咨询行业专业顾问
关于使用场景和技术架构的更多咨询, 请联系我们的销售和技术支持团队。
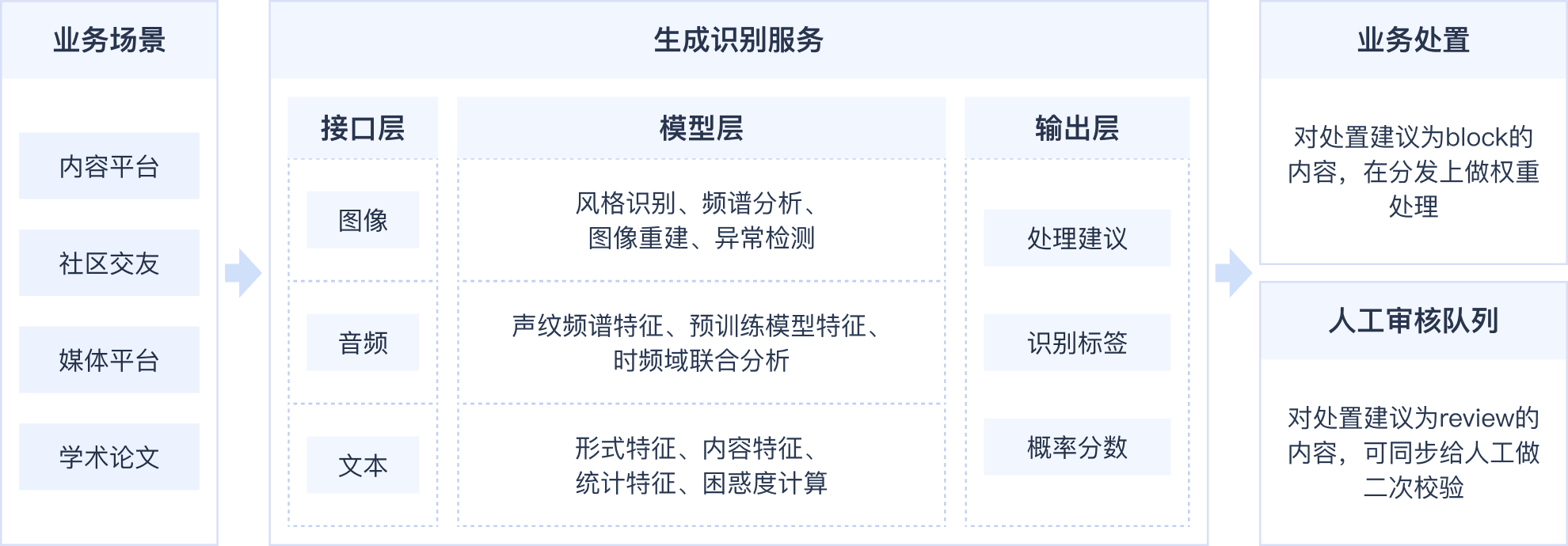
利用AI工具生成的内容,图片逼真、且音视频搭配,颠覆了常规的“有图有真相”的认知,蛊惑性极强。
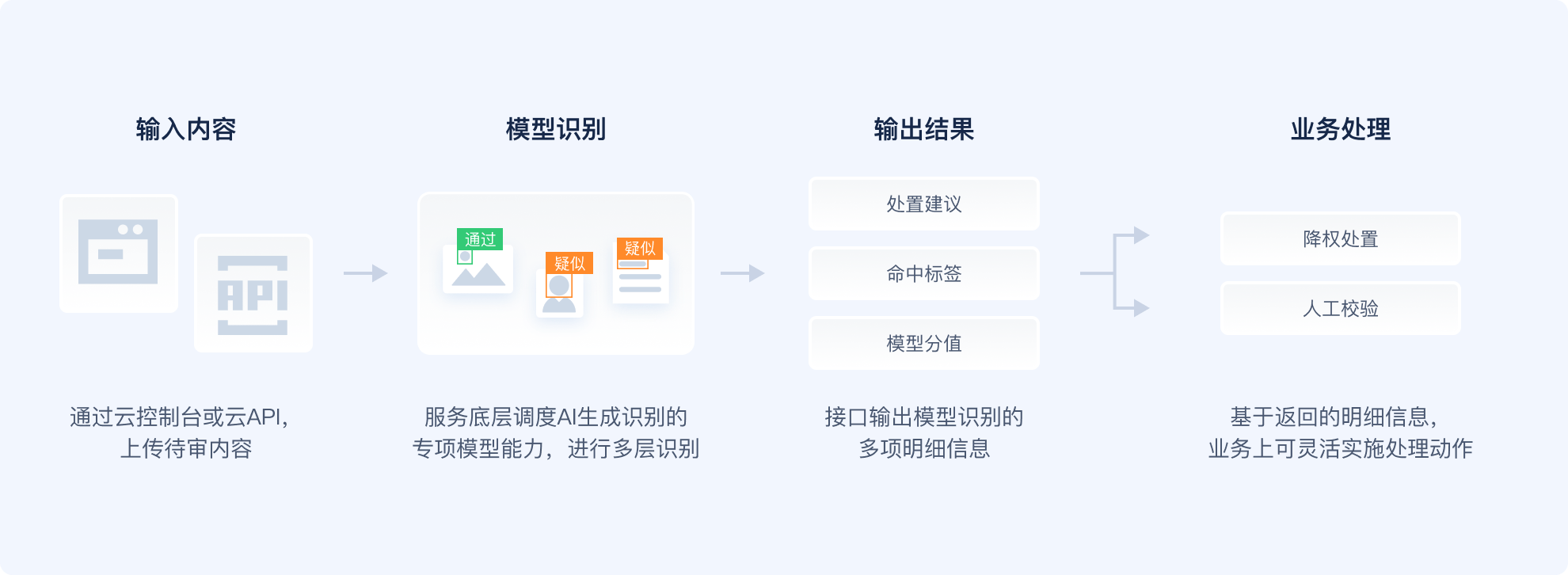
能够捕捉到AI生成图片与真实图片之间的细微差异,如不符合常识逻辑的内容、隐层特征以及人物形象等,在实际应用中准召指标优异
不同于对所有类型的文字内容进行泛泛训练,我们对新闻、百科、问答、评论、小说等场景专项构建模型,从而能针对性的精准识别这些场景的生成风格
通过自主构建并持续更新的“对抗性”数据集,有效覆盖各类难以检测的AI生成音频,确保对新型生成方式的识别能力