点击下方链接前往控制台,只需点几次鼠标,即可创建您的首个腾讯云向量数据库实例。
DeepSeek+腾讯云向量数据库:构建高质量国产「纯血」RAG应用
方案介绍
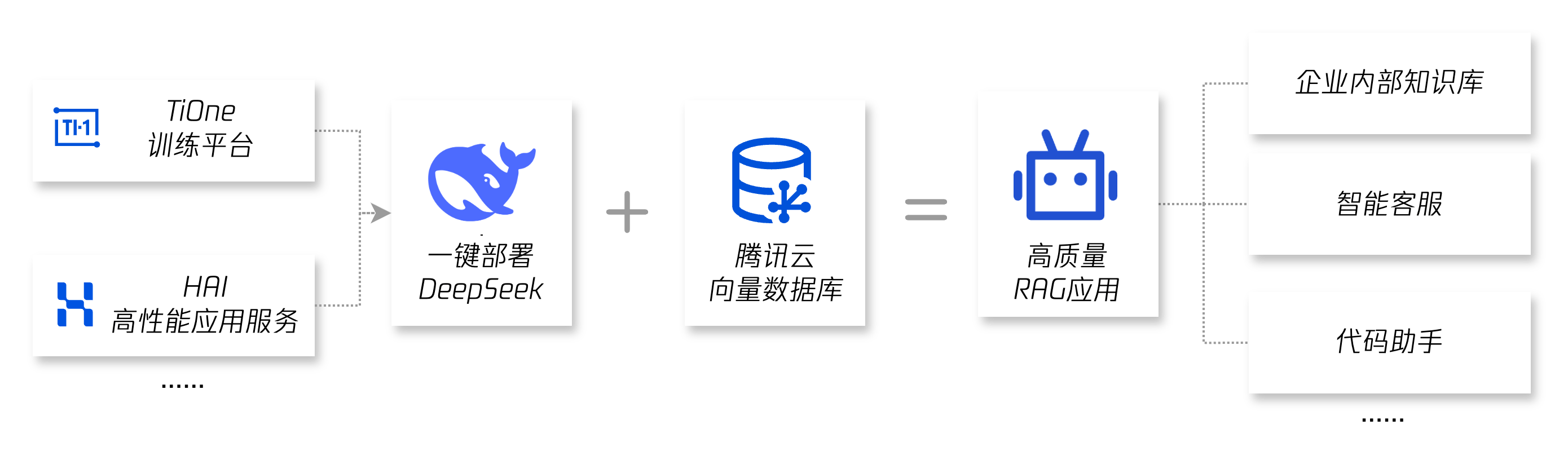
腾讯云向量数据库作为RAG应用中的核心组件,提供独特的「AI套件」功能,用户仅需上传原始文档即可快速构建知识库,并结合Deepseek模型搭建高质量RAG应用,如:企业内部知识库、内外部智能客服、代码助手等 了解详情->
产品特性
Embedding功能
数据写入/检索自动向量化,对齐传统数据库的使用体验,用户无需关注向量生成过程,极大降低使用门槛。
端到端AI套件
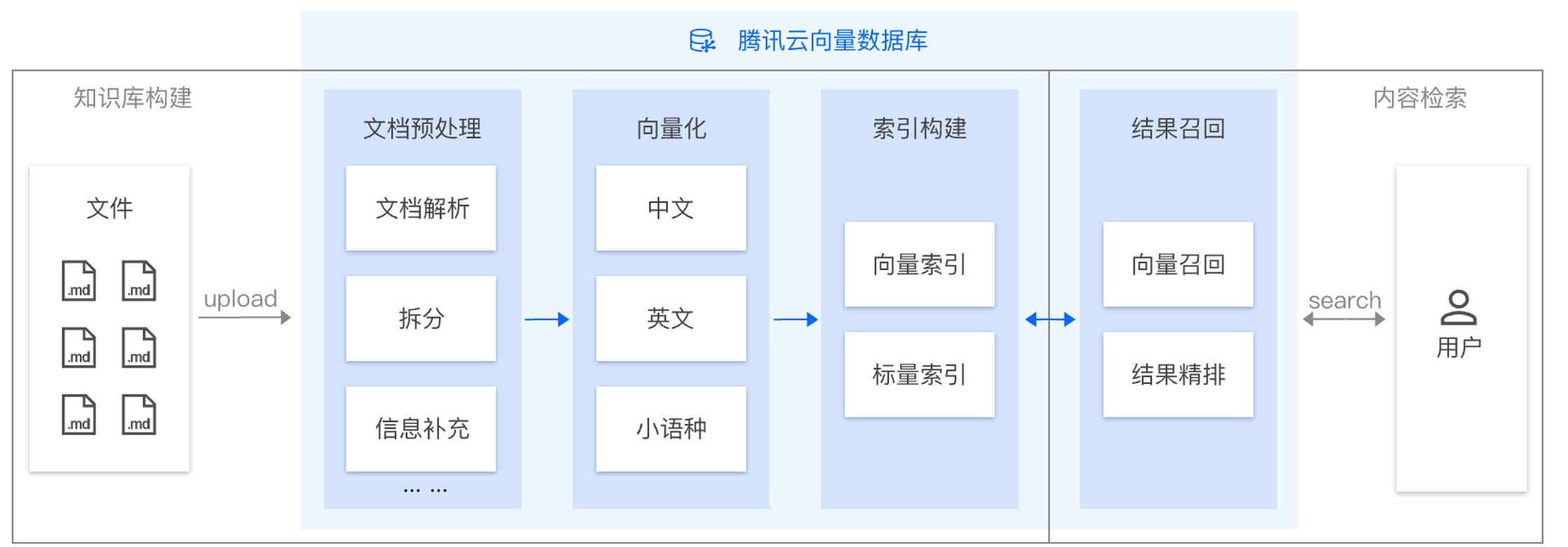
面向RAG领域中内容检索的端到端解决方案,在向量数据库中集成文档预处理、自动向量化、检索精排等功能,简化RAG中的数据处理以及检索流程,提高数据接入效率。
高性能
向量数据库 Tencent Cloud VectorDB 单索引支持千亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
高可用
向量数据库 Tencent Cloud VectorDB 提供多副本高可用特性,提高容灾能力,确保数据库在面临节点故障和负载变化等挑战时仍能正常运行。
低成本
只需按照控制台的指引简单操作,即可快速创建向量数据库实例,全流程平台托管,无需进行任何安装、部署、运维操作,减少机器成本、运维成本、人力成本开销。
稳定可靠
向量数据库 Tencent Cloud VectorDB 源自腾讯集团自研的向量检索引擎 OLAMA,近 40 个业务线上稳定运行,日均处理的搜索请求高达千亿次,服务连续性、稳定性有保障。
产品规格
快速入门
高可用版(计算型)
广州
CPU
1核内存
2G磁盘
20GB节点数量
2个
- 推荐快速入门使用
- 开箱即用的高性能向量数据库
- 向量规模:50w(768维度)
高可用版(存储型)
广州
CPU
1核内存
8G磁盘
20G节点数量
2个
- 推荐个人、小型企业开发使用
- 存储型用于数据量大、QPS低场景
- 向量规模:200w(768维度)
高性价比
高可用版(标准型)
广州
CPU
2核内存
8G磁盘
20GB节点数量
2个
- 推荐个人、小型企业开发使用
- 标准型适用于绝大多数业务场景
- 向量规模:200w(768维度)
高可用版(计算型)
广州
CPU
4核内存
8G磁盘
20GB节点数量
2个
- 推荐中大型企业开发使用
- 计算型用于QPS高、延迟敏感场景
- 向量规模:200w(768维度)
端到端AI套件
AI 套件是腾讯云向量数据库(Tencent Cloud VectorDB)提供的一站式文档检索解决方案,包含自动化文档解析、信息补充、向量化、内容检索等能力,并拥有丰富的可配置项,可显著提升文档检索的召回效果。用户仅需上传原始文档,数分钟内即可快速构建高质量专属知识库,大幅提高知识接入效率。
Embedding功能

更优体验
数据写入/检索自动向量化,对齐传统数据库的使用体验,无需关注向量生成过程
性能提升
优化GPU处理速率,性能提升5~10倍,效率更高
共享资源池
海量GPU资源池提供算力服务,按需使用,成本更优
产品架构
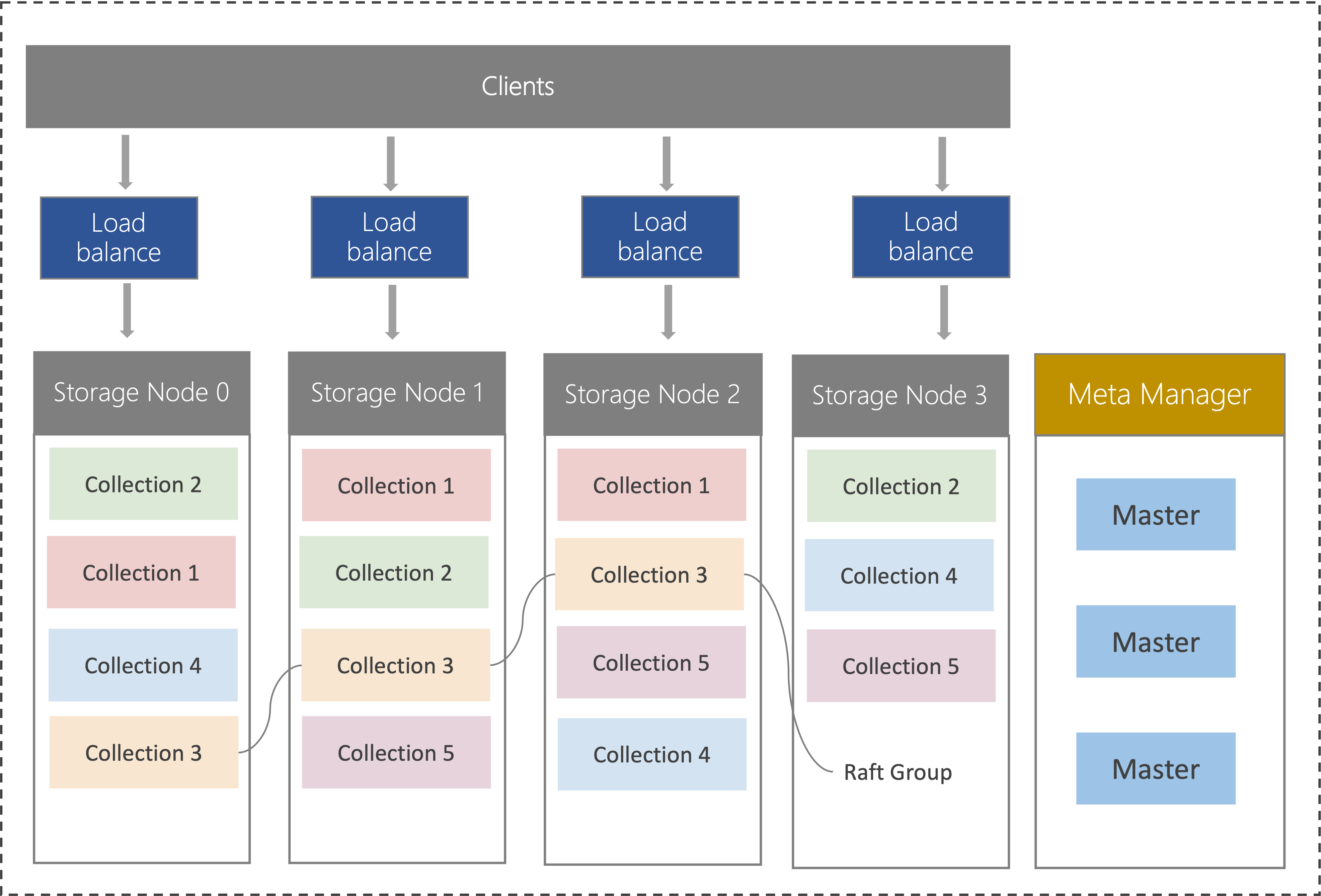
腾讯云向量数据库 Tencent Cloud VectorDB 基于腾讯集团每日处理千亿次检索的向量引擎 OLAMA,底层采用 Raft 分布式存储,通过 Master 节点进行集群管理和调度,实现系统的高效运行。同时,腾讯云向量数据库支持设置多分片和多副本,进一步提升了负载均衡能力,使得向量数据库能够在处理海量向量数据的同时,实现高性能、高可扩展性和高容灾能力。
应用场景
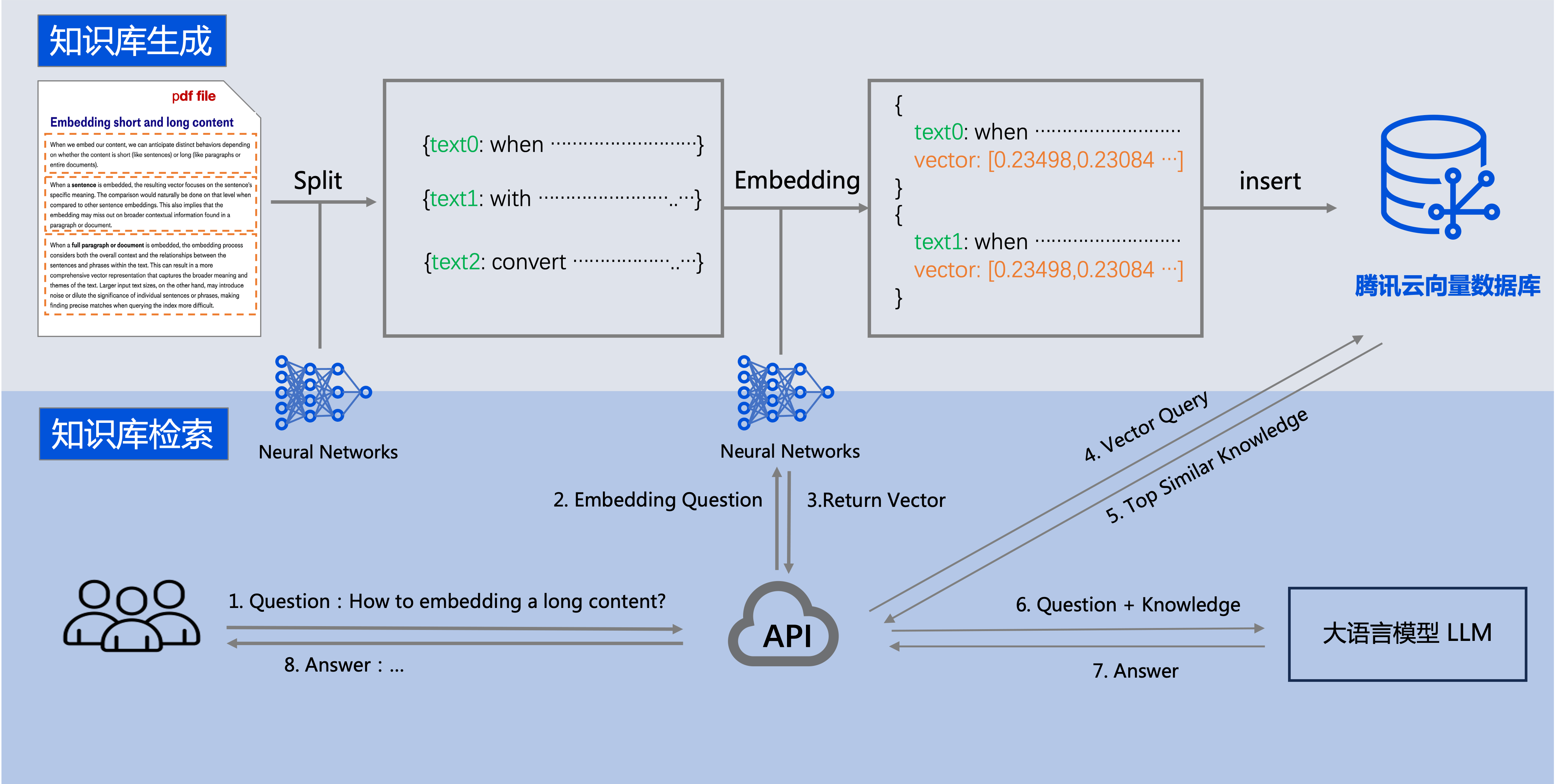
腾讯云向量数据库可以和大语言模型 LLM 配合使用。企业的私域数据在经过文本分割、向量化后,可以存储在腾讯云向量数据库中,构建起企业专属的外部知识库,从而在后续的检索任务中,为大模型提供提示信息,辅助大模型生成更加准确的答案。