操作场景
异常诊断为 TDSQL Boundless(TDStore 引擎) 实例提供实时的健康巡检、性能异常发现与故障定位能力。本功能以实例为单位采集与展示性能指标和诊断事件,帮助用户在统一界面中快速感知 CPU 使用率突增、内存压力、磁盘占用过高、慢会话堆积、死锁等异常事件,并基于诊断详情进一步排查根因。
适用场景
业务高峰期 CPU/内存使用率异常飙升时,快速定位异常实例并查看对应 TOP 活跃会话。
磁盘空间告警时,识别实例的磁盘占用情况。
出现死锁告警时,查看死锁阻塞环、被回滚事务及涉及的 SQL。
业务侧反馈数据库响应变慢时,通过历史诊断追溯异常时间窗口及对应事件。
背景信息
异常诊断围绕 TDSQL Boundless 实例提供完整的诊断能力:
实例级诊断:所有诊断项均以实例为单位计算与触发,告警值与诊断详情聚合后在实例视图中统一呈现。
诊断事件:当实例的关键指标超过阈值时,生成对应风险等级的诊断事件,事件包含事件摘要、现场描述、智能分析三部分内容。
现场快照:CPU 类诊断事件自动抓取实例当时的 TOP 活跃会话与性能监控曲线,附加在诊断详情的“现场描述”中。
死锁感知:内置死锁增量检测能力,识别死锁阻塞环并展示被回滚的事务 ID 及涉及的 SQL。
实现机制
异常诊断采用“实时事件驱动 + 定时巡检”双通道:
实时通道:通过性能监控数据流持续监测实例的关键指标,指标超过阈值时触发实时诊断事件。
定时通道:默认每 10 分钟执行一次健康巡检,对死锁信息进行增量扫描。
诊断结果以“事件”形式持久化保存,每个事件包含事件摘要、现场描述、智能分析三部分内容,并按风险等级分级展示。
诊断项说明
诊断项 | 类别 | 触发条件 | 风险等级划分 |
CPU 利用率 | 性能 | CPU 利用率过高 | 致命:80% < CPU 利用率 严重:60% < CPU 利用率 ≤ 80% 告警:40% < CPU 利用率 ≤ 60% |
死锁 | 可靠性 | 数据库发生死锁 | 致命 |
使用限制
死锁版本依赖:死锁诊断依赖内核侧的死锁系统视图,仅在内核版本21.6.1 及以上的实例上生效。
死锁巡检周期:死锁诊断采用“定时巡检 + 增量扫描”,默认每 10 分钟执行一次,单次最长回溯 30 天。
注意事项
在大流量场景下,CPU、内存、磁盘等资源类告警可能在短时间内连续触发,DBbrain 会自动对短时间窗口内的同类告警进行去重,仅保留首条事件。
前提条件
已在数据库智能管家 DBbrain 中正确接入 TDSQL Boundless 实例。
当前登录账号对该实例具备 DBbrain 的查看权限。
查看诊断信息
1. 登录 DBbrain 控制台。
2. 在左侧导航栏选择 诊断优化。
3. 在页面顶部依次选择数据库类型为 TDSQL Boundless,并选择目标实例 ID。
4. 单击异常诊断页签。
5. 在页面右侧选择查看实时或历史诊断信息。
6. 查看已选时间范围的核心健康指标、异常事件诊断图表、SQL 情况、诊断提示。
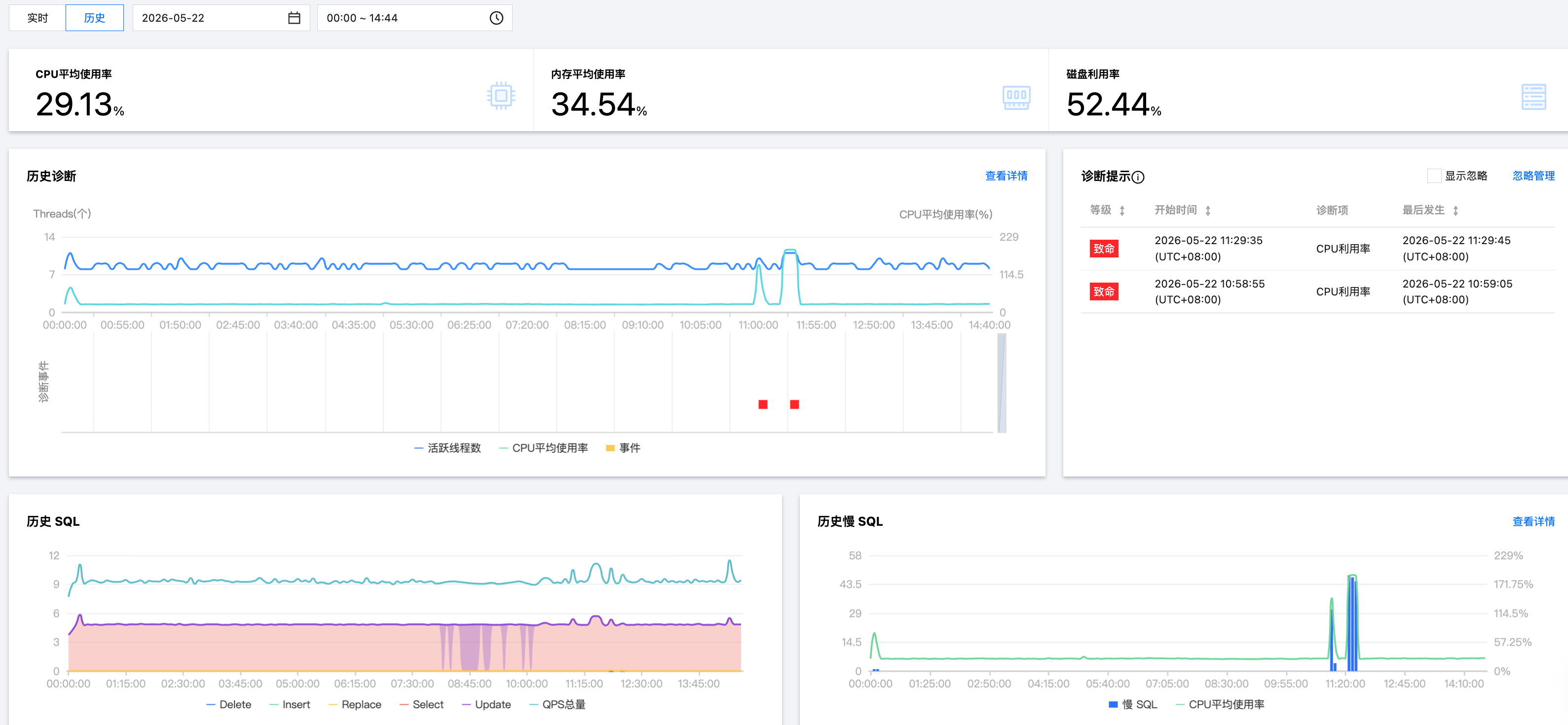
查看核心健康指标
CPU 平均使用率:确认是否在正常范围内,关注变化趋势箭头(↑上升、↓下降)。
内存平均使用率:关注变化趋势箭头(↑上升、↓下降),评估是否存在内存泄漏风险。
磁盘利用率:确认是否接近告警阈值(建议 < 80%)。
分析实时/历史诊断
展示活跃线程数(Threads)与 CPU 平均使用率的时间序列,曲线下方红色色块标识诊断事件发生位置。
6.1.1 观察活跃线程数和 CPU 平均使用率的变化趋势。
线程数突刺 + CPU 同步飙升:可能是并发请求暴增。
CPU 飙升但线程数无明显变化:可能是单条复杂 SQL 导致。
6.1.2 鼠标悬停至诊断事件条形图时,将展示风险等级、概要和起止时间等信息,单击条形图可跳转至事件详情页面,可查看事件详情、现场描述、智能分析、优化建议等信息。查看事件详情的操作请参见 异常告警。
查看下方事件时间线的颜色分布,快速定位异常密集时段,若需查看更多维度指标,单击右上方查看详情。
查看实时/历史 SQL 趋势图和实时/历史慢 SQL 趋势图
实时/历史 SQL:查看 Select、Update 等各类 SQL 的执行数量变化趋势。
某类 SQL 突然激增可能是业务异常或慢查询导致的堆积。
实时/历史慢 SQL:查看慢 SQL 数量与 CPU 平均使用率的关联曲线。
若慢 SQL 与 CPU 曲线同步上升,说明慢查询可能是 CPU 资源消耗的主因。若需深入分析,单击查看详情跳转至慢 SQL 分析页面。
查看诊断提示
列出近 3 小时内触发的诊断事件,包含事件等级、开始时间、诊断项、最后发生时间字段。
诊断事件显示等级分为健康、提示、告警、严重、致命。
查看诊断事件详情
在诊断提示中,单击具体的事件告警所在行,或者鼠标悬停至事件告警上,单击查看,进入事件详情页面,查看事件详情。
事件详情主要包括事件详情、现场描述、智能分析、优化建议等信息。诊断类型不同展示的事件详情不同,请以实际展示为准。
事件详情:包括诊断项、起止时间、风险等级、概要等信息。
现场描述:异常事件(或健康巡检事件)的外在表现现象的快照和性能趋势等信息。
智能分析:展示问题描述、可能原因等说明,帮助理解事件含义。
优化建议:针对资源类、会话类、死锁类等不同诊断项给出对应的处理建议。
忽略/取消忽略诊断提示告警
说明:
该功能仅针对诊断项为非“健康巡检”的异常告警。
在诊断提示中,鼠标悬停至事件告警上,单击忽略,可选择忽略本条、忽略此类型,单击确定。
忽略本条:仅忽略本条告警。
忽略此类型:忽略后,由相同根因产生的异常告警也将被忽略。
已被忽略的诊断事件,将会被置为灰色。
若需取消忽略,单击取消忽略,单击确定。
若需要展示已忽略的告警,可勾选显示忽略。
单击忽略管理,可查看已忽略内容和已忽略类型。
支持进入事件详情页,在右上方单击忽略或取消忽略。
相关操作
性能趋势
实时会话
慢 SQL 分析
空间分析
后续步骤
若 CPU/内存类告警持续出现,建议进入性能趋势页查看更长时间范围的指标曲线,并结合慢 SQL 分析定位具体的高消耗 SQL。
若磁盘利用率较高,建议进入空间分析页查看 TOP 库表的空间占用,定位空间快速增长的数据对象。
若发现慢 SQL,跳转至慢 SQL 分析页面,查看执行计划和优化建议。
若线程数异常,进入实时会话页面,查看当前活跃连接,必要时 Kill 异常会话。
常见问题
Q1:历史诊断图表中没有事件标记点,是什么原因?
该时间段内未触发任何诊断事件,说明实例运行正常。
也可能是诊断功能当时未开启,检查开启时间是否晚于查询的起始时间。
Q2:事件时间线上全是绿色方块,需要关注吗?
全绿表示所有诊断事件均为“健康”等级,无需特别处理。
建议仍关注趋势图中指标是否有缓慢上升趋势(如内存逐步增长),这类情况可能尚未触发告警阈值。
Q3:实例 CPU 平均使用率为什么会显示超过 100%?
CPU 平均使用率反映实例的整体 CPU 压力,受实例规格与统计口径影响,在高负载场景下可能超过 100%。具体的告警值与触发时间,可在 诊断提示 列表中查看对应诊断事件。



