真希望你也明白runtime.Map和sync.Map
原创
真希望你也明白runtime.Map和sync.Map
原创
面向加薪学习
发布于 2022-12-13 09:28:26
发布于 2022-12-13 09:28:26
Map 官方介绍
One of the most useful data structures in computer science is the hash table. Many hash table implementations exist with varying properties, but in general they offer fast lookups, adds, and deletes. Go provides a built-in map type that implements a hash table.
哈希表是计算机中最有用的数据结构之一。提供快速查找、添加和删除。 Go 提供了一个实现哈希表的内置 Map 类型。
Hash 冲突
那对于 Hash 的一个最重要的问题,就是 hash 冲突。下面我们看一下常用的解决方案。
开放寻址法
开放寻址法想象成一个停车问题。若当前车位已经有车,则继续往前开,直到找到一个空停车位。
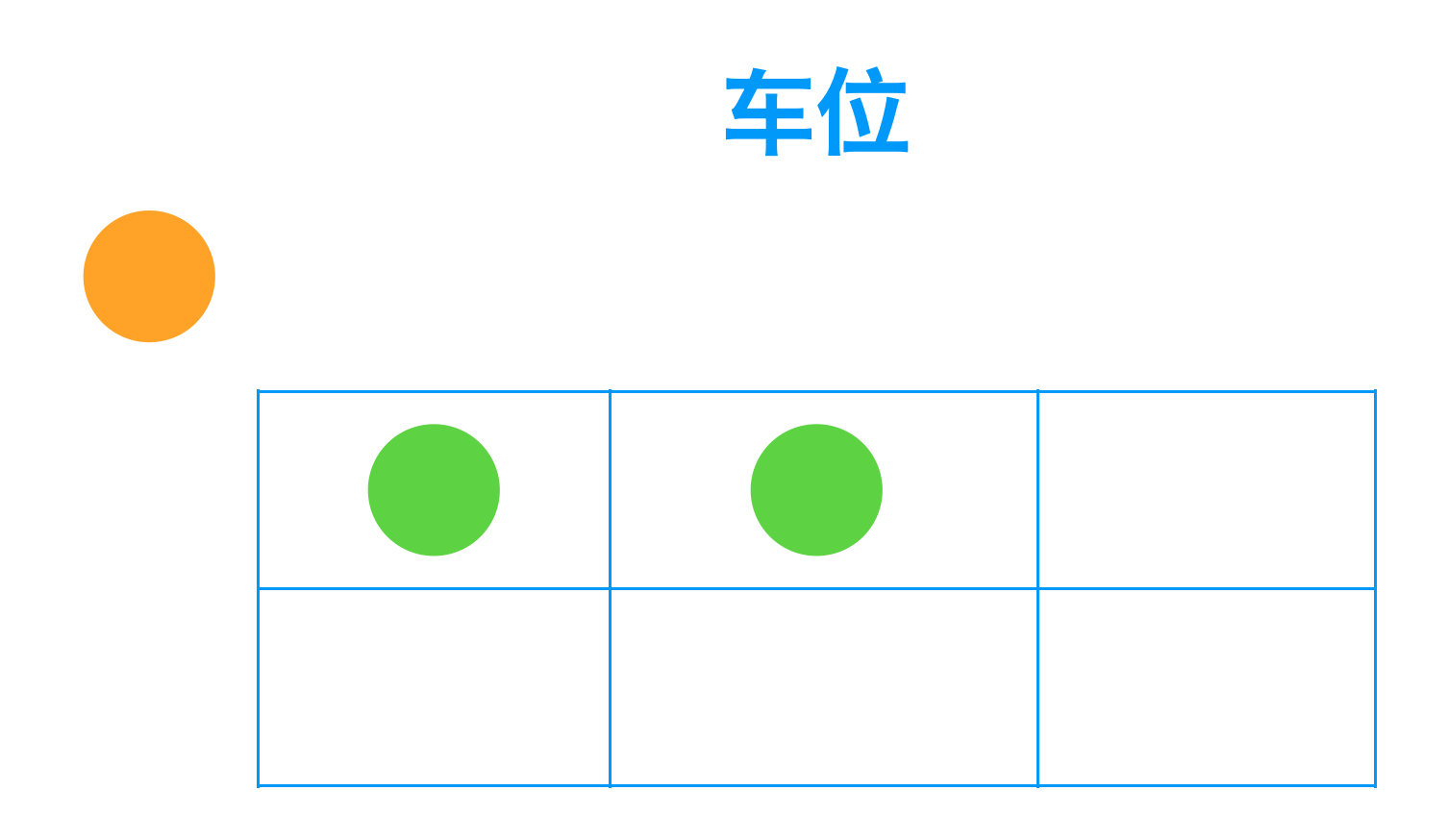
go-32-001
上图,每个方格子,就是一个车位,当一辆车来的时候,会依次查询是否有空位,如果没有,则继续向后面找,如果发现空位置,就会停到空位置中。
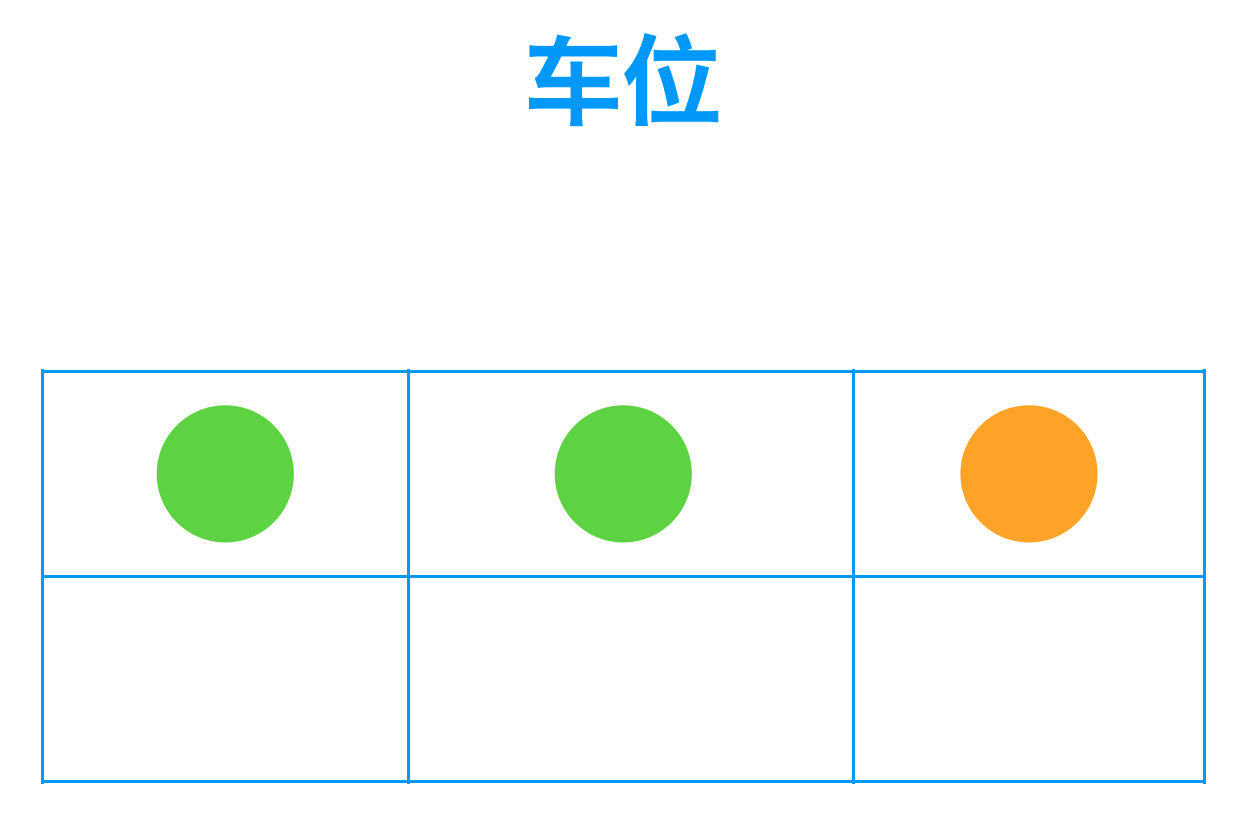
go-32-002
下面看一下,我们的代码是如何实现的?
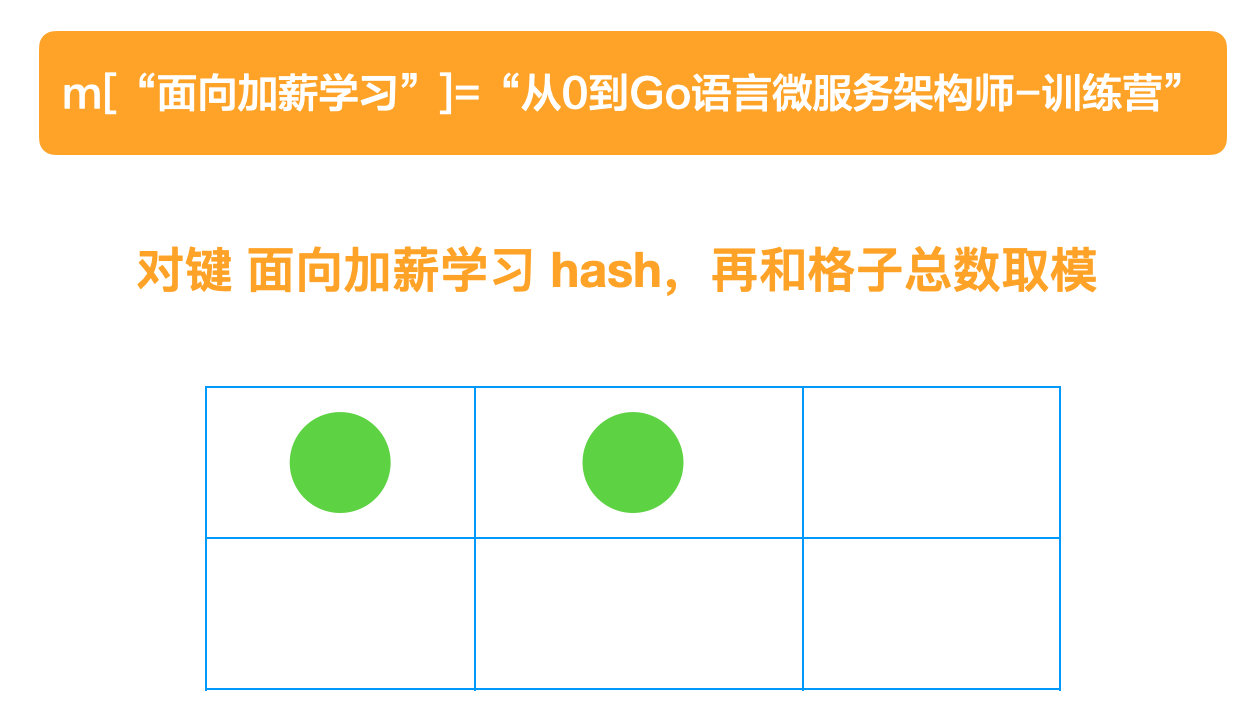
go-32-003
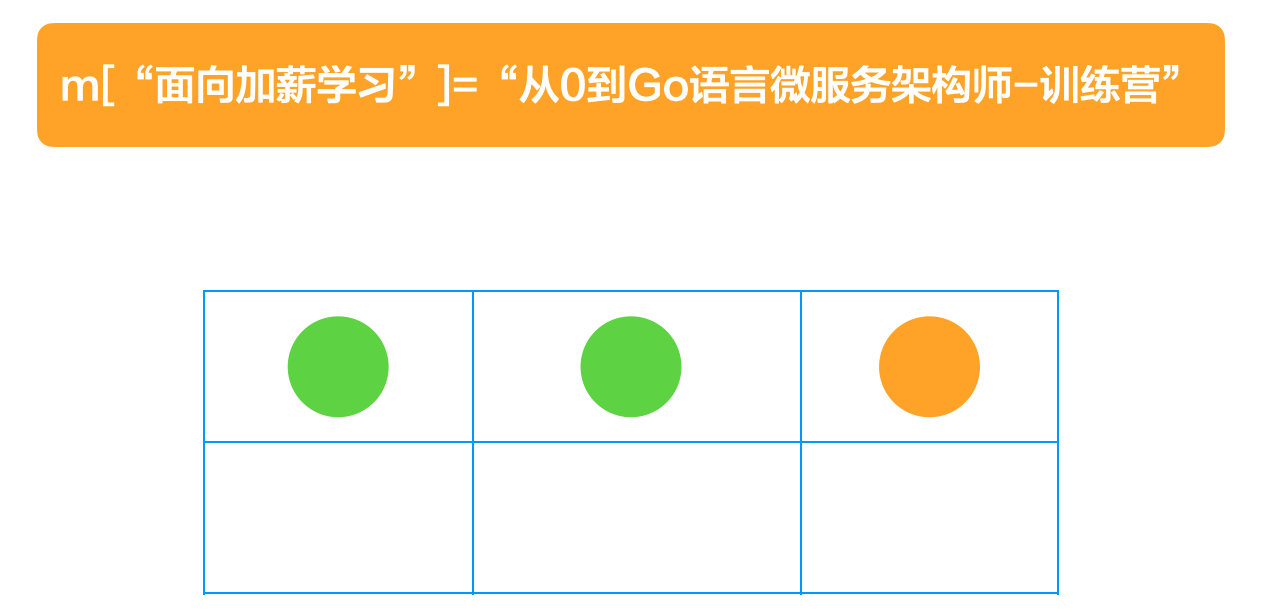
go-32-004
- m"面向加薪学习"="从 0 到 Go 语言微服务架构师-训练营"
- 要对键-"面向加薪学习",进行 hash
- 拿到全体格子的总数,然后取模
- 如果取模发现是位子 1,但是发现 1 已经被别人占了,那么就向后走,直到有空位,再把自己放进去。
看了上面的步骤是不是和停车,是一个道理?
那我们再看,如果想读取数据的时候:
- 同样对 J 键进行 hash
- 拿到全体格子的总数,然后取模
- 找到位置是 1,但是发现 key 不一样,它可能在后面,就一直向后查找。
拉链法
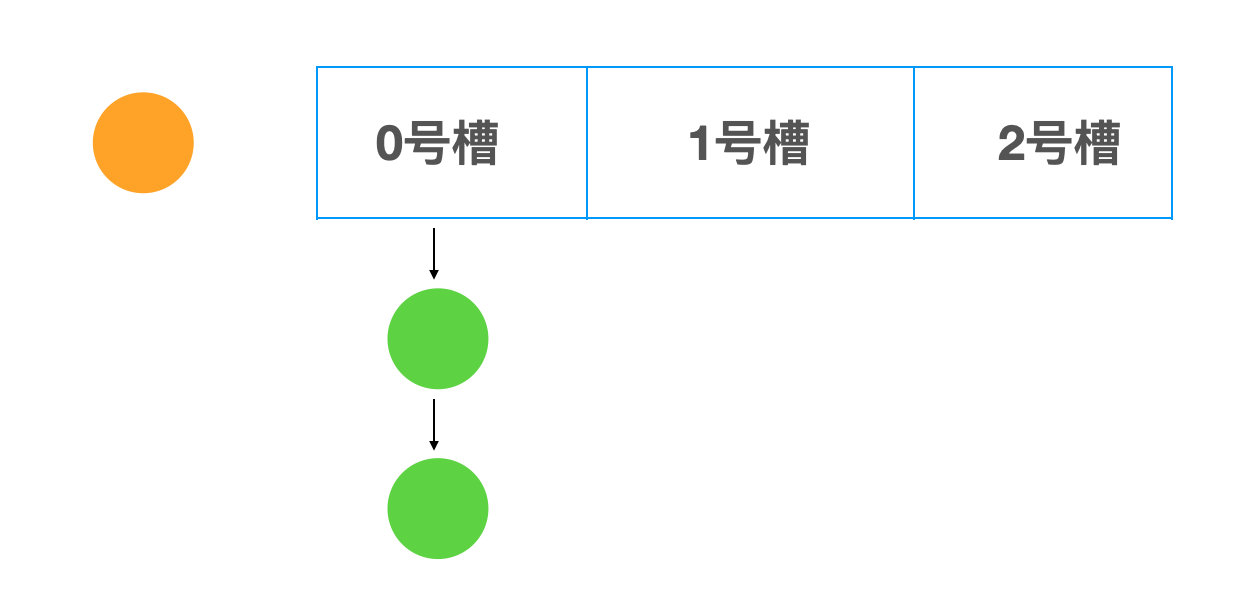
go-32-005
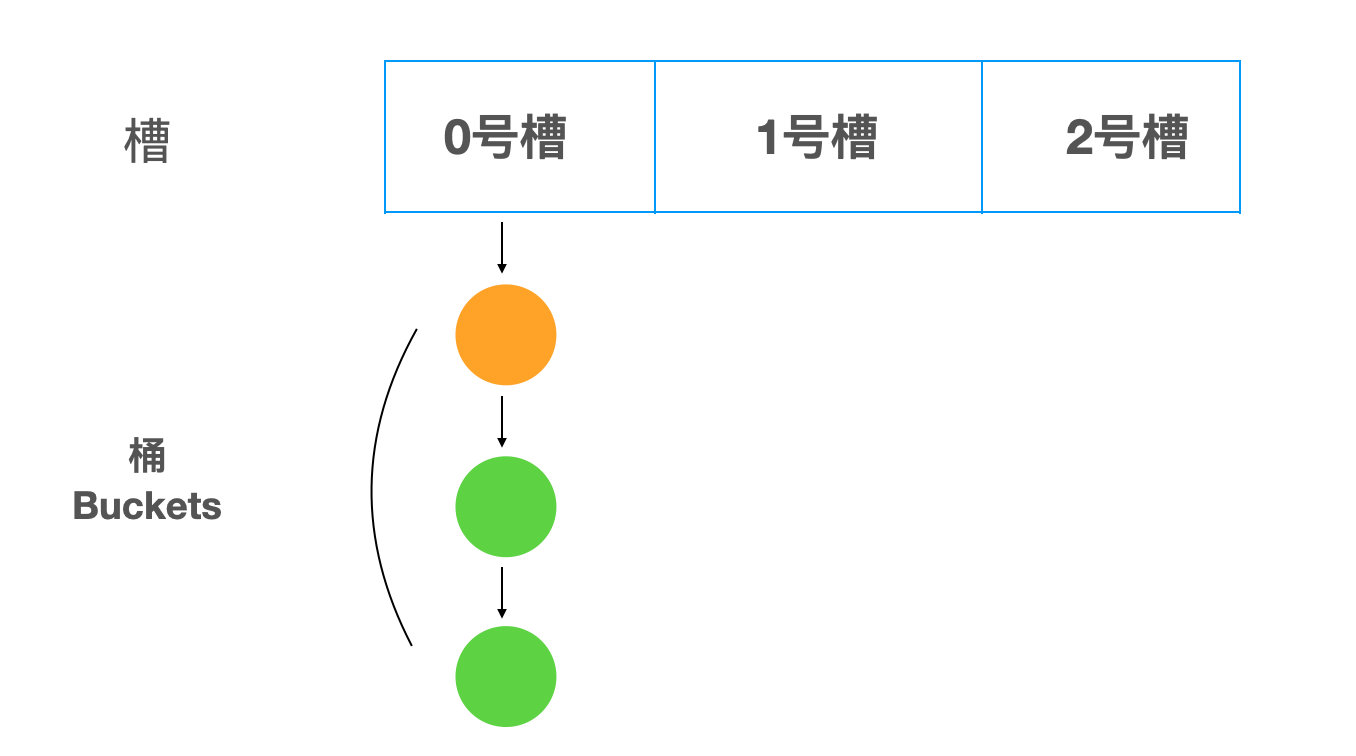
go-32-006
- m"面向加薪学习"="从 0 到 Go 语言微服务架构师-训练营"
- 要对键-"面向加薪学习",进行 hash
- 找到对应到槽位,每个槽位并不存储具体数据,只是一个指针,它指向下面的链表
- 当新增数据的时候,会把数据添加到链表头部(上图中黄色小球为例)
Go 语言的 Map
runtime/map.go,看到 hmap 这个结构体,它就 go 语言的 map
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}- count 键值对的数量
- B 是以 2 为底,桶个数的对数
- hash0 hash 的种子
- oldbuckets 旧的 hash 桶
- buckets hash 桶
下面看一个 Go 语言的哈希桶具体长什么样?用 bmap 结构体表示
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
type bmap struct {
tophash [bucketCnt]uint8
}bucketCntBits 一个哈希桶可以存放最大的 KV 键值对的数量
bucketCnt Hash 桶的数量(左移 3 位,也就是 8。)
tophash [8]uint8uint8 是无符号的 8 为数字,也就是 1 个字节。 tophash 是存储桶中的每个键的哈希值的顶部字节(1 个字节)。同样,k 和 v 也是对应的 8 个。然后在编译的时候,将所有键和值再打包,这样就避免了在 bmap 中固定 K 和 V 的类型,最后还有一个 overflow 的指针,指向一个溢出桶。
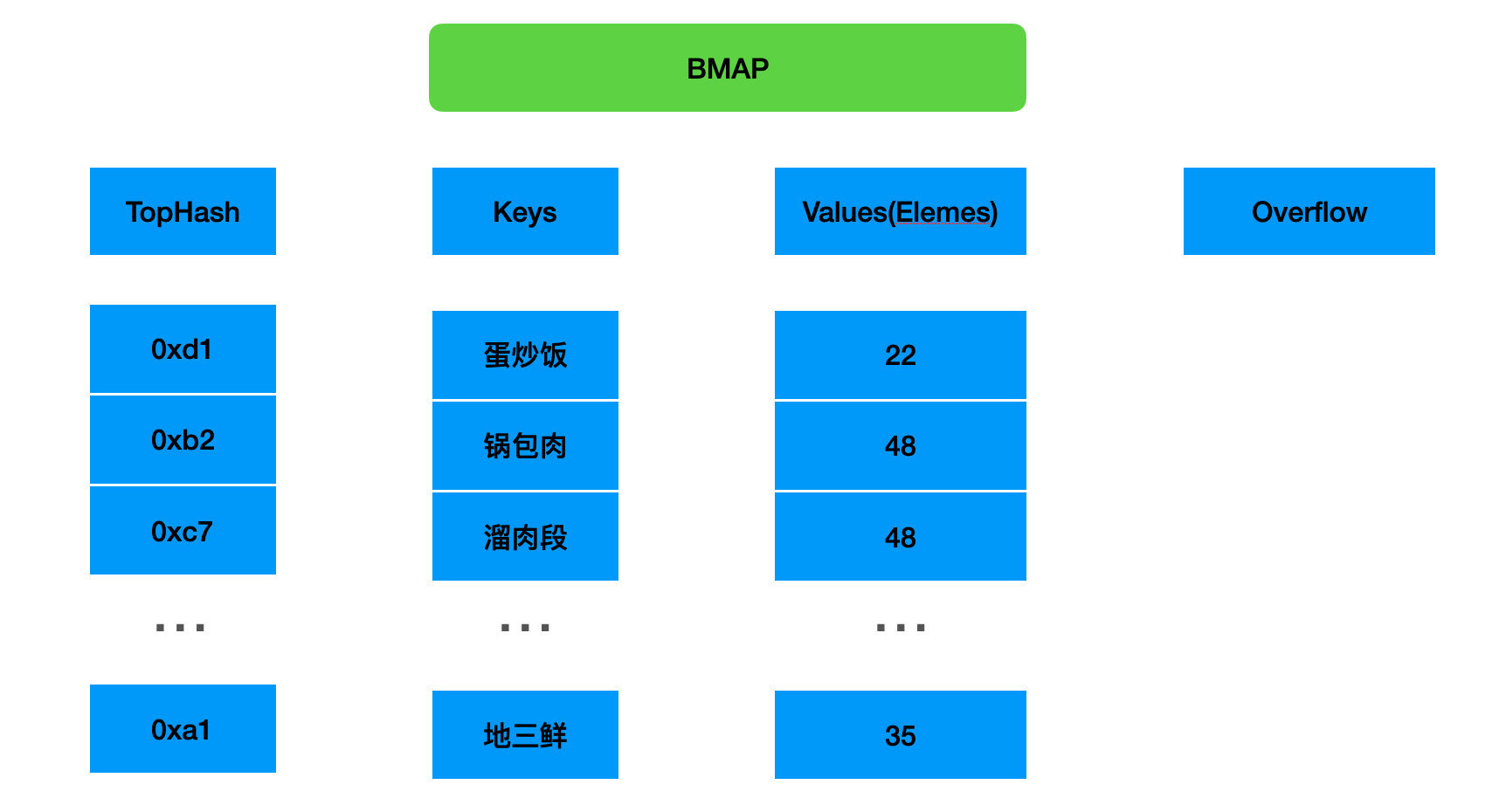
go-32-007
新建 Map
package main
import "fmt"
func main() {
m := make(map[string]int, 16)
}16 代表预计要有 16 个 Key,当然你也可以放更多的 Key,Map 会扩容,后面我们介绍到。
下面到命令行执行 go build -gcflags -S main.go
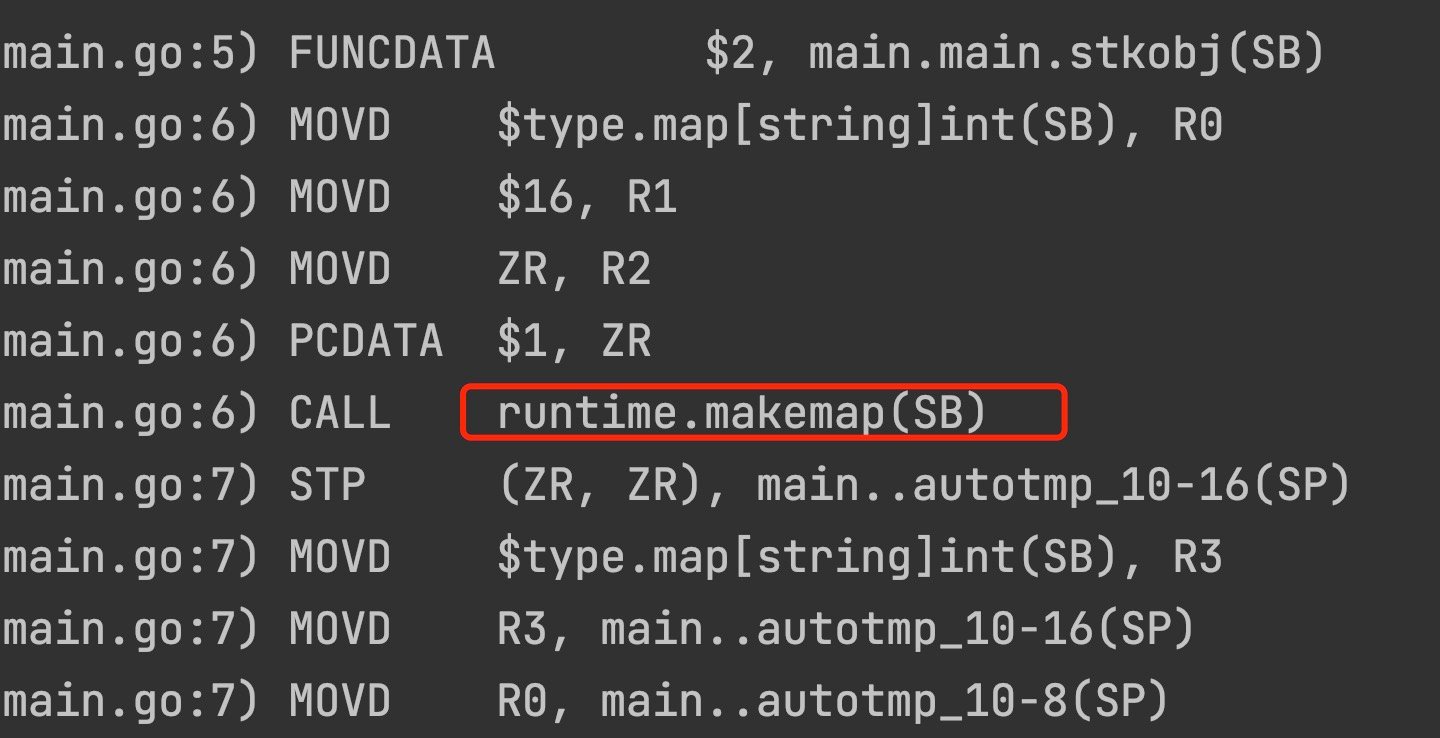
go-32-008
看到它调用了 runtime.makemap 这个函数。到 runtime/map.go 中,找到 makemap()函数。
func makemap(t *maptype, hint int, h *hmap) *hmap {
...
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
}
...
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
...4 行 新建 hmap
6 行 获取 hash 种子
9-11 行 计算 B 的个数,根据初始化的时候传入的数据。(make(mapstringint, 16) 就是这个数字 16)
15 行 生成多个 hash 桶
16-19 行 生成溢出桶,并存放在.extra 中,当一个正常的 Bmap 装满数据后,会去到 NextOverflow 中找到空闲的溢出桶,因为 Bmap 字段中,也有个 overflow 的指针。(也就是说,一开始先保持空闲捅的指针,每个 bmap 数据也不多,当哪个桶装满了,就是那个桶的 overflow 指针指向原来闲置的的溢出桶地址,然后 nextOverflow 再继续指向下一个空闲的溢出桶,也就是 nextOverflow 永远指向下一个空闲的溢出桶,等待着哪个捅满了需要新桶来装数据了,再通过那个装满数据桶的 overflow 指向这个桶,然后 NextOverflow 接着移动指针指向新空闲桶)
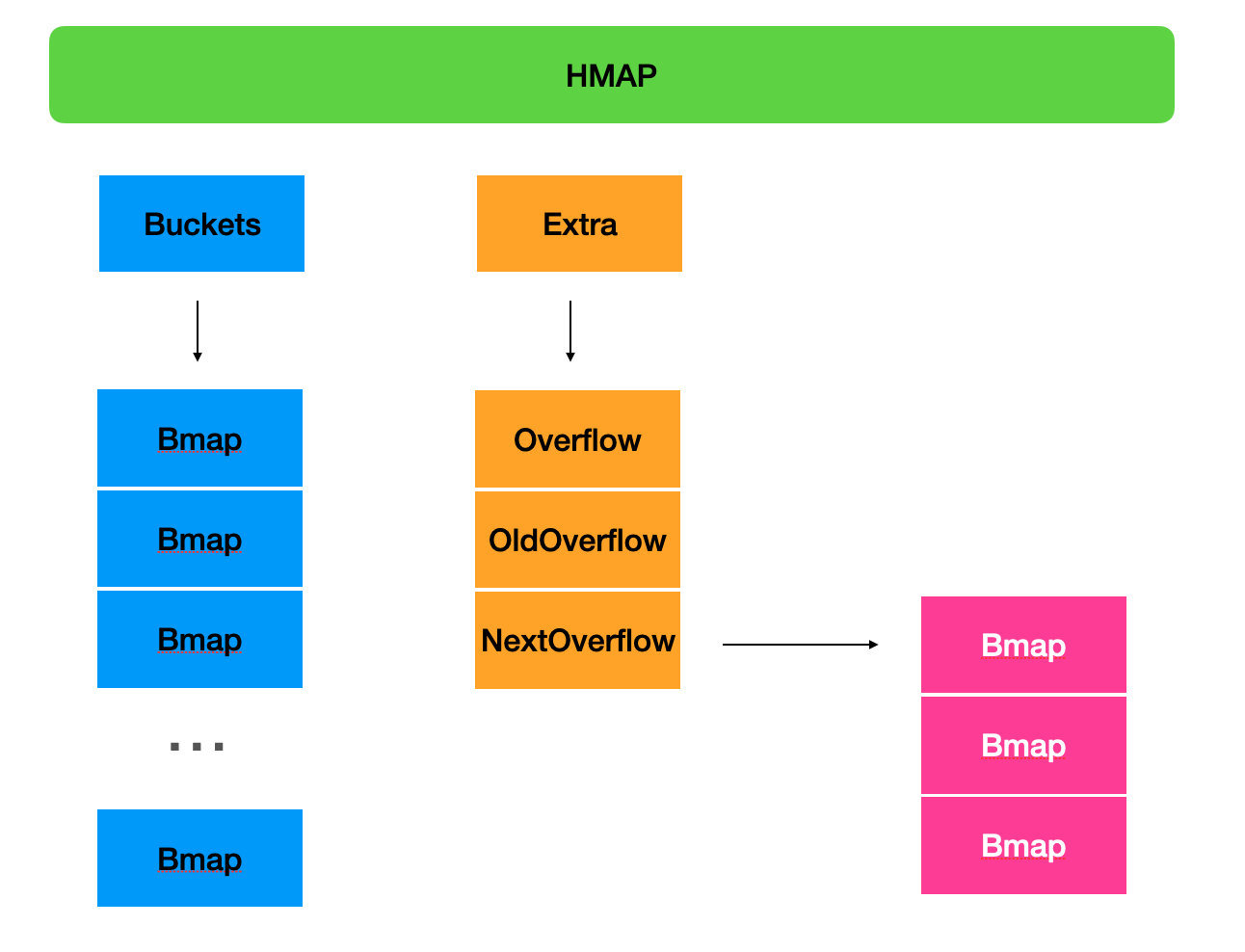
go-32-009
Map 读取数据
1.计算在哪个桶里?
Hash("锅包肉"+hash0),如果生成的二进制是 0110001101001011,如果我们的 HMap 中的 B 是 3,那么末尾取 3 位 011, 换算成十进制就是 3,就可以拿到 buket 3,由于数组是从 0 开始,所以也就是 4 号桶。
2.获取 TopHash
获取二进制前 8 位 01100011,换算成 16 位是 0x63
3.遍历 TopHash
到数组中遍历,看看哪个位置的 tophash 是 0x63
4.TopHash 相同
继续查看 key,如果相等,就返回元素,如果不相等,继续对比查找。
5.TopHash 不同
如果 4 号桶的数组都遍历完了,没有 0x63 的 tophash,如果有溢出桶,那就再去溢出桶中查找。如果都没有找到,那就是找不到 key 所对应的元素。
Map 写数据
1.找到对应的桶(桶自身或溢出桶)
2.找到对应的 key
3.修改数据的值
4.如果这个桶里没有对应的 key,那么就直接插入一个
Map 扩容都做了什么?
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
...
}可以看到有 2 个条件可以触发 Map 的扩容
- hmap 不在增加并且溢出因子很多
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}
bucketCnt 是 8,loadFactorNum 是 13,loadFactorDen 是 2
- 太多的溢出桶(这个会形成非常长的链表,导致严重的性能下降)
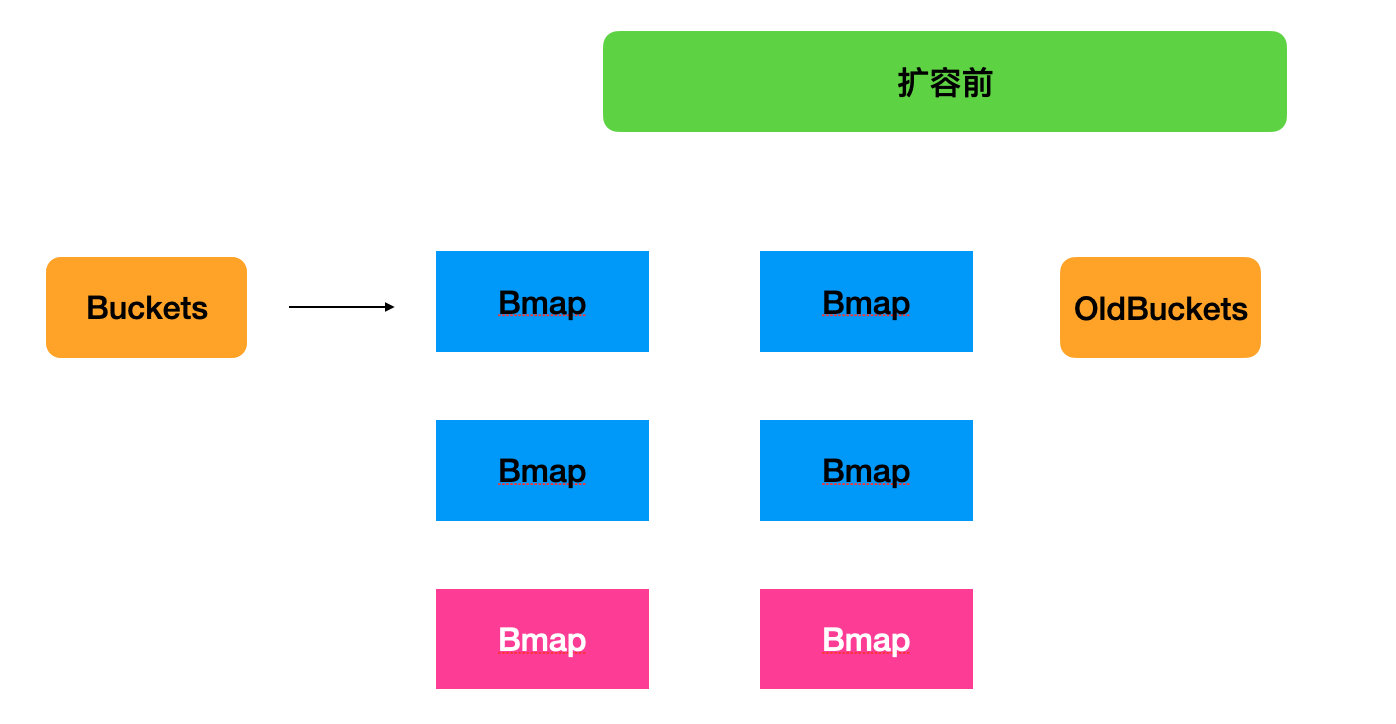
go-32-010
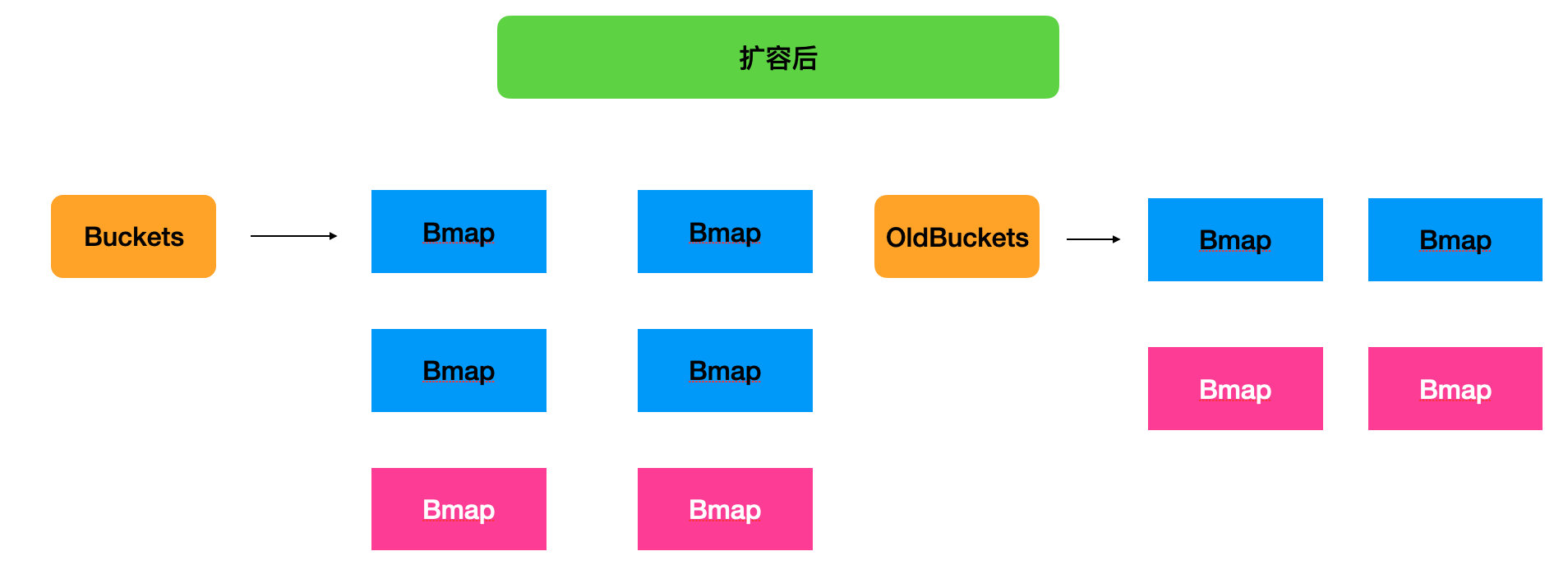
go-32-011
看一下代码
func hashGrow(t *maptype, h *hmap) {
...
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
...
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
if h.extra != nil && h.extra.overflow != nil {
...
}
}- 3 行 把原来的桶给 oldbuckets
- 4 行 h.B+bigger 进行创建新桶和溢出桶
- 6 行 更新 B 的值
- 7 行 更新 flags
- 8 行 把 oldbuckets 给 h.oldbuckets
- 9 行 把 newbuckets 给 h.buckets
- 10 行 溢出桶如果不为空,更新新桶的溢出桶
此时,新桶和老桶都存在,还没涉及到数据迁移的问题,下面我们看
Hash(“锅包肉”+hash0),如果生成的二进制是 0110001101001011,如果我们的 HMap 中的 B 是 1,那么末尾取 1 位 1, 换算成十进制就是 1,现在扩容,B 是 2,末尾取 2 位,就是 11,换算十进制就是 3,也就是说,未来数据会分配到 buket-1 和 buket-3 上。
接下来看如何处理数据
func growWork(t *maptype, h *hmap, bucket uintptr) {
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}growWork()将旧桶上的数据放到新桶中去。
数据迁移完成后,把旧桶给 GC 了。
Map 是并发安全的吗?
基于上面的学习,我们也可以看到 扩容前和扩容后, 当旧桶和新桶同时存在的时候,小明发起读数据,小刚发起写数据,小刚就会进入旧桶,进行数据迁移,那么小明很有可能在读取的时候,旧桶的数据已经被迁移到了新桶中,这样数据就会读错乱。
下面看一下 Snyc.Map(注:上面的 map 是 runtime 包下的)
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[any]*entry
misses int
}
type readOnly struct {
m map[any]*entry
amended bool
}
type entry struct {
p unsafe.Pointer // *interface{}
}- 2 行 mu 是一个锁
- 8-11 行 read 对应 readOnly 的结构体,readOnly 中的 m 是一个任意类型键和任意类型值的 map,entry 是包含一个 unsafe.Pointer 的指针 p 的结构体。
- 10 行 amended 是修正的意思。
- 4 行 dirty 是一个任意类型键和任意类型值的 map
- 5 行 misses 未击中
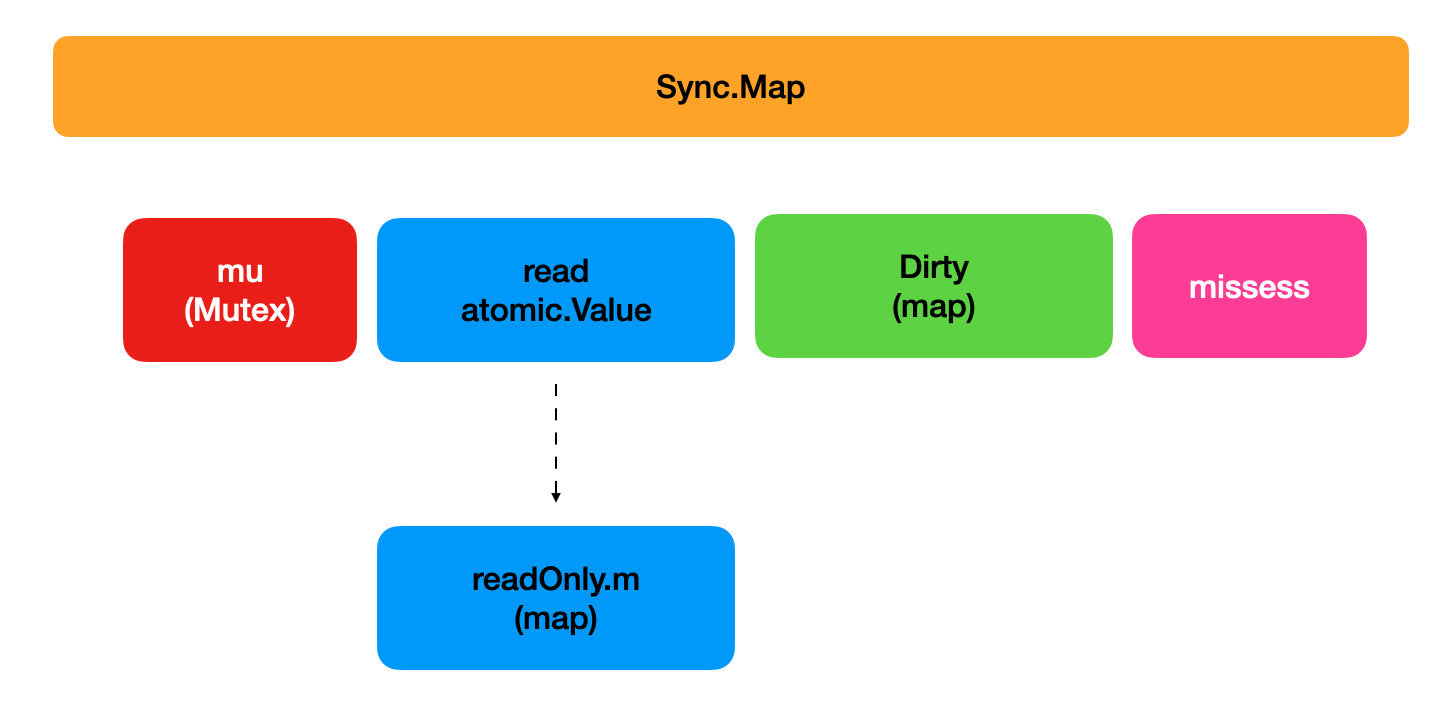
go-32-013
func (m *Map) Store(key, value any) {
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() {
m.dirty[key] = e
}
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
e.storeLocked(&value)
} else {
if !read.amended {
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}上面就是存储数据的代码。
2-5 如果 read 中中可以找到这个 Key,并且没有被标记被删除,就 tryStore(),试图去更新值。
7-24 如果 read 中不存在这个 Key 或者被标记为已删除的情况,此时加锁/解锁。
9-13 再次读取 read,此时已经找到了 Key,如果 entry 被删除了,那么就把这个 key 和 value 存储到 dirty 的 map 中
14-16 dirty 的 map 中存在这个 key,更新这个值
17 到这一步,这个判断证明 read 和 dirty 都没有这个 key,如果 read 的 amended 为假,证明 read 和 dirty 的两个 map 中的数据是相等的
18 如果 dirty 是 nil,就把 read 的数据都放到 dirty 中,否则 dirty 有数据,就怎么都不做,直接返回。
19 标记 amended 为 true,证明 read 和 dirty 不同了
21 把数据放到 dirty 的 map 中。
单协程代码演示

go-32-012
上图,从 goland 中打印出来的消息看,数据都在 dirty 的 map 中。
func (m *Map) Load(key any) (value any, ok bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}2-3 到 read 中的 map 查找 key
4-13 read 中没找到,并且 amended 为真,意味 read 和 dirty,这 2 个 map 数据不一致。(dirty 的数据通常是多的)
5-12 加锁,操作 dirty 的 map
6-7 再次读取 map
8 read 中仍然找不到这个 key,并且 amended 为真
9 去 dirty 中读取该 key
10 给 misses +1,如果 m.misses == len(m.dirty),那么就把 m.dirty 放到 read 中的 m 变量里,然后 dirty 设置 nil,misses 设置为 0
14 read 中没找到,但是 amended 为假,说明 read 和 dirty 数据相同,所以,直接返回 nil,false
17 read 中找到了 entry,直接调用 entry 的 load()方法就可以了
var m sync.Map
num := 100
var w sync.WaitGroup
w.Add(num)
m.Store("《Go语言极简一本通》第4次印刷", 1)
m.Store("《Go语言微服务架构核心22讲》", 2)
m.Store("《Go语言+Redis》实战课", 3)
m.Store("《Go语言+RabbitMQ》实战课", 4)
m.Store("《从0到Go语言微服务架构师》训练营", 5)
m.Store("《Web3与Go语言》实战课", 6)
for i := 0; i < num; i++ {
go func() {
v2, _ := m.Load("《Web3与Go语言》实战课")
fmt.Println(v2)
w.Done()
}()
}
w.Wait()
fmt.Println(m)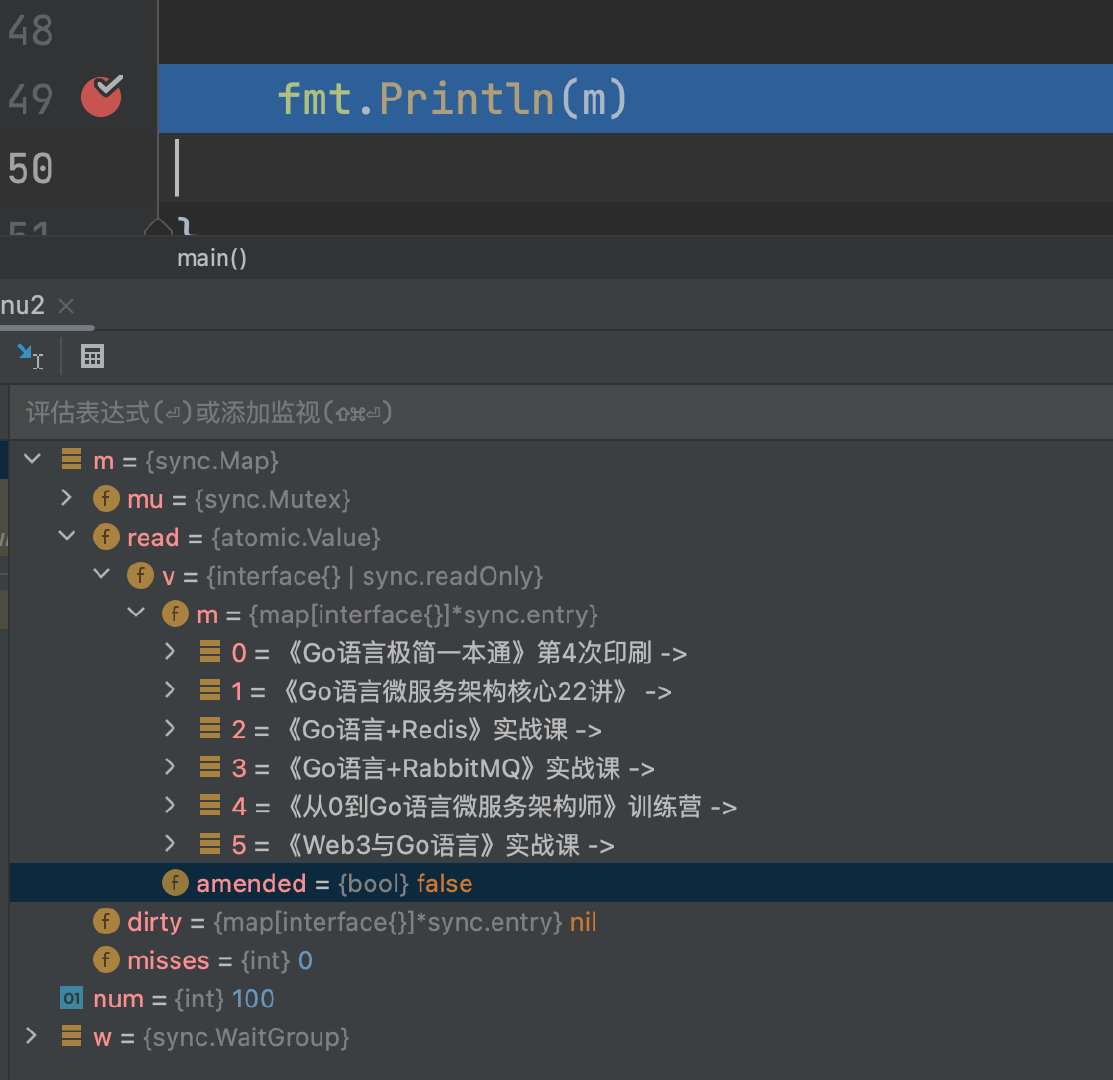
go-32-014
删除方法源代码分析
func (m *Map) Delete(key any) {
m.LoadAndDelete(key)
}
func (m *Map) LoadAndDelete(key any) (value any, loaded bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
delete(m.dirty, key)
m.missLocked()
}
m.mu.Unlock()
}
if ok {
return e.delete()
}
return nil, false
}6-7 读取 read 中的 map 的 key
8 如果没找到,并且 amended 为真,证明 read 和 dirty 中的 map 数据不相等
9-17 加锁操作 dirty 的 map
10-12 再次读取 read 中的 map,如果没找到,并且 amended 为真
13 查找 dirty 的 map 中 key
14 删除 dirty 的 map 中 key
15 判断是否把 dirty 的 map 提升到 read 中去
19-20 在 read 中找到了 entry,那么就直接调用 entry 的 delete()
在 main 协程内,执行删除操作
var m sync.Map
m.Store("《Go语言极简一本通》第4次印刷", 1)
m.Store("《Go语言微服务架构核心22讲》", 2)
m.Store("《Go语言+Redis》实战课", 3)
m.Store("《Go语言+RabbitMQ》实战课", 4)
m.Store("《从0到Go语言微服务架构师》训练营", 5)
m.Store("《Web3与Go语言》实战课", 6)
m.Delete("《Web3与Go语言》实战课")
fmt.Println(m)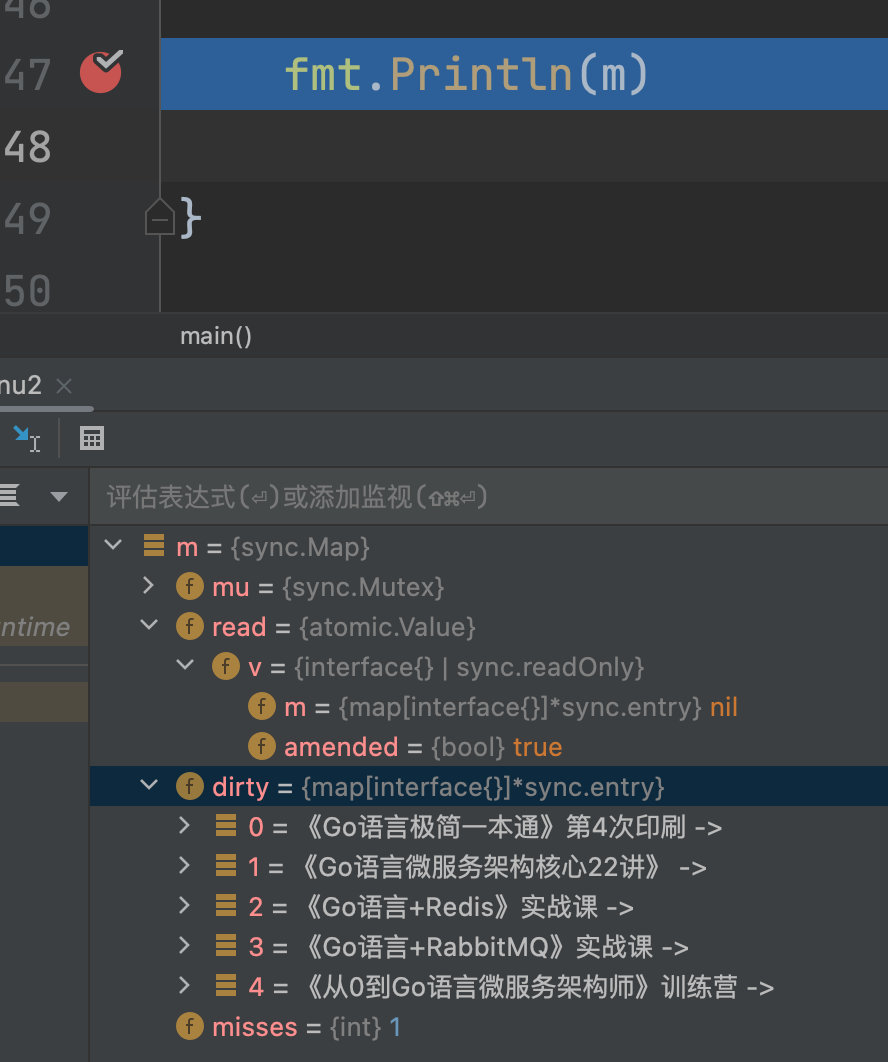
go-32-015
多协程删除操作
var m sync.Map
num := 100
var w sync.WaitGroup
w.Add(num)
m.Store("《Go语言极简一本通》第4次印刷", 1)
m.Store("《Go语言微服务架构核心22讲》", 2)
m.Store("《Go语言+Redis》实战课", 3)
m.Store("《Go语言+RabbitMQ》实战课", 4)
m.Store("《从0到Go语言微服务架构师》训练营", 5)
m.Store("《Web3与Go语言》实战课", 6)
for i := 0; i < num; i++ {
go func() {
m.Delete("《Web3与Go语言》实战课")
w.Done()
}()
}
w.Wait()
fmt.Println(m)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号