说明
该功能适用于 Doris 1.2.2及后续版本。
用户经常设置不合适的 Bucket,导致各种问题,这里提供一种方式,来自动设置分桶数。
实现
以往创建分桶时需要手动设定分桶数,而自动分桶推算功能使 Doris 可以动态地推算分桶个数,使得分桶数始终保持在一个合适范围内,让用户不再操心桶数的细枝末节。 为了方便阐述该功能,该部分会将桶拆分为两个时期的桶,即初始分桶以及后续分桶;这里的初始和后续只是本文为了描述清楚该功能而采用的术语,Doris 分桶本身没有初始和后续之分。 BUCKET_DESC 非常简单,但是需要指定分桶个数。在自动分桶推算功能上,BUCKET_DESC 的语法直接将分桶数改成"Auto",并新增一个 Properties 配置即可:
-- 旧版本指定分桶个数的创建语法DISTRIBUTED BY HASH(site) BUCKETS 20-- 新版本使用自动分桶推算的创建语法DISTRIBUTED BY HASH(site) BUCKETS AUTO properties("estimate_partition_size" = "100G")
新增的配置参数 estimate_partition_size 表示一个单分区的数据量。该参数是可选的,如果没有给出则 Doris 会将 estimate_partition_size 的默认值取为 10GB。 从上文中已经得知,一个分桶在物理层面就是一个Tablet,为了获得最好的性能,建议 Tablet 的大小在 1GB - 10GB 的范围内。那么自动分桶推算是如何保证 Tablet 大小处于这个范围内的呢?主要原则如下:
若是整体数据量较小,则分桶数不要设置过多。
若是整体数据量较大,则应使桶数跟总的磁盘块数相关,充分利用每台 BE 机器和每块磁盘的能力。
初始分桶推算
从原则出发,理解自动分桶推算功能的详细逻辑就变得简单了,首先来看初始分桶:
1. 先根据数据量得出一个桶数 N。首先使用 estimate_partition_size 的值除以 5(按文本格式存入 Doris 中有 5 比 1 的数据压缩比计算),得到的结果为:
(, 100MB),则取 N=1
[100MB, 1GB),则取 N=2
[1GB, ),则每GB一个分桶
2. 根据 BE 节点数以及每个 BE 节点的磁盘容量,计算出桶数 M。其中每个 BE 节点算 1,每 50G 的磁盘容量算 1,那么 M 的计算规则为: M = BE 节点数 ( 一块磁盘块大小 / 50GB) 磁盘块数 例如有 3 台 BE,每台 BE 都有 4 块 500GB 的磁盘,那么 M = 3 (500GB / 50GB) 4 = 120
3. 得到最终的分桶个数计算逻辑: 先计算一个中间值 x = min(M, N, 128), 如果 x < N并且x < BE节点个数,则最终分桶为 y 即 BE 节点个数;否则最终分桶数为 x
上述过程伪代码表现形式为:
int N = 计算N值;int M = 计算M值;int y = BE节点个数;int x = min(M, N, 128);if (x < N && x < y) {return y;}return x;
有了上述算法,再引入一些例子来更好地理解这部分逻辑:
case1:数据量 100 MB,10 台 BE 机器,2TB *3 块盘数据量 N = 1BE 磁盘 M = 10* (2TB/50GB) * 3 = 1230x = min(M, N, 128) = 1最终: 1case2:数据量 1GB, 3 台 BE 机器,500GB *2块盘数据量 N = 2BE 磁盘 M = 3* (500GB/50GB) * 2 = 60x = min(M, N, 128) = 2最终: 2case3:数据量100GB,3台BE机器,500GB *2块盘数据量N = 20BE磁盘M = 3* (500GB/50GB) * 2 = 60x = min(M, N, 128) = 20最终: 20case4:数据量500GB,3台BE机器,1TB *1块盘数据量N = 100BE磁盘M = 3* (1TB /50GB) * 1 = 60x = min(M, N, 128) = 63最终: 63case5:数据量500GB,10台BE机器,2TB *3块盘数据量 N = 100BE磁盘 M = 10* (2TB / 50GB) * 3 = 1230x = min(M, N, 128) = 100最终: 100case 6:数据量1TB,10台BE机器,2TB *3块盘数据量 N = 205BE磁盘M = 10* (2TB / 50GB) * 3 = 1230x = min(M, N, 128) = 128最终: 128case 7:数据量500GB,1台BE机器,100TB *1块盘数据量 N = 100BE磁盘M = 1* (100TB / 50GB) * 1 = 2048x = min(M, N, 128) = 100最终: 100case 8:数据量1TB, 200台BE机器,4TB *7块盘数据量 N = 205BE磁盘M = 200* (4TB / 50GB) * 7 = 114800x = min(M, N, 128) = 128最终: 200
可以看到,详细逻辑与原则是匹配的。
后续分桶推算
上述是关于初始分桶的计算逻辑,后续分桶数因为已经有了一定的分区数据,可以根据已有的分区数据量来进行评估。后续分桶数会根据最多前 7 个分区数据量的 EMA(短期指数移动平均线)值,作为 estimate_partition_size 进行评估。此时计算分桶有两种计算方式,假设以天来分区,往前数第一天分区大小为 S7,往前数第二天分区大小为 S6,依次类推到 S1。
1. 如果 7 天内的分区数据每日严格递增,则此时会取趋势值。有6个 delta 值,分别是:
S7 - S6 = delta1,S6 - S5 = delta2,...S2 - S1 = delta6
由此得到 ema(delta) 值: 那么,今天的 estimate_partition_size = S7 + ema(delta)
2. 非第一种的情况,此时直接取前几天的 EMA 平均值:
今天的estimate_partition_size = EMA(S1, ..., S7)
根据上述算法,初始分桶个数以及后续分桶个数都能被计算出来。跟之前只能指定固定分桶数不同,由于业务数据的变化,可能前面分区的分桶数和后面分区的分桶数不一样,这对用户是透明的,用户无需关心每一分区具体的分桶数是多少,而这一自动推算的功能会让分桶数更加合理。
最佳实践
创建使用自动分桶表
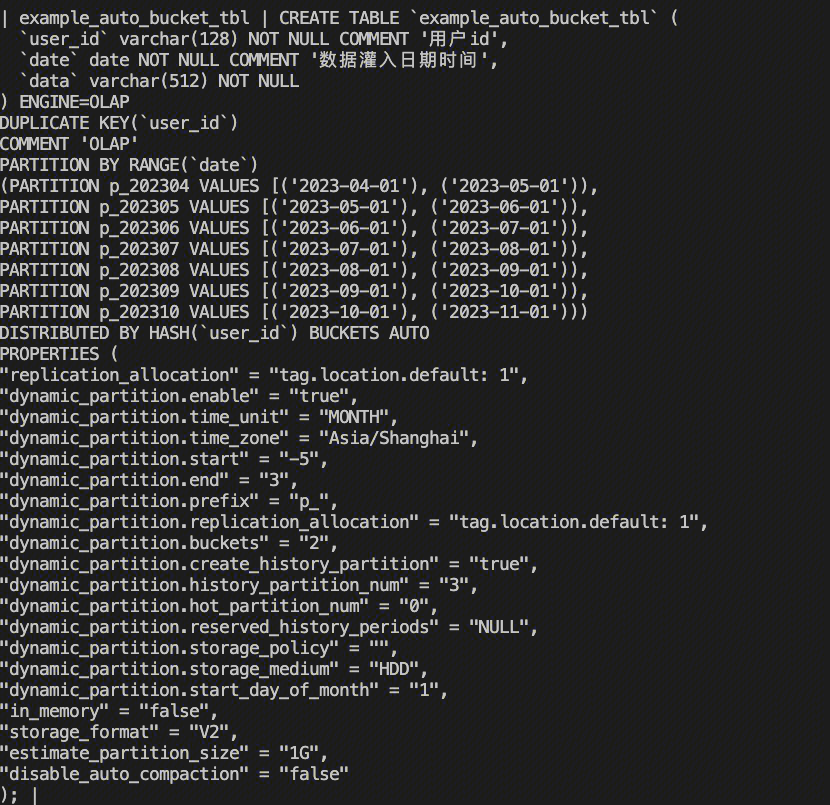
CREATE TABLE IF NOT EXISTS example_auto_bucket_tbl (user_idVARCHAR(128) NOT NULL COMMENT "用户id",dateDATE NOT NULL COMMENT "数据灌入日期时间",datavarchar(512) NOT NULL ) ENGINE=OLAP DUPLICATE KEY(user_id) PARTITION BY RANGE(date)() DISTRIBUTED BY HASH(user_id) BUCKETS AUTO PROPERTIES ( "replication_num" = "1", # 开启动态分区 "dynamic_partition.enable" = "true", # 按月进行动态分区 "dynamic_partition.time_unit" = "MONTH", # 保留5个历史分区 "dynamic_partition.start" = "-5", # 提前创建10个未来分区 "dynamic_partition.end" = "3", # 分区命名前缀 "dynamic_partition.prefix" = "p_", # 开启创建历史分区 "dynamic_partition.create_history_partition" = "true", # 创建3个历史分区 "dynamic_partition.history_partition_num" = "3", # 预计分区的数据量 "estimate_partition_size" = "1G" );
可以看到,在创建表后,Doris系统自动为每个分区设置的分桶数量为2。
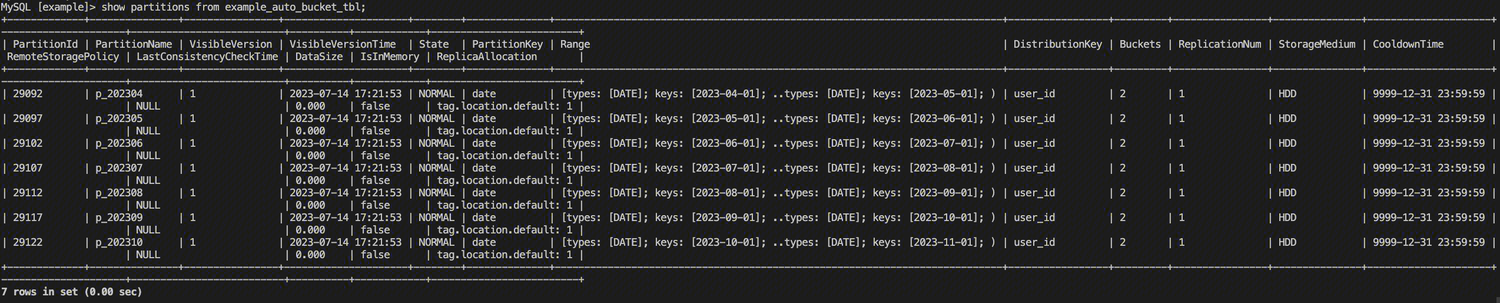
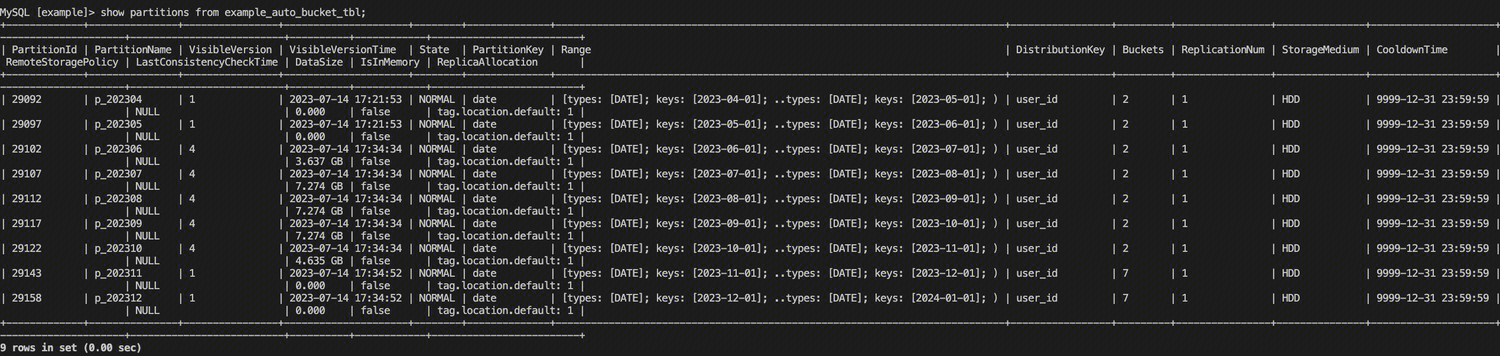
接下来我们向表内导入一定数量的数据,之后调整 dynamic_partition.end 参数,让 Doris 自动创建新的分区。查看新分区的分桶情况,可以看到新创建的分区的分桶数量变为7。
关闭自动分桶功能
临时关闭:关闭动态分区
ALTER TABLE example_auto_bucket_tbl SET(# 关闭动态分区"dynamic_partition.enable" = "false");
永久关闭:关闭动态分区后,修改表的分桶数量关闭
# 关闭动态分区后,修改表的分桶数量alter table example_auto_bucket_tbl modify DISTRIBUTION DISTRIBUTED BY HASH(`user_id`) BUCKETS 16;
需要注意两种操作的效果:
临时关闭后,如果重新打开动态分区功能,动态分区新创建的分区分桶数量为 Doris 根据最近几个分区的数据量计算出的结果。
关闭动态分区后,若修改表的分桶数量,后续将无法再开启自动分桶功能。
说明
只对动态分区创建的分区生效。
开启 autobucket 之后,在 show create table 的时候看到的 schema 也是 BUCKETS AUTO。如果想要查看确切的 bucket 数,可以通过 show partitions from ${table}; 来查看。
不可以在已有表上开启自动分桶功能,自动分桶功能只能在创建表时开启。
自动分桶不会对已有分区产生影响,自动分桶只是在动态分区创建新分区时,根据历史分区数据,磁盘,doris 的 BE 节点数量等信息,通过一定的算法得出新分区的分桶数量,不会对已有的分区造成影响。



