引言
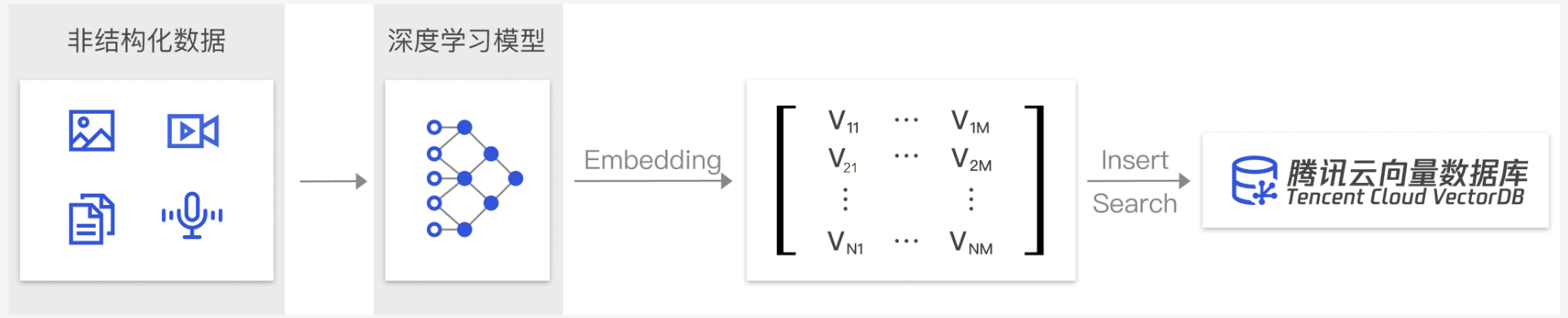
在 AI 时代,非结构化数据(如图片、文本、音视频)已成为企业的核心资产。腾讯云向量数据库将此类数据转化为 AI 能理解的“向量”,并提供毫秒级、高并发的智能检索能力,是构建下一代 AI 应用的核心基础设施。
什么是腾讯云向量数据库?
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、索引、检索、管理由深度神经网络或其他机器学习模型生成的大量多维嵌入向量。作为专门为处理输入向量查询而设计的数据库,它支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,高达百万级 QPS 及毫秒级查询延迟(请参见 性能白皮书)。不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
为什么选择腾讯云向量数据库?
全托管服务:无需关心底层基础设施,自动化部署与运维,显著降低机器成本、运维成本与人力投入。
性能与规模:自研分布式架构,轻松应对亿级向量数据,最高支持百万级 QPS,通常可达毫秒级检索延迟,满足高要求的业务需求。具体数据,请参见 性能白皮书。
企业级可靠性与安全:提供高可用架构、数据冗余备份和完善的监控体系,保障业务稳定与数据安全。
高效 AI 生态集成:与大模型及其他腾讯云服务深度集成,提供端到端的 AI 解决方案。
关键概念:快速理解向量世界
概念 | 通俗解释 | 与腾讯云向量数据库的关联 |
向量 | AI 的世界语言。它将文本、图像等非结构化数据转换为一串数字,捕捉其核心特征。 | 数据库存储和管理的核心对象。 |
向量检索 | 在向量空间中寻找“最相似”的数据。它不是精确匹配,而是相似性匹配。 | 数据库的核心功能,通过先进的索引算法实现毫秒级检索。 |
索引 | 为了加速检索而建立的数据结构,如同书籍的目录。 | 提供多种索引类型,可根据数据规模和应用场景灵活选择。 |
相似度度量 | 判断两个向量是否相似的“尺子”。 | 向量数据库通过相似度计算方法计算两个向量之间的相似距离来分析它们之间的相关性。 |
核心技术:支持哪些索引类型和相似度计算方法?
索引类型 | 核心原理 | 最佳适用场景 |
FLAT | 暴力比对,精确搜索 | 数据量小(<10万),要求100%召回率的基准场景 |
HNSW | 基于多层图结构,快速导航 | 通用首选,百万至亿级数据,平衡高性能与高召回 |
IVF系列 | 聚类思想,缩小搜索范围 | 亿级以上大规模数据,追求高存储和计算效率 |
IVF_RABITQ | 聚类思想与二进制量化 | 亿级超大规模高维向量,在保证高召回率的同时实现高倍压缩 |
BIN_FLAT | 专为二进制向量设计 | 图像二值化特征等二进制数据的检索 |
相似度计算方法 | 说明 | 适用场景 |
内积(IP) | 值越大越相似 | 通用场景,尤其适用于深度学习模型输出的向量 |
余弦相似度(COSINE) | 值越大越相似 | 文本相似度计算的黄金标准,忽略向量长度 |
欧式距离(L2) | 值越小越相似 | 衡量绝对距离,在低维空间中效果良好 |
汉明距离 | 值越小越相似 | 专用于比较二进制向量的差异 |
应用场景:赋能 AI 业务
大规模知识库:企业的私域数据存储在向量数据库中可构建外部知识库,帮助企业更好地管理和利用自己的数据资源。
推荐系统:向量数据库会基于用户特征进行向量存储与检索,最终筛选用户可能感兴趣的物品推荐给用户。
问答系统:向量数据库会基于问题信息进行向量存储与检索,并返回最相关的问题与对应的答案。
文本/图像检索:向量数据库对输入的图像和文本信息进行向量存储与检索,会找到最匹配输入信息的文本或图像结果。
产品架构与接入
弹性可扩展的架构:采用分布式部署,负载均衡,支持在线平滑扩缩容,保障服务高可用。更多信息,请参见 设计架构中的部署架构。
清晰的资源层次:从 实例 > Database > Collection > Document,层次分明,管理便捷。更多信息,请参见 设计架构中的逻辑架构。
多语言 SDK 支持:提供 Python、Java、Go、C++ 等主流语言的 SDK,并附有丰富的 Demo,助您快速上手。
开发者工具 | API |
HTTP API | |
Python SDK | |
Java SDK | |
Go SDK | |
C++ SDK |



