Elastic-Job2.1.5源码-分布式场景下如何用逻辑分片来进行水平扩展的?
Elastic-Job2.1.5源码-分布式场景下如何用逻辑分片来进行水平扩展的?

大家好,本文给大家介绍一下Elastic-Job 中使用的分片的概念和在调度系统中如何来获取分片
分布式场景下如何用逻辑分片来进行水平扩展的
文 | 宋小生
7.4 作业分片
分布式场景下的任务执行我们往往会有这样的一些需求,如何将大批量的任务拆分成多个小任务,又或者在集群环境下我们如何控制哪些进程可以执行一次作业,,哪些进程可以执行多次作业,哪些进程不可以执行作业。
任务的拆分执行需要将一个任务拆分为多个独立的任务项,然后由分布式环境下的进程节点分别执行某一个或几个任务项,我们可以将这些任务项称为被拆分的分片项,另外我们也可以使用这些拆分的分片项来标记某个进程是否可以执行作业或者执行几次,获取到一个分片项的进程则执行一次,获取到多个分片项的进程则执行多次,未获取到分片项的机器则不执行作业。
7.4.1 分片概念
先来看看什么是分片:分片(Sharding)将一个数据分成两个或多个较小的块,称为逻辑分片(logical shards)。尽管如此,所有分片中保存的数据,共同代表整个逻辑数据集。
分片的主要好处在于,它可以帮助促进水平扩展(horizontal scaling),也称为向外扩展(scaling out),以分散负载,允许更多的流量和更快的处理。这通常与垂直扩展(vertical scaling)形成对比,垂直扩展也称为向上扩展(scaling up),是指升级现有服务器的硬件,通常是添加更多内存或CPU。
Elastic-Job就是使用了逻辑分片的思想,将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。使用这种逻辑分片的思想可以帮助我们进行水平扩展,一方面便于拆分作业执行,一方面方便在运行时动态的扩容或者缩容。
例如:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器可以处理50%的数据量。为满足此需求,可将作业分成2个分片,每一个分片负责处理50%的数据量,让每台服务器各执行1个分片。作业遍历数据的逻辑可以为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。
如果仍旧是2台机器,想要将任务拆分成10份,则可以将分片总数设置为10 ,则作业遍历数据的逻辑可以是这样的:每片分到的分片项应为ID%10,如果只有两台服务器A,B,,而服务器A被分配到分片项0,1,2,3,4 服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历与0,1,2,3,4相关的数据;服务器B遍历ID与5,6,7,8,9相关的数据,这个时候同一台机器获取到了多个分片项,则执行的时候会进行多次执行,每个分片项的执行则可以通过不同的分片项来进行业务的处理。如果现在有更多的机器20台机器来处理,如果按平均分配的策略,则这10个分片会被10台机器获取到,这10台机器各执行一个分片项,而另外10台机器无法获取到分片,则另外10台机器上的作业进程在执行作业的时候则直接返回不做处理. 上面的场景是以平均分散在各个服务器来举例子,实际上哪些实例上获取到哪些分片,又获取到多少个分片,取决于我们配置的分片总数和分片策略。
通过以上的分片说明可以看到分片一共有2大作用:
(1)帮助拆分任务 。
(2)控制进程是否可以执行作业。
接下来我们可以看下如下图所示当作业到达了执行时间的时候未分片的作业执行和作业分片执行的场景:
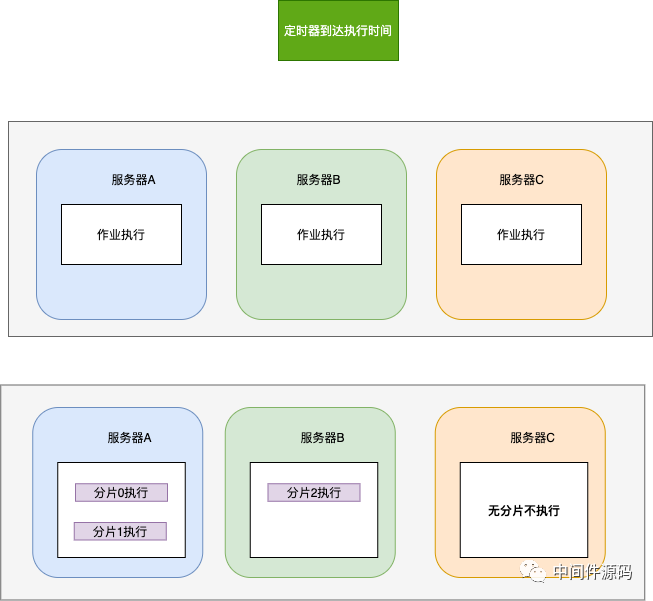
图7-1 作业执行与分片执行
7.4.2 分片上下文的获取
作业在执行的时候每台机器上的进程都会按时触发作业到了执行时间每台机器都会去获取当前机器对应的分片,当前机器获取到1个分片则执行一次,获取到多个分片则执行多次,如果当前机器未获取到分片则直接结束本次执行,主要经历这样的一个步骤:
- 如果失效转移的分片项存在,则处理失效转移的分片项。
- 当前是否需要重新分片,如果需要则选作业主节点帮助分片。
- 获取当前机器被分配到的分片项,移除无效分片。
- 返回分片上下文。
获取分片项列表的代码如下:
@Override
public ShardingContexts getShardingContexts() {
//是否开启失效转移,并且当前有待处理的失效转移项则处理失效转移的分片执行
boolean isFailover = configService.load(true).isFailover();
if (isFailover) {
List<Integer> failoverShardingItems = failoverService.getLocalFailoverItems();
if (!failoverShardingItems.isEmpty()) {
return executionContextService.getJobShardingContext(failoverShardingItems);
}
}
//如果当前需要分片则选举一个作业主主节点,作业主节点来执行分片的逻辑,将分片项按分片算法拆分给当前在线的进程实例
shardingService.shardingIfNecessary();
//获取当前节点被分配到的分片项,如果开启了失效转移则将那些崩溃分片移除
List<Integer> shardingItems = shardingService.getLocalShardingItems();
if (isFailover) {
//移除分片项中的崩溃分片
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
}
//移除被设置为不可见状态的分片项
shardingItems.removeAll(executionService.getDisabledItems(shardingItems));
//将分片项封装到上下文对象中
return executionContextService.getJobShardingContext(shardingItems);
}分片项获取的源码会根据当前作业的状态与可用实例来获取本机可以拿到的分片信息,如果当前机器执行作业的时候可以获取到分片项那就可以去执行作业,如果当前机器并未被分配任何的分配项,那当前机器就无需执行作业。
整体来看获取分片信息方法getShardingContexts一共有两部分:
① 失效转移条件满足,并且存在失效转移的分片项则本次执行失效转移的分片项
② 选主分片,获取当前机器被分配到的分片项
- 判断是否需要先进行选主分片,如果需要的会进行选主分片。
- 获取当前机器应得的分片。
- 移除失效机器和被禁用机器的分片。
- 封装分片上下文信息返回。
7.4.3 获取失效转移的分片项
当失效转移存在的时候先获取失效转移的分片项来执行,具体源码如下:
/**
* 获取运行在本作业服务器的失效转移分片项集合.
*
* @return 运行在本作业服务器的失效转移分片项集合
*/
public List<Integer> getLocalFailoverItems() {
if (JobRegistry.getInstance().isShutdown(jobName)) {
return Collections.emptyList();
}
return getFailoverItems(JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
}
/**
* 获取作业服务器的失效转移分片项集合.
*
* @param jobInstanceId 作业运行实例主键
* @return 作业失效转移的分片项集合
*/
public List<Integer> getFailoverItems(final String jobInstanceId) {
//获取所有的分片节点
List<String> items = jobNodeStorage.getJobNodeChildrenKeys(ShardingNode.ROOT);
List<Integer> result = new ArrayList<>(items.size());
//遍历所有的分片节点
for (String each : items) {
int item = Integer.parseInt(each);
//失效转移可执行节点,对应/sharding/{item}/failover
String node = FailoverNode.getExecutionFailoverNode(item);
//当前机器实例为失效转移可执行机器实例(用来执行崩溃的作业分片的节点)
if (jobNodeStorage.isJobNodeExisted(node) && jobInstanceId.equals(jobNodeStorage.getJobNodeDataDirectly(node))) {
result.add(item);
}
}
Collections.sort(result);
return result;
}读取所有分片项,判断当前分片项下面是否存在failover失效转移可执行节点(这个节点完整路径为sharding/{分片项}/failover),如果存在则说明当前节点是崩溃节点,同时崩溃后的节点被转移到当前机器,也就是failover下的instanceid与当前机器相同,则将当前分片项放入result集合中作为当前待执行分片项返回,回顾一下分片监听器FailoverListenerManager,当出现作业实例崩溃时候,可运行的机器监听到这个开启了失效转移的崩溃作业则使用分布式锁来抢占执行崩溃节点,将本机器实例信息写入失效转移执行节点(sharding/{分片项}/failover)下,而这里正是获取失效转移可执行节点来执行崩溃的作业分片的地方。如果失效转移节点存在则将失效转移分片信息封装为分片上下文对象返回。接下来看下正常执行的作业是如何获取的。
7.4.4 正常执行作业的分片项获取
先看下这一部分的源码:
//是否需要重新分片,如果需要就选作业主节点来进行作业分片
shardingService.shardingIfNecessary();
//获取当前机器实例被分片到的分片项
List<Integer> shardingItems = shardingService.getLocalShardingItems();
//移除当前机器被分配到的分片项中崩溃的分片项列表
if (isFailover) {
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
}
//移除当前机器被分配到的分片项中被禁用的分片项
shardingItems.removeAll(executionService.getDisabledItems(shardingItems));
//将当前实例的分片项封装为分片上下文
return executionContextService.getJobShardingContext(shardingItems);这里主要看下获取流程:
- 是否需要重新分片:在获取分片项之前先判断是否需要执行分片逻辑如果需要分片则进行分片。
- 获取分片:然后获取当前作业,当前实例被分配到的对应的分片项。
- 移除崩溃分片:如果失效转移配置开启,并且被分配的分片项中存在崩溃的节点要移除掉。
- 移除禁用分片:再移除被禁用的任务分片项获取最终的分片项。
- 封装分片上下文:最后根据分片项拼装分片上下文。
调度系统使用记录在Zookeeper上的逻辑分片来拆分作业和控制集群下作业的有效执行,后面我们再来看如何使用不同的分片算法进行分片。
- END -