腾讯云图像识别提供强大的多模态内容理解能力,支持对图片和视频的智能分析,广泛适用于图像识别、智能打标、视频内容理解等场景。
产品功能
基于不同的 AI 技术架构,图像识别产品分为两类产品形态:多模态理解模型与传统 CV 模型。
多模态理解模型
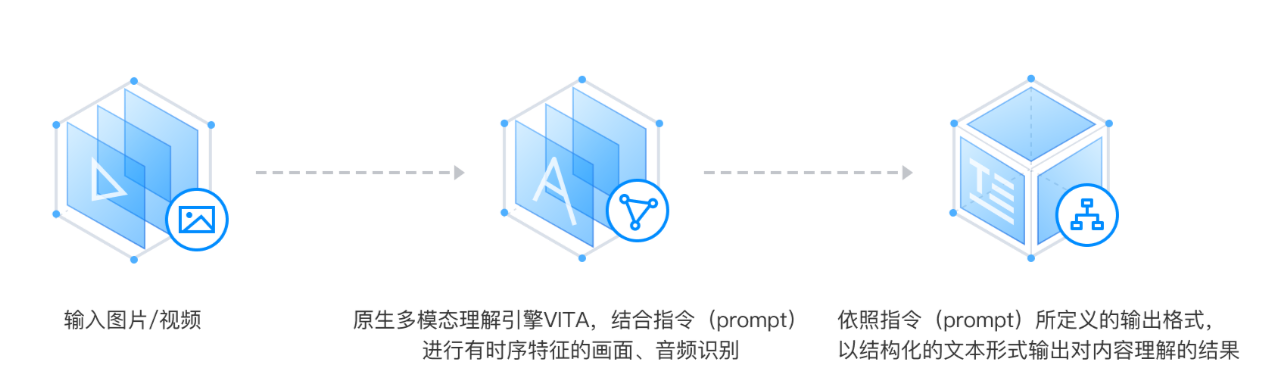
基于大模型技术打造的视觉理解产品(产品名:VITA),泛化能力强,适合开放识别场景。
输入:图片或视频 + 大模型 Prompt
输出:以文本形式输出理解的内容
传统 CV 模型
在特定业务场景积累的领域模型,适合识别需求固定且耗时要求高的场景。
商品识别:覆盖电商、广告场景下的常见商品,并输出商品所在坐标。
车辆识别:识别图片中车辆的品牌、车系、类型、颜色等,覆盖轿车、SUV、大型客车等市面常见车。
车辆识别(增强版):在车辆识别的基础上增加了车牌识别的功能。可对图片中车辆的车型和车牌进行同时识别,输出车辆的车牌信息,以及车辆品牌、车系、类型、颜色和车辆在图中的坐标等信息,覆盖轿车、SUV、大型客车等市面常见车。
文件封识别:检测图片中是否包含符合文件封(即文件、单据、资料等的袋状包装)特征的物品,可应用于物流行业对文件快递的包装审核等场景。



