Apache Kyuubi (Incubating)是一个 Thrift JDBC/ODBC 服务,目前对接了 Apache Spark 计算框架(正在对接Apache Flink计算框架以及Trino),支持多租户和分布式等特性,可以满足企业内诸如 ETL、BI 报表等多种大数据场景的应用。
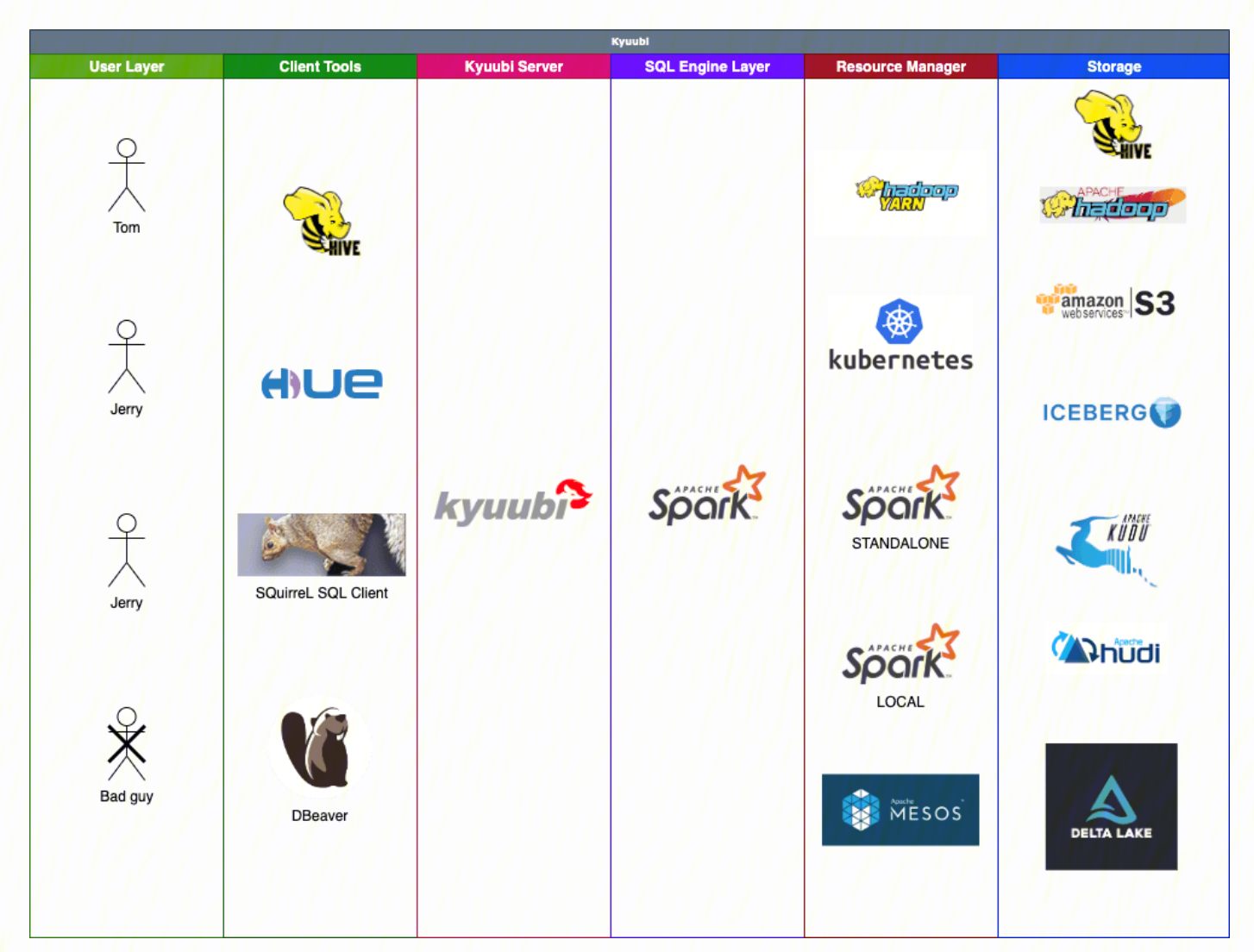
使用场景
替换 HiveServer2,轻松获得 10~100 倍性能提升。
Kyuubi 高度兼容 HiveServer2 接口及行为,支持无缝迁移。
Kyuubi 分层架构,消除客户端兼容性问题,支持无感升级。
Kyuubi 支持 Spark SQL 全链路优化及再增强,性能卓著。
高可用、多租户、细粒度权限认证各种企业级特性都有。
构建 Serverless Spark 平台。
Serverless Spark 目标绝对不是让用户调用 Spark 的 API、继续写 Spark 作业。
通过 Kyuubi 预置的 Engine 模块,用户无需理解 Spark 逻辑,入门门槛极低。
用户只需通过 JDBC 及 SQL 操作数据专注自身业务开发即可,资源弹性伸缩,0运维。
支持资源管理器(Kubernetes, YARN 等),Engine 生命周期,Spark 动态资源分配3级不同粒度全方位的资源弹性策略。
支持 YARN/Kubernetes 多种资源管理器同时调度,保障历史作业安全迁移上云。
Spark 自适应查询引擎(AQE)及 Kyuubi AQE plus,提供澎湃动力。
构建统一数据湖探索分析管理平台(kyuubi-1.5以上版本)。
支持 Spark 所有官方数据源及第三方数据源。
支持 Spark DSv2 元数据管理,直观进行数据湖构建及管理。
支持 Apache Iceberg/Hudi, DeltaLake 等所有主流数据湖框架。
一个接口一个引擎一份数据,提供统一的分析查询、数据摄取、数据湖管理平台。
批流一体,支持流式作业(Upcoming)。



