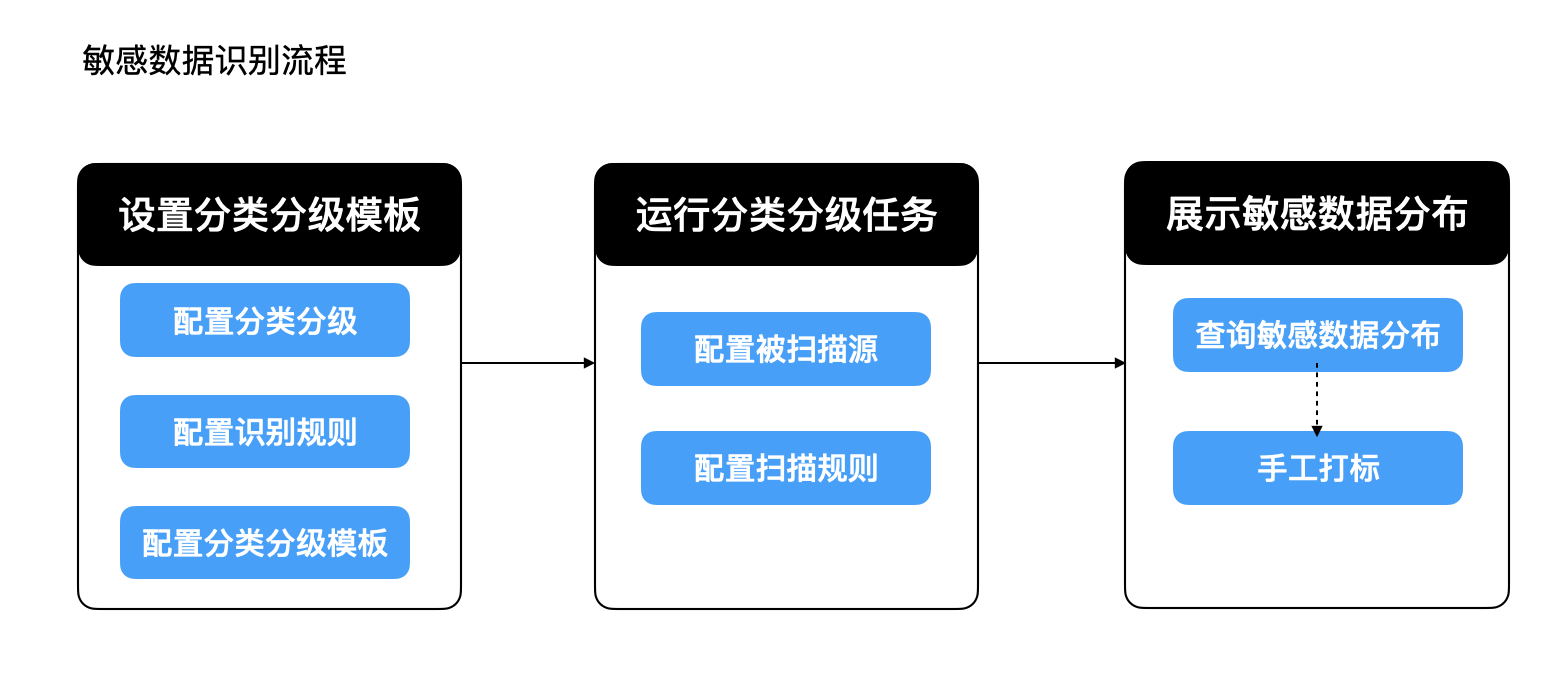
数据分类分级是通过对数据全盘梳理,通过对数据分类分级&敏感数据采用不同的管控策略,实现精细化管控。将数据安全等级与敏感数据识别规则进行结合,以敏感数据识别任务的形式对数据进行周期性检查并输出相应的数据敏感度分类分级,同样支持人工对敏感数据进行打标。
流程图
整体流程如下:
分类分级配置 > 分级
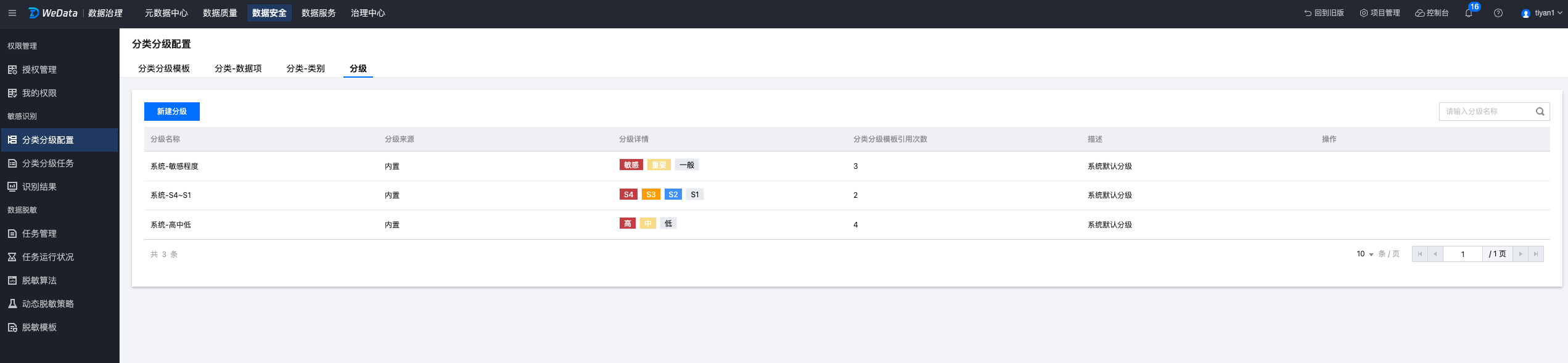
提供给用户进行数据安全分级的定义和管理功能,建立自定义的数据安全等级,最多支持10级。
1. 登录腾讯云后进入WeData 控制台,选择项目并进入 数据安全 > 分类分级配置 > 分级页面,单击新建分级。
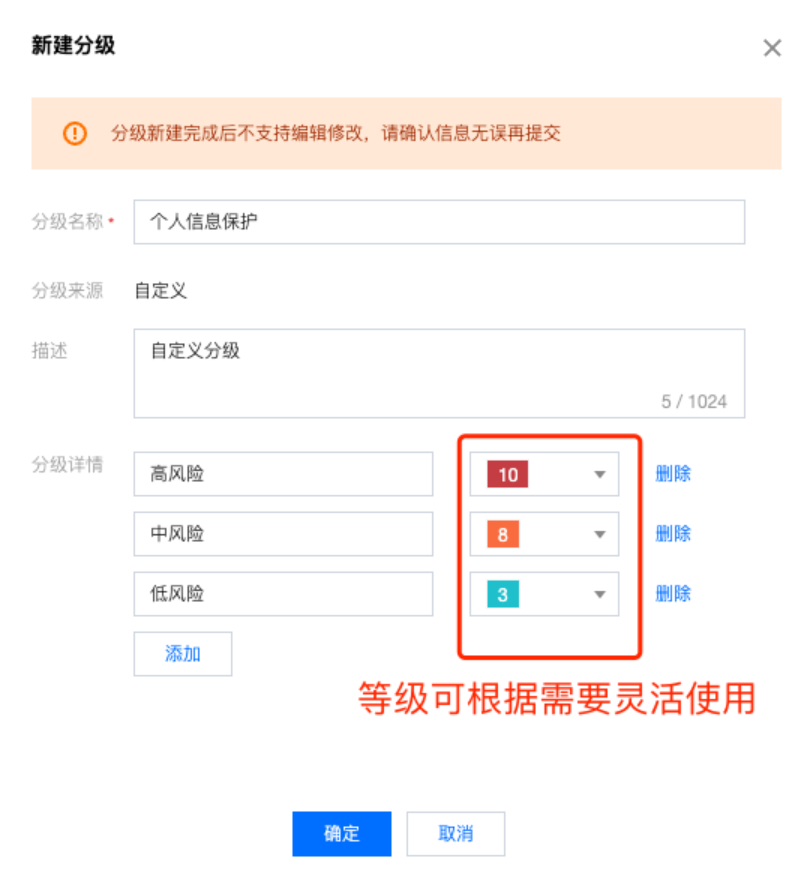
2. 进入新建分级界面,设置分级信息,单击确定。
分级名称:敏感级别名称可自定义输入。
分级描述:简单对分级进行描述。
分级详情:敏感等级最多10个,可根据需要自定义选择。
分类-类别
提供给用户进行数据安全分类的定义和管理功能,通过建立分类维度与细分类适应不同类型、不同场景下的业务敏感数据管理。
1. 进入分类分级配置 > 分类-类别页面,单击新建类别。
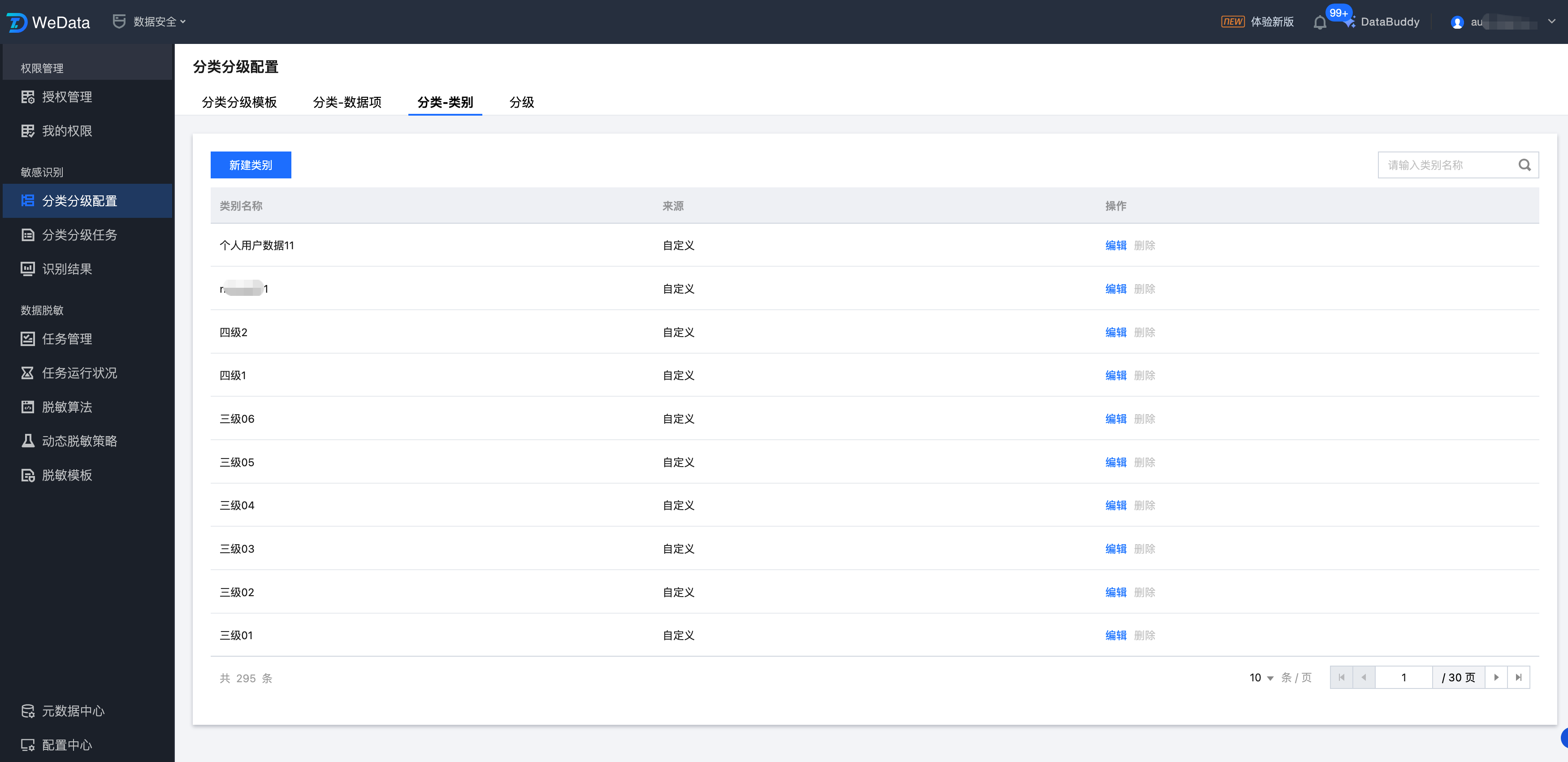
2. 进入新建分类界面,填写分类名称,单击确定。
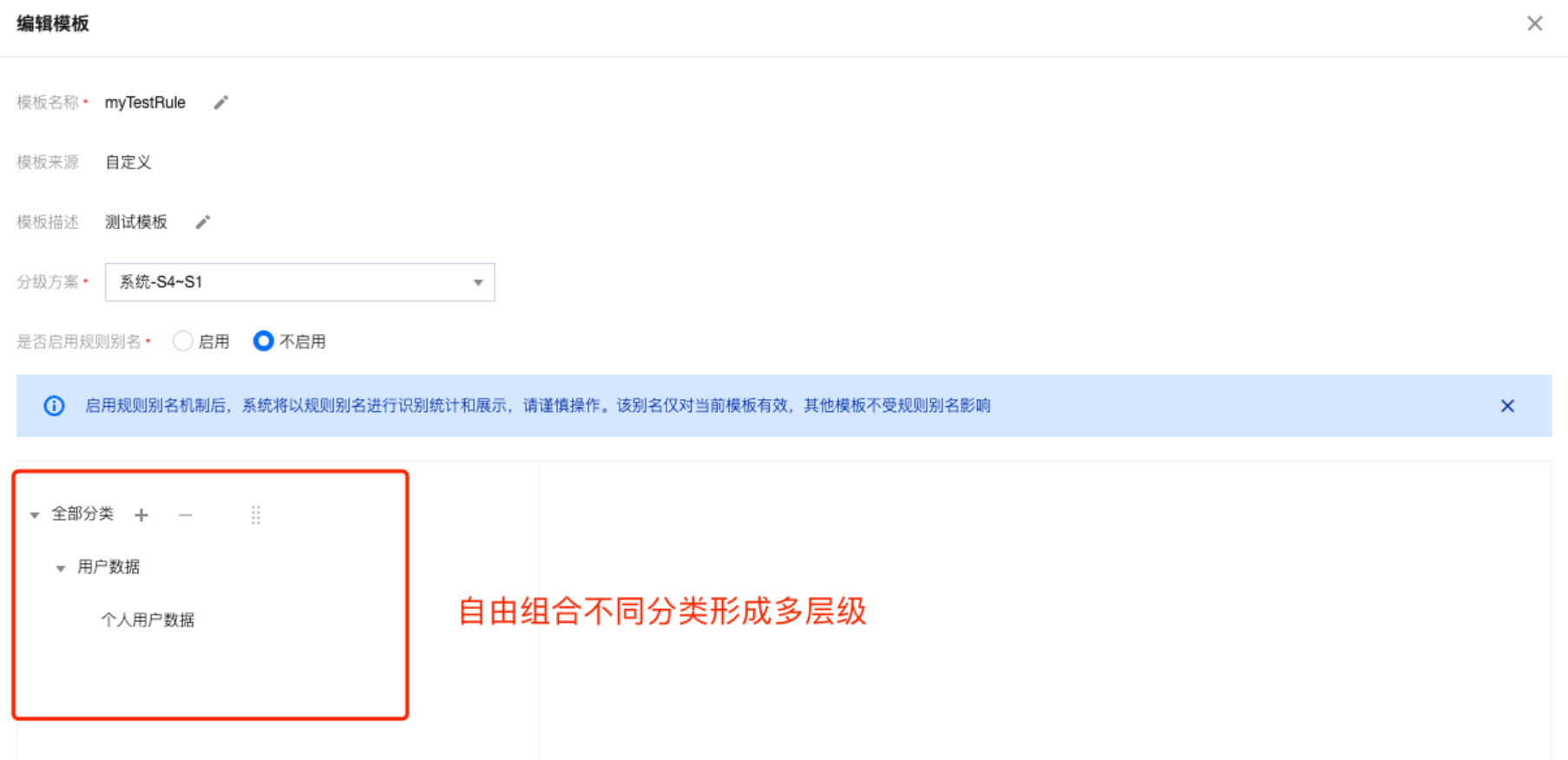
3. 各个分类独立存在,可以组合成不同的多层级分类。在分类分级模板中自由使用,不同模板可以复用分类。进入新建/编辑模板界面,在全部分类中,您可以自由组合不同分类,从而形成多层级。
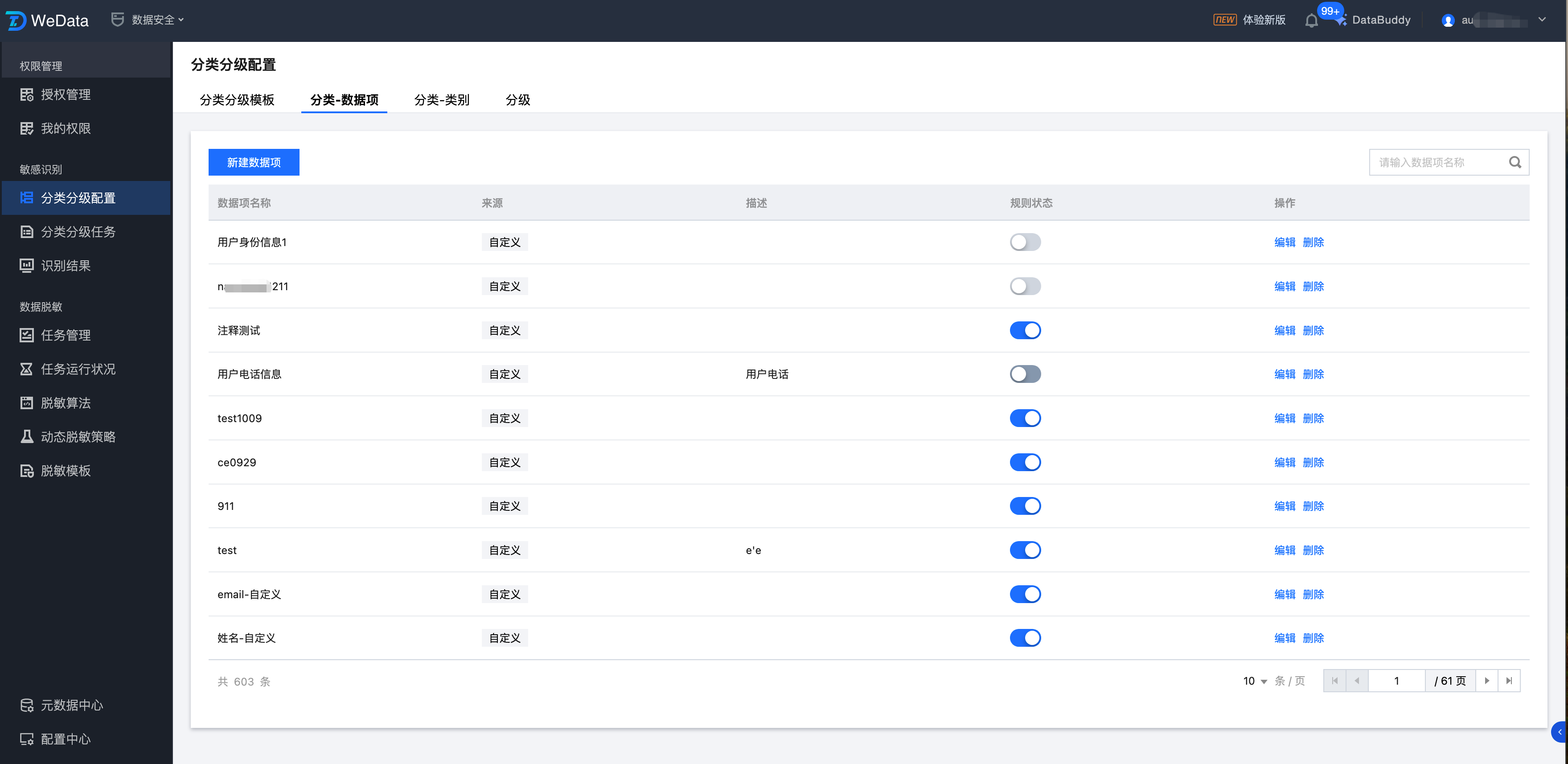
分类-数据项
通过创建数据项来针对数据表字段名称、字段描述、数据内容进行敏感数据识别,主要使用正则表达式来建立规则。利用数据安全分级与识别规则相结合,可以对识别到的敏感数据进行分类分级。
1. 我们提供系统规则模板可以直接在数据识别任务中使用。进入分类分级配置 > 分类-数据项页面,单击新建规则。
2. 进入新建规则界面,填写规则基本信息,单击确定。
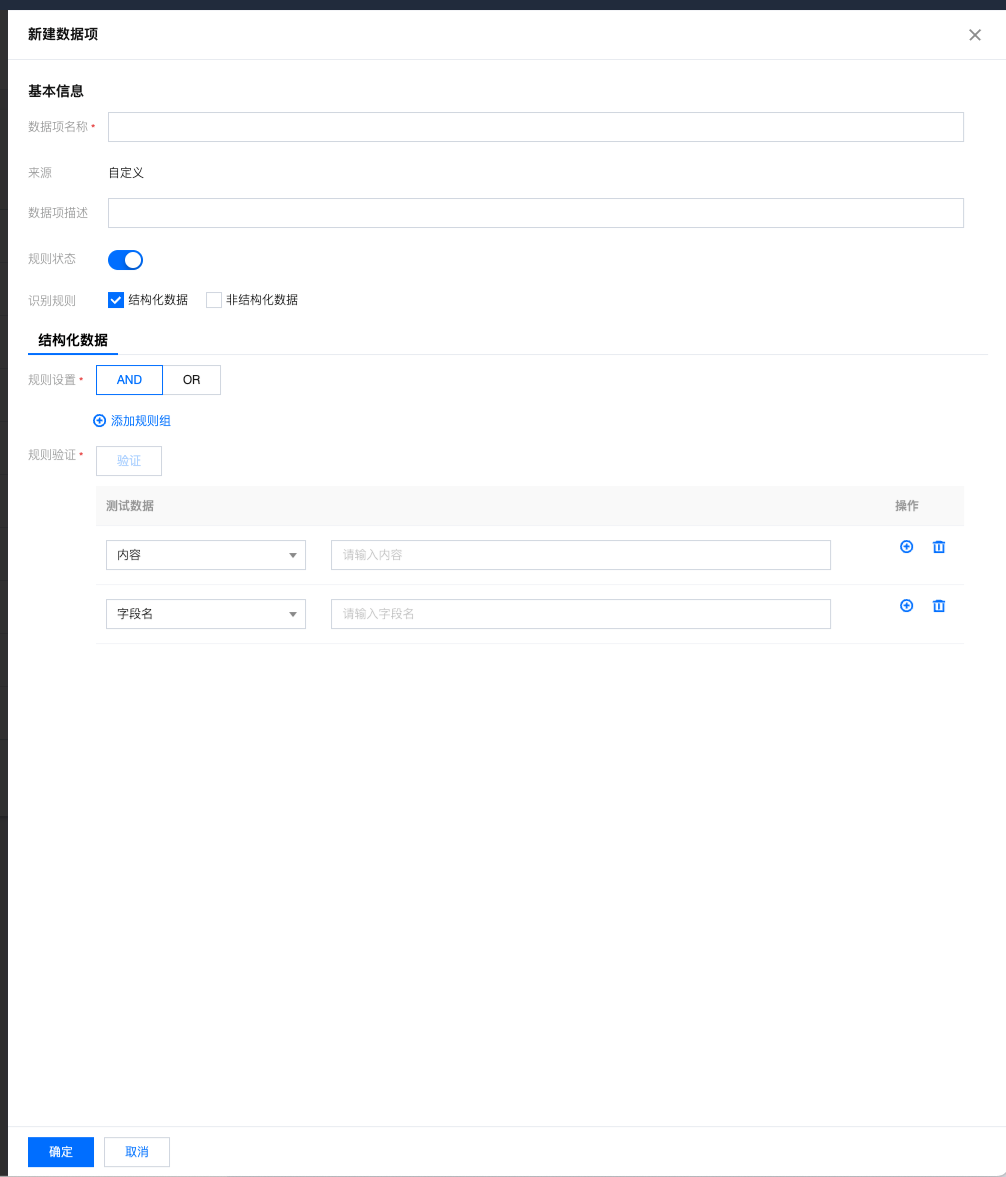
信息 | 详情 |
数据项名称 | 1~60个字符;以中英文或数字开头结尾;仅允许中英文,数字,括号, ' - ', '_'; |
来源 | 分为“内置”和“自定义”,用户自己创建的默认为“自定义” |
规则状态 | 用于控制是否在模板中可用。内置规则默认开启,不可关闭。 |
识别规则 | 支持“结构化数据”和“非结构化数据”两种,可同时配置 |
规则配置: 结构化数据 | 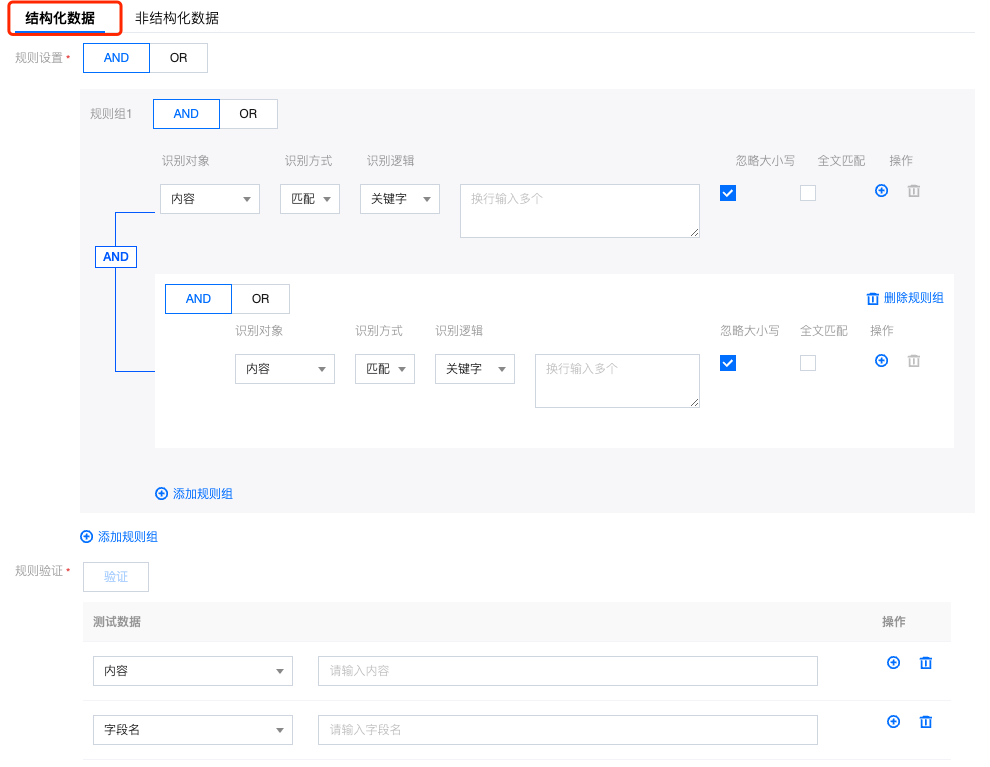 规则设置:支持and和or逻辑判断 ● 识别对象:支持:内容,字段名,字段描述,表名,表描述等对象的识别。(具体以系统为准) ● 识别方式:匹配。 ● 识别逻辑:支持:关键字,正则两种方式。 ● 忽略大小写:默认开启。 ● 全文匹配:默认关闭。 ● 操作:支持规则新增和删除。 规则验证: 完成配置后可以输入测试文字验证识别效果: 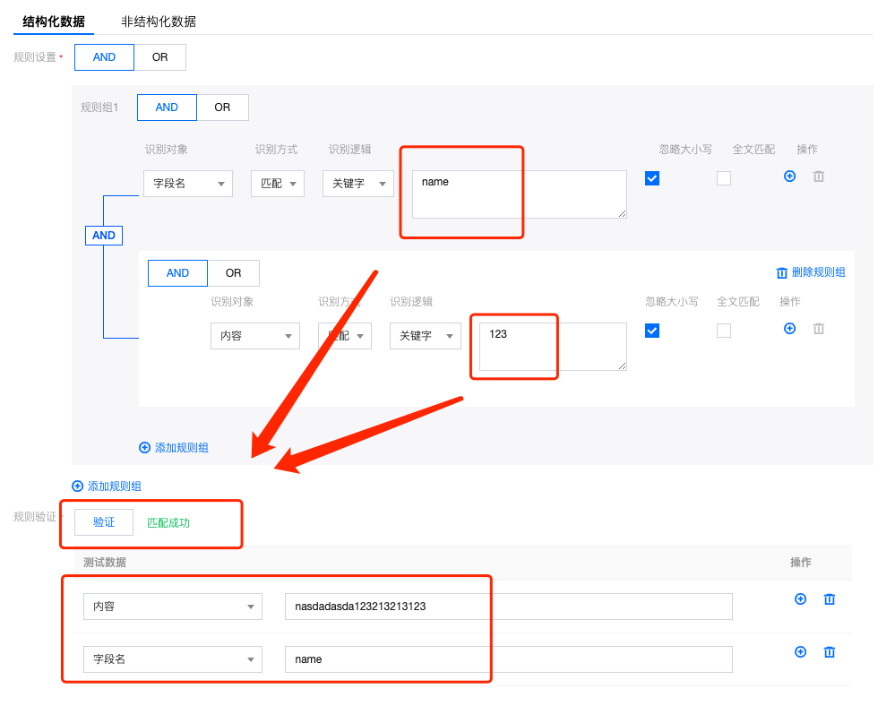 |
非结构化数据 | ● 最大匹配距离:用于识别内容的最大距离,支持1~500,默认100 ● 支持关键字和正则表达式两种识别方式: 关键字: 通过匹配输入的关键字识别内容。支持全文匹配和忽略大小写配置: 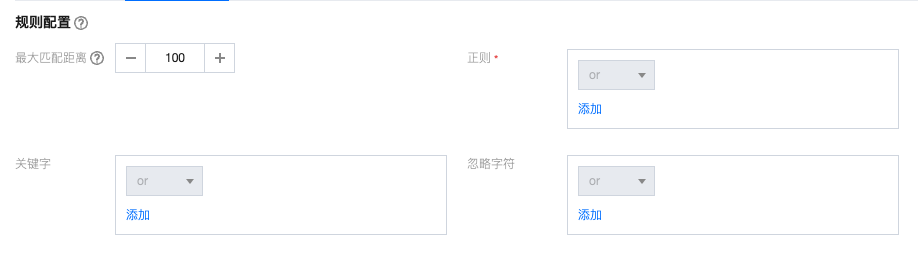 正则: 通过正则表达式识别内容。 ● 忽略字符:支持识别过程中忽略指定的字符。 ● 完成配置后可以输入测试文字验证识别效果: 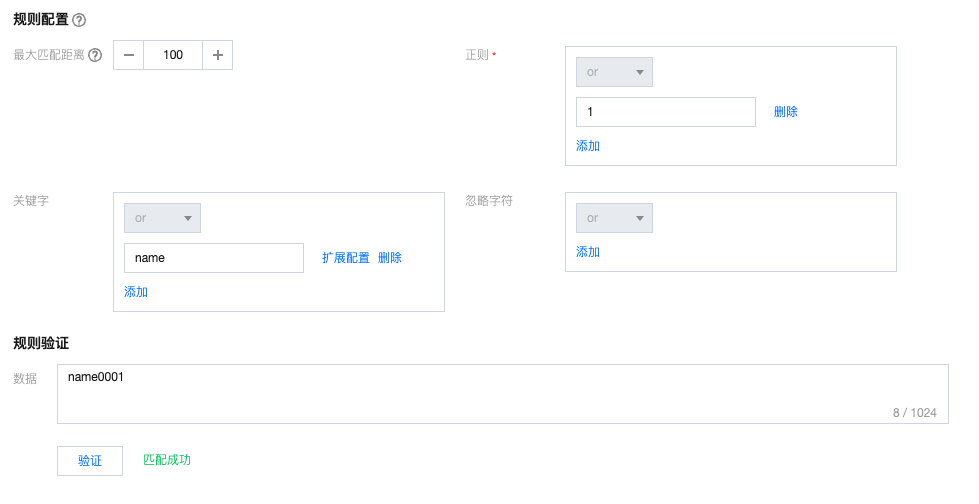 |
分类分级模板
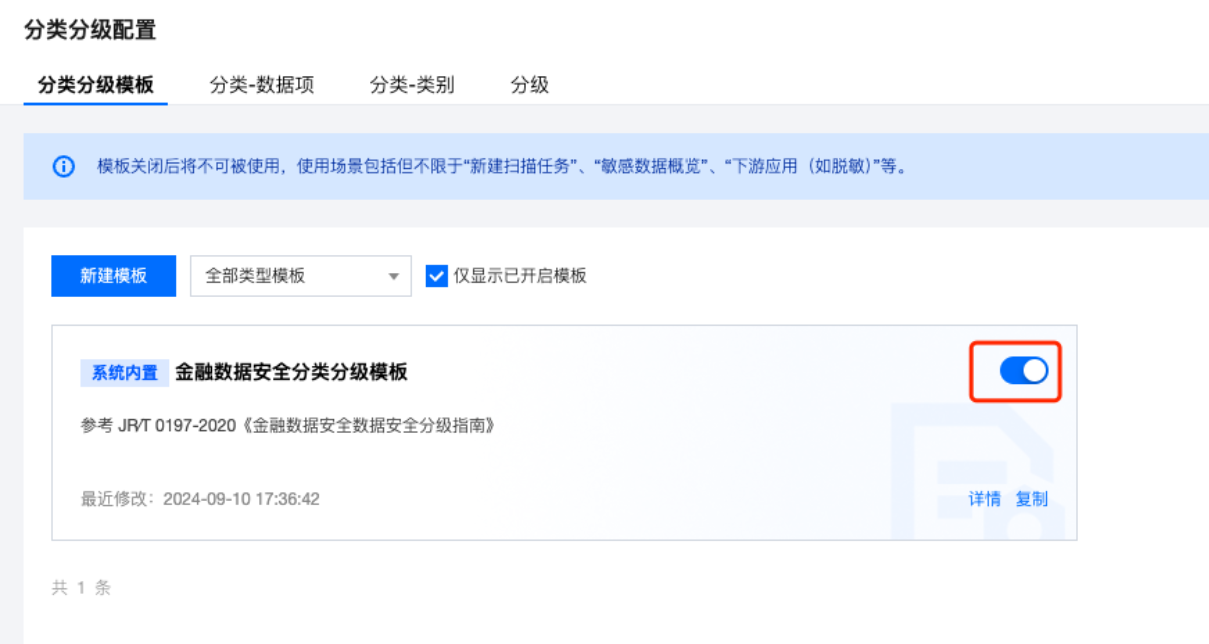
分类分级模板将分类,分级以及识别规则整合起来,实现某个业务场景下的敏感数据识别规则集。在 WeData 中,最终是按照分类分级模板粒度执行数据敏感识别的。为了方便快速使用,内置了5种分类分级模板,如:JR/T 0197-2020《金融数据安全数据安全分级指南》。
说明:
模板只能有一个生效,需要开启模板。
模板关闭后将不可被使用,使用场景包括但不限于“新建扫描任务”、“敏感数据概览”、“下游应用(如脱敏)”等。
1. 进入分类分级配置 > 分类分级模板页面,点击开关按钮生效模板:
2. 单击新建模板进入编辑模板界面,您可编辑模板。
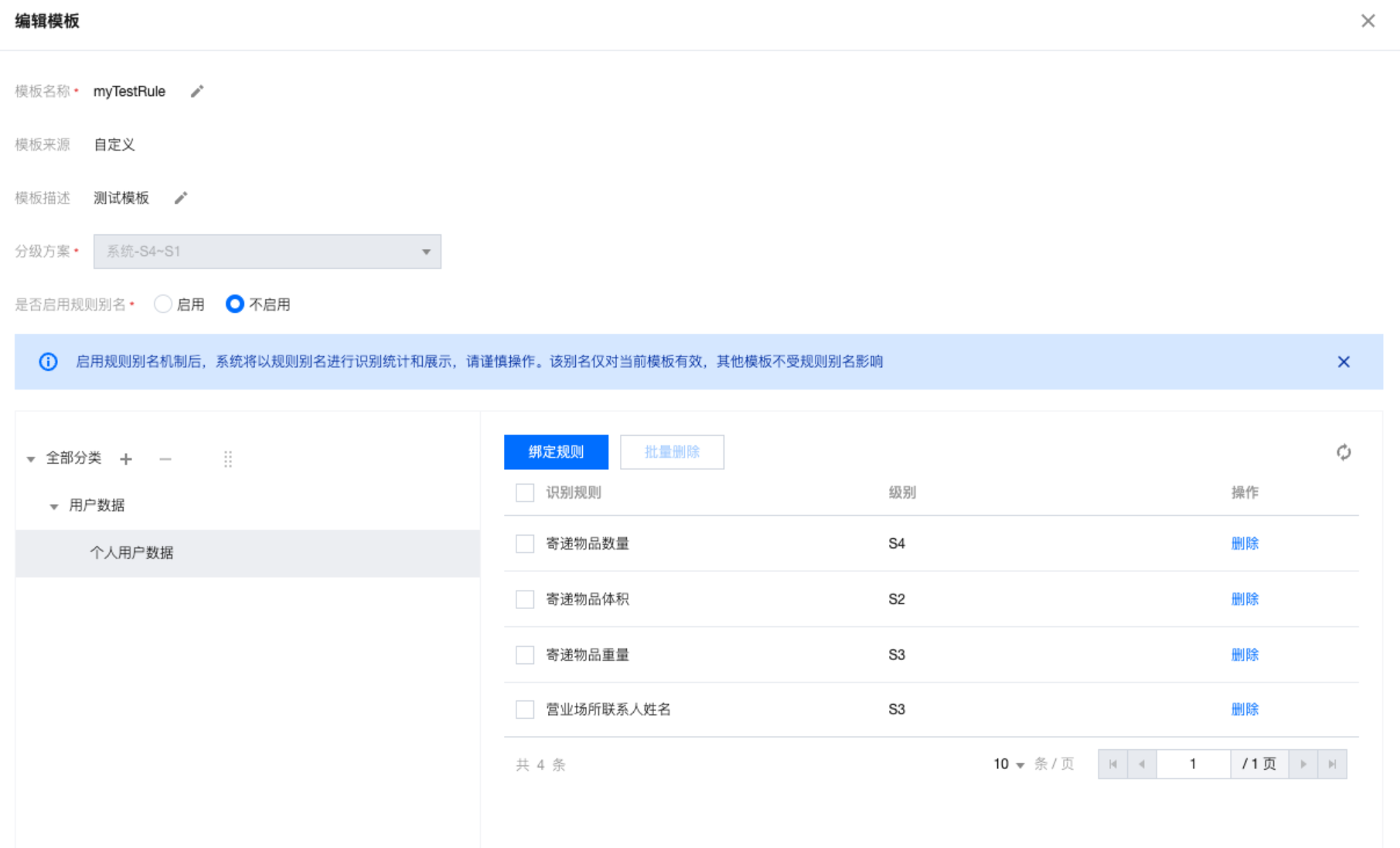
信息 | 详情 |
模板名称 | 填写模板名称,可自定义填写。 |
模板描述 | 简单对模板描述。 |
分级方案 | 选择分级方案。 |
是否启用规则别名 | 启用规则别名机制后,系统将以规则别名进行识别统计和展示,请谨慎操作。该别名仅对当前模板有效,其他模板不受规则别名影响。 核心场景:主要用于内置的规则,用户可根据需要修改名称。 |



