HASH JOIN 是列存只读分析实例中常见的连接算法,分为 Build 和 Probe 两个阶段。当 Probe 阶段数据量较大,而 JOIN 后输出数据较少时,开启 Runtime Filter 可提前过滤无效数据,从而降低 Probe 数据规模并提升查询性能。
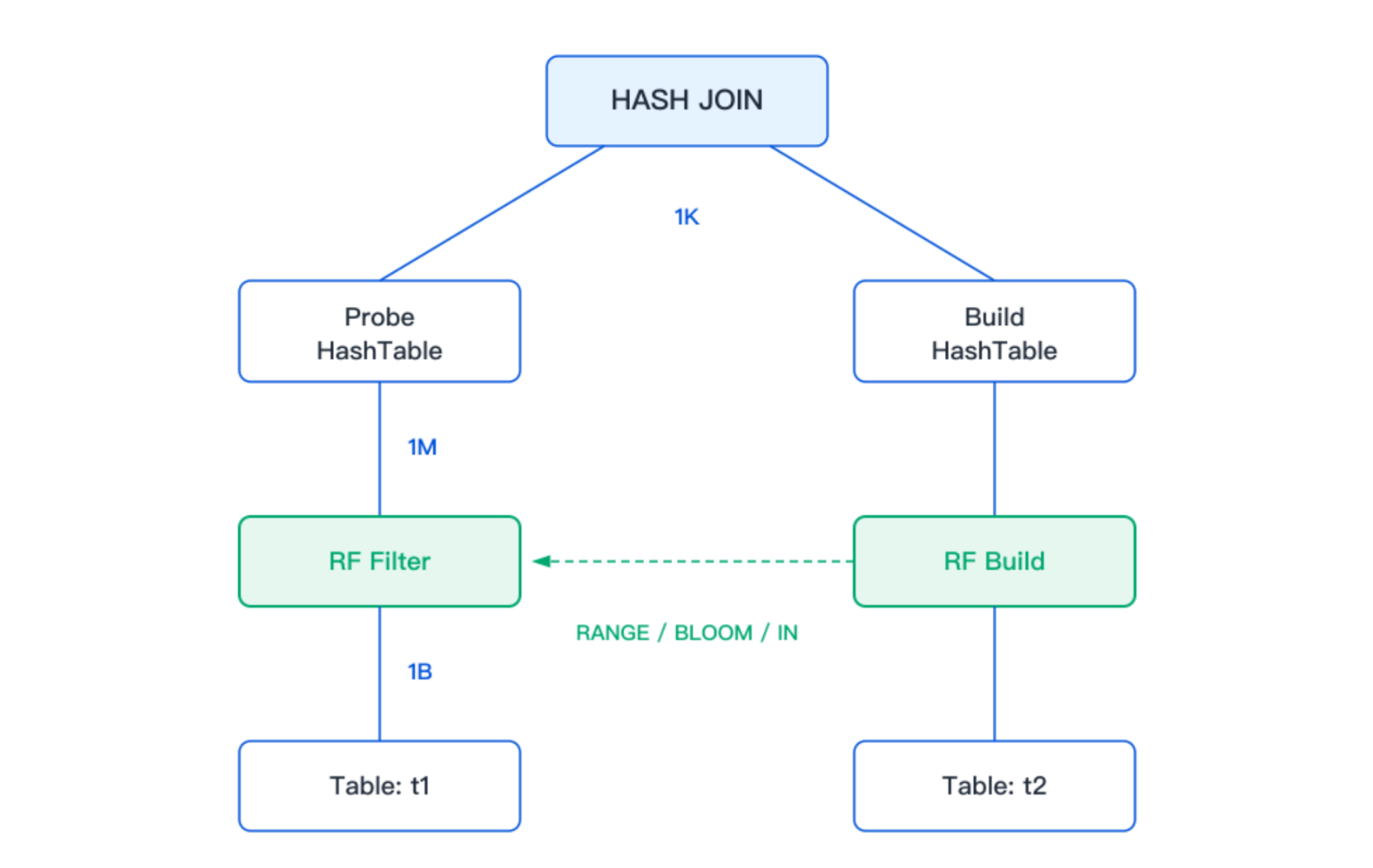
列存只读分析实例中的 Runtime Filter 由两部分构成:RF Build 位于 HASH JOIN 的 Build 端,负责构建过滤器;RF Filter 位于 Probe 端的 TableScan 上,负责提前过滤数据。
Runtime Filter 类型
列存只读分析实例根据 JOIN 中 Build 端的数据是否经过 Shuffle,将 Runtime Filter 分为 Local Runtime Filter 和 Global Runtime Filter 两类。
Local Runtime Filter
Local Runtime Filter 适用于 JOIN 数据在 Build 端未发生 Shuffle 的场景。当前节点构建的过滤器已可满足 Probe 端的需要,无需跨节点传输,可直接将过滤器传递给同一计划中的 Probe 侧使用。
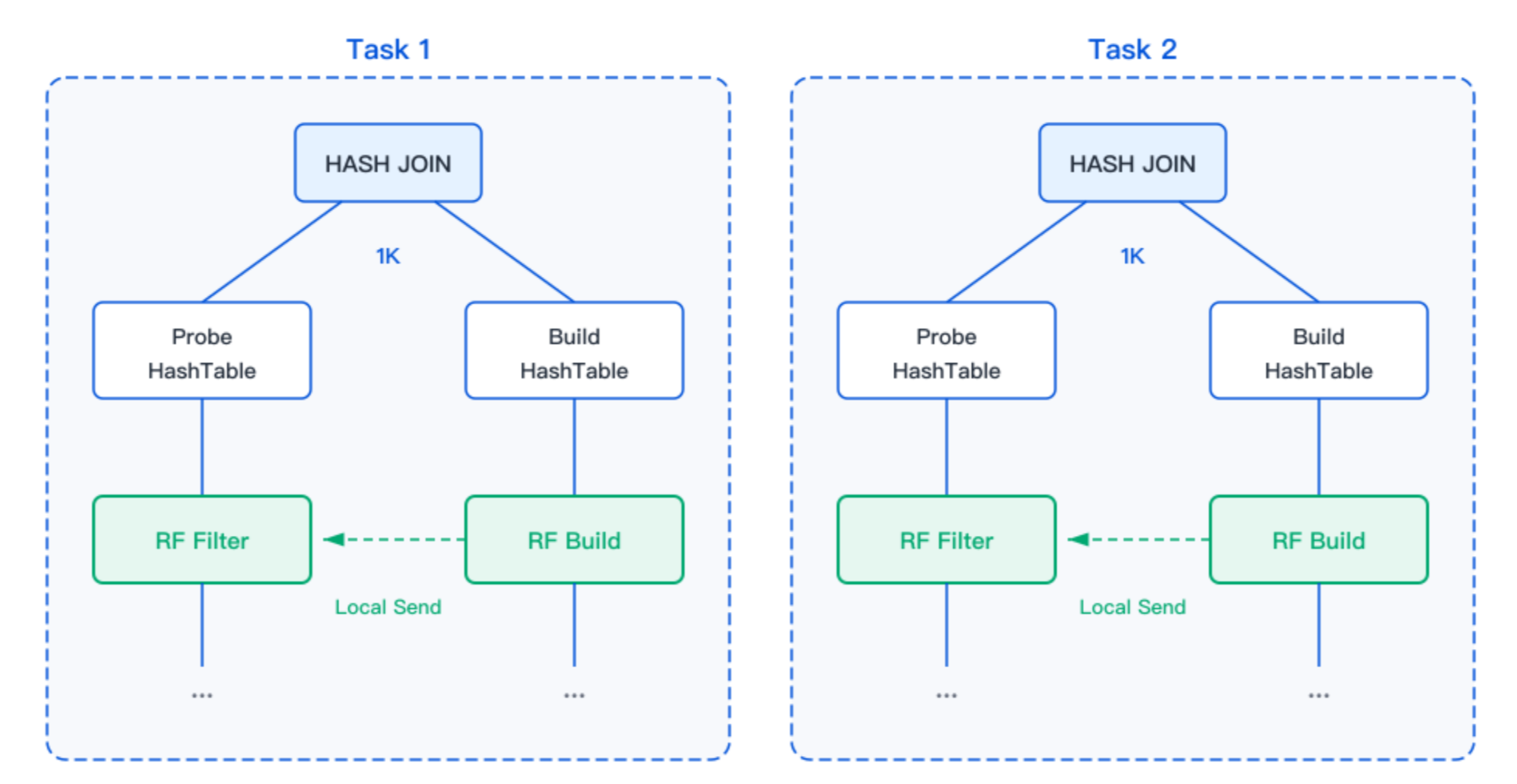
如上图所示,当 JOIN 的 Build 表未经 Shuffle 时,同一计划中的 RF Build 算子将构建的过滤器直接发送给计划中对应的 RF Filter 算子。
Global Runtime Filter
Global Runtime Filter 适用于 JOIN 数据在 Build 端经过 Shuffle 分布到不同节点的场景。此时单个节点构建的过滤器无法覆盖完整数据集,必须接收其他节点的过滤器并合并后再使用。
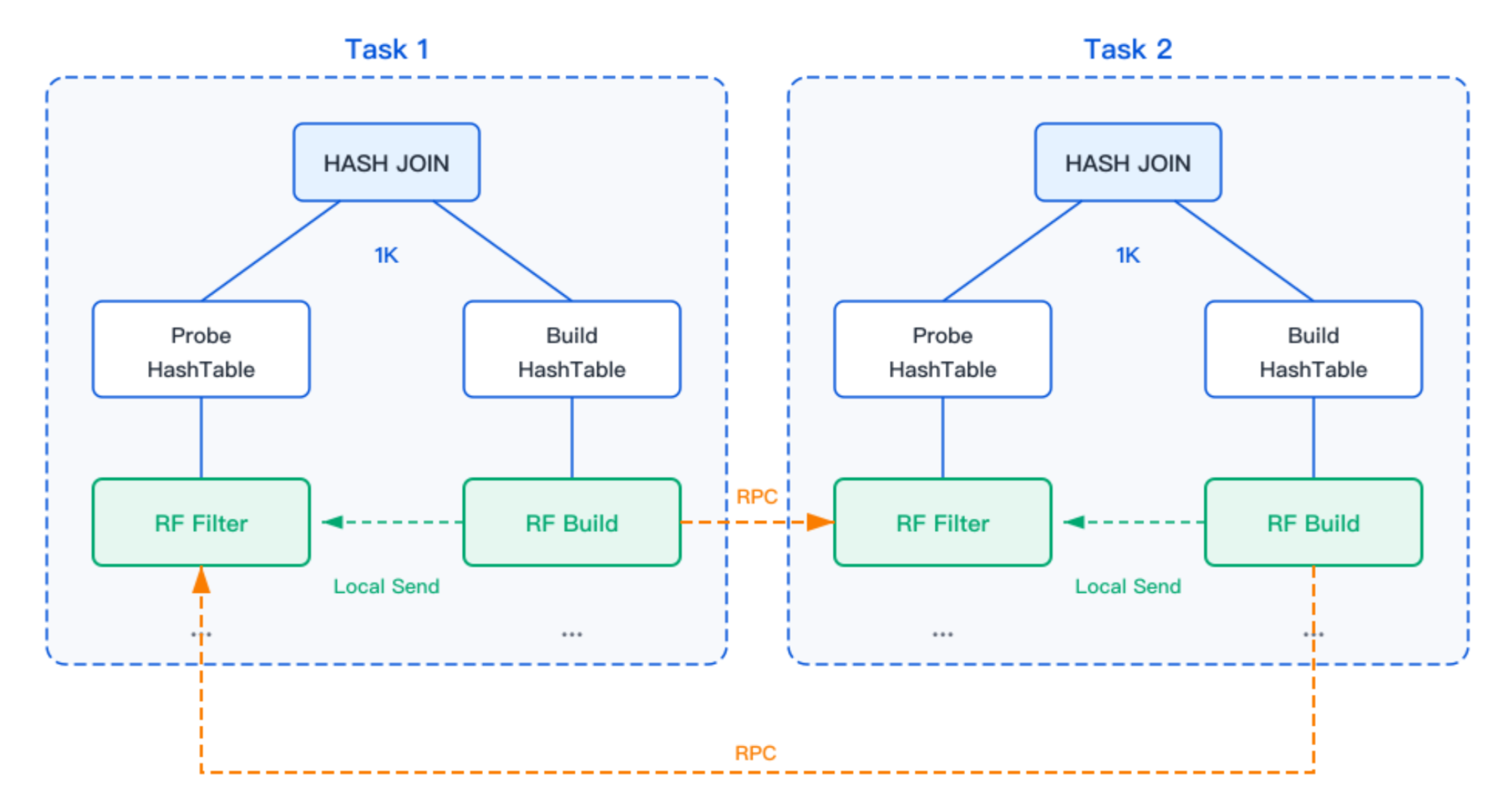
如上图所示,当 JOIN 的 Build 表数据经过 Shuffle 后,当前计划中 RF Build 算子构建的过滤器不完整,需接收并合并其他相同计划节点构建的过滤器,再将合并后的过滤器下发给 Probe 端使用。
过滤器类型
列存只读分析实例会根据数据分布特征,为 JOIN 自动选择一种或多种过滤算法。当前支持以下四种过滤器类型。
Bloom Filter
Bloom Filter 是经典的过滤器算法,通过多个哈希函数判断数据是否可能存在。过滤器的大小通常取决于数据的 NDV(Number of Distinct Values)。Bloom Filter 存在一定的误判率(False Positive),但误判的数据会在 JOIN 的 Probe 阶段被进一步过滤掉,不影响查询结果正确性。
MIN_MAX Filter
MIN_MAX Filter 收集 Build 端数据的最大值和最小值。过滤时判断数据是否落在该区间,不在区间内的数据会被直接过滤。当 Build 端数据在某个区间内集中分布时,MIN_MAX Filter 过滤效果较好。
IN Filter
IN Filter 适用于 NDV 较小的场景。构建时将 Build 端该列的所有值打包后发送到 Probe 端进行精确匹配。
TOPN_FILTER
TOPN_FILTER 适用于包含 TopN 算子下推的 JOIN 场景。构建时收集 TopN 结果集中 JOIN KEY 的值集合,发送到 Probe 端用于提前过滤不会进入最终结果的数据。
开启或关闭 Runtime Filter
分析实例默认开启 Runtime Filter。可通过以下系统变量控制开关。
-- 开启 Runtime FilterSET libra_enable_runtime_filter = ON;-- 关闭 Runtime FilterSET libra_enable_runtime_filter = OFF;
开启后,优化器会基于代价评估 JOIN,在符合条件时自动启用 Runtime Filter。如需强制对所有 JOIN 启用 Runtime Filter,可关闭基于代价的分配策略。
SET libra_enable_cost_based_runtime_filter = OFF;
查看 Runtime Filter 执行计划
使用
EXPLAIN 查看带 Runtime Filter 的执行计划。计划中通过 Mode: LOCAL 或 Mode: GLOBAL 标识过滤器类型。以下示例为 Local Runtime Filter 计划,HASH JOIN 的 Build 侧与 Probe 侧之间没有数据重分布,在 JOIN 上分配了三种 Runtime Filter。
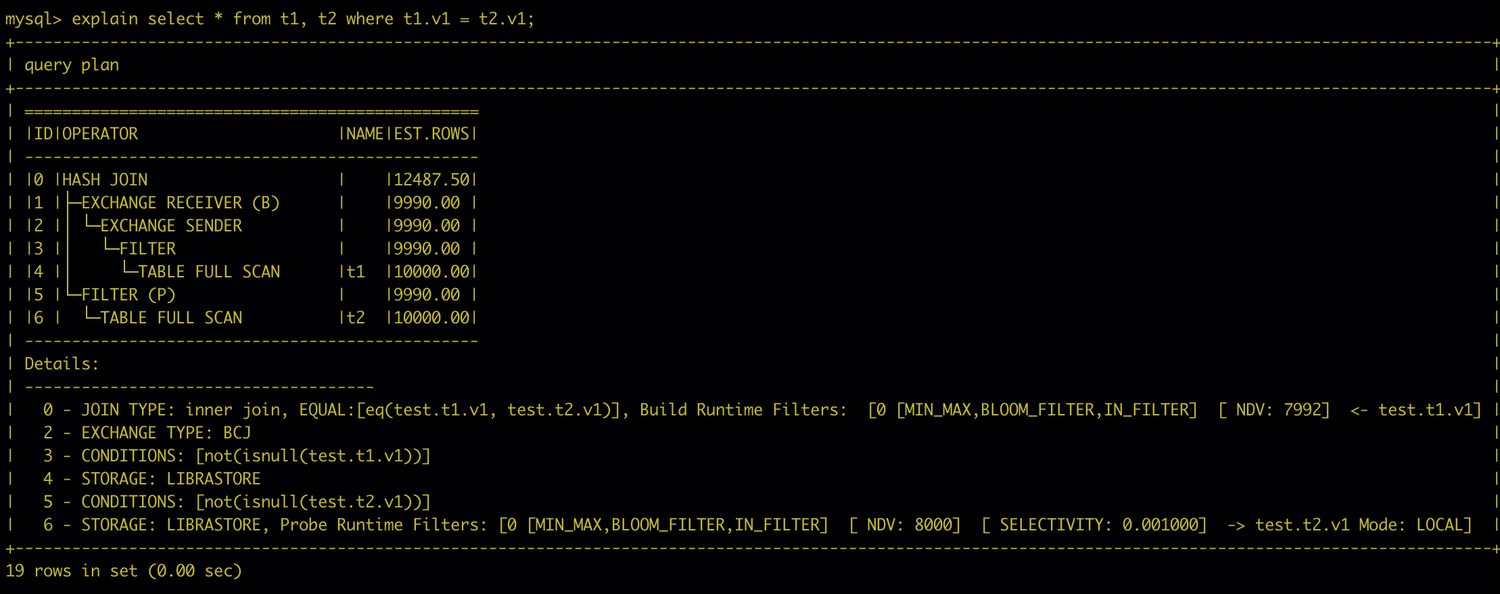
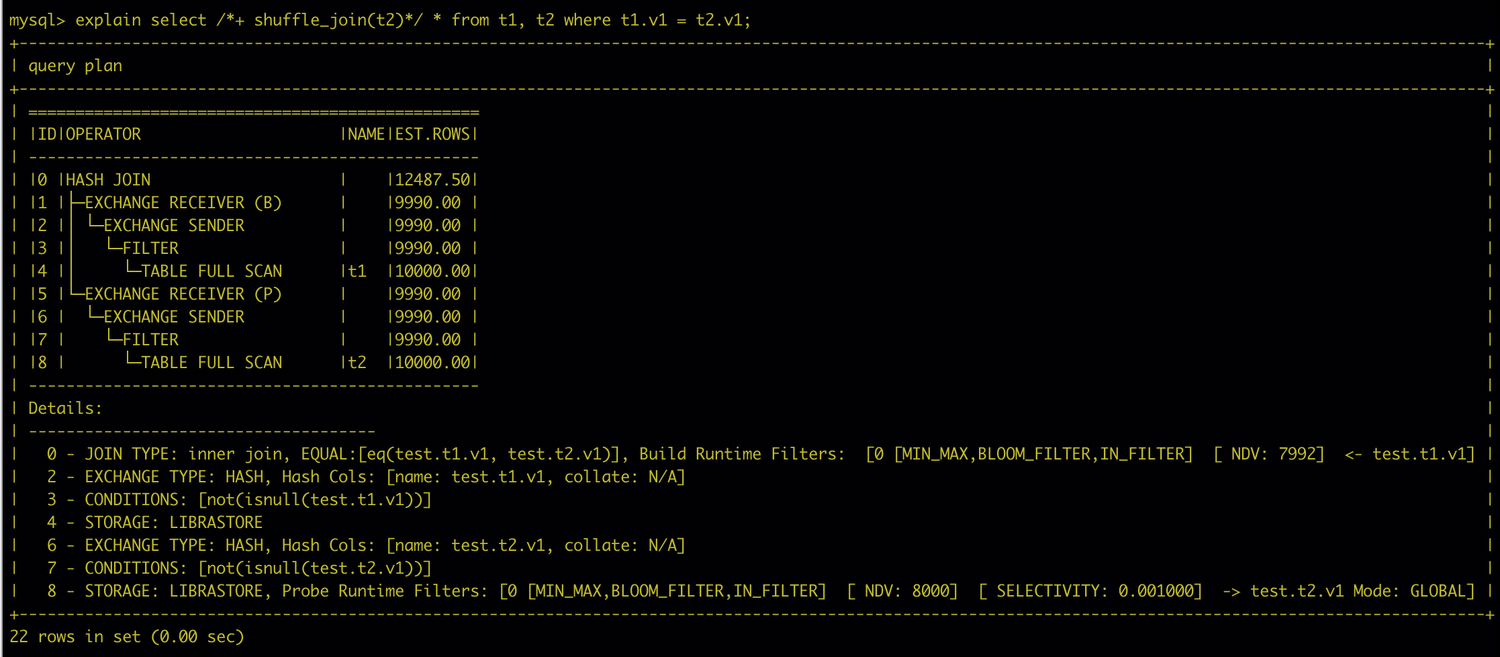
以下示例为 Global Runtime Filter 计划。Build 侧与 Probe 侧之间存在数据重分布,Runtime Filter 可在数据跨节点传输前提前过滤,减少网络传输量和后续 JOIN 开销。
调整 Runtime Filter 参数
Runtime Filter 提供以下系统变量用于精细化控制。
libra_enable_runtime_filter
控制 Runtime Filter 功能的总开关。
属性 | 说明 |
参数类型 | BOOL |
默认值 | ON |
取值范围 | ON:开启 Runtime Filter;OFF:关闭 Runtime Filter |
作用域 | Global & Session |
支持 SET_VAR Hint | 是 |
libra_runtime_filter_type
控制可供优化器选择的 Runtime Filter 类型。支持多个类型组合,以英文逗号分隔。
属性 | 说明 |
参数类型 | VARCHAR |
默认值 | MIN_MAX,BLOOM_FILTER,IN_FILTER,TOPN_FILTER |
取值范围 | BLOOM_FILTER:构建 JOIN Build 端 JOIN KEY 的 Bloom Filter 过滤 Probe 端数据;MIN_MAX:构建 JOIN Build 端 JOIN KEY 的最大最小值过滤 Probe 端数据;IN_FILTER:构建 JOIN Build 端 JOIN KEY 的值列表过滤 Probe 端数据;TOPN_FILTER:针对 TopN 下推场景构建过滤器;空字符串:关闭 Runtime Filter |
作用域 | Global & Session |
支持 SET_VAR Hint | 否 |
注意:
该参数取值为字符串,设置时需使用单引号包裹。示例:
SET libra_runtime_filter_type = 'MIN_MAX,BLOOM_FILTER';。libra_enable_cost_based_runtime_filter
控制是否启用基于代价的 Runtime Filter 分配策略。关闭后会对所有符合条件的 JOIN 生成完整的 Runtime Filter。
属性 | 说明 |
参数类型 | BOOL |
默认值 | ON |
取值范围 | ON:开启基于代价的分配策略;OFF:关闭基于代价的分配策略 |
作用域 | Global & Session |
支持 SET_VAR Hint | 是 |
libra_max_in_runtime_filter_ndv
控制在基于代价的分配策略下,生成 IN_FILTER 类型过滤器时 Build 端允许的最大 NDV。NDV 超过该值时,优化器不会选择 IN_FILTER。
属性 | 说明 |
参数类型 | INT |
默认值 | 1024 |
取值范围 | [0, 9223372036854775807] |
作用域 | Global & Session |
支持 SET_VAR Hint | 是 |
libra_runtime_filter_max_wait_ms
控制 Probe 端等待 Runtime Filter 构建完成的最长时间,单位为毫秒。超过该时间后,Probe 端不再等待,直接以当前已到达的过滤器开始执行。
属性 | 说明 |
参数类型 | INT |
默认值 | 1000 |
取值范围 | [0, 9223372036854775807] |
作用域 | Global & Session |
支持 SET_VAR Hint | 是 |
libra_runtime_filter_max_bloom_filter_size
控制单个 Bloom Filter 过滤器的最大字节数。估算的过滤器大小超过该值时,优化器不会生成 Bloom Filter。
属性 | 说明 |
参数类型 | INT |
默认值 | 1073741824(1GB) |
取值范围 | [0, 9223372036854775807] |
作用域 | Global & Session |
支持 SET_VAR Hint | 是 |



