杨校老师课堂之MySQL数据库面试题【开发工程师面试前必看】
杨校老师课堂之MySQL数据库面试题【开发工程师面试前必看】

1.说一说三大范式
「第一范式」:数据库中的字段具有「原子性」,不可再分,并且是单一职责
「第二范式」:「建立在第一范式的基础上」,第二范式要求数据库表中的每个实例或行必须「可以被惟一地区分」。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主键>
「第三范式」:「建立在第一,第二范式的基础上」,确保每列都和主键列直接相关,而不是间接相关不存在其他表的非主键信息
但是在我们的日常开发当中,「并不是所有的表一定要满足三大范式」,有时候冗余几个字段可以少关联几张表,带来的查询效率的提升有可能是质变的
2.MyISAM 与 InnoDB 的区别是什么?

1.「 InnoDB支持事务,MyISAM不支持」。 「InnoDB 支持外键,而 MyISAM 不支持」。 2. 「InnoDB是聚集索引」,使用B+Tree作为索引结构,数据文件是和索引绑在一起的,必须要有主键。「MyISAM是非聚集索引」,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。 3. 「InnoDB 不保存表的具体行数」。 4. 「MyISAM 用一个变量保存了整个表的行数」。 5. Innodb 有 「redolog」日志文件,MyISAM 没有 6. 「Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI」
- Innodb:frm是表定义文件,ibd是数据文件
- Myisam:frm是表定义文件,myd是数据文件,myi是索引文件
- 「InnoDB 支持表、行锁,而 MyISAM 支持表级锁」
- 「InnoDB 必须有唯一索引(主键)」,如果没有指定的话 InnoDB 会自己生成一个隐藏列Row_id来充当默认主键,「MyISAM 可以没有」
3.为什么推荐使用自增 id 作为主键?

1.普通索引的
B+ 树上存放的是主键索引的值,如果该值较大,会「导致普通索引的存储空间较大」
2.使用自增 id 做主键索引新插入数据只要放在该页的最尾端就可以,直接「按照顺序插入」,不用刻意维护
3.页分裂容易维护,当插入数据的当前页快满时,会发生页分裂的现象,如果主键索引不为自增 id,那么数据就可能从页的中间插入,页的数据会频繁的变动,「导致页分裂维护成本较高」
4.一条查询语句是怎么执行的?
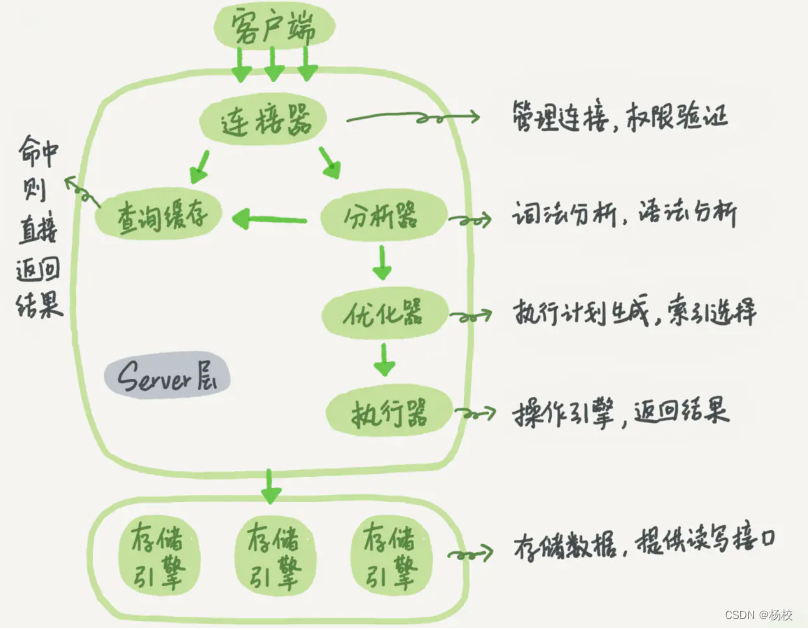
1.通过连接器跟客户端
「建立连接」2.通过查询「缓存查询」之前是否有查询过该 sql 有则直接返回结果 没有则执行第三步 3.通过分析器「分析该 sql 的语义」是否正确,包括格式,表等等 4.通过优化器「优化该语句」,比如选择索引,join 表的连接顺序 5.「验证权限」,验证是否有该表的查询权限
- 没有则返回无权限的错误
- 有则执行第六步
6.通过执行器调用存储引擎执行该 sql,然后返回「执行结果」
5. 什么是索引?
相信大家小时候学习汉字的时候都会查字典,想想你查字典的步骤,我们是通过汉字的首字母 a~z 一个一个在字典目录中查找,最终找到该字的页数。想想,如果没有目录会怎么样,最差的结果是你有可能翻到字典的最后一页才找到你想要找的字。 索引就
「相当于我们字典中的目录」,可以极大的提高我们在数据库的查询效率。
6.索引失效的场景有哪些?
以下随便列举几个,不同版本的 mysql 场景不一
1.最左前缀法则(带头索引不能死,中间索引不能断
2.不要在索引上做任何操作(计算、函数、自动/手动类型转换),不然会导致索引失效而转向全表扫描
3.不能继续使用索引中范围条件(bettween、<、>、in等)右边的列,如:
select a from user where c > 5 and b = 4;
4.索引字段上使用(!= 或者 < >)判断时,会导致索引失效而转向全表扫描
5.索引字段上使用 is null / is not null 判断时,会导致索引失效而转向全表扫描。
6.索引字段使用like以通配符开头(‘%字符串’)时,会导致索引失效而转向全表扫描,也是最左前缀原则。
7.索引字段是字符串,但查询时不加单引号,会导致索引失效而转向全表扫描
8.索引字段使用 or 时,会导致索引失效而转向全表扫描
什么是最左前缀原则
最左前缀其实说的是,在 where 条件中出现的字段,「如果只有组合索引中的部分列,则这部分列的触发索引顺序」,是按照定义索引的时候的顺序从前到后触发,最左面一个列触发不了,之后的所有列索引都无法触发。 比如「有一个 (a,b,c) 的组合索引」
where a = 1 and b = 1此时 a,b 会命中该组合索引where a = 1 and c = 1此时 a 会命中该组合索引, c 不会where b = 1 and c = 1此时不会命中该组合索引
普通索引和唯一索引该怎么选择?
查询 当普通索引为条件时查询到数据会一直扫描,直到扫完整张表 当唯一索引为查询条件时,查到该数据会直接返回,不会继续扫表
更新 普通索引会直接将操作更新到 change buffer 中,然后结束 唯一索引需要判断数据是否冲突
所以「唯一索引更加适合查询的场景,普通索引更适合插入的场景」
什么是事务?其特性是什么?
事务是指是程序中一系列操作必须全部成功完成,有一个失败则全部失败。
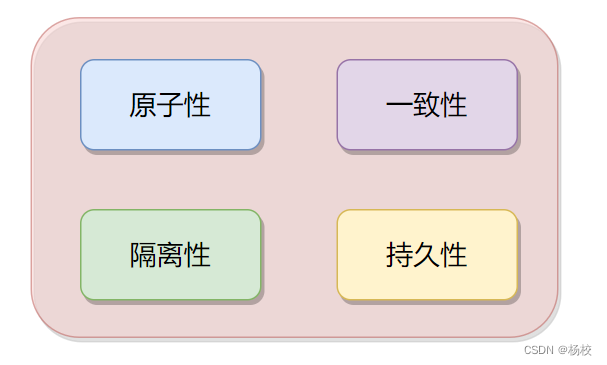
特性:
「1.原子性(Atomicity)」:要么全部执行成功,要么全部不执行。
「2.一致性(Consistency)」:事务前后数据的完整性必须保持一致。
「3.隔离性(Isolation)」:隔离性是当多个事务同事触发时,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
「4.持久性(Durability)」:事务完成之后的改变是永久的。
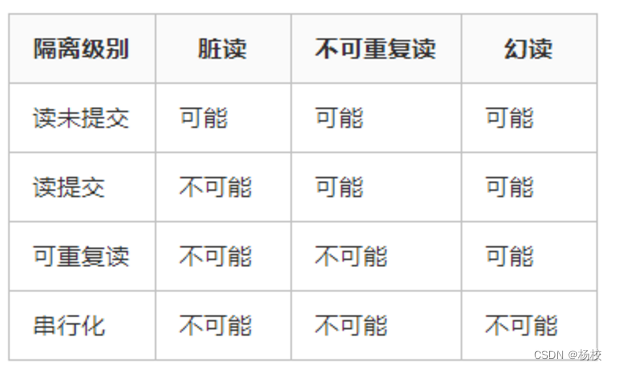
事务的隔离级别?
1.
「读提交」:即能够「读取到那些已经提交」的数据
2.「读未提交」:即能够「读取到没有被提交」的数据
3.「可重复读」:可重复读指的是在一个事务内,最开始读到的数据和事务结束前的「任意时刻读到的同一批数据都是一致的」
4.「可串行化」:最高事务隔离级别,不管多少事务,都是「依次按序一个一个执行」
- 「脏读」
- 脏读指的是·
「读到了其他事务未提交的数据」,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读
- 脏读指的是·
- 「不可重复读」
- 对比可重复读,不可重复读指的是在同一事务内,
「不同的时刻读到的同一批数据可能是不一样的」。
- 对比可重复读,不可重复读指的是在同一事务内,
- 「幻读」
- 幻读是针对数据插入(INSERT)操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现
「好像刚刚的更改对于某些数据未起作用」,但其实是事务B刚插入进来的这就叫幻读
- 幻读是针对数据插入(INSERT)操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现
说说你的 Sql 调优思路吧

1.「表结构优化」
- 拆分字段
- 字段类型的选择
- 字段类型大小的限制
- 合理的增加冗余字段
- 新建字段一定要有默认值
2.「索引方面」
- 索引字段的选择
- 利用好mysql支持的索引下推,覆盖索引等功能
- 唯一索引和普通索引的选择
3.「查询语句方面」
- 避免索引失效
- 合理的书写where条件字段顺序
- 小表驱动大表
- 可以使用force index()防止优化器选错索引
4.「分库分表」
作者: 杨校
出处: https://mryang.blog.csdn.net
分享是快乐的,也见证了个人成长历程,文章大多都是工作经验总结以及平时学习积累,基于自身认知不足之处在所难免,也请大家指正,共同进步。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 如有问题, 可邮件(397583050@qq.com)咨询