Mirage:基于GPU张量程序的多级超级优化器
Mirage:基于GPU张量程序的多级超级优化器

在深度学习领域,针对GPU的高性能执行深度神经网络(DNNs)对于现代机器学习应用至关重要。当前的DNN框架通常使用张量程序来指定DNN计算,张量程序是由节点和边构成的有向无环图,其中节点和边分别代表张量代数操作符(如矩阵乘法)和操作符之间共享的张量(即n维数组)。为了优化输入的张量程序,现有的框架(如PyTorch和TensorFlow)使用手动设计的规则将张量程序映射到专家编写的GPU内核。然而,这些方法通常需要大量的工程努力来设计和实施优化规则,并可能错过一些优化机会。
为了应对这些挑战,最近的工作引入了通过搜索全面的程序转换空间并基于目标GPU的性能来应用这些转换的自动化方法来优化张量程序。这些方法通常分为两类:基于算法和调度分离的思想,通过固定算法优化张量程序的调度(如Halide、TVM和Ansor),以及考虑代数转换的方法,这些方法利用不同算法之间的数学等价性(如TASO、Grappler、Tensat和PET)。然而,这两类方法都需要程序员手动指定一组内核(每个内核由张量函数定义),然后探索代数或调度转换的搜索空间。
现在,我们介绍Mirage,这是首个针对张量程序的多级超级优化器,由卡内基梅隆大学的研究团队开发。

Mirage能够自动发现和验证需要代数转换、调度转换和新自定义内核联合优化的复杂张量程序优化。
Mirage的核心思想之一是𝜇Graphs,这是一种层次化的图表示,它指定了GPU计算层次中多个级别的张量程序。通过统一处理内核、线程块和线程级别,𝜇Graphs能够捕获代数和调度转换。此外,优化𝜇Graph可以引入新的自定义内核,这超出了代数和调度转换的范围。
Mirage通过以下步骤工作:首先,它将输入张量程序分割成属于受限Lax片段的子程序。Lax片段包括多线性操作符(如矩阵乘法和卷积)、除法(用于归一化)以及有限的指数运算(用于激活函数)。将程序分割成Lax子程序可以减小优化搜索空间,同时保留大多数优化机会,并启用Mirage的概率等价验证器。
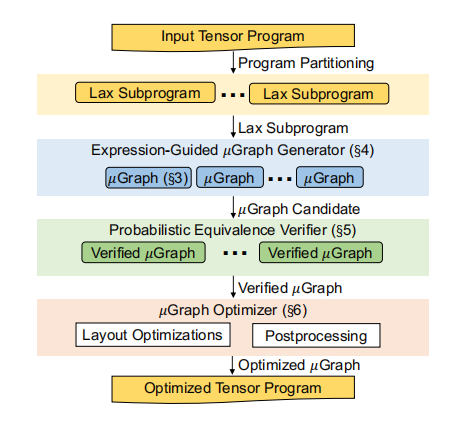
Mirage概览
对于每个Lax子程序,Mirage的表达式引导生成器使用穷举搜索来找到与其等价的可能𝜇Graphs。为了有效地导航这个显著更大和更复杂的搜索空间,Mirage引入了一种基于抽象表达式的剪枝技术。这种方法大大减少了Mirage需要考虑的𝜇Graphs的数量,同时提供了关于发现的𝜇Graphs的最优性的理论保证。
对于Mirage发现的每个𝜇Graph,验证其与输入程序的功能等价性引入了另一个挑战,因为程序的输入和输出张量可能包含多达数百万个元素。Mirage的一个关键思想是概率等价验证,它通过在有限域上进行随机测试来检查𝜇Graphs之间的等价性。虽然随机测试几乎不能为一般程序提供任何正确性保证,但Mirage依赖于一个新颖的理论结果来显示Lax片段的限制确保了对于Lax程序,在有限域上的随机测试提供了强大的正确性保证。
最后,对于每个经过验证的𝜇Graph,Mirage的𝜇Graph优化器通过考虑内核、线程块和线程级别所有中间张量的潜在数据布局来最大化其运行时性能。最终,Mirage基于每个单独Lax子程序发现的最佳𝜇Graph返回优化的张量程序。
在评估中,团队在12个常用的DNN基准测试中评估了Mirage,包括不同变种的注意力机制、低秩适应和多层感知器。即使在现有的系统(如当今大型语言模型中使用的组查询注意力)广泛使用和高度优化的DNN基准测试中,Mirage仍然通过利用现有系统中缺少的微妙自定义内核和优化,将性能提高了高达3.5倍。Mirage现已公开可用,可在GitHub上的Mirage项目中找到。
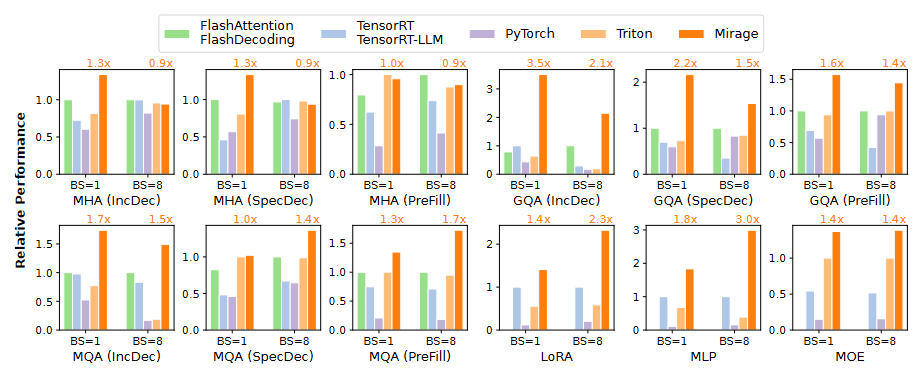
图中比较了Mirage和现有的张量程序优化器在12个深度神经网络(DNN)基准测试上的性能,这些基准测试使用了两种不同的批次大小。所有系统都使用半精度浮点数来处理所有DNN基准测试。PyTorch使用了高度优化的cuDNN和cuBLAS库来在GPU上执行DNN操作。TensorRT及其针对大型语言模型(LLM)的变体TensorRT-LLM包含了一组手动设计且高度优化的内核,用于处理常见的张量操作,如注意力机制。Triton是一个基于调度的优化器,用于生成高性能的张量程序,并已部署在现有的DNN系统中,其性能优于其他基于调度的优化器。团队没有将Mirage与现有的超级优化器(如TASO或PET)进行比较,因为我们使用的DNN输入不包含纯代数层面的优化机会。
简单来说,图中展示了Mirage与其他流行的DNN优化工具在处理不同DNN任务时的性能对比。所有工具都使用了半精度浮点数,但Mirage在多个基准测试中表现优异。团队主要关注的是DNN操作层面的优化,因此没有与那些专注于代数层面优化的工具进行比较。
Mirage的自动优化能力可能极大地简化将GPU内核移植到不同硬件平台(如AMD和英特尔的硬件)的过程,从而促进更大范围的深度学习模型(LLM)的采用,并在各种设备上实现性能提升。
论文可以访问:https://arxiv.org/pdf/2405.05751
代码:github.com/mirage-project/mirage