原理分析

作者:vernedeng
WeData 是一体化全链路大数据开发治理平台,基于天穹大数据基础能力的积累,结合内网各业务痛点,融合了包含数据集成、数据研发、数据探索、数据资产等能力。WeData 数据集成完全基于 Apache InLong 构建,本文阐述的 InLong 数据入湖能力可以在 WeData 直接使用。
前言
关于 Apache InLong
作为业界首个一站式、全场景海量数据集成框架,Apache InLong(应龙) 提供了自动、安全、可靠和高性能的数据传输能力,方便业务快速构建基于流式的数据分析、建模和应用。目前 InLong 正广泛应用于广告、支付、社交、游戏、人工智能等各个行业领域,服务上千个业务,其中高性能场景数据规模超百万亿条/天,高可靠场景数据规模超十万亿条/天。InLong 项目定位的核心关键词是“一站式”、“全场景”和“海量数据”。对于“一站式”,我们希望屏蔽技术细节、提供完整数据集成及配套服务,实现开箱即用;对于“全场景”,我们希望提供全方位的解决方案,覆盖大数据领域常见的数据集成场景;对于“海量数据”,我们希望通过架构上的数据链路分层、全组件可扩展、自带多集群管理等优势,在百万亿条/天的基础上,稳定支持更大规模的数据量。
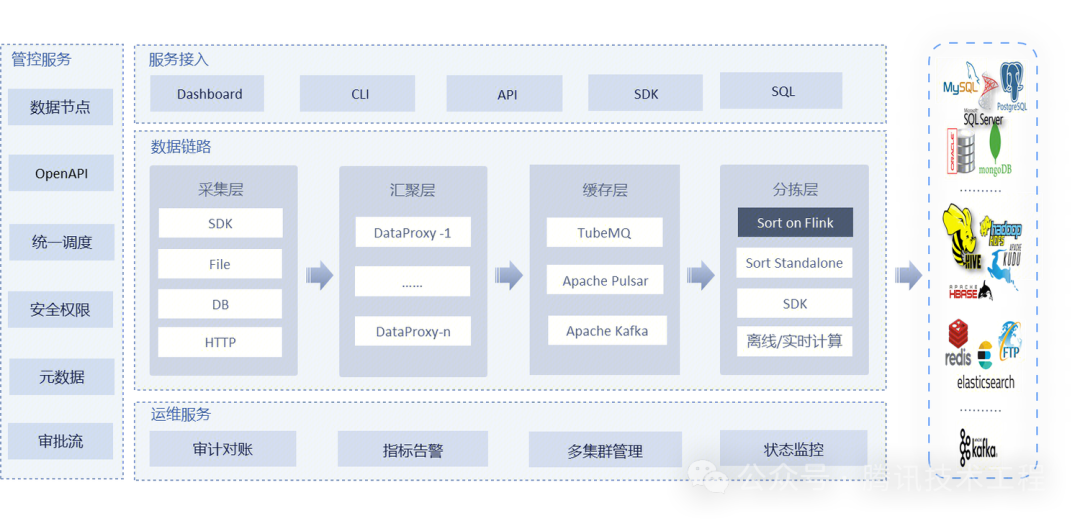
关于 Apache Iceberg
Apache Iceberg 是一种数据湖管理库,其设计简单、易用,并具备强大的查询和分析能力。它解决了数据湖的成本效益和使用复杂性的问题,同时还提供了数据管理与访问的解耦、数据的可见性和一致性保证、快照和时间旅行查询等特性。在各种数据湖的场景中,Iceberg 都能够发挥重要的作用,提高数据湖的可用性和可靠性,同时也为用户带来了更好的数据管理和查询体验。

入 Iceberg 实现原理
InLong 分拣模块简介
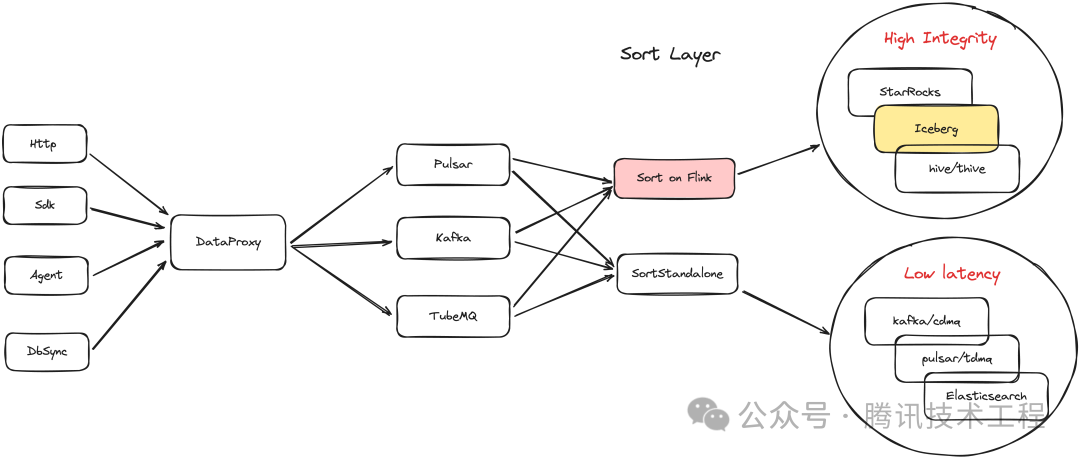
Sort 意为分拣, InLong Sort 负责将业务数据分拣写入到指定的库表中。根据不同的业务场景,如下图所示 InLong Sort 由两种引擎组成:
- Sort Standalone 基于 Flume 引擎,主要针对时效性要求非常高、可以容忍极少数据不一致的业务(例如监控、日志等),将数据实时写入 Kafka、Pulsar、 Elasticsearch 中,实现秒级延迟;
- Sort on Flink 基于 Flink 引擎, 主要针对时效性要求较低,对数据完整性要求更高的业务,流式地将数据写入 StarRocks、Iceberg、Hive 等数仓中,并实现 Exactly Once 语义和数据回滚等能力;
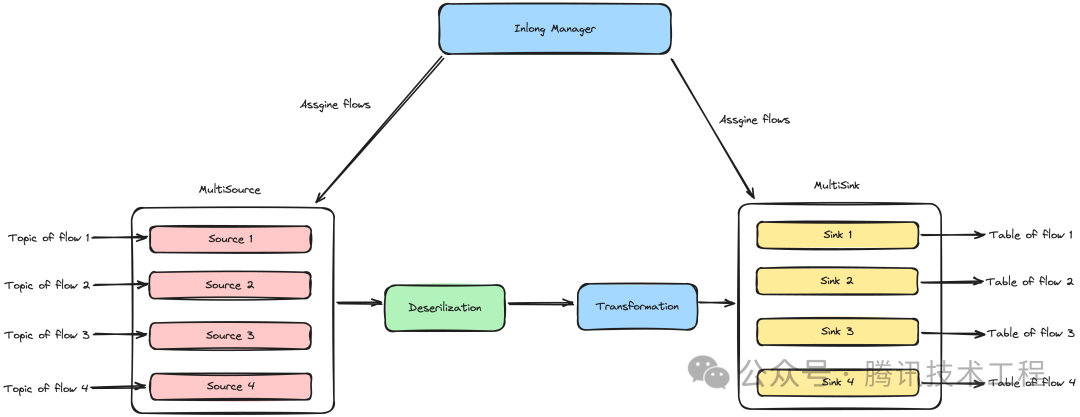
依托于 Apache InLong 全链路,Sort on Flink 拥有更加准确且丰富的对账能力。Sort on Flink 支持单任务多流向,每个流向通过各自的配置文件进行描述,如下图所示,在逻辑上数据流之间是互相隔离的,单个流向的上线和下线由 InLong Manager 控制,且不会影响到其他流向的正常运行。因此对于小流量业务而言,Sort on Flink 通过共享任务资源的方式,拥有更低的接入成本和运营成本。
Sort on Flink 入 Iceberg
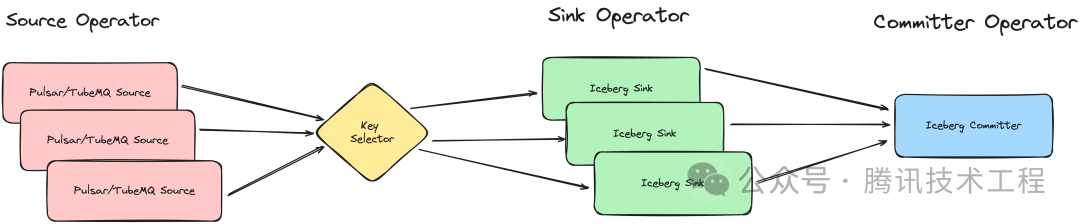
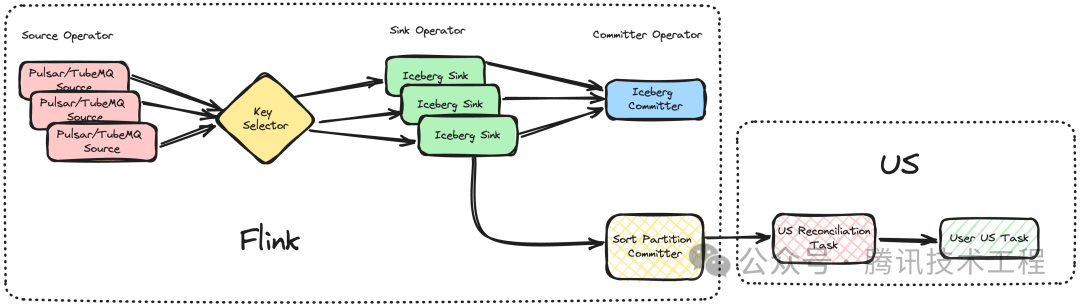
上图为 Sort on Flink 主要流程,入 Iceberg 任务由三个算子一个分区选择器组成,Source 算子从源端拉取数据, Key Selector 负责计算数据对应的分区,并将其映射到分区对应的 Sink 算子上,Iceberg Sink 算子则负责实际的数据写入,最终由 Committer 算子保存写入结果,将其置为用户可见的状态。
接下来介绍 Iceberg 几个特性的实现细节:
Partition
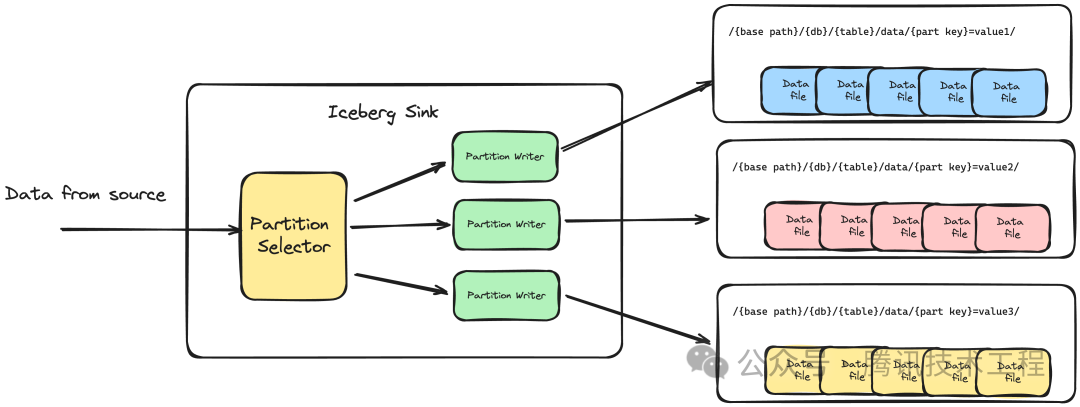
与 Hive 类似,Iceberg 通过文件目录来管理不同分区的数据,所有的数据按照分区写入在对应目录的数据文件中。同时,Iceberg 还支持多级分区,目录按照 /k1=v1/k2=v2/…/kn=vn/ 的方式进行组织。下图为 InLong Sort 将数据写入不同分区的实现细节,根据 Iceberg 的特性,Sort 为不同分区的数据分别初始化了各自的 Writer,通过 Partition Selector 将数据路由至对应的 Writer 上,每个 Writer 在同一时间内只会打开目录下的一个 Data file。在文件写入满足最大文件大小,或者进行 checkpoint 时,当前文件会被关闭并记录。
Update and Delete
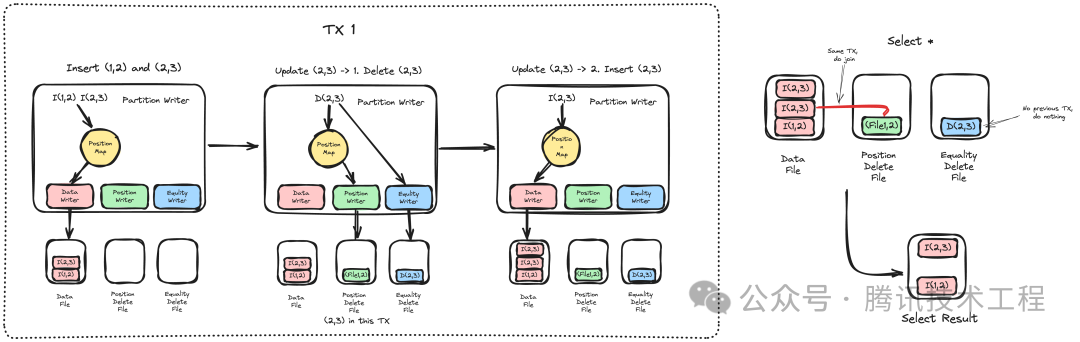
在 v2 版本中,Iceberg 支持通过 Merge on Read(MOR)的模式更新数据。与传统 Copy on Write 的模式不同,MOR 不再将所有数据加载到内存中后逐项对比更新再写入文件,而是将 Update 的操作拆分成 Delete 和 Insert 两步,但这在同一行多次更新时会导致错误语义。下图为导致错误语义的事例,通过反复插入删除同一行数据,最终查询时 Iceberg 将无法推断最终应该展示哪一次插入的数据。

因此 Iceberg 通过 Mixed position-delete and equality-delete 的方式保证更新和删除操作的正确性。简单来说,Iceberg 将不同的操作写入了 Data File, Equality Delete File, Position Delete File 三类文件中。Equality Delete File 负责记录同一行数据的删除记录,而 Position Delete File 则负责解决一个 Transaction 内同一行数据反复插入删除的语义问题。在查询时,对于 Position Delete File 只需要和当前 Transaction 对应的 Data File进行 Join 操作,Equality Delete File 和之前 Transaction 进行 Join 操作,最终便能保证流程的正确性。如下图所示,在 InLong Sort 实现里, 通过 Position Map 来维护当前 Transaction 中具体 Key 最新对应的文件名和位置,Insert 操作在写入 Data File 前先记录其写入的位置,Delete 操作通过查询 Position Map 当前 Transaction 是否记录了该数据的插入信息。如果是,将该信息写入 Position Delete File 和 Equality Delete File;反之则只写入 Equality Delete File。
Snapshot
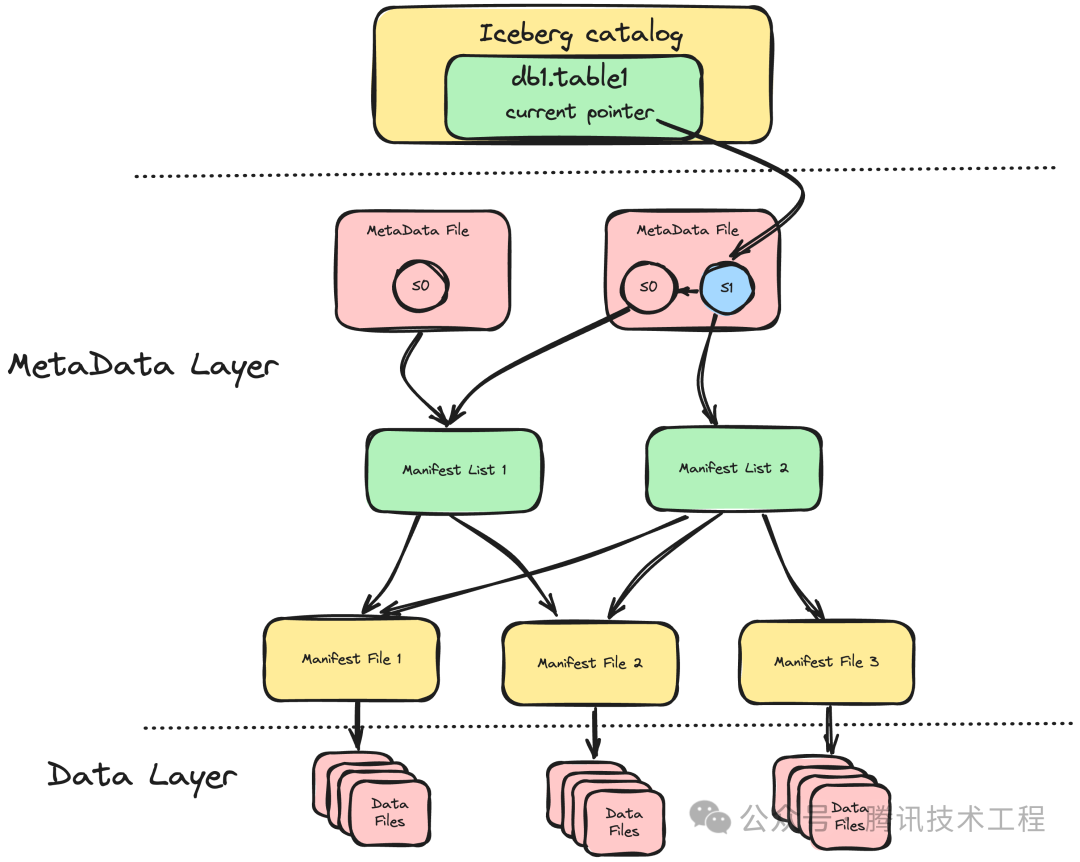
Iceberg 通过快照(Snapshot)实现了时间旅行(Time Travel)的能力,用户可以根据时间或者 Snapshot ID 定位到目标 Snapshot,通过对应的 Manifest 文件快速获取历史版本的数据文件,查看 Iceberg 表的历史情况。如下图所示,Iceberg 元数据文件中记录了一组 Snapshot 信息,并维护他们之间的父子关系,Iceberg 库表则通过指针指向当前使用的 Snapshot。每个 Snapshot 都维护各自的 Manifest List 用来记录当前 Snashot 和其父 Snapshot 所创建的所有 Manifest File,每个 Manifest File 则记录每个 Writer 写入的一组 Data File。
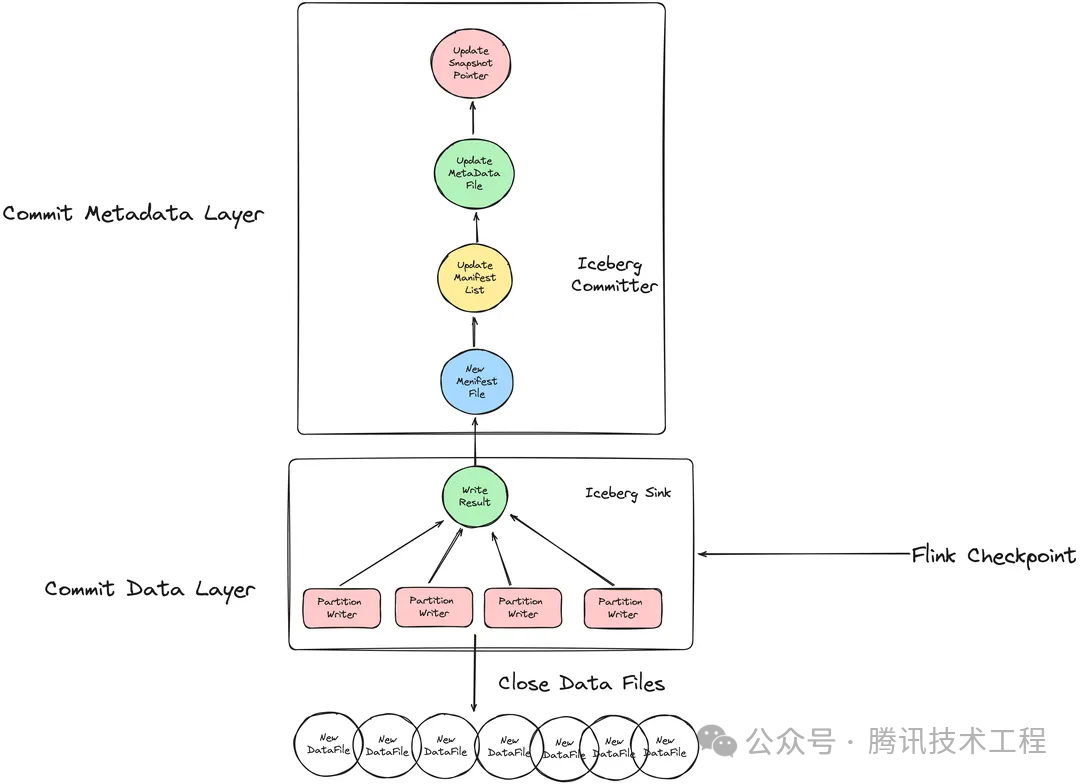
InLong Sort 通过在 Flink Checkpoint 时提交 Iceberg Snapshot 的方式来实现事物更新快照的能力,流程上与 Iceberg 表查询流程正好相反。如下图所示,当检测到 Flink Chekcpoint 通知时,Iceberg Sink 会关闭并统计当前所有的写入文件,将文件名,路径,数据条数等信息提交给 Iceberg Committer 算子。Committer 算子会进一步聚合当前 Checkpoint 周期的写入结果,并形成一个新的 Manifest File,接着更新生成新的 Manifest List,并产生一个全新的 Snapshot,将该 Snapshot 信息加入到 Metadata File中。最终 Iceberg Catalog 将当前的元数据指针指向最新的 Metadata Flie。
故障恢复与数据重做
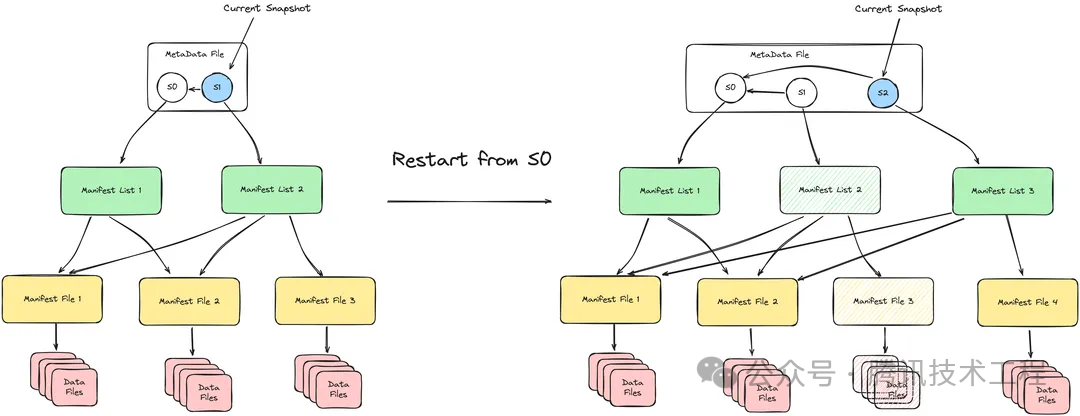
借助 Iceberg Snapshot 的特性,Sort 支持在故障恢复以及数据重做时的 Exactly Once 语义。具体的实现非常简单,InLong Sort 在每个 Checkpoint 后记录上一次完成的 Snapshot ID 号,在故障恢复(默认从上次成功的 Checkpoint 重启)以及用户指定时间重做数据(用户选择从指定 Checkpoint/Snapshot 重启)后,从上一次完成的 Snapshot 开始重置整个 Snapshot 的父子关系。以下图为例,当 InLong Sort 从 S0 对应的 Checkpoint 开始重启时,新的 Snapshot S2 将会从 S0 的基础上开始更新 Manifest 文件,S1 所对应的 Manifest 和 Data Files 将会被废弃。
Watermark 和 周期任务
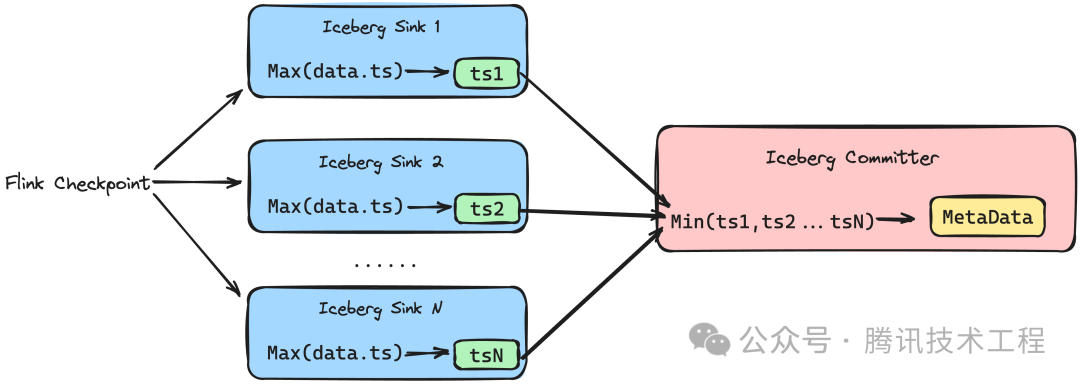
Sort on Flink 支持简单的 Watermark 推断能力,用户可以从 Metadata File 中获取当前 Snapshot 对应的 Watermark,也可以在 US 平台上配置 Watermark 检测任务,从而触发业务自定义的周期性任务。如下图所示,Iceberg Sink 中会记录整个 Snapshot 周期内获取的最大的数据时间 ts,在 Checkpoint 时在 Iceberg Committer 会汇总所有 Sink 的 Watermark,并选择其中的最小值,将其记录进 Metadata File 之中。
除了 Watermark 之外,InLong Sort 还提供了更为精细化和全场景覆盖的周期性分区检测方式,下图为 InLong Sort 业务可配置的 US 周期任务触发插件的架构。Iceberg Sink 在提交 Iceberg Snapshot 时,会将这个 Transaction 内完成了的分区信息提交到 Sort Partition Committer 算子,再触发 US 平台上 Inlong 数据对账任务。当该周期的数据对账符合条件后,再触发业务自定义的 US 周期任务。
分区断流检测
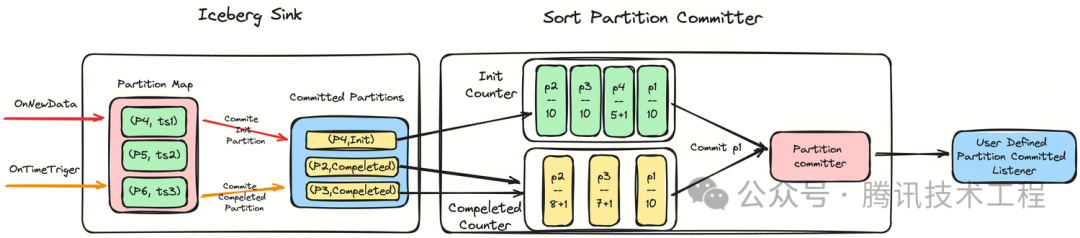
InLong Sort 是如何判断周期性分区是否已经完成的呢?如下图所示,在 Iceberg Sink 处,InLong Sort 维护一个分区以及最近更新时间的映射关系。对于新到来的分区,则生成一个 Partition Init 信息。对于超过分区时间范围,并连续5分钟没有新数据的分区,则生成一个 Partition Compeleted 信息。在 Sort Partition Committer 处收集每个 Subtask Sink 的分区创建和结束信息,并分别统计他们的个数。当 Compeleted 等于 Init 数时,则可以认为所有 Sink 都处理完毕这个分区的数据,随后便通知 US 上的 InLong 对账任务和业务自定义任务。
空分区检测
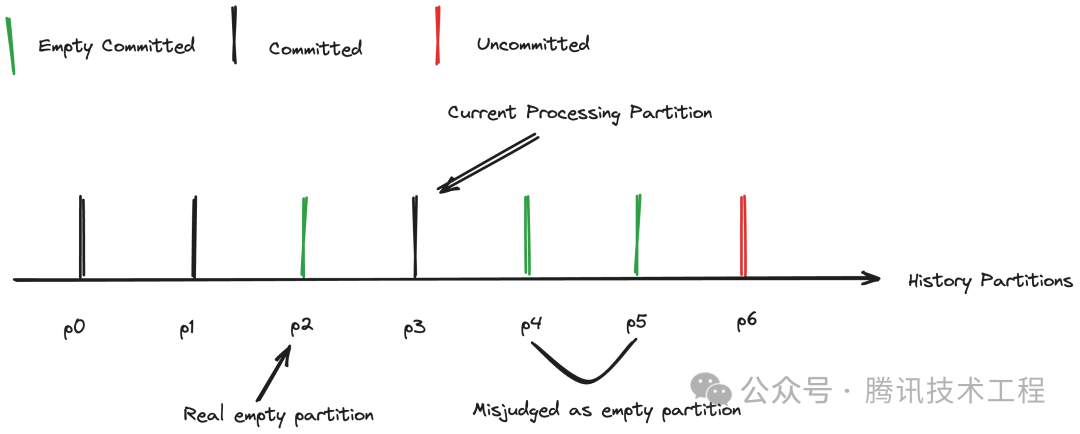
在某些场景下,业务数据并不是连续上报的,但业务也希望获得空分区的信息。因此,InLong Sort 增加了空分区检测的能力。一个简单的做法是如果当前分区数据超过一定时间还未提交,则默认该分区为空分区。但是这种检测机制存在一定的问题,如下图所示,如果数据处理存在大量延迟,当前处理的数据时间远落后于当前时间,那么就将导致数据未到达的分区被误判为空分区。
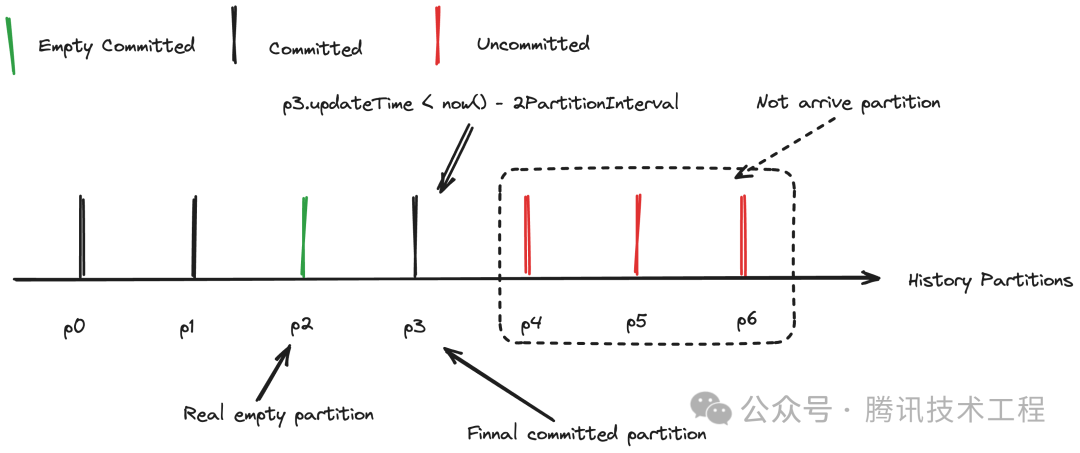
因此 Sort 通过判断最后提交的分区和当前时间的关系来推测数据是延迟到达还是确为空分区。例如下图所示,p3 为最后提交的分区,p3的提交时间和当前时间对比在2个分区周期之内,则认为 Sort 还在处理延迟到达的数据,p4, p5, p6 分区数据还未处理,不能进行超时提交。
案例分析
业务背景
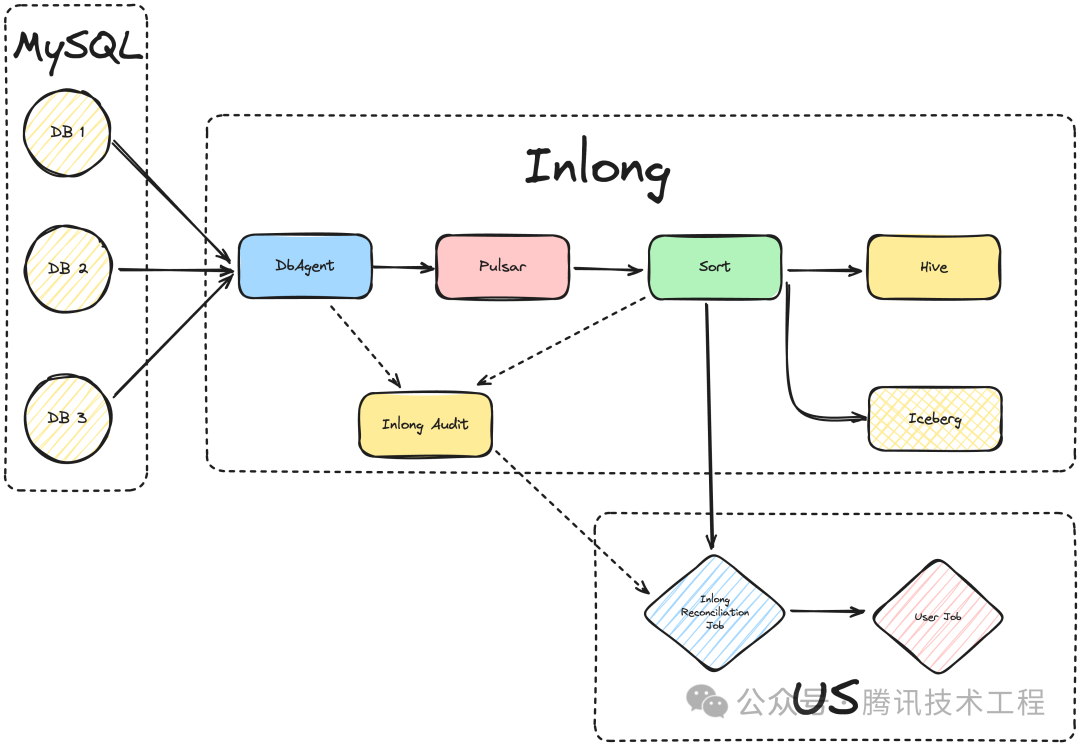
财付通使用 InLong 实现 MySQL Binlog 数据的增量采集和分拣入库 Thive,目前将该链路逐步迁移至入库 Iceberg。财付通对于数据一致性要求极高,可以容忍非常少量的数据重复,而不允许数据丢失。完整入库流程如下图所示,由于 DataProxy 没有副本的概念,为了降低 DataProxy 异常终止时数据丢失的风险,针对财付通业务我们取消了 DataProxy 的汇聚操作,而是直接将数据写入 Pulsar 之中。同时为了配合财付通存量业务从 Thive 平滑迁移到 Iceberg 上,部分流向目前处于“一份上报,两份写入”的状态中,方便业务试用对比 Iceberg 和 Thive 能力差异。
数据上报
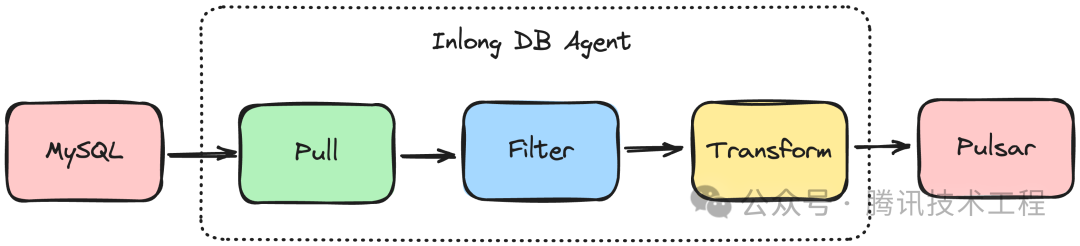
InLong DB Agent 为无状态节点,具备断点续采、单机多 DB 任务采集、DB 采集任务 HA 调度等能力,同时支持单机多部署、异构机型部署等能力。如下图所示,DB Agent 主要完成 Binlog 同步、Binlog 数据解析、Binlog 数据过滤、Binlog 数据转换及将符合过滤条件的数据信息发送到消息中间件的功能。
数据对账
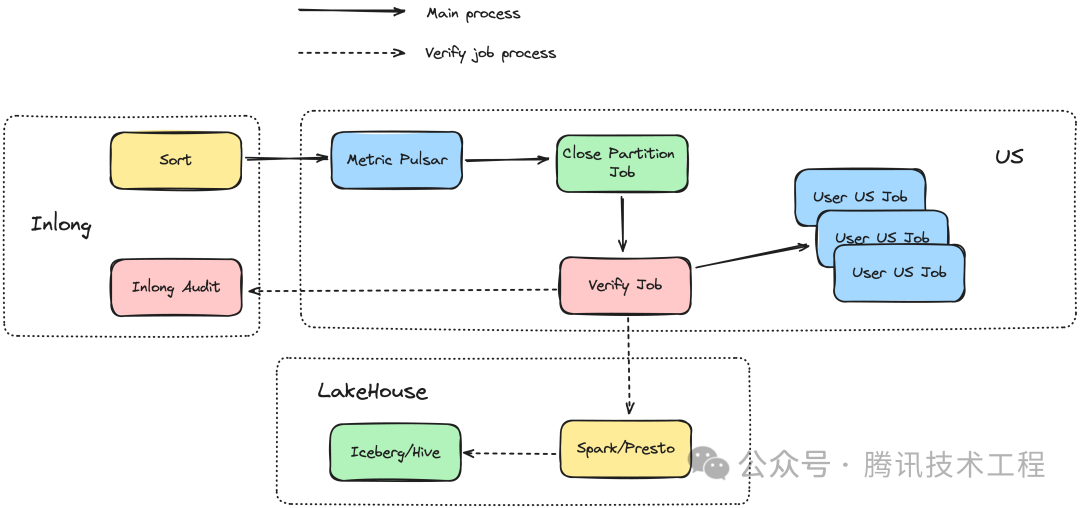
下图为数据对账的完整流程。在数据接入侧,DB Agent 会上报审计数据到 InLong Audit 模块中。InLong Audit 会根据数据流 ID,时间等维度将审计数据汇总到一起。在数据入库侧,当 Sort 检测到分区数据断流后,便会向 Metric Pulsar 中对应的 Topic 生产分区断流消息,Close Partition 任务通过订阅该 Topic 获得对应流向的分区断流状态,生成一个对应的任务实例。在 Close Partition 任务实例生成后,Verify 任务实例便会被调起,检测数据的完整性。Verify 任务会通过 Spark 或 Presto 对比 DB Agent 采集的条数以及实际入库后的数据条数是否一致,用来校验数据是否丢失,或者检查是否存在超长延迟数据(大于 Sort 分区断流检测的最大值)。如果 Verify Job 校验通过,则会进一步调起业务建立的 US 任务;如果失败,则反复重试并告警。
写在最后
当前 Apache InLong 入库 Iceberg 还存在优化空间,例如部分前端链路不支持数据有序写入,进而影响 Iceberg Upsert 的最终一致性;多分区场景下小文件过多,内存不足等问题,未来 InLong 将会针对这些问题进一步优化 Sort 性能以及支持更加丰富的使用场景。
InLong 入 Iceberg 的能力已在 WeData 产品化,欢迎感兴趣的业务试用。WeData 是一体化全链路大数据开发治理平台,基于天穹大数据基础能力的积累,结合内网各业务痛点,融合了包含数据集成、数据研发、数据探索、数据资产、小马BI等一系列数据开发、治理与运营能力。助力公司各业务领域更好的挖掘数据价值,赋能业务,实现数据开发治理的降本增效。