操作场景
腾讯云对运行中的 Logstash 实例,提供了多项监控指标,用以监测实例的运行情况,如 CPU、JVM、磁盘使用率等。您可以根据这些指标实时了解实例的运行状况,针对可能存在的风险及时处理,保障实例的稳定运行。本文为您介绍通过控制台查看实例监控的操作。
操作步骤
1. 登录 Elasticsearch Service 控制台,在左侧导航栏单击 Logstash 管理,进入 Logstash 管理列表页。在实例列表中,选择需要查看监控的实例,单击实例 ID/名称,进入实例基本信息页。
2. 在实例基本信息页面,切换到监控页签,即可查看实例的运行情况。
监控状态
页面展示了实例详细的指标和随时间变化的指标,可了解实例过去一段时间内的运行情况。
说明
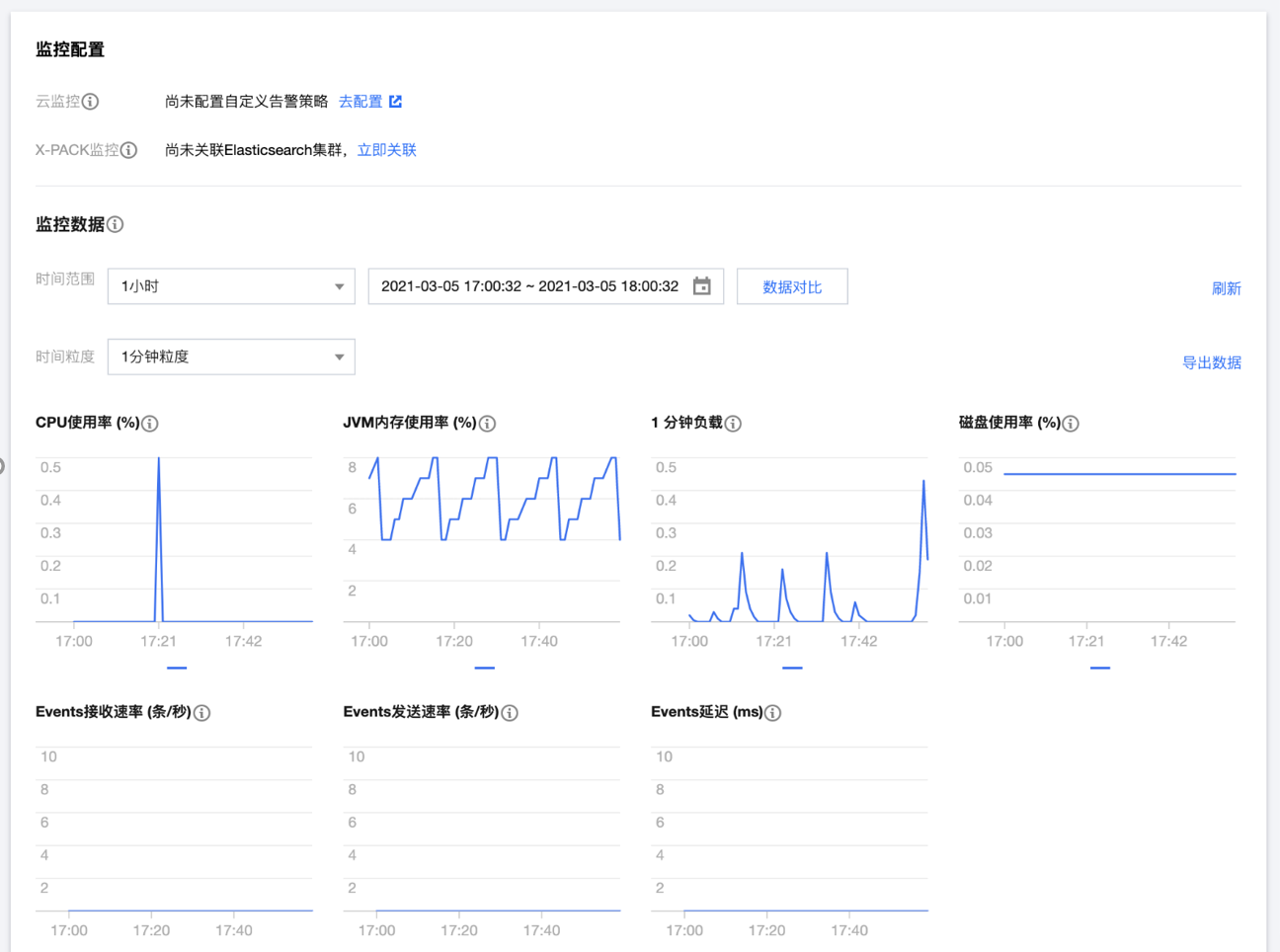
指标含义及说明
Logstash 实例一般由多个节点构成,所有指标的统计周期均为1分钟,即每1分钟对实例的指标采集1次。具体各指标含义说明如下:
监控指标 | 统计方式 | 详情 |
CPU 使用率 | 每单位统计周期内(1分钟),实例各个节点的 CPU 使用率的平均值 | 当实例各节点处理的读写任务超出节点 CPU 的负载能力时,该指标就会过高,CPU 使用率过高会导致实例节点处理能力下降,甚至宕机。您可观察该指标是持续性较高,还是临时飙升。若是临时飙升,确定是否有临时性复杂任务正在执行。 |
JVM 内存使用率 | 每单位统计周期内(1分钟),实例各个节点的 JVM 内存使用率的平均值 | 该值过高会导致实例节点 GC 频繁,甚至有出现 OOM。导致该值过高的原因,一般是节点上管道处理任务超出节点 JVM 的负载能力。您需要注意观察实例正在执行的任务,或调整实例的配置。 |
1分钟负载 | 实例1分钟所有节点的平均负载 load_1m,指标来源:Logstash 节点监控 api:_node/stats/process?pretty | load_1m 过高时,建议调大实例节点规格。 |
磁盘使用率 | 每单位统计周期内(1分钟),实例各个节点的磁盘使用率的平均值 | 磁盘使用率过高会导致 Logstash 无法正常工作。可对实例进行扩容,增加单节点的磁盘容量。 |
Events 接收速率 | Logstash 实例在统计周期内各节点 Events 接收速率的总和 | Logstash 各个节点上的所有管道每秒接收 Events 数量的总和。 |
Events 发送速率 | Logstash实例在统计周期内各节点 Events 发送速率的总和 | Logstash 各个节点上的所有管道每秒发送 Events 数量的总和。 |
Events 延迟 | Logstash 实例在统计周期内各节点 Events 处理延迟的平均值 | Logstash 节点 Events 处理延迟的平均值。 |



