linux 下 core 相关知识总结
原创

在以往的测试过程中,每当遇到程序出现 coredump 的状况,我的第一反应就是有 bug,让开发定位原因,但是如果自己能够去挖掘原因,在与开发沟通的过程中能明确指出问题所在,一定能提高沟通,定位问题的效率。
最近利用空余时间学习了一下 core 的基本知识,发现有很多新的发现(其实是自己以前不知道,呵呵),在这里分享给大家,希望对大家有所帮助。
1. core 文件的简单介绍
在一个程序崩溃时,它一般会在指定目录下生成一个 core 文件,core 文件包含了程序运行时的内存,寄存器状态,堆栈指针,内存管理信息等,可以帮助我们进行调试。
2. 造成 coredump 的常见原因
- 内存访问越界
- 多线程程序使用了线程不安全的函数
- 多线程读写的数据未加锁保护
- 非法指针
- 堆栈溢出
3. core 文件的生成开关和大小限制
使用 ulimit –c 命令可查看 core 文件的生成开关,若结果为0,则表示关闭了此功能,不会生成 core 文件。
- 使用 ulimit –c filesize 命令,可以限制 core 文件的大小,如果此文件大小超过限制,将会被裁剪,最终生成不完整的 core 文件。若为 ulimit –c unlimited ,则不限制 core 文件的大小。 注意:在测试前需检查 core 文件的开关是否打开;在测试过程中发现程序异常退出,但没有产生 core ,我们也需要第一时间检查 core 文件是否打开;有几种方式让程序产生 core 。
- 修改 core 文件生成大小的配置,例如 ulimit –c 1000,这个修改只对当前会话有效。
- 通过将一个相应的 ulimit 语句添加到由登录 shell 读取的文件,如 ~/.profile ,例如在wx用户下的 ~/.profile 增加 ulimit –c unlimited ,那么对于 wx 用户就可以生成没有大小限制的 core 文件,但是对于其他用户不生效。
- 修改 /etc/profile 文件,将默认配置 # ulimit -Sc 0 ,将配置改成可用,并设置为 ulimit -Sc unlimited ,那么该机器的所有用户都将生成无大小限制的 core 文件。
- 在程序的启动脚本(例如 restart.sh )的开头设置 ulimit –c unlimited ,这只是对该进程有用。
4. core 文件的名称和生成路径设置
若系统生成的 core 文件不带其他任何扩展名称,则全部命名为 core,新的 core 文件生成将会覆盖原来的 core 文件。
/proc/sys/kernel/ core_uses_pid 可以控制 core 文件的文件名是否添加 pid 作为扩展。文件内容为1表示添加 pid ,生成的 core 文件格式为 core.XXXX ,为0表示不添加。可以通过以下命令修改此文件: echo “1”> /proc/sys/kernel/ coreuses_pid 。
/proc/sys/kernel/ core_pattern可以控制 core 文件保存位置和文件名格式。可以通过以下命令修改此文件:
echo “/corefile/core-%e-%p-%t”> core_pattern,可以将 core 文件统一生成到 / corefile 目录下,产生的文件名为 core - 命令名 - pid - 时间戳,以下是参数列表:
%p表示添加pid;
%u表示添加当前uid;
%g表示添加当前gid;
%s表示添加导致产生core的信号;
%t表示添加core文件生产时的unix时间;
%h表示添加主机名;
%e表示添加命令名;
5. 如何查看 core 文件
如果我们不清楚 core 是由哪个进程产生的,我们可以通过使用命令 “ file core 文件 ”来查看。
例如 core 文件是由 test 这个进程产生的,那么通过命令 “ gdb test corefile ” 查看 core 文件的内容,在输入 bt 或 where 检查程序运行到哪里,来定位 coredump 的行。
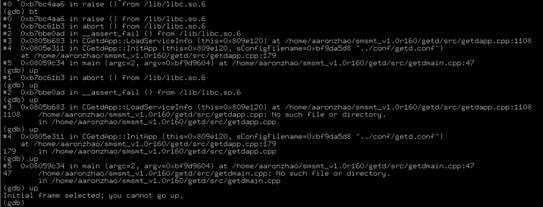
我们查看一个core的例子,例如getd在启动时出现了 core,内容为:

我们可以看到在 getdapp.cpp 的1108行调用 assert 函数出现错误,从而抛出了信号,产生了 core 。
core 显示的内容为堆栈信息,我们可以通过输入 up 来查看上一层堆栈的信息,例如:我们最初看到 core 文件信息为:

连续输入 up 后,显示内容为:
6. gdb 常用命令
有些 core 能简单的定位出,但是有些 core 文件的定位还需要了解 gdb 常用的命令,通过这些命令与 core 文件结合,我们才能快速定位出问题。下面简单的介绍一下 gbd 常用的命令:
l:相当于list,从第一行开始列出原码;
回车:表示重复上一次命令;
P:print的缩写,打印变量的值,格式为P 变量名;
break:设置断点,例如break 22表示在22行设置断点,break test表示在test函数入口处设置断点;
info break:查看断点信息;
r:表示运行程序;
c:继续运行程序;
n:next的缩写,表示单步运行;
bt:查看函数堆栈;
finish:退出函数;原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号