软硬件融合技术内幕 进阶篇 (15) —— 世界大同的梦想 (中)
软硬件融合技术内幕 进阶篇 (15) —— 世界大同的梦想 (中)

在上期,我们提到,在多处理器计算机系统中,每个物理CPU可以挂载自己的RAM,而跨Socket的内存访问也可以通过QPI/UPI总线实现。但是,QPI/UPI总线有两个难以解决的问题:
- QPI/UPI是Intel的私有标准。Intel处理器和AMD、海光、鲲鹏等异构处理器是无法互通的;
- QPI/UPI是所谓的“局部总线”,也就是其扩展范围难以突破计算机机箱的范围。如果需要访问另一计算节点的内存,QPI/UPI是无法实现的;
因此,Intel,HPE,Google以及Microsoft等业界巨头,以及国内一些中小企业,在2019年联合成立了一个开放的CXL(Compute Express Link)组织,制定相关的标准,实现跨计算机的互联体系。很快,AMD,NVidia,Sumsung,Xilinx,ARM,Broadcom,IBM,Ericsson,Marvell,Mellanox,Micron,Oracle,Qualcomm,Rambus (就是在2000年前后在SDRAM后继标准之争中败给DDR那家),Seagate,SK Hynix,Western Digital等
CXL体系如下图:
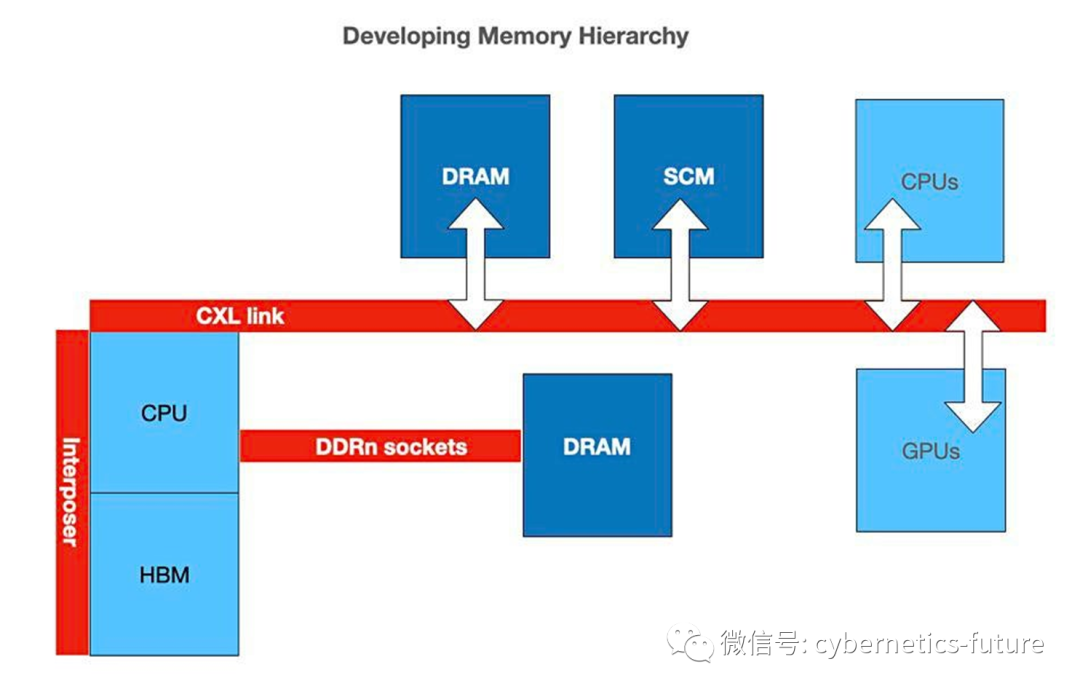
如图,CPU可以通过CXL连接其他的RAM,SCM(Storage Class Memory,非易失性内存)以及其他GPU、CPU等设备。
CXL的文档中提到,它是基于PCI-E 5.0的。可能有的读者在这个地方会疑惑:PCI-E总线是用于CPU连接IO设备,或网卡/IO设备通过DRAM控制器发起DMA的。它怎么能连接RAM呢?
原来,CXL只是复用了PCI-E总线的物理层和数据链路层。相比PCI-E总线的前身PCI/PCI-X总线标准,PCI-E做了革命性的改变,将并行的地址线/数据线改为串行总线,同时,将从前标准中的命令/地址/数据时序,使用串行总线上传输的封包来替代。CXL就是复用了PCI-E的这一系列机制实现的。在CXL标准中,甚至可以兼容PCI-E的物理插槽,在上电启动时计算机识别出该插槽连接的设备是PCI-E设备还是CXL设备。
让我们回顾一下在《软硬件融合技术内幕 进阶篇 (5) ——云计算的六次危机(下)》中提到的PCI-E总线的结构:
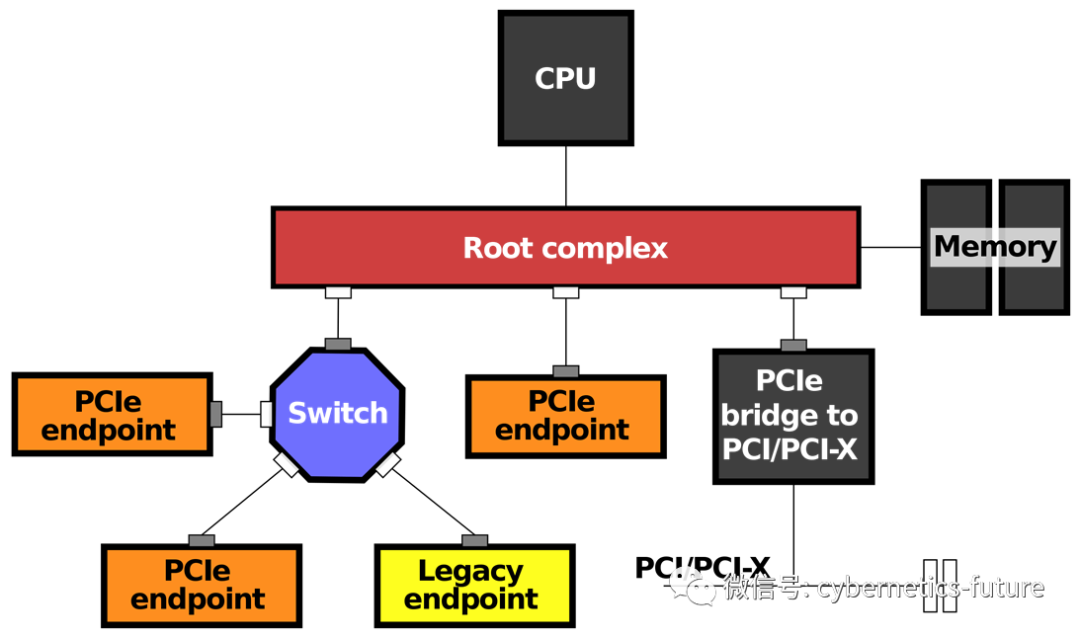
注意到蓝色八边形:
这个家伙实际上是一个PCI-E Switch。与网络中的交换机类似,PCI-E Switch也可以将多条PCI-E总线连接在一起,让N个PCI-E设备之间的互通,无需进行full-mesh的连接,大大降低了互联拓扑的复杂度。
在CXL中,也有CXL Switch这么一个角色,它在CXL系统中的位置如下图:
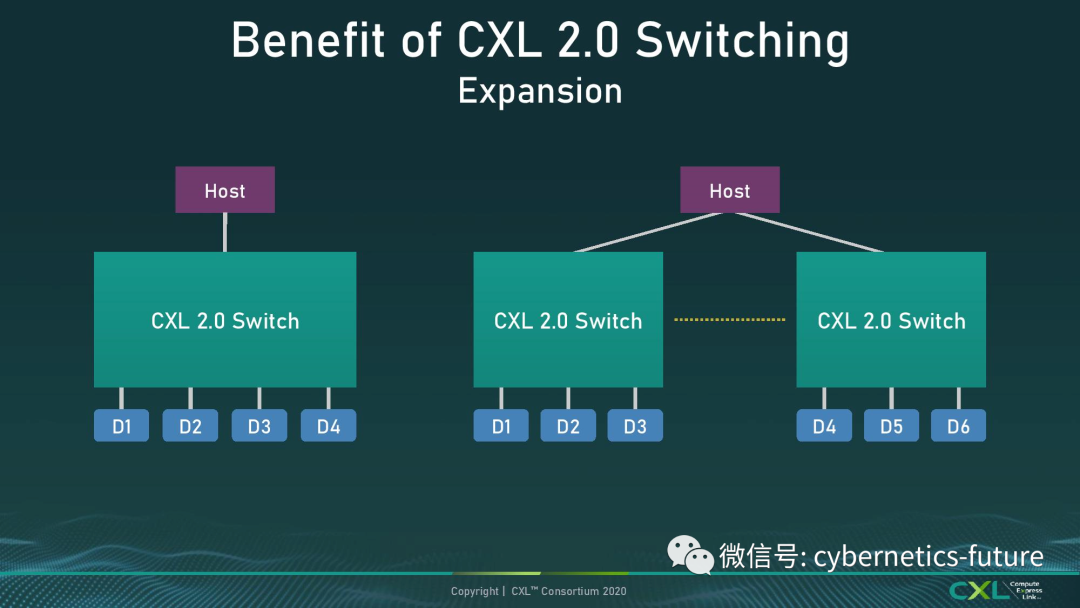
如图,主机通过一条或多条CXL总线,可以实现连接多个CXL Switch,扩展出通往更多Device的通路。

CXL支持三种类型的Device,其中Type1和Type2主要用于连接网卡、FPGA、GPU或TPU(Tensor Process Unit,张量处理单元,一般专门用于深度神经网络模型的训练与推理)等设备。而Type3用于Memory Expander,也就是内存扩充器。
CXL Type3的连接方式如下图所示:
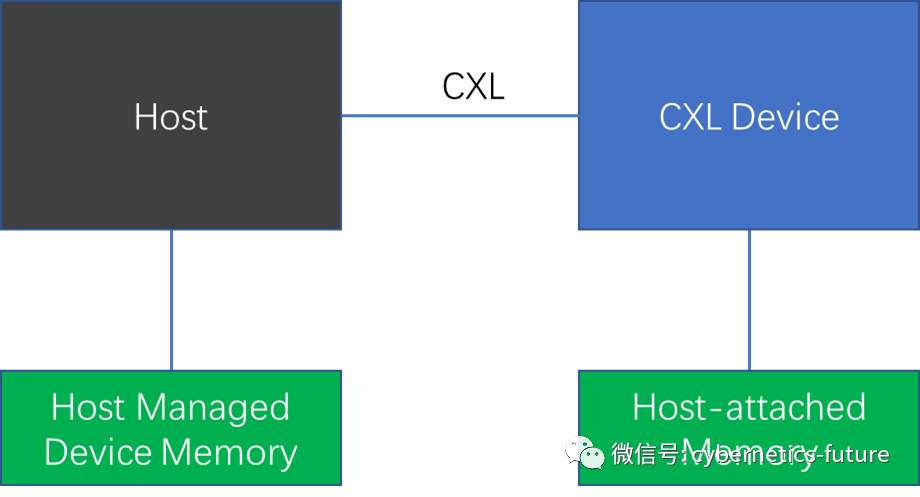
主机Host通过CXL可以访问CXL Device,从而读写CXL Device上的内存。在初始化枚举设备及执行ioctl控制平面命令时,Host通过CXL.io协议对CXL Device进行初始化,而数据平面通过CXL.mem协议,使得Host可以透明地(也就是对指令而言没有差别地)访问远端内存。这样一来,如果另一台服务器被视为Type2的CXL Device,服务器之间就可以共享内存了!
服务器共享内存的价值在哪里呢?
我们在《虚拟化与云计算技术硬核内幕 (22) —— 十个茶杯八个盖》中提到过,在生产环境中,虚拟化宿主机的内存是不允许超分配的。由于虚拟机售卖规格的差异,有可能出现部分宿主机空闲内存较多,而部分宿主机空闲CPU资源较多的情况。
r
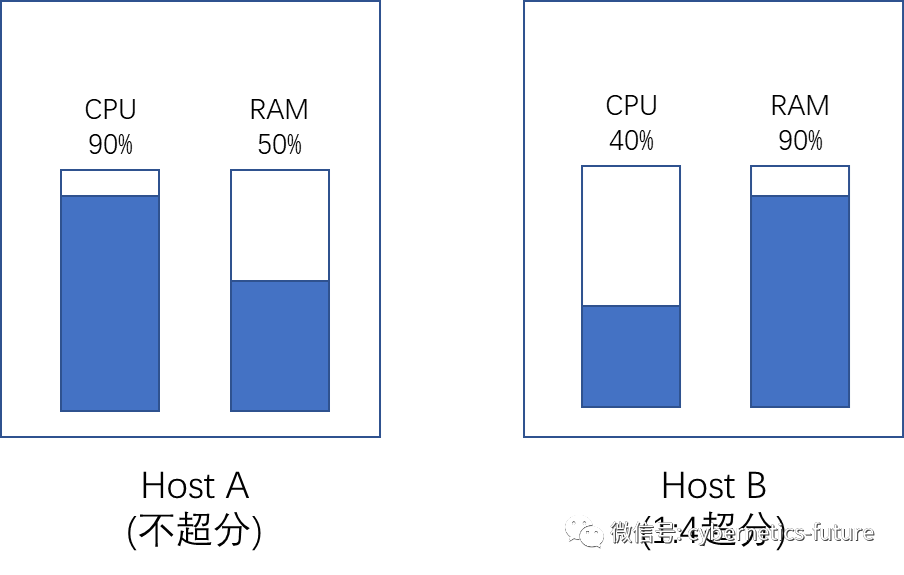
如图,由于售卖策略的不同,Host A上不超分CPU,90%的CPU已经被占用,而RAM尚有50%可售卖资源。而Host B开启了1:4的CPU超分,但由于内存无法超分,因此Host B上内存接近售罄,但CPU仍有60%空闲。
在引入CXL后,由于CPU可以直接访问其他宿主机的RAM,我们就可以实现资源的整合,让Host A上多余的内存和Host B上多余的CPU整合售卖,如下图:
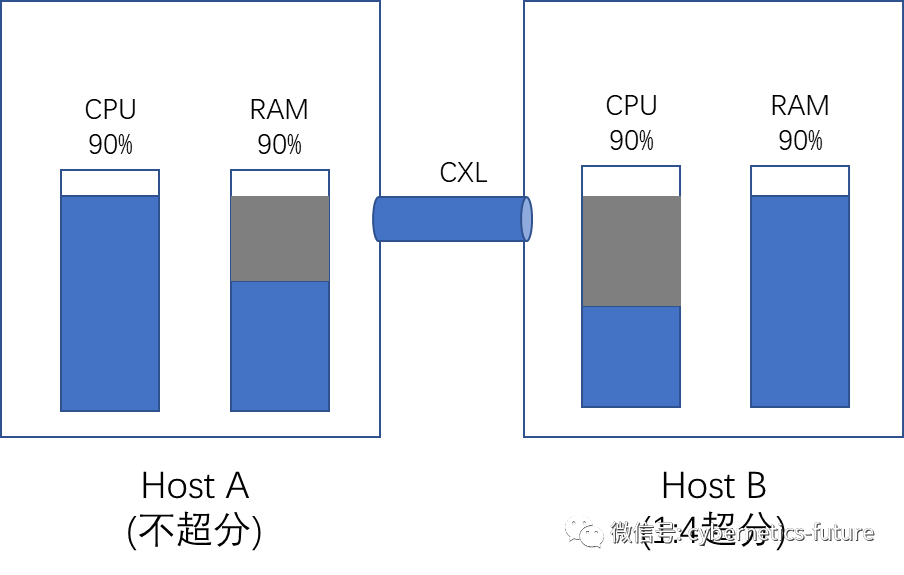
然而,理想与现实总是有一定的差距的。
在分布式系统中经常出现的一个谬误就是:假设网络传输是可靠并无时延的。事实上,即使在同一个机箱内,Intel的UPI/QPI,或AMD的Infinity Fabric连接,其时延也不是完全可以忽略的。在上一期我们就提到,无论是Intel还是AMD处理器,跨NUMA的内存访问性能略低于NUMA内。
那么,在计算机系统中应当如何解决这一问题呢?
请看下期。