
Graphs and Sessions(图表和会话)
TensorFlow使用数据流图来表示单个操作之间依赖关系的计算。这导致了一个低级编程模型,您首先在其中定义数据流图,然后创建一个TensorFlow 会话以在一组本地和远程设备上运行图的一部分。
如果您打算直接使用低级编程模型,本指南将非常有用。更高级别的API(例如tf.estimator.EstimatorKeras)隐藏最终用户的图表和会话细节,但如果您想了解如何实现这些API,本指南可能也很有用。
为什么使用数据流图?
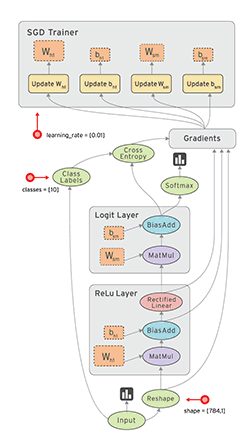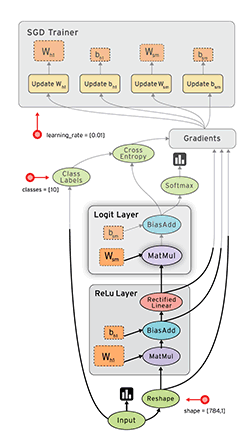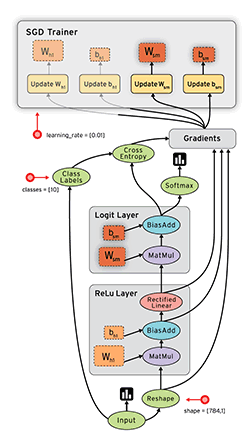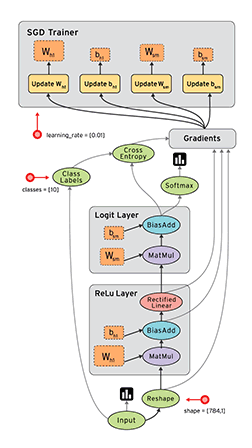
数据流具有TensorFlow在执行程序时利用的几个优点:
- 并行。通过使用显式边来表示操作之间的依赖关系,系统很容易识别可以并行执行的操作。
- 分布式执行。通过使用显式边来表示在操作之间流动的值,TensorFlow可以将程序分区到连接到不同机器的多个设备(CPU,GPU和TPU)上。TensorFlow在设备之间插入必要的通信和协调。
- 汇编。TensorFlow的XLA编译器可以使用数据流图中的信息生成更快的代码,例如,通过融合相邻操作。
- 可移植性。数据流图是模型中代码的语言无关表示。您可以使用Python构建数据流图,将其存储在SavedModel中,然后在C ++程序中将其恢复为低延迟推理。
什么是tf.Graph?
tf.Graph包含两种相关的信息:
- 图结构。图的节点和边,表示单个操作如何组合在一起,但没有规定应该如何使用它们。图结构就像汇编代码:检查它可以传达一些有用的信息,但它不包含源代码传达的所有有用上下文。
- 图表集合。TensorFlow提供了一种通用机制来存储a中的元数据集合
tf.Graph。该tf.add_to_collection函数使您可以将对象列表与一个键(其中tf.GraphKeys定义了某些标准键)tf.get_collection相关联,并且使您能够查找与某个键相关联的所有对象。TensorFlow库的许多部分都使用这个工具:例如,当您创建一个工具时tf.Variable,它会默认添加到代表“全局变量”和“可训练变量”的集合中。当您稍后创建tf.train.Saveror时tf.train.Optimizer,这些集合中的变量将用作默认参数。
建立 tf.Graph
大多数TensorFlow程序从数据流图构建阶段开始。在这个阶段,您调用构建新tf.Operation(节点)和tf.Tensor(边)对象并将它们添加到tf.Graph实例的TensorFlow API函数。TensorFlow提供了一个默认图形,它是对同一上下文中所有API函数的隐式参数。例如:
- 调用
tf.constant(42.0)会创建一个tf.Operation生成该值的单个元素42.0,将其添加到默认图形中,并返回一个tf.Tensor代表该常量的值。 - 呼叫
tf.matmul(x, y)创建一个tf.Operation相乘的值tf.Tensor对象x和y,把它添加到默认的图形,并返回一个tf.Tensor表示相乘的结果。 - 执行
v = tf.Variable(0)添加到图表中tf.Operation,该表格将存储在tf.Session.run调用之间持续存在的可写张量值。的tf.Variable对象包装该操作,并且可以像张量,这将读出的存储值的当前值被使用。该tf.Variable对象还具有创建对象的方法assign,assign_add该tf.Operation对象在执行时更新存储的值。(有关变量的更多信息,请参阅变量。) - 调用
tf.train.Optimizer.minimize会将操作和张量添加到计算梯度的默认图形中,并tf.Operation在运行时返回该图形将这些梯度应用于一组变量。
大多数程序仅依赖于默认图形。但是,请参阅处理多个图表以获取更高级用例。高级API(如tf.estimator.EstimatorAPI)代表您管理默认图形,并且 - 例如 - 可以创建用于培训和评估的不同图形。
注意:调用TensorFlow API中的大多数函数只会将操作和张量添加到默认图形中,但不会执行实际计算。相反,您可以编写这些函数,直到您具有
tf.Tensor或tf.Operation代表整体计算 - 例如执行一步梯度下降 - 然后将该对象传递给atf.Session执行计算。有关tf.Session更多详细信息,请参见“在a中执行图形” 部分。
命名操作
tf.Graph对象定义一个命名空间为tf.Operation它包含的对象。TensorFlow自动为图中的每个操作选择一个唯一名称,但给操作描述性名称可以使您的程序更易于阅读和调试。TensorFlow API提供了两种覆盖操作名称的方法:
- 每个创建新的
tf.Operation或返回新的API函数tf.Tensor接受一个可选name参数。例如,tf.constant(42.0, name="answer")创建一个新的tf.Operationnamed"answer"并返回一个tf.Tensornamed"answer:0"。如果默认的图形已经包含的操作命名"answer",该TensorFlow会追加"_1","_2"等的名称,以使其具有唯一性。 tf.name_scope函数可以为特定上下文中创建的所有操作添加名称范围前缀。当前名称作用域前缀是"/"所有活动tf.name_scope上下文管理器的名称的限定列表。如果一个名字的范围已经在当前的环境中使用,TensorFlow appens"_1","_2"等。例如:
c_0 = tf.constant(0, name="c") # => operation named "c"
# Already-used names will be "uniquified".
c_1 = tf.constant(2, name="c") # => operation named "c_1"
# Name scopes add a prefix to all operations created in the same context.
with tf.name_scope("outer"):
c_2 = tf.constant(2, name="c") # => operation named "outer/c"
# Name scopes nest like paths in a hierarchical file system.
with tf.name_scope("inner"):
c_3 = tf.constant(3, name="c") # => operation named "outer/inner/c"
# Exiting a name scope context will return to the previous prefix.
c_4 = tf.constant(4, name="c") # => operation named "outer/c_1"
# Already-used name scopes will be "uniquified".
with tf.name_scope("inner"):
c_5 = tf.constant(5, name="c") # => operation named "outer/inner_1/c"图形可视化器使用名称范围对操作进行分组,并减少图形的视觉复杂性。请参阅可视化图表以获取更多信息。
请注意,tf.Tensor在tf.Operation生成张量作为输出后,对象将隐式命名。张量名称的形式"<OP_NAME>:<i>"如下:
"<OP_NAME>"是生成它的操作的名称。"<i>"是一个整数,表示操作输出中该张量的索引。
将操作放置在不同的设备上
如果您希望您的TensorFlow程序使用多个不同的设备,tf.device功能提供了一种便捷的方式来请求在特定上下文中创建的所有操作都放置在同一设备(或设备类型)上。
设备规范具有以下形式:
/job:<JOB_NAME>/task:<TASK_INDEX>/device:<DEVICE_TYPE>:<DEVICE_INDEX>where:
<JOB_NAME>是不以数字开头的字母数字字符串。<DEVICE_TYPE>是已注册的设备类型(如GPU或CPU)。<TASK_INDEX>是一个非负整数,表示指定作业中任务的索引<JOB_NAME>。查看有关tf.train.ClusterSpec工作和任务的解释。<DEVICE_INDEX>是一个表示设备索引的非负整数,例如,用于区分同一进程中使用的不同GPU设备。
您不需要指定设备规范的每个部分。例如,如果您正在单GPU配置的单机配置中运行,则可以使用tf.device它将一些操作固定到CPU和GPU上:
# Operations created outside either context will run on the "best possible"
# device. For example, if you have a GPU and a CPU available, and the operation
# has a GPU implementation, TensorFlow will choose the GPU.
weights = tf.random_normal(...)
with tf.device("/device:CPU:0"):
# Operations created in this context will be pinned to the CPU.
img = tf.decode_jpeg(tf.read_file("img.jpg"))
with tf.device("/device:GPU:0"):
# Operations created in this context will be pinned to the GPU.
result = tf.matmul(weights, img)如果您要在典型的分布式配置中部署 TensorFlow,则可以指定作业名称和任务ID,以将变量放置在参数服务器作业("/job:ps")中的任务上,并在工作作业("/job:worker")中指定任务中的其他操作:
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(tf.truncated_normal([784, 100]))
biases_1 = tf.Variable(tf.zeroes([100]))
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(tf.truncated_normal([100, 10]))
biases_2 = tf.Variable(tf.zeroes([10]))
with tf.device("/job:worker"):
layer_1 = tf.matmul(train_batch, weights_1) + biases_1
layer_2 = tf.matmul(train_batch, weights_2) + biases_2tf.device为您提供了很大的灵活性,可以为单个操作或 TensorFlow 图的广泛区域选择展示位置。在很多情况下,有简单的启发式方法很好。例如,tf.train.replica_device_setterAPI 可用于tf.device为数据并行分布式培训进行操作。例如,以下代码片段显示了如何tf.train.replica_device_setter将不同的放置策略应用于tf.Variable对象和其他操作:
with tf.device(tf.train.replica_device_setter(ps_tasks=3)):
# tf.Variable objects are, by default, placed on tasks in "/job:ps" in a
# round-robin fashion.
w_0 = tf.Variable(...) # placed on "/job:ps/task:0"
b_0 = tf.Variable(...) # placed on "/job:ps/task:1"
w_1 = tf.Variable(...) # placed on "/job:ps/task:2"
b_1 = tf.Variable(...) # placed on "/job:ps/task:0"
input_data = tf.placeholder(tf.float32) # placed on "/job:worker"
layer_0 = tf.matmul(input_data, w_0) + b_0 # placed on "/job:worker"
layer_1 = tf.matmul(layer_0, w_1) + b_1 # placed on "/job:worker"张量类物体
tf.Tensortf.Variablenumpy.ndarraylist(and lists of tensor-like objects)- Scalar Python types:
bool,float,int,str
您可以使用注册附加的类张量类型 tf.register_tensor_conversion_function。
注意:默认情况下,
tf.Tensor每当您使用相同的类张量对象时,TensorFlow 将创建一个新的。如果类张量对象很大(例如numpy.ndarray包含一组训练示例)并且多次使用它,则可能会导致内存不足。为了避免这种情况,请手动调用tf.convert_to_tensor类似张量的对象一次,然后使用返回的对象tf.Tensor。
在tf.Session中执行图形
TensorFlow 使用tf.Session该类来表示客户端程序(通常是 Python 程序)之间的连接,尽管类似的接口在其他语言中可用---和 C ++ 运行时。一个tf.Session对象提供对本地机器中的设备以及使用分布式 TensorFlow 运行时的远程设备的访问。它还会缓存关于您的信息,tf.Graph以便您可以高效地多次运行相同的计算。
创建一个 tf.Session
如果您使用的是低级别 TensorFlow API,则可以tf.Session按如下所示为当前默认图创建一个:
# Create a default in-process session.
with tf.Session() as sess:
# ...
# Create a remote session.
with tf.Session("grpc://example.org:2222"):
# ...由于tf.Session拥有物理资源(例如GPU和网络连接),因此它通常用作在with退出块时自动关闭会话的上下文管理器(在块中)。也可以在不使用with块的情况下创建一个会话,但tf.Session.close在完成时释放资源时应该明确地调用它。
注意:更高级别的 API(例如
tf.train.MonitoredTrainingSession或tf.estimator.Estimator将为您创建和管理)tf.Session。这些 API 接受可选target和config参数(直接或作为tf.estimator.RunConfig对象的一部分),具有与下面所述相同的含义。
tf.Session.__init__ 接受三个可选参数:
target**。如果此参数为空(默认值),则会话将仅使用本地计算机中的设备。但是,您也可以指定一个grpc://URL 来指定 TensorFlow 服务器的地址,从而使会话可以访问此服务器控制的计算机上的所有设备。请参阅有关如何创建 TensorFlow 服务器的详细信息。例如,在常见的图形间复制**配置中,连接到与客户端相同的进程中。分布式 TensorFlow 部署指南介绍了其他常见情况。tf.train.Servertf.Sessiontf.train.Servergraph**。默认情况下,一个新的tf.Session将被绑定---并且只能在---当前默认图中运行操作。如果您在程序中使用多个图形(请参阅使用多个图形编程以获取更多详细信息),则可以tf.Graph在构建会话时指定显式。config**。这个参数允许你指定一个tf.ConfigProto控制会话行为的参数。例如,一些配置选项包括:allow_soft_placement。将其设置True为启用“软”设备放置算法,该算法将忽略tf.device尝试将仅CPU操作放置在GPU设备上的注释,并将其放置在CPU上。cluster_def。使用分布式 TensorFlow 时,此选项允许您指定在计算中使用哪些机器,并提供作业名称,任务索引和网络地址之间的映射。详情请参阅tf.train.ClusterSpec.as_cluster_def。graph_options.optimizer_options。提供对TensorFlow在执行图形之前对其进行优化的控制。gpu_options.allow_growth。将其设置True为更改 GPU 内存分配器,以便逐渐增加分配的内存量,而不是在启动时分配大部分内存。
使用tf.Session.run执行操作
tf.Session.run方法是运行 tf.Operation或评估 的主要机制tf.Tensor。你可以通过一个或多个tf.Operation或tf.Tensor对象tf.Session.run,并TensorFlow将执行所需计算结果的操作。
tf.Session.run要求你指定一个确定返回值的提取列表,可能是a tf.Operation, tf.Tensor或类似张量的类型,例如tf.Variable。这些提取确定必须执行总体的哪个子图tf.Graph来生成结果:这是包含所有在提取列表中指定的操作的子图,以及所有其输出用于计算提取值的操作。例如,下面的代码片段显示了不同的参数如何tf.Session.run导致不同的子图被执行:
x = tf.constant([[37.0, -23.0], [1.0, 4.0]])
w = tf.Variable(tf.random_uniform([2, 2]))
y = tf.matmul(x, w)
output = tf.nn.softmax(y)
init_op = w.initializer
with tf.Session() as sess:
# Run the initializer on `w`.
sess.run(init_op)
# Evaluate `output`. `sess.run(output)` will return a NumPy array containing
# the result of the computation.
print(sess.run(output))
# Evaluate `y` and `output`. Note that `y` will only be computed once, and its
# result used both to return `y_val` and as an input to the `tf.nn.softmax()`
# op. Both `y_val` and `output_val` will be NumPy arrays.
y_val, output_val = sess.run([y, output])tf.Session.run还可以选择使用Feed的字典,它是从tf.Tensor对象(通常为tf.placeholder张量)到值(通常是Python标量,列表或NumPy数组)的映射,这些值将替换执行中的张量。例如:
# Define a placeholder that expects a vector of three floating-point values,
# and a computation that depends on it.
x = tf.placeholder(tf.float32, shape=[3])
y = tf.square(x)
with tf.Session() as sess:
# Feeding a value changes the result that is returned when you evaluate `y`.
print(sess.run(y, {x: [1.0, 2.0, 3.0]}) # => "[1.0, 4.0, 9.0]"
print(sess.run(y, {x: [0.0, 0.0, 5.0]}) # => "[0.0, 0.0, 25.0]"
# Raises `tf.errors.InvalidArgumentError`, because you must feed a value for
# a `tf.placeholder()` when evaluating a tensor that depends on it.
sess.run(y)
# Raises `ValueError`, because the shape of `37.0` does not match the shape
# of placeholder `x`.
sess.run(y, {x: 37.0})tf.Session.run还接受一个可选options参数,使您可以指定有关该调用的选项,以及一个可选run_metadata参数,使您可以收集有关执行的元数据。例如,您可以一起使用这些选项来收集有关执行的跟踪信息:
y = tf.matmul([[37.0, -23.0], [1.0, 4.0]], tf.random_uniform([2, 2]))
with tf.Session() as sess:
# Define options for the `sess.run()` call.
options = tf.RunOptions()
options.output_partition_graphs = True
options.trace_level = tf.RunOptions.FULL_TRACE
# Define a container for the returned metadata.
metadata = tf.RunMetadata()
sess.run(y, options=options, run_metadata=metadata)
# Print the subgraphs that executed on each device.
print(metadata.partition_graphs)
# Print the timings of each operation that executed.
print(metadata.step_stats)你的可视化图形
TensorFlow包含的工具可以帮助您理解图表中的代码。曲线图可视化是在视觉上呈现您图的结构在浏览器TensorBoard的组分。创建可视化的最简单方法是tf.Graph在创建以下代码时传递tf.summary.FileWriter:
# Build your graph.
x = tf.constant([[37.0, -23.0], [1.0, 4.0]])
w = tf.Variable(tf.random_uniform([2, 2]))
y = tf.matmul(x, w)
# ...
loss = ...
train_op = tf.train.AdagradOptimizer(0.01).minimize(loss)
with tf.Session() as sess:
# `sess.graph` provides access to the graph used in a `tf.Session`.
writer = tf.summary.FileWriter("/tmp/log/...", sess.graph)
# Perform your computation...
for i in range(1000):
sess.run(train_op)
# ...
writer.close()注意:如果您使用的是
tf.estimator.Estimator,则图形(和任何摘要)将自动记录到model_dir创建估计器时指定的值。
然后您可以打开登录tensorboard,导航到“图形”选项卡,并查看图形结构的高级可视化。请注意,典型的TensorFlow图 - 特别是具有自动计算梯度的训练图 - 具有太多的节点,无法一次显示。图表可视化器利用名称范围将相关操作分组为“超级”节点。您可以点击任何这些超级节点上的橙色“+”按钮来展开里面的子图。

有关使用TensorBoard可视化TensorFlow应用程序的更多信息,请参阅TensorBoard教程。
多图表编程
注意:在训练模型时,组织代码的常用方法是使用一个图形来训练模型,并使用单独的图形来评估或执行训练模型的推理。在许多情况下,推理图将与训练图不同:例如,丢失和批量归一化等技术在每种情况下都使用不同的操作。此外,默认情况下,实用程序
tf.train.Saver会使用tf.Variable对象的名称(具有基于底层的名称tf.Operation)来标识保存的检查点中的每个变量。以这种方式进行编程时,可以使用完全独立的Python进程来构建和执行图形,也可以在同一进程中使用多个图形。本节介绍如何在同一过程中使用多个图。
如上所述,TensorFlow提供了一个“默认图”,该图默认传递给同一上下文中的所有API函数。对于许多应用程序来说,一张图就足够了。但是,TensorFlow还提供了操作默认图的方法,这在更高级的使用情况下可能很有用。例如:
tf.Graph定义了tf.Operation对象的名称空间:单个图形中的每个操作都必须具有唯一的名称。通过附加TensorFlow将“uniquify”操作的名称"_1","_2"等他们的名字,如果请求的名称已被使用。使用多个显式创建的图可以更好地控制每个操作的名称。- 默认图形存储关于每个
tf.Operation和tf.Tensor添加到它的信息。如果你的程序创建了大量的未连接的子图,那么使用一个不同的tf.Graph子程序来构建每个子图可能会更有效率,这样就可以无用地收集不相关的状态。
您可以安装另一个tf.Graph使用tf.Graph.as_default上下文管理器作为默认图形:
g_1 = tf.Graph()
with g_1.as_default():
# Operations created in this scope will be added to `g_1`.
c = tf.constant("Node in g_1")
# Sessions created in this scope will run operations from `g_1`.
sess_1 = tf.Session()
g_2 = tf.Graph()
with g_2.as_default():
# Operations created in this scope will be added to `g_2`.
d = tf.constant("Node in g_2")
# Alternatively, you can pass a graph when constructing a `tf.Session`:
# `sess_2` will run operations from `g_2`.
sess_2 = tf.Session(graph=g_2)
assert c.graph is g_1
assert sess_1.graph is g_1
assert d.graph is g_2
assert sess_2.graph is g_2要检查当前的默认图形,调用tf.get_default_graph,返回一个tf.Graph对象:
# Print all of the operations in the default graph.
g = tf.get_default_graph()
print(g.get_operations())本文档系腾讯云开发者社区成员共同维护,如有问题请联系 cloudcommunity@tencent.com
