操作场景
数据订阅 Kafka 版(当前 Kafka Server 版本为V2.6.0)中,针对 Protobuf 格式的订阅数据,可以使用 Flink 客户端(仅支持客户端类型为 DataStream API)进行消费,本场景为您提供使用 consumer-demo-tdsql-pb-flink 进行数据消费的 Demo 示例,方便您快速测试消费数据的流程,了解数据格式解析的方法。
前提条件
1. 已 创建数据消费任务。
2. 已 创建消费组。
3. 已安装 Flink 运行环境,并能够正常执行 Flink 任务。
注意事项
Demo 并不包含消费数据的用法演示,仅对数据做了打印处理,您需要在此基础上自行编写数据的处理逻辑。
目前不支持通过外网连接数据订阅的 Kafka 进行消费,只支持腾讯云内网的访问,并且订阅的数据库实例所属地域与数据消费的地域相同。
在订阅指定库/表对象(非源实例全部),并且采用 Kafka 单分区的场景中,DTS 解析增量数据后,仅将订阅对象的数据写入 Kafka Topic 中,其他非订阅对象的数据会转成空事务写入 Kafka Topic,所以在消费数据时会出现空事务。空事务的 Begin/Commit 消息中保留了事务的 GTID 信息,可以保证 GTID 的连续性和完整性。
为了保证数据可重入,DTS 订阅引入 Checkpoint 机制。消息写入 Kafka Topic 时,一般每10秒会插入一个 Checkpoint,用来标识数据同步的位点,在任务中断后再重启识别断点位置,实现断点续传。另外,消费端遇到 Checkpoint 消息会做一次 Kafka 消费位点提交,以便及时更新消费位点。
消费 Demo下载
在配置订阅任务中,TDSQL MySQL 支持的订阅数据格式为 Protobuf。Protobuf 采用二进制格式,消费效率更高。如下 Demo 中已包含 Protobuf 协议文件,无需另外下载。如果您选择自行下载 Protobuf 协议文件,请使用 Protobuf 3.X 版本进行代码生成,以便数据结构可以正确兼容。
Demo 语言 | Protobuf(TDSQL MySQL) |
Java |
Java Flink Demo 操作步骤
编译环境:Maven 包管理工具,JDK8。用户可自行选择打包工具,如下以 Maven 为例进行介绍。
运行环境:腾讯云服务器(需要与订阅实例相同地域,才能够访问到 Kafka 服务器的内网地址),安装 JRE8。
操作步骤:
1. 下载 consumer-demo-tdsql-pb-flink.zip ,然后解压该文件。
2. 进入解压后的目录,为方便使用,目录下已放置了 pom.xml 文件,用户需要修改 Flink 的版本,确保 Flink 集群的版本与 pom.xml 依赖的 Flink 的版本相同。
3. 如下代码中的 ${flink.version} 需要与集群的 Flink 版本保持一致。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala.binary.version}</artifactId><version>${flink.version}</version><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>
4. 进入 pom 文件所在的目录,使用 Maven 进行打包,也直接使用 IDEA 打包。
5. 使用 Maven 进行打包:mvn clean package。
6. 针对 Flink 客户端类型为 DataStream API 的场景,使用 Flink 客户端命令提交 job 到 Flink 集群,启动消费。
./bin/flink run consumer-demo-tdsql-pb-flink.jar --brokers xxx --topic xxx --group xxx --user xxx --password xxx --trans2sqlbrokers 为数据订阅 Kafka 的内网访问地址,topic 为数据订阅任务的订阅 topic,这两个可在 订阅详情 页查看。group、user、password 分别为消费组的名称、账号和密码,可在 消费管理 页查看。trans2sql 表示是否转换为 SQL 语句,java 代码中,携带该参数表示转换为 SQL 语句,不携带则不转换。7. 在源数据库执行 DML 语句并观察 Flink 中所提交的 job 的消费情况。
CREATE TABLE `flink_test` (`id` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,`parent_id` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,`user_id` bigint NOT NULL,`type` int NOT NULL COMMENT '1:支出 2:收入',`create_time` timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),PRIMARY KEY (`id`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC
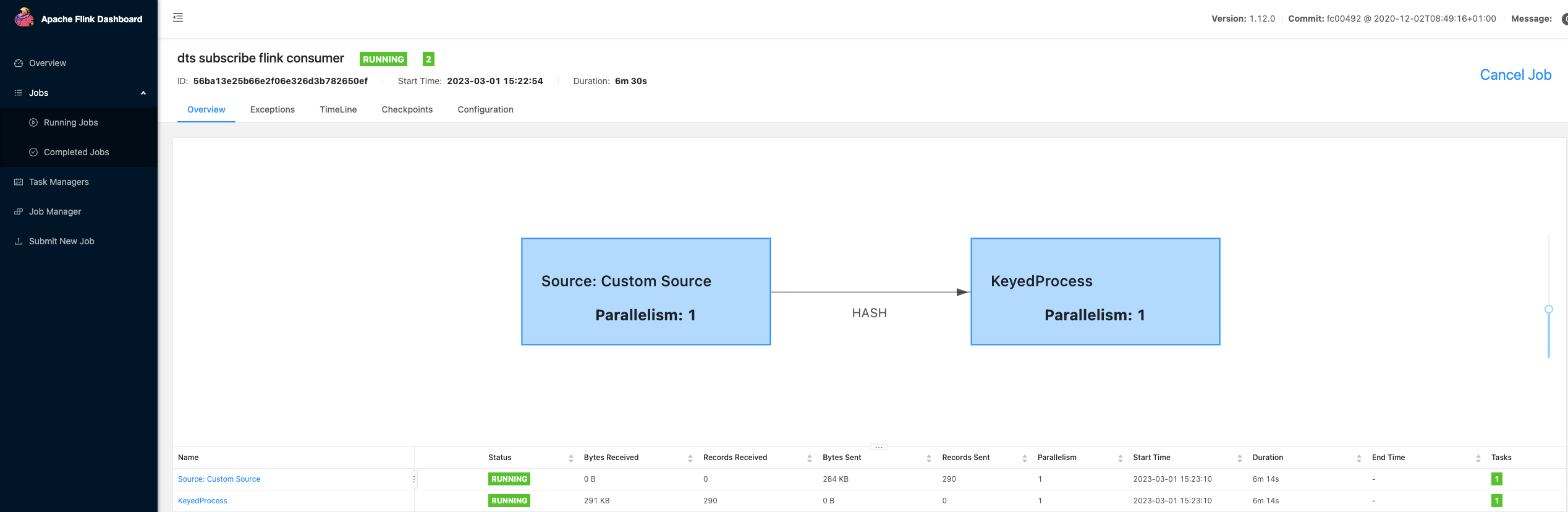
8. 观察 Flink 中提交的 job 的消费情况。

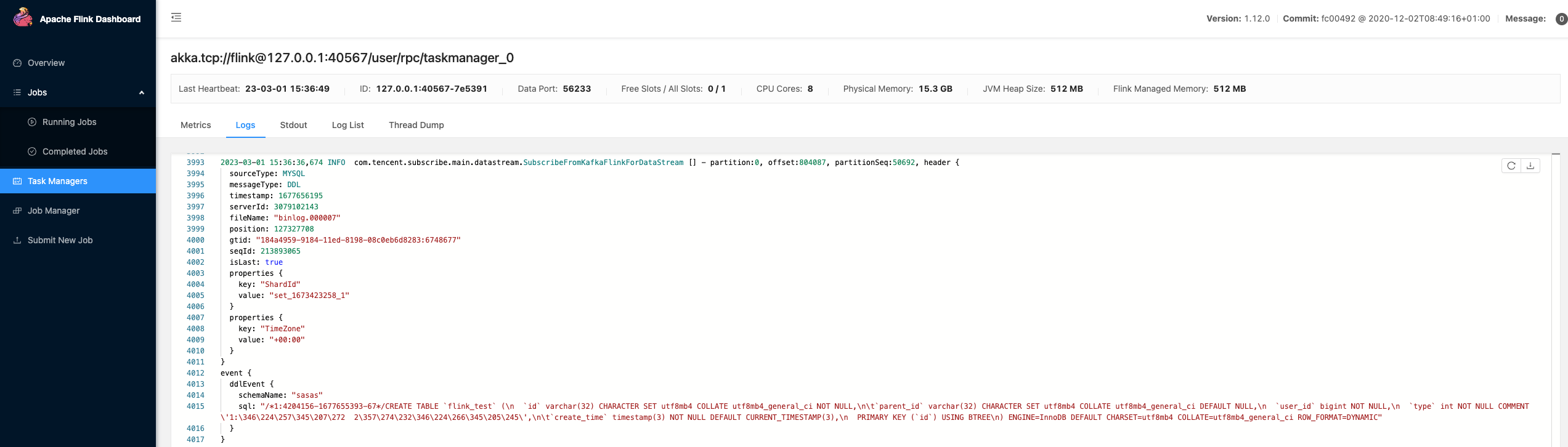
在 Task Managers 上查看具体的 task 的日志。
在 Task Managers 上查看具体的 Stdout 信息。




