Trio-ViT | 专门针对高效 ViTs 的卷积 Transformer混合架构的加速器!
Trio-ViT | 专门针对高效 ViTs 的卷积 Transformer混合架构的加速器!


受到在自然语言处理(NLP)领域取得巨大成功的Transformers的启发,视觉Transformers(ViTs)迅速发展,并在各种计算机视觉任务中取得了显著性能。 然而,它们巨大的模型尺寸和密集的计算阻碍了ViTs在嵌入式设备上的部署,这需要有效的模型压缩方法,例如量化。 不幸的是,由于存在硬件不友好且对量化敏感的非线性操作,尤其是Softmax,完全量化ViTs中的所有操作并非易事,这会导致显著的准确度下降或不可忽视的硬件成本。 针对与标准ViTs相关的挑战,作者将注意力转向对高效ViTs的量化和加速,这些高效ViTs不仅消除了麻烦的Softmax,还集成了具有低计算复杂度的线性注意力,并相应地提出了Trio-ViT。具体来说,在算法层面,作者开发了一个定制的后训练量化引擎,充分考虑了Softmax-free高效ViTs的独特激活分布,旨在提高量化精度。 此外,在硬件层面,作者构建了一个专门针对高效ViTs的卷积-Transformer混合架构的加速器,从而提高了硬件效率。广泛的实验结果一致证明了作者Trio-ViT框架的有效性。特别是,与现有的ViT加速器相比,在可比精度下,作者可以实现高达
.2
和
.4.6
的FPS速度提升,以及
.5
和
.2
的DSP效率。
I Introduction
感谢自注意力机制强大的全局信息提取能力,Transformers在各种自然语言处理(NLP)任务中取得了巨大成功。这一成功催生了视觉Transformers(ViTs)[4, 5]的快速发展,它们在计算机视觉领域受到了越来越多的关注,并且与基于卷积的对应物相比显示出优越的性能。
然而,它们巨大的模型尺寸和密集的计算挑战了在嵌入式/移动设备上的部署,这些设备的内存和计算资源都是有限的。例如,ViT-Large[4]包含307M个参数,并在推理过程中产生190.7G FLOPs。因此,有效的模型压缩技术被高度期望以促进ViT在实际应用中的使用。
其中,模型量化是众多压缩方法中最有效且广泛采用的方法之一。它将浮点权重/激活转换为整数,从而在推理过程中减少内存消耗和计算成本。不幸的是,由于存在非线性操作,包括LayerNorm(LN)、GELU,特别是Softmax,这些操作不仅对硬件不友好,而且对量化敏感,因此ViTs难以被完全量化,导致要么显著降低准确性,要么显著增加硬件开销。为了解决这些挑战,已经投入了几项努力。
例如,FQ-ViT 识别了LN输入中极端的通道间变化以及注意力图中的过度非均匀分布,并分别为LN和Softmax量化提出了幂次因子(PTF)和对数整型Softmax(LIS)。此外,I-ViT 开发了创新的双元素算术方法来近似ViTs的非线性操作,从而实现仅整数的推理。尽管它们有效,但它们专门针对标准ViTs的量化,而忽略了高效ViTs内固有的量化和加速机会,其中通常用具有二次计算复杂度的标准Softmax-based注意力换取具有线性计算复杂度的更高效的_Softmax-free attentions_。因此,作者将重点转向探索高效ViTs的有效量化和加速,旨在完全释放它们的潜在算法优势,以在准确性和硬件效率上取得双赢,即
(i) Softmax-free属性以提高可实现的量化性能
(ii)注意力的线性复杂性特征以提高推理效率
除了算法层面,众多工作从硬件角度出发,构建了专用加速器来提升ViTs的硬件效率[15, 16, 17]。例如,Auto-ViT-Acc [16]采用了混合量化方案,如固定点和二进制幂,对ViTs进行量化,并开发了一个专用加速器,以充分利用FPGAs上可用的计算资源。
此外,ViTCoD [17]提出了剪枝和极化技术,将ViTs的注意力图转换为更密集和更稀疏的变体,然后开发了一个结合了密集和稀疏引擎的专用加速器,以同时执行上述两个工作负载。尽管上述加速器在提高硬件效率方面具有优势,但它们专门针对标准ViTs,并且在加速高效ViTs[12, 13, 14]方面存在不足,这些高效ViTs的特点通常包括(i)无需Softmax的线性注意力,(ii)卷积-Transformer混合架构。特别是,已经广泛验证了线性注意力的计算复杂度降低会使其局部特征提取能力退化,因此需要额外的补偿组件,如卷积[12, 13]。这导致了高效ViTs的混合架构,包括卷积和Transformer块,因此需要专用加速器来释放其潜在的好处。
为了掌握高效ViTs内在的量化和加速机会,作者做出了以下贡献:
- 作者提出了_Trio-ViT_,一个通过算法和硬件共同设计的后训练量化与加速框架,用于高效视觉 Transformer (ViTs)。据作者所知,这是首个致力于高效ViTs的量化和加速的工作。
- 在算法层面,作者对去除了Softmax的效率型ViTs的不同激活进行了全面分析,揭示了特定的量化挑战。接着,作者开发了一个定制的后训练量化引擎,该引擎融合了多种新颖策略,包括_channel-wise迁移、filter-wise移位_以及_log2量化_,以提升量化精度并应对相关挑战。
- 在硬件层面,作者提倡一个_hybrid设计_,整合多个计算核心以有效支持高效ViTs中卷积- Transformer 混合架构中的各种操作类型。
- 此外,作者提出了一种 pipeline 架构 ,以促进层间和层内融合,从而提高硬件利用率并减轻带宽需求。
广泛的实验和消融研究一致验证了作者的Trio-ViT框架的有效性。例如,与现有最先进的(SOTA)ViT加速器相比,作者在保持相似准确度的同时,可以提供高达
**7.2
**和
**14.6
**的FPS。此外,作者还可以实现高达
**5.9
**和
**2.0
**的DSP效率。
作者期望作者的工作能为去除了Softmax的高效ViTs的量化和加速开辟一个激动人心的视角。
本文的其余部分组织如下:
作者在第二节介绍相关工作,第三节介绍预备知识;然后第四和第五节分别说明了Trio-ViT的后训练量化和专用加速器;此外,第六节通过广泛的实验和消融研究一致展示了作者的Trio-ViT的有效性!最后,第七节对本文进行总结。
II Related Works
Model Quantization for Vision Transformers (ViTs)
模型量化是一种不修改模型结构而用整数表示浮点权重和激活的通用压缩解决方案。它可以大致分为两种方法:量化感知训练(QAT)和训练后量化(PTQ)。具体来说,QAT 涉及权重微调以促进量化,从而获得更高的准确度或更低的量化位数。相比之下,PTQ 消除了资源密集型的微调,简化了模型的部署,近年来受到了越来越多的关注。
例如, 采用了一种创新的排序损失,在量化过程中保持了自注意力机制的功能,成功地对ViTs中的线性操作(矩阵乘法)进行了量化。此外,FQ-ViT 进一步引入了二进制因子(PTF)和对数整数softmax(LIS)来量化在ViTs中硬件和量化不友好的非线性操作(即LayerNorm和Softmax),实现了完全量化。然而,这些工作是为标准的ViTs开发的,无法捕捉到高效ViTs 提供的量化机会,后者具有无需Softmax的线性复杂度注意力,以同时提高量化准确性和硬件效率。
Efficient ViTs
ViTs(视觉 Transformer )最近受到了越来越多的关注,并且在计算机视觉领域得到了快速发展。其中,ViT(视觉 Transformer ) 首次将纯Transformer应用于处理图像块序列,取得了显著性能。此外,DeiT(蒸馏视觉 Transformer )为ViT提供了更好的训练策略,显著降低了训练成本。然而,为了达到卓越的性能,ViTs在推理过程中仍然产生了高昂的计算成本和巨大的内存占用,这呼唤着高效的ViTs。
特别是,EfficientViT(高效视觉 Transformer ),作为当前最先进的方法,用一种新颖的轻量级多尺度注意力替换了复杂度为平方的普通自注意力,实现了全局感受野的同时提升了硬件效率。
另外,Flatten Transformer(扁平 Transformer )选择了一种创新的聚焦线性注意力,保持了低计算复杂性的同时保留了表达性。尽管在高效ViTs中的无需Softmax的线性注意力具有固有的算法优势,
包括(i)无需Softmax的性质便于量化,(ii)线性复杂度提升硬件效率,但它们专门的量化和加速方法仍然探索不足。
Transformer Accelerators
近期,各种研究工作开发了专用的加速器来推动Transformers在实际应用中的部署。特别是,Sanger 在推理过程中动态剪枝注意力图,并构建了一个可重新配置的加速器,采用得分静止数据流来加速这种稀疏模式。
对于ViT加速器,VAQF 被设计用来加速具有二进制权重和混合精度激活的ViTs。Auto-ViT-Acc 结合了FPGA上可用的异构计算资源(即DSPs和LUTs)来分别为ViTs加速混合量化方案(即固定点和二进制)。
ViToCop 将ViTs的注意力图剪枝并极化为更密集和更稀疏的形式,并构建了一个加速器在单独的计算引擎上执行它们。尽管这些方法可以增强标准 ViTs 的硬件效率,但由于高效 ViTs 具有独特的模型架构,如无Softmax的线性注意力和卷积-Transformer混合结构,这些方法不能直接适用于高效 ViTs,这需要专用的加速器。
III Preliminaries
Structure of Standard VITs
如图1所示,输入图像最初被划分为固定大小的块,并通过 Token 和位置嵌入进一步增强,作为ViTs Transformer 块的输入 Token 。
每个 Transformer 块包括两个关键组件:
多头自注意力模块(MHSA)和多层感知机(MLP),两者之前都有层归一化(LN),并通过残差连接相连接。特别是,MHSA是 Transformer 中用于捕获全局信息的核心元素。
它根据方程(1)将输入 Token
投影到 Query
、键
和值
,其中
、
和
是第
个头的相应权重。随后,如方程(2)所示,
乘以转置的
(
),然后进行Softmax归一化(其中
表示每个头的特征维度)以生成注意力图。这个注意力图进一步乘以
,以获得第
个头的注意力输出
。最后,所有
个头的注意力输出被连接起来,并使用权重
进行投影,以生成最终的MHSA输出,即方程(3)中的
。至于_MLP_,它包括由GELU激活函数分隔的两个线性层。
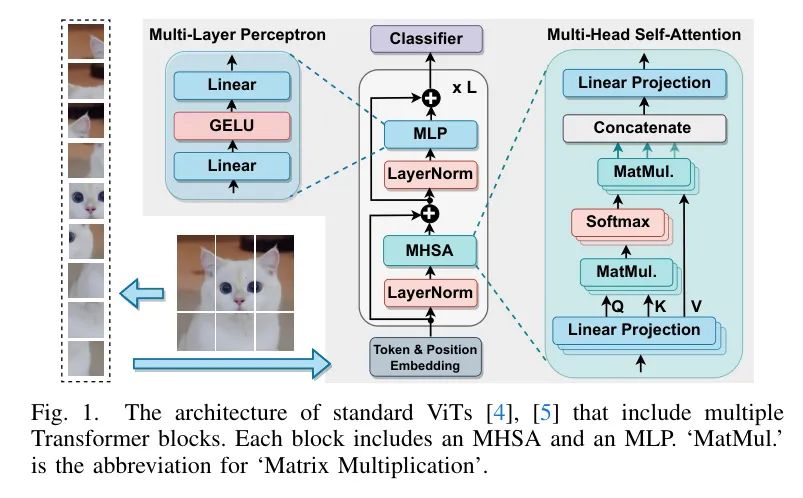
局限性。 标准ViTs有两个局限性:(i) 自注意力关于 Token 数量的二次计算复杂度,以及(ii) 对硬件和量化不友好的非线性操作,即LN、GELU,尤其是Softmax[9, 10],阻碍了ViTs可实现的硬件效率和量化准确性。
Structure of EfficientViT
为了解决上述限制,高效的ViTs 已成为一种有前景的解决方案。在这里,作者以EfficientViT [12]为例,这是目前最先进的ViT,进行说明。如图2所示,它不仅**(i)融入了无需Softmax的线性注意力,而且(ii)**用硬件亲和且适合量化的BatchNorm(BN)和Hardswish(Hswish)[29]分别替换了普通的LN和GELU,显著简化了量化和加速。
具体来说,EfficientViT 主要由两种类型的块组成:MBConvs 和EfficientViT模块。每个_MBConv_包括两个点卷积(PWConvs),由一个深度卷积(DWConv)分隔,每个卷积后面跟着一个BN和一个Hswish(最后一层除外)。特别是,BN可以用
卷积实现,并且可以无缝地折叠到前面的卷积中,简化了量化和加速 。此外,每个_EfficientViT模块_包括一个用于提取上下文信息的轻量级多尺度注意力(MSA)和一个用于提取局部信息的_MBConv_。在MSA中,输入被投影以生成
,然后通过轻量级的小核卷积处理以生成多尺度标记。在应用基于ReLU的全局注意力之后,将结果 ConCat 并投影以产生最终的输出。值得注意的是,基于ReLU的全局注意力本质上用
替换了基于Softmax的注意力中的相似性函数
,从而(i)去除了Softmax,并(ii)利用了矩阵乘法的结合性质,将计算复杂度从二次降低到线性。这重新制定了方程(2)如下:
IV Trio-ViT's Post-Training Quantization
如图所示,由于SOTA高效ViT(称为EfficientViT [12])固有的优势,即:硬件和量化友好的ReLU基全局注意力(具有线性复杂度)替代了基于vanilla Softmax的自注意力(具有二次复杂度),LN(层归一化)和GELU(高斯误差线性单元)分别被BN(批量归一化)和Hardswish取代,因此作者在EfficientViT之上探索了量化和加速,以同时获得量化准确性和硬件效率。
作者默认采用最广泛应用的硬件友好量化设置[6],即对激活
和权重
分别采用对称逐层和逐滤波器统一量化。形式上.
特别是,作者遵循SOTA PTQ方法BRECQ [6],该方法使用对角Fisher信息矩阵(FIM)依次重构基本块(例如,EfficientViT中的MBConvs和Lightweight MSAs),从而在保持泛化的同时增强跨层依赖。给定FIM作为目标函数,权重和激活的量化分别通过Adaround [31]和Learned Step size Quantization (LSQ) [32]进行优化。
Observations
作者采用了遵循[6]的块状重建方法来进行量化优化,同时MBConvs和轻量级MSAs是EfficientViT的两个主要块。作者从保留方程(4)中MSAs内的矩阵乘法(MatMuls)在全精度开始,以评估量化对MBConvs的影响。
Iii-A1 Observations on Quantization of MBConvs
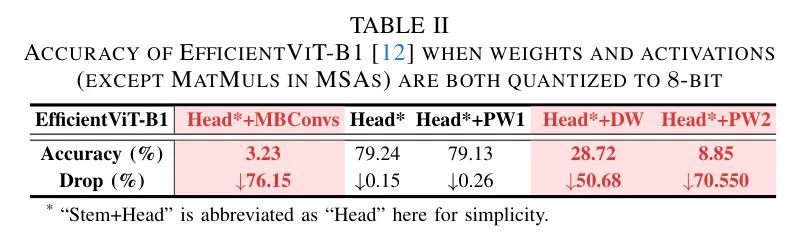
尽管已经广泛认识到激活值对量化的敏感性高于权重,但在EfficientViT的背景下,这种敏感性被加剧了。如表格I所示,仅将EfficientViT-B1 的权重量化为8位(W8)与全精度版本相比,具有可比较的准确度(
),而将权重和激活值(除了MSAs中的MatMuls)都量化到相同的位数(W8A8)会导致灾难性的准确度下降
76.15
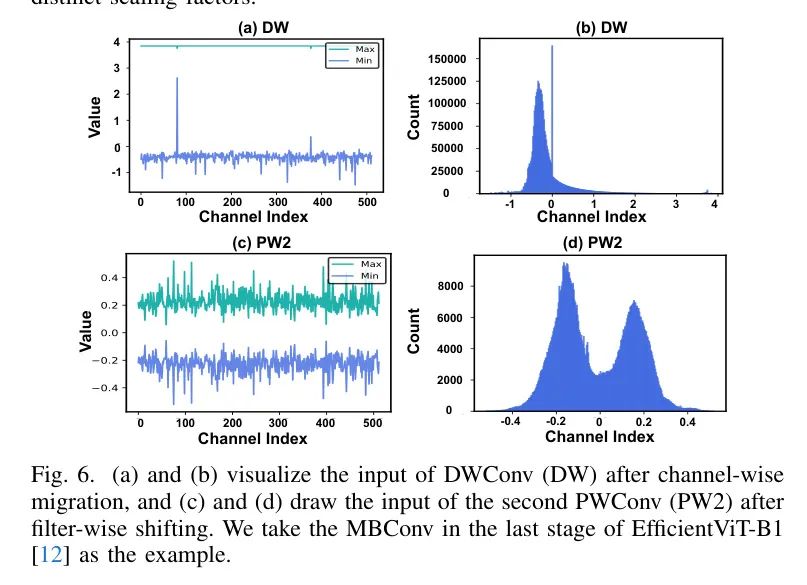
。这强调了EfficientViT中激活值的极端量化敏感性,尤其是那些在MBConvs中的,正如表格II中第1列和第2列之间的准确度比较所示。如第三节B部分之前所介绍,每个MBConv包含两个由DWConv分隔的PWConv,然后作者进行消融研究,单独量化所有MBConvs中这三个层的输入激活值。如表2所示,DWConvs(DW)和第二个PWConvs(PW2)的输入激活值对量化最为敏感,应该是准确度下降的主要责任所在。为了理解这个问题,作者在图3中可视化它们的输入激活值,并观察到了两个挑战。
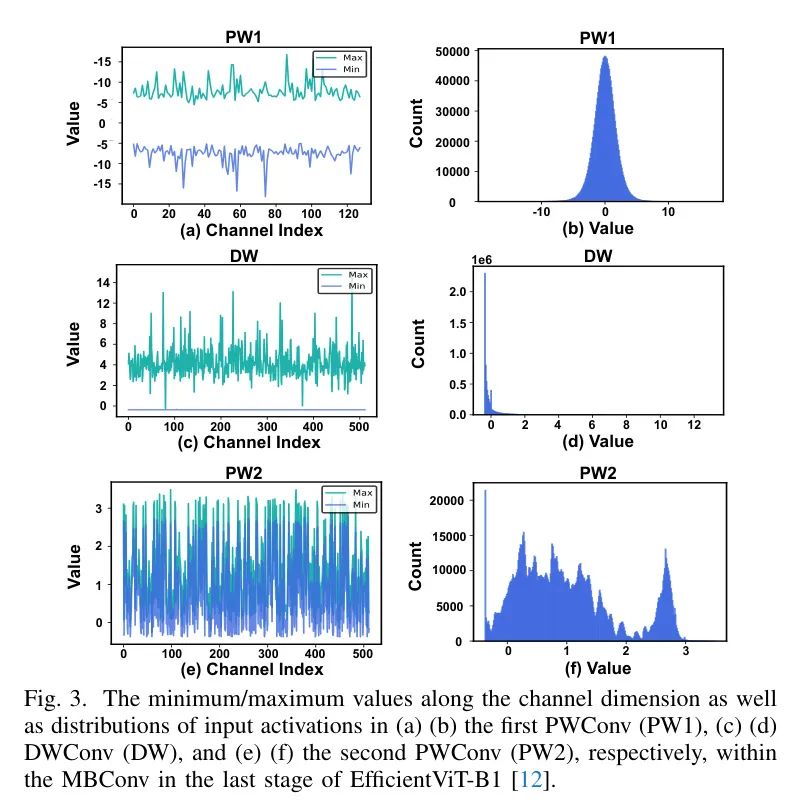
挑战一:DW输入中的通道间变化。特别是,如图3(c)所示,DW的输入激活值表现出显著的通道间变化,导致大多数值只用少数几个量化箱表示(见图3(d))。例如,在EfficientViT-B1最后一个阶段的MBConv中的DW输入激活值中,大约有
的值只占用总量化箱的
。相比之下,PW1输入的这一比例要高得多,为
,是
。
挑战二:PW2输入中的通道间不对称性。如图3(e)所示,与图3(a)中PW1的输入激活值相比,PW2的输入激活值表现出极端的通道间不对称性,导致值范围更广,从而降低了量化分辨率。例如,在EfficientViT-B1最后一个阶段的MBConv中的PW2输入中,第一个通道的区间为(
,
),而所有通道的区间为(
,
),这大了
。
Iii-A2 Observations on Quantization of Lightweight MSAs
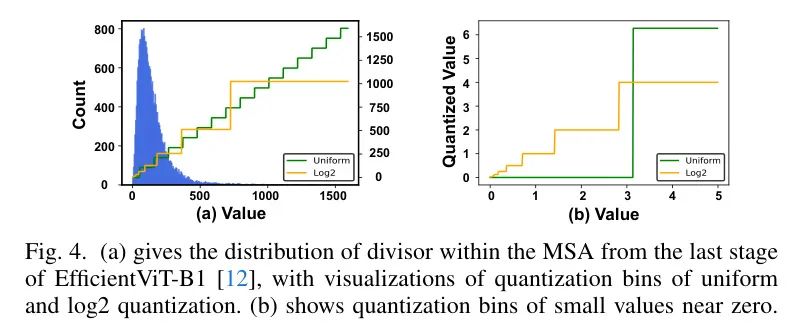
当将轻量级MSAs中的方程(4)的矩阵乘法量化为8位时,作者遇到了显著更差的结果,表现为“不是一个数字”(NaN)问题。
作者发现这个问题主要源于除数/分母的量化。如图4 (a)和(b)所示,采用均匀量化时,除数内部值的广泛范围导致小值的量化分辨率降低。然而,与较大值相比,除数内部的小值显示出更大的敏感性。例如,在量化过程中将750的除数四舍五入到1500,导致绝对差为750,但它仅将最终的除法结果_翻倍_。相比之下,将0.3的除数近似为3,造成仅仅2.7的绝对差,但将最终结果增加了
倍。特别是,将0.01的除数更改为1,产生可忽略的0.99的绝对差,但它导致最终结果
增大。这些例子清楚地突显了均匀量化对于除数(尤其是那些具有广泛值的除数)的固有不兼容性。
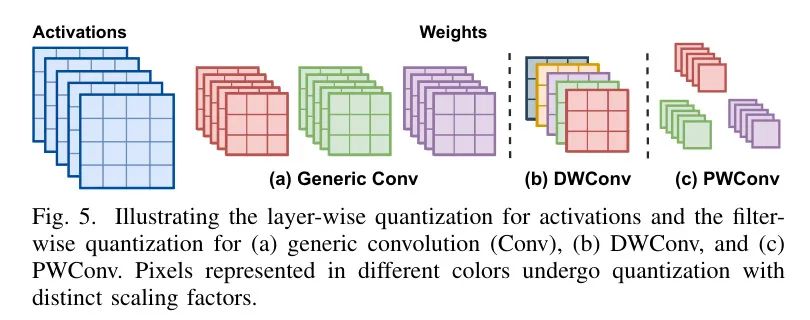
Channel-Wise Migration for DW's Inputs
正如在第IV-A1节挑战#2中介绍的,DW的输入存在极大的通道间变化,使得传统的逐层量化方法不适用。幸运的是,由于DWConvs独特的算法特性,它们独立处理每个输入通道,从而消除了通道间的求和,作者可以直接采用_通道量化_为每个输入通道分配单独的缩放因子。这种方法有效地解决了上述挑战,同时没有牺牲硬件效率。然而,尽管它在提高量化精度方面具有潜在优势,但它显著增加了缩放因子的数量,这对于通过LSQ [32]进行优化构成了另一个挑战,LSQ是在_逐层_量化激活中广泛采用的优化缩放因子的方法。
为了克服这一限制,作者 Proposal 在DW的输入上采用_基于逐层量化的通道迁移_。
具体来说,如图5所示,DWConvs中的权重具有与输入相同的通道数,每个权重通道作为一个独立的过滤器,专门处理相应的输入通道。这种安排使作者能为每个权重通道分配不同的缩放因子。因此,滤波器量化本质上是DW权重的通道量化。因此,激活
的通道间变化可以通过使用通道迁移因子
的数学等价变换无缝地转移到权重
上:
其中
,
和
分别是第
通道的输出、输入、权重和迁移因子。
表示量化函数,
和
分别是
和
的逐层和通道缩放因子。这种方法极大地促进了激活量化,而没有阻碍权重量化。注意,权重可以在部署之前进行预变换,以消除芯片上的计算。至于在推理过程中依赖于输入图像的激活,因此无法预处理,作者可以将
与
融合,提前获得一个融合缩放因子
,从而避免即时变换:
此外,
的计算可以表示为:
其中
是跨N个通道最大值的平均值。通过比较Figs. 3 (c)/(d)和Figs. 6 (a)/(b),可以明显看出,这种方法可以实现两个基本目标。_首先_,它压缩了异常值,有效地减少了激活值的范围。_其次_,它放大了较小的值,使它们更容易量化。
Filter-Wise Shifting for PW2's Inputs
为了消除PW2输入中的通道间不对称性,受到的启发,作者提出了在量化之前对PW2的输入进行逐滤波器移位的预处理方法。 如公式(9)所示,它将每个输入通道减去其通道均值
,从而得到以零为中心的校准输入
(见图6(c)),并显著减小值范围(比较图3(f)和图6(d))。为了适应上述对激活的逐滤波器移位,并保持与原始PW相同的功能,需要将第
个输出通道的原始偏置
更新为
,遵循公式(10),其中
表示输入通道数。这可以预先计算以消除芯片上的处理。
Log2 Quantization for Divisors in MSAs
如图4(a)和(b)所示,log2量化将为较小的值分配更多的箱,反之亦然。这一固有特性与MSAs中除数的算法属性相一致,如第IV-A2节所述,小值表现出更高的量化敏感性。因此,为了提高MSAs中除数小值的量化分辨率,作者建议采用以下log2量化:
[
\tag{11} ]
其中
是log2量化的除数,
是由方程(4)中的整数量乘
和
生成的整数除数,以及它们的缩放因子
和
。注意,
可以预先计算,而
可以在整数域中有效地实现,如文献[9]所述。具体来说,作者首先采用领先一位检测器(LOD)来找到
第一个非零位的索引
,然后加上
与
位的值来获得结果。例如,如果
是
,那么第一个非零位的索引
是
,而第
位的值是
,因此log2量化的
(
)是
。
通过采用除数的log2量化,作者可以进一步用硬件高效的位运算移位来替换方程(4)中硬件不友好的除法,从而在提高量化性能的同时进一步提升硬件效率。
V Trio-ViT's Accelerator
Design Considerations
为了充分利用作者的算法优势,开发一个专用的加速器用于量化EfficientViT [12]是非常必要的。然而,这带来了几个挑战, 因为(i)EfficientViT内部存在多种操作类型, 以及(ii)其轻量级注意力与标准ViTs [4, 5]中的普通自注意力计算模式不同。
V-A1 Design Challenge # 1: Various Operation Types
如图2和第III-A节介绍,EfficientViT的卷积-Transformer混合骨架主要有四种操作类型:通用卷积(输出像素由沿输入通道的滑动窗口内的部分和累加产生)、PWConvs(本质上是有
核的通用卷积)、DWConvs(分别处理每个输入通道,因此只需要累加滑动窗口内的部分和)以及矩阵乘法(MatMuls)。例如,在输入分辨率为
的EfficientViT-B1中,它们分别占总操作数的
、
、
和
。
设计选择 1:乘法器-加法器-树结构。鉴于PWConvs是主要的操作类型,一个自然的想法是构建作者专用的加速器,采用乘法器-加法器-树(MAT)结构,这是一种有效支持PWConvs通道并行性的典型设计[34, 35]。具体来说,如图7(a)所示,MAT引擎中的每个处理元素(PE)通道负责沿着输入通道维度进行乘法(通过乘法器)、求和(通过加法树)以及累加(通过累加器),以生成每个输出像素(对于PWConvs)或部分和(对于通用卷积,称作psum)。
因此,MAT引擎中 PE通道内的并行性 沿着 输入通道维度 以便于 psum重用 。此外,输入被广播到不同的PE通道,并与不同的权重滤波器相乘,以从不同的输出通道产生输出/psum像素,从而增强 PE通道间的并行性 沿着 输出通道维度 以增强 _输入重用_。
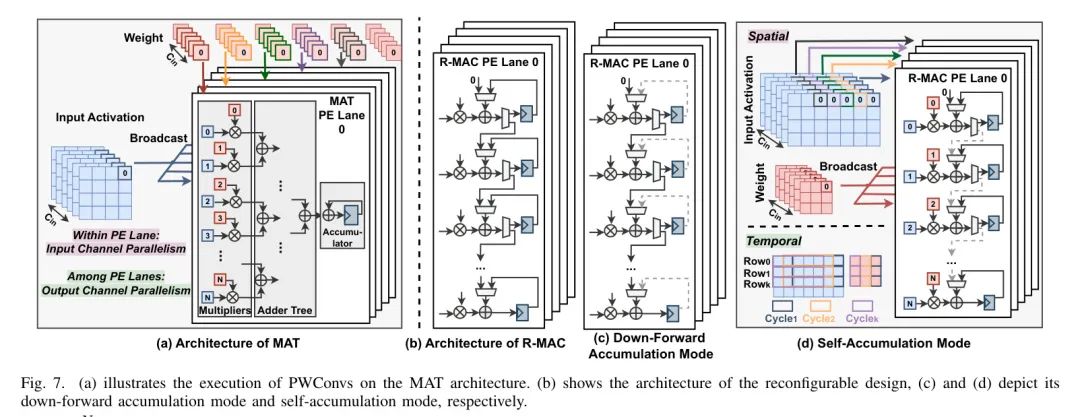
局限性。尽管MAT结构可以高效处理PWConvs,同时容易支持通用卷积和MatMuls(可以将它们视为具有大批量尺寸的PWConvs),但在处理DWConvs时其灵活性有限。
首先 ,对于DWConvs,只有来自同一滑动窗口产生的psum可以求和和累加,因此MAT中每个PE通道可实现的并行性受到DWConvs核尺寸的限制。 其次 ,EfficientViT中的DWConvs具有各种核尺寸(
和
)和步幅(
和
),导致进行卷积时相邻滑动窗口之间具有不同尺寸的滑动窗口和不同的重叠模式。
这需要在PE通道内支持连续输出像素的乘法和求和功能,并额外增加线路缓冲区和大量的内存管理开销[34]。
设计选择 2:可重构架构。 为了解决上述限制,作者可以考虑图7(b)中所示的可重构架构,该架构包含了多个可重构的乘积累加单元(R-MACs)。 (i) 如图7(c)所示,在执行通用卷积、PWConvs和MatMuls时,此架构可以配置为在向下前向累加模式下运行,以实现与MAT架构相同的功能。这意味着每个PE通道支持输入通道并行以实现psum重用,而不同的PE通道则倾向于输出通道并行以利用输入重用的机会。 (ii) 如图7(d)所示,在执行DWConvs时,
可以被配置为在自累加模式下运行,因此每个滑动窗口内的部分和可以在每个R-MAC中_时间上_积累,这使得这种设计固有地支持各种核大小的DWConvs。特别是,每个PE通道内的R-MAC可以_空间上_计算来自不同输出通道的多个输出像素以提高吞吐量,因此这里的并行性是沿着 输出通道(见图7(d)右)。
此外,权重可以广播到所有PE通道,并与来自不同滑动窗口的输入像素相乘,以生成同一输出通道的连续输出像素(见图7(d)左上)。通过这样做,作者只需要几个辅助寄存器就可以重用相邻滑动窗口之间的重叠,并且轻松支持具有不同步长的DWConvs。
例如,在图7(d)左下,作者以在
个PE通道中同一行上排列的
个R-MAC上执行的
DWConv,步长为
的计算为例。最初,一系列输入像素
被传输到输入移位寄存器中,然后在周期内向前移动。在每次周期中,移位寄存器中的前
个像素独立地与广播权重
相乘,为
个连续输出像素生成第
个psum。经过
个周期后,计算进展到输入特征图的下一行和相应的滤波器,保持相同的计算模式。这个过程重复,直到处理完所有
行,产生
个输出像素。至于步长为
的DWConvs的计算,相邻滑动窗口之间的重叠是间隔的,而不是连续的。
因此,每一行中奇数列索引的输入像素最初被传输到移位寄存器进行处理,然后是偶数列索引的像素。权重也需要按照相同的“先奇数后偶数”规则进行广播,以适应这种修改后的计算方案。因此,此架构中 PE通道之间的并行性是沿着_输出特征图_以增强_权重重用_。
局限性。 尽管它在支持EfficientViT中的所有类型操作方面具有灵活性,但存在可重构的开销。 _首先_,计算资源和缓冲区的开销:每个R-MAC需要一个高比特加法和psum寄存器来支持自累加。 _其次_,控制逻辑的开销:需要额外的多路复用器来同时支持两种累加模式,即自累加和向下前向累加。
作者提出的设计:混合架构。鉴于以下事实:(i) PWConvs在EfficientViT [12]中占主导地位,而MAT架构可以有效地支持它们,以及(ii) EfficientViT融合了各种操作类型,特别是具有不同 Kernel 大小和步长的DWConvs,而R-MAC设计可以灵活地支持它们,作者提出了一个混合架构,用于作者的专用加速器,以结合两者的优点。
具体来说,它包括一个_MAT引擎_,用于高效处理通用卷积、PWConvs和矩阵乘法,以及一个_R-MAC引擎_,用于有效支持上述三种操作类型和DWConvs,从而在保持硬件效率的同时提高灵活性。
提供的机会:层间流水线。除了作者提出的混合架构的效率和灵活性之外,它还提供了层间流水线的机会,以节省数据访问成本。具体来说,在作者的混合加速器中,DWConvs只在R-MAC引擎上执行,并且在EfficientViT的MBConvs中的两个PWConvs之间。
因此,当R-MAC引擎处理DWConvs时,产生的输出可以立即传输到空闲的MAT引擎,并作为输入参与到后续PWConvs的计算中。这种整合使得DWConvs及其后续的PWConvs的计算可以融合,从而提高了硬件利用率并减少了从片外访问数据的成本。
Distinct Computational Pattern of Attention
如公式(4)所示,在 Query
和键
经过ReLU之后,还需要五个步骤来生成最终的注意力图A:(i)在
和值
之间进行MatMuls;(ii)对
进行逐 Token 求和;接着(iii)用
和步骤i的输出进行MatMuls;(iv)用
和步骤ii的输出进行矩阵-向量乘法;最后(v)在步骤iii(被除数)和步骤iv(除数)的输出之间进行除法。由于作者在第IV-D节引入的对除数的log2量化,这些昂贵的除法可以用硬件高效的位运算移位来代替。因此,很明显,在EfficientViT中的轻量级注意力计算中,除了乘法,还涉及到逐元素求和和位运算移位。这些无需乘法的逐元素操作本质上与作者的基于乘法的PE阵列不兼容。此外,它们也表现出较低的计算强度,导致带宽要求增加或潜在的延迟[36]。
作者提出的解决方案:低成本的辅助处理器。除了可以有效地处理上述步骤i、iii和iv中的MatMuls的MAT引擎和R-MAC引擎之外,作者还将几个低成本的辅助处理器集成到混合架构中,以促进轻量级注意力中涉及的无乘法计算。特别是,作者加入了一个_加法树_来支持步骤ii中的行求和,以及一个_移位器阵列_来处理步骤v中的位运算移位。这种架构调整提供了在注意力内部进行计算融合的机会(即层内流水线,将在第V-C节中解释),从而提高数据复用并减轻带宽要求。
提供的机会:层内流水线。考虑到作者的混合设计中MAT引擎、R-MAC引擎和低成本的辅助处理器,上述涉及各种操作类型的注意力计算步骤可以同时由不同的计算单元处理,从而提供了融合的机会。例如,(i)当步骤i中的
在MAT/R-MAT引擎上执行时,
可以广播到辅助加法树以执行步骤ii中的行求和。此外,(ii)当步骤iii和iv被处理时,它们的输出可以立即发送到移位器阵列进行逐元素除法。
Micro Architecture
如图8所示,作者的专用加速器由
个计算核心和几个全局缓冲区(缓冲区B/C和输出缓冲区)组成。每个计算核心包括几个内部缓冲区(缓冲区A和辅助/除数缓冲区)和多个计算单元(R-MAC引擎、MAT引擎、辅助处理器以及重新/以log2为底的量化模块)。特别是,对于每个计算核心中的计算单元,_R-MAC引擎_包括
个PE通道,每个通道包含
,并且可以重新配置为在自累加或下前向累加模式下运行。
这种灵活性使得有效地处理EfficientViT中的所有基于乘法的操作成为可能,包括通用卷积、DWConvs、PWConvs和MatMuls,如第V-A1节的设计选择#2中所述。_MAT引擎_由
个PE通道组成,每个通道包括
个乘法器,旨在高效处理EfficientViT中的多个基于乘法的操作,不包括DWConvs,如第V-A1节的设计选择#1中解释的那样。
此外,_log2量化模块_用于根据第IV-D节第一段末尾步骤对等式(4)中的除数进行量化,从而提高量化精度并使昂贵的除法转换为硬件高效的位运算移位,如第IV-D节所述。作者的加速器还配备了几个低成本_辅助处理器_,如加法树和移位器阵列,以适应MSAs中乘法无关操作(例如,行求和和位运算移位)的计算,
如第V-A2节作者的解决方案中所述。另外,还需要一个_重新量化模块_按照等式(12)重新量化输出,其中
和
分别是量化输出
、输入和权重,
和
是它们相应的缩放因子,_b/c_都是正整数。通过这样做,浮点重新缩放因子被转换为二进制数(DN),并且重新量化过程可以通过仅使用整数乘法和位运算移位实现[7, 8, 11],从而促进芯片上的层内和层间流水线。
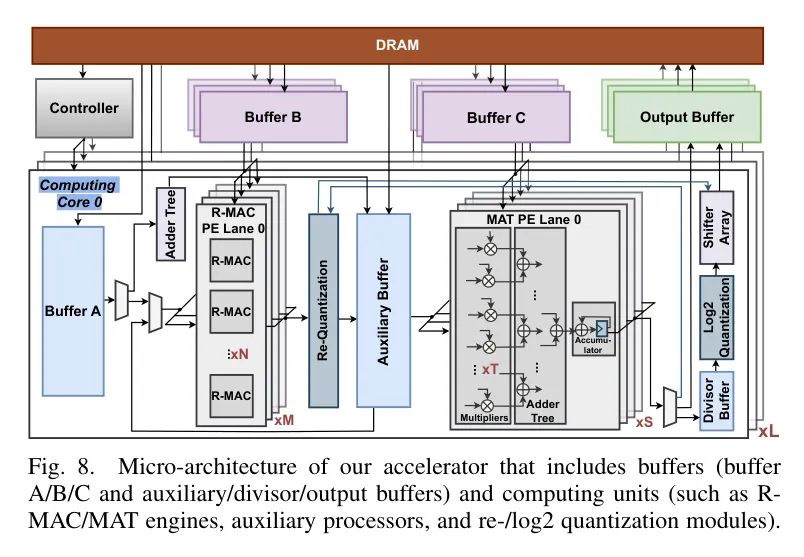
至于内部缓冲区,缓冲区A将数据广播到R-MAC引擎中的所有PE通道,也可以将数据发送到辅助加法树。辅助缓冲区缓存R-MAC引擎的输出,并将数据广播到MAT引擎中的所有PE通道,作为两个引擎之间的桥梁。除数缓冲区存储等式(4)中的除数,然后将其传输到log2量化模块,为随后的位运算移位做准备。
关于全局缓冲区,缓冲区B/C将数据发送到所有计算核心,数据在这些核心中被分配并传输到R-MAC/MAT引擎中的不同PE通道。输出缓冲区存储来自所有计算核心的数据,并将其指导到片外DRAM。
Inter- and Intra-Layer Pipelines
如上所述,作者的专用加速器融合了基于乘法的引擎(R-MAC和MAT引擎,DWConvs限制在前者)和无需乘法的引擎(辅助处理器,旨在加快MSAs中的计算)。这种架构本质上提供了流水线处理的机会,各种操作可以同时在不同的计算单元上执行,从而提高硬件利用率和吞吐量。至于层间流水线,如图9(a)和(b)所示,当
引擎处理DWConv时,首先将得到的输出结果减去在校准数据上获得的通道均值,以实现第IV-C节中引入的滤波器级移位,以便促进激活量化。之后,它们通过重新量化模块进行重新量化,然后存储在辅助缓冲区中。然后,它们迅速被引导到空闲的MAT引擎,作为后续PWConv计算的输入。鉴于DWConvs的计算量比PWConvs少,一旦完成当前DWConv的处理,R-MAC引擎可以重新分配,与MAT引擎一起参与PWConv的并发计算。
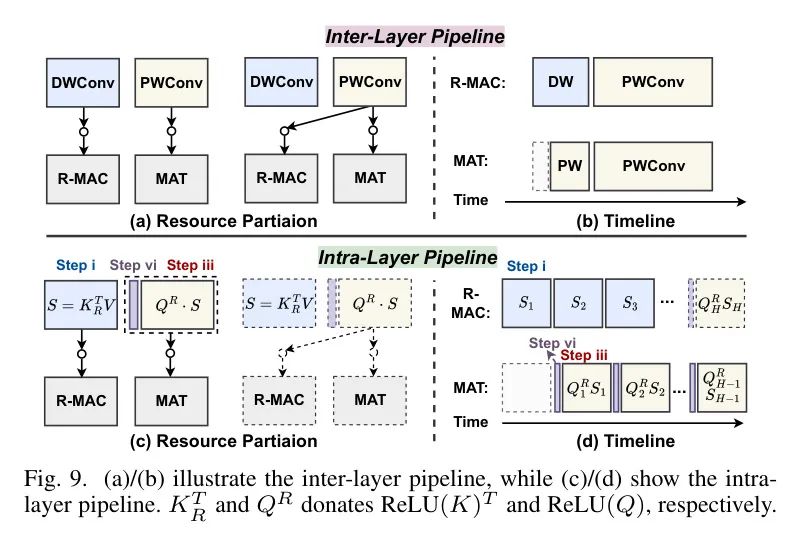
图9:(a)(b)展示了层间流水线,而(c)/(d)展示了层内流水线。
和
分别表示
和
。
关于层内流水线,(i)当R-MAC引擎处理第
个头的
时,
被广播到辅助加法树,通过行求和生成向量
。这意味着第V-A2节的步骤i/ii可以在不同的计算单元上同时执行。同时,(ii)MAT引擎顺序地执行
与1)已获得的
以及2)
之间的乘法,为
个头分别生成等式(4)中的除数和被除数。这意味着第V-A2节的步骤i/iii在MAT引擎上连续计算。在此过程中,首先生成的除数被缓存到除数缓冲区,然后路由到对数2量化模块进行对数2量化。(iii)一旦获得被除数,它们可以通过重新量化模块重新量化,然后与已对数2量化的除数一起发送到辅助移位器阵列,通过位运算移位执行元素级除法,从而得到MSA的最终输出。请注意,一旦完成所有头的
的计算,R-MAC引擎可以与MAT引擎一起重新用于计算除数和被除数。
VI Experimental Results
Experimental Setup
数据集、 Baseline 与评价指标。 作者在_ImageNet数据集_[37]上验证了TriViT的后训练量化算法。具体来说,作者从训练集中随机抽取了
张图像作为校准数据,然后在验证集上进行测试。
为了验证作者的_量化引擎_的有效性,作者考虑了_seven baselines_:MinMax、EMA [38]、Percentile [39]、OMSE [40]、Bit-Split [41]、EasyQuant [42]以及当前最优方法FQ-ViT [9],针对标准的ViTs [4]/DeiTs [5],并与它们在准确性(默认为top-1准确性)方面进行比较。
为了验证作者专用的_加速器_,作者考虑了_nine baselines_:
(i)全精度ViTs在广泛使用的边缘GPU(NVIDIA Tegra X2)上执行;8位量化ViTs遵循
(ii) FasterTransformer [43],
(iii) I-BERT [44],以及
(iv) I-ViT ,并在支持通过TVM高效整数运算的GPU(NVIDIA 2080Ti)的Turing Tensor Core上进行加速;(v)在广泛使用的边缘CPU(高通骁龙8Gen1 CPU)和边缘GPU上执行全精度EfficientViT,
(vi) NVIDIA Jetson Nano
(vii) NVIDIA Jetson Orin;以及两个SOTA ViT加速器,
(viii)针对标准ViTs的专用加速器Auto-ViT-Acc
(ix)针对高效ViTs之一的Swin Transformer 定制的ViA 。
作者从吞吐量、能效、帧率和DSP效率方面进行比较。
加速器设置。特性: 作者加速器中的计算引擎并行性
(如图8所示)配置为
。因此,作者的加速器中总共有
个乘法器,每个可以执行一个
-位的乘法。为了提高DSP利用率,作者采用了SOTA DSP打包策略[46],在每个DSP内容纳两个
-位乘法,类似于Auto-ViT-Acc [16]以便公平比较。_评估:_ 作者用Verilog实现加速器,通过Vivado Design Suite进行综合,并在Xilinx ZCU102 FPGA上以200-MHz的频率进行评估。表3列出了作者的资源消耗。此外,作者为作者的加速器开发了一个周期精确的模拟器,以获得快速可靠的估算,并通过与RTL实现对比来确保正确性。
Evaluation of Trio-ViT's Post-Training Quantization
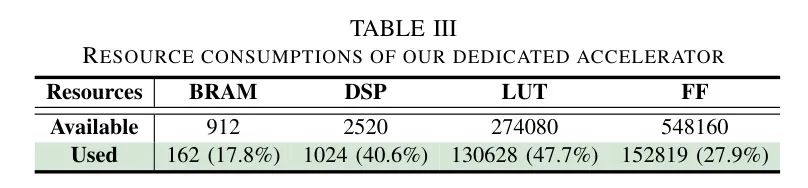
结果与分析。从表4中,作者可以得出四个结论。
(i) 当前的SOTA后训练量化(PTQ)方法FQ-ViT [9],它开发了专门的量化方案以完全量化标准ViTs(包括Softmax)中的所有操作,以提高硬件效率,与全精度模型相比,准确性下降了
**1.36
**。此外,它还比 Baseline PTQ产生了平均
0.75
的准确度下降,在 Baseline PTQ中Softmax和其他非线性操作没有被量化,从而产生了不可忽视的硬件成本。这表明硬件不友好的非线性操作对量化很敏感,阻碍了标准ViTs的可实现硬件效率和量化准确性。
(ii) 为了解决这一限制,提出了名为EfficientViT [12]的SOTA高效ViT,其特点是无需Softmax的线性注意力(LinAttn),并且可以用更少的参数和计算成本实现更高的准确度。这凸显了EfficientViT的优势,强调了量化以促进其实际应用的需求。
(iii) 然而,由于MBConvs和MSAs中激活分布的不同,如第IV-A节所述,普通的PTQ方法无法量化EfficientViT,甚至产生了非数字(NaN)问题。
(iv) 为了解决这个问题,作者提出了作者专用的PTQ引擎,它可以有效地量化EfficientViT,与全精度模型相比,平均准确度仅下降了
**0.92
**,证明了作者方法的有效性。
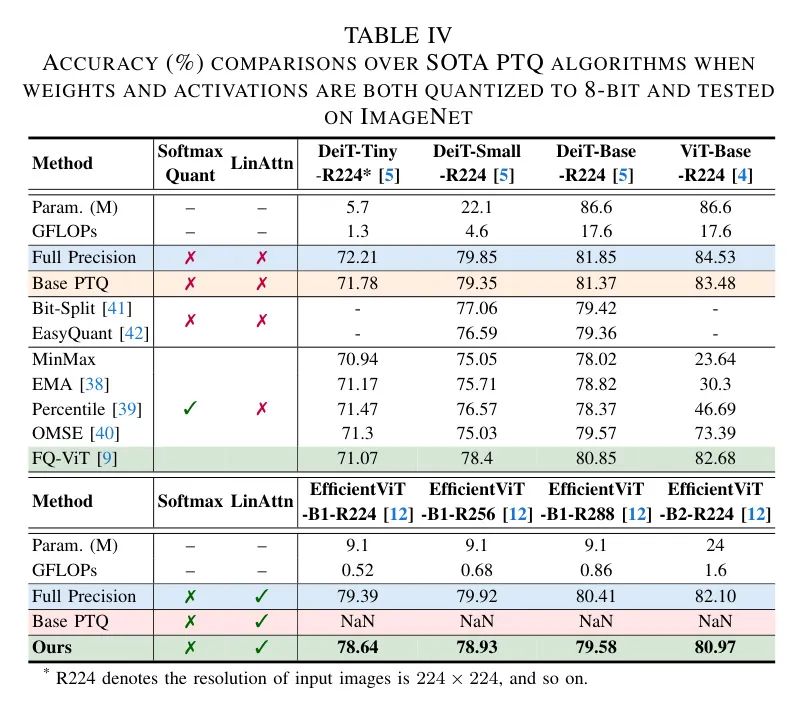
作者专用量化引擎的有效性。如表5所示,作者可以看出:对于MBConvs内的量化,
(i) 由于DW输入中的通道间变化和PW2输入中的通道间不对称,如第IV-A1节所述,普通的均匀量化无法量化EfficientViT中的MBConvs。
(ii) 通过结合作者提出的通道迁移和滤波器偏移,分别解决上述两个问题,两者都是不可或缺的,作者可以有效地量化MBConvs,平均准确度仅下降0.54%。在此基础上,关于轻量级MSA的量化,
(iii) 由于小值在除数中的量化极端敏感性,如第IV-A2节所示,普通的8位均匀量化产生了NaN问题。
(iv) 因此,作者建议对除数采用以2为底的对数量化,这为较小的值分配了更多的箱,并且与除数的算法性质本质上兼容,从而允许仅用4位有效地量化除数。
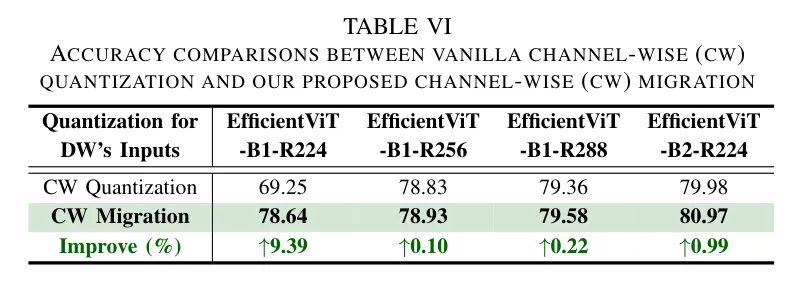
提出的通道迁移的有效性。考虑到DWConvs的独特算法特性,其中每个权重通道作为一个独立的滤波器处理每个输入通道,通道量化是解决DW输入中通道间变化的直接解决方案,如第IV-B节所述。然而,这将大大增加缩放因子的数量,通过LSQ [32]进行量化优化挑战性增加,限制了可实现的准确性。因此,作者建议在层量化之上采用通道迁移。如表6所示,通过这样做,作者可以提供平均
**2.67
**的准确度,证明了在保持优化效率的同时解决DW输入的通道间变化的优势。
Evaluation of Trio-ViT's Dedicated Accelerator
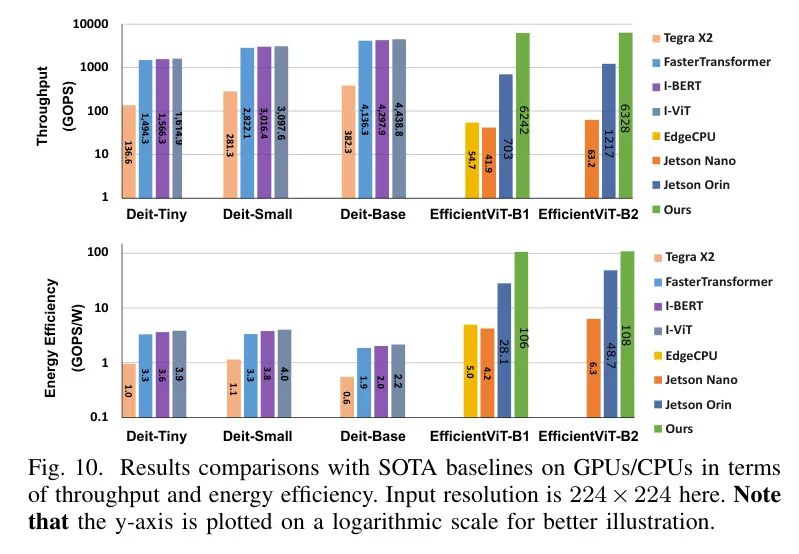
与GPU/CPU上的SOTA Baseline 的比较。作者遵循[47, 26]的方法,将作者的加速器的硬件资源扩展到与通用计算平台(即NVIDIA 2080Ti GPU)具有可比的峰值吞吐量,以便与GPU/CPU进行公平的比较。如图10所示(其中y轴以对数刻度绘制以便更好地说明),与GPU/CPU上的SOTA Baseline 相比,作者可以获得更好的硬件效率,证明了作者的有效性。具体来说:
**(i)**与Edge GPU(Tegra X2)上的全精度DeiTs [5]相比,作者可以分别实现
17
46
的吞吐量和
92
195
的能量效率。
**(ii)**对于与NVIDIA 2080Ti GPU的Turning Tensor Core上执行的通过FasterTransformer [43]量化的8位DeiTs、I-BERT [44]和I-ViT [11]的比较,作者可以提供
1.4
4.2
的吞吐量和
26
58
的能量效率。此外,
(iii)与边缘CPU上全精度的EfficientViT [12]相比,作者可以分别获得高达
116
的吞吐量和
22
的能量效率。
**(iv)**与边缘GPU(NVIDIA Jetson Nano和Jetson Orin)上的EfficientViT相比,作者可以在吞吐量和能量效率方面分别获得
5.2
149
和
2.2
25
的提升。
与SOTA ViT加速器的比较。
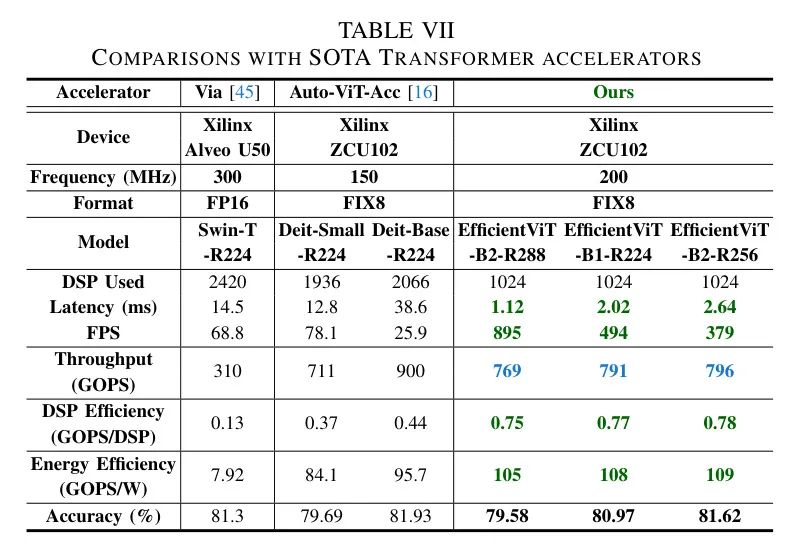
从表7中可以看出:
(i)由于作者量化引擎的优越性以及与标准DeiT相比EfficientViT在硬件效率方面的前景,作者在可比准确度下获得了最低的延迟和最高的帧率(FPS)。特别是,与为Swin-Transformer-Tiny(Swin-T)[22]这个高效ViT设计的专用加速器Via [45]相比,作者可以实现高达
**7.2
**的FPS,以及与专用ViT/DeiT加速器Auto-ViT-Acc [16]相比,实现
**14.6
**的FPS。
(ii)此外,由于作者的专用加速器采用了混合设计,旨在有效地支持EfficientViT中卷积-Transformer混合架构的各种算子,并提高了硬件利用率,作者可以实现最高的硬件利用率效率。例如,与Via和Auto-ViT-Acc相比,作者可以分别提供高达
**6.0
**和
**2.1
**的DSP效率。
(iii)此外,由于作者开发的流水线架构旨在促进层间和层内融合,与Via和Auto-ViT-Acc相比,作者可以分别获得高达
**13.7
**和
1.3
的能量效率。
VII Conclusion
作者提出了Vision Transformer(ViT),称为EfficientViT。具体来说,在算法层面,作者提出了一种定制的后训练量化引擎,该引擎融合了多种创新量化方案,以有效量化EfficientViT并提高量化精度。在硬件层面,作者开发了一个专用的加速器,整合了混合设计和流水线架构,旨在提升硬件效率。广泛的实验结果一致证明了作者的有效性。特别是,与最先进的ViT加速器相比,作者可以获得高达
**7.2
**和
**14.6
**的帧率,同时保持相当的准确度。
在本文中,作者提出了、开发并验证了Trio-ViT,这是首个针对最先进(SOTA)高效限制和未来工作的后训练量化与加速框架。已经广泛证明,模型层对量化表现出不同程度的敏感性,因此为所有层分配相同位数被认为是准确性和效率上的次优选择。因此,作者未来的研究将重点探索混合量化,考虑量化位数和方案(如固定点和二进制幂)的变化。
已经广泛证明,模型层对量化表现出不同程度的敏感性,因此为所有层分配相同位数被认为是准确性和效率上的次优选择[18, 20]。因此,作者未来的研究将重点探索混合量化,考虑量化位数和方案(如固定点和二进制幂)的变化。
参考
[1].Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer.