基于Hive的数据立方体实践

Tech 导读 本文主要基于京东集团的大数据平台,详细讲述了使用Hive实现数据立方体的方法。通过阅读本文,读者可了解Hive批处理的通用多维分析技术及调优措施,并应用于生产环境。
01
概述
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
基于京东物流业务持续拓展、复杂化,业务侧人员(简称:业务侧)根据业务场景需要从数据角度做经营分析、运营分析或大促监控等。业务侧可以根据仓储、拣运、终端等场景涉及的业务动作、业务环节、业务过程等多维度分析一线操作动作是否标准、工作效率高低等。有些分析需要多个维度、有些分析甚至穷尽所有维度,统计的结果数据集,称之为数据立方体(Data Cube)。通常情况下,工程师思考的第一实现方式是union all,这很有可能会导致代码冗余。然而,通过Hive的高阶函数:with cube、grouping sets、with rollup,同样也可以达到union all的效果,且代码相对简单易维护。
02
方法简介
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。从设计稿出发,提升页面搭建效率,亟需解决的核心问题有:
准备样例数据,创建表结构,并将数据加载到所创建的表中:
【SQL】
CREATE
TABLE tmp.tmp_hivecube_test
(
`province` string COMMENT '省份',
`city` string COMMENT '城市',
`population` int COMMENT '人口数量'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC tblproperties
(
'orc.compress' = 'SNAPPY'
);
insert into tmp.tmp_hivecube_test
select '北京市','大兴区',260
union all
select '北京市','通州区',300数据插入成功,查询数据:
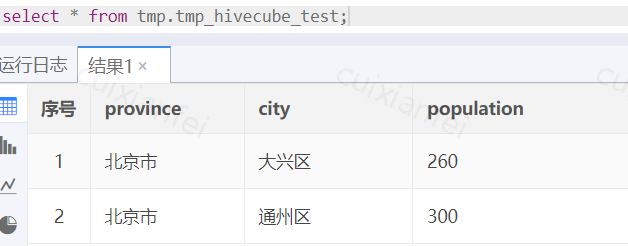
图1 准备样例数据
2.1 with cube简介
所有参与粒度统计的字段都要写在group by后面,with cube函数会将所有可能的粒度结果统计出来:N维数据模型,通过cube操作,可产生2的N次方种聚合方式。
要求统计各个维度的人口数据?
1. 使用union all方式统计,代码如下:
【SQL】
select
province
,city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
,city
union all
select
province
,null city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
union all
select
null province
,city
,sum(population)
from tmp.tmp_hivecube_test
group by
city
union all
select
null province
,null city
,sum(population)
from tmp.tmp_hivecube_test统计结果如下:
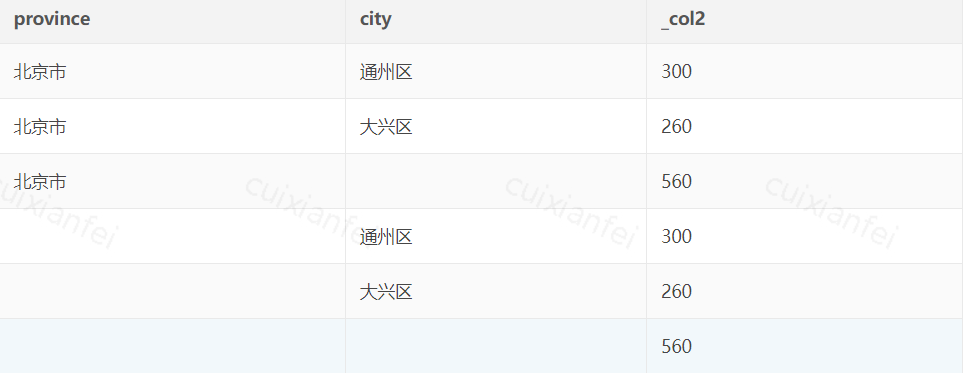
图2 union all 实现 Data Cube
2. 使用with cube方式,代码如下:
【SQL】
select
province
,city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
,city
with cube统计结果如下:
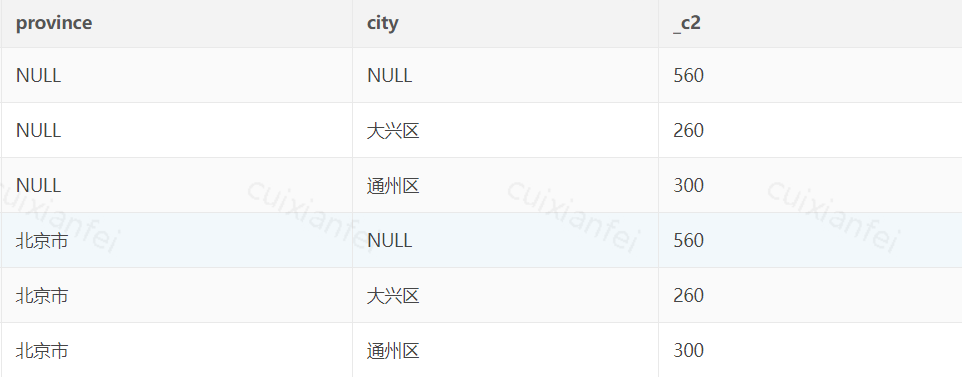
图3 with cube 实现 Data Cube
观察对比可知,union all与with cube统计结果一致,但with cube代码风格简洁易读、便于开发维护。
2.2 grouping sets简介
grouping sets可以灵活配置需要聚合的列名,按照用户需求维护聚合列的组合配置即可。假设需要(col1),(col1,col2)两种维度,配置在group by之后即可,不需要的维度不用配置。
要求统计北京市及各区人口数量?
1. 使用union all方式统计,代码如下:
【SQL】
select
province
,city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
,city
union all
select
province
,null city
,sum(population)
from tmp.tmp_hivecube_test
group by
province统计结果如下:
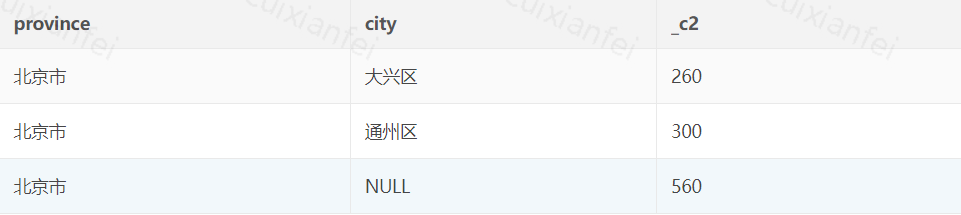
图4 union all 实现 Data Cube
2. 使用grouping sets方式,代码如下:
【SQL】
select
province
,city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
,city
grouping sets((province),(province,city))统计结果如下:

图5 grouping sets 实现 Data Cube
观察对比可知,union all与grouping sets统计结果一致,但grouping sets代码风格简洁易读、便于开发人员灵活配置统计维度。
注意:
(1)grouping sets中的所有字段,必须出现在group by之中;
(2)grouping sets中的所有字段,必须出现在group by之中;grouping sets可包含多种粒度,每种粒度单独使用在英文括号内部,不同粒度之间用逗号间隔。
2.3 with rollup简介
with rollup主要是针对不同粒度数据的聚合处理,从右到左逐层递增(递减)组合计算,不允许左侧为null右侧非null的情况出现。
要求统计北京市及各区人口数量?
1. 使用union all方式统计,代码如下:
【SQL】
select
null province
,null city
,sum(population)
from tmp.tmp_hivecube_test
union all
select
province
,null city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
union all
select
province
,city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
,city统计结果如下:
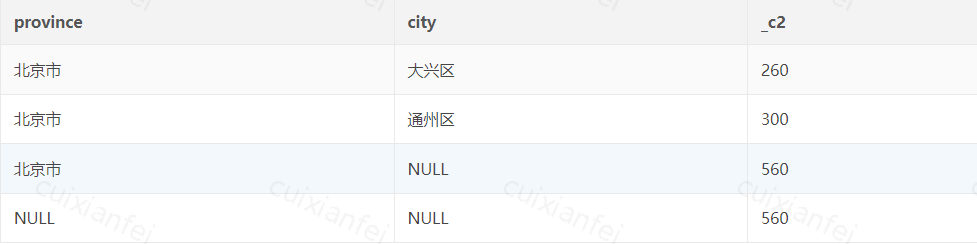
图6 union all 实现 Data Cube
3. 使用with rollup方式,代码如下:
【plain】
select
province
,city
,sum(population)
from tmp.tmp_hivecube_test
group by
province
,city
with rollup统计结果如下:
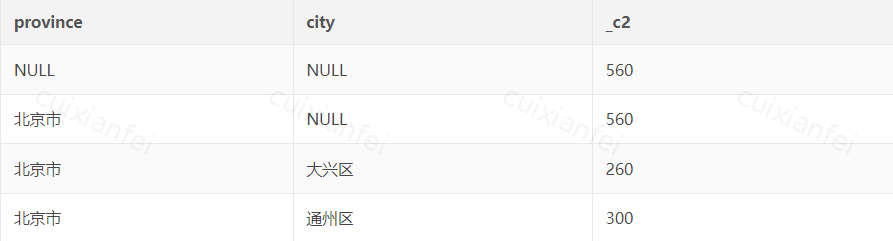
图7 with rollup 实现 Data Cube
观察对比可知,union all与with rollup统计结果一致,但with rollup代码风格简洁易读,更适合按照层级递增(递减)方式聚合。
注意:with rollup对group by后的字段排列顺序要求非常严格,顺序不一样,统计结果也会不一样。
03
实践避坑
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。从设计稿出发,提升页面搭建效率,亟需解决的核心问题有:
前文已介绍数据cube实践方法,而在实际开发过程中,用户想要不同维度组合信息做统计。可能用户前期不确定想要统计哪些维度,可将历史数据所有维度组合的指标存储起来,用户想要查看数据时,可用grouping__id(grouping与id用2个“_”连接)筛选预期数据。grouping__id是hive内置变量,可以和上文方法配合使用。grouping__id 返回对应于与行关联的 grouping 位向量的数字,在功能上等同于获取多个 grouping函数的结果并将它们连接成一个位向量(一串 1 和 0)。使用 grouping__id = n 的单个条件来识别所需的行,可以避免使用多个 grouping 函数并使行过滤条件更易于表达。
通过实例展示grouping_id使用方法,参考下图:
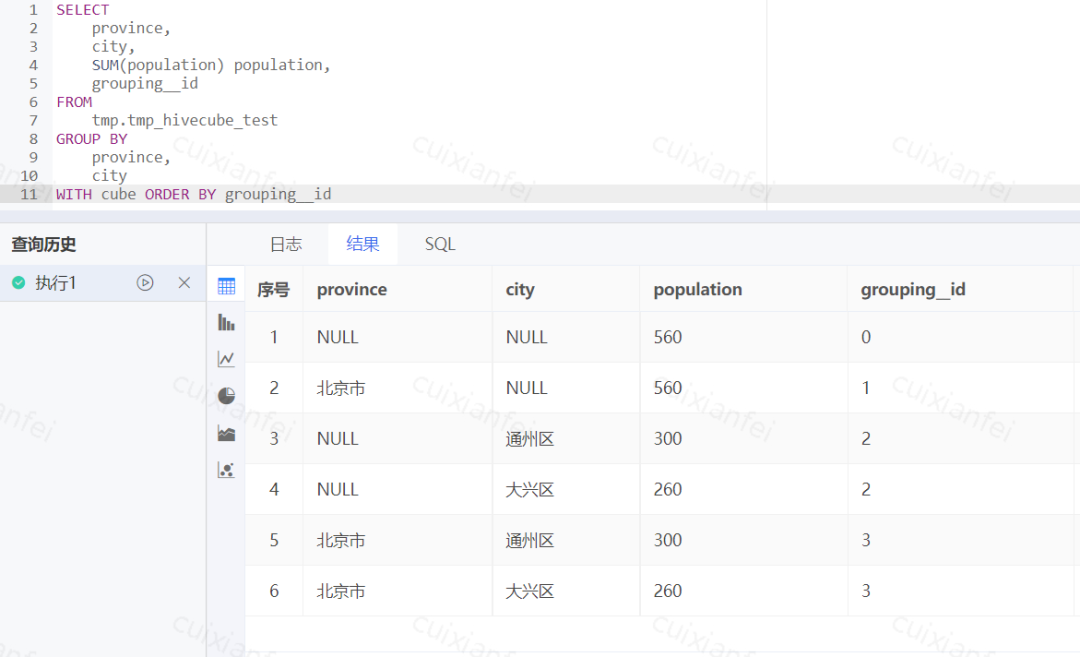
图8 Hive 内置多维分组标记 grouping_id
了解grouping__id使用方法后,使用with cube方式统计北京市及各区人口数量,grouping_id值为0或2的数据需要剔除,如下图:
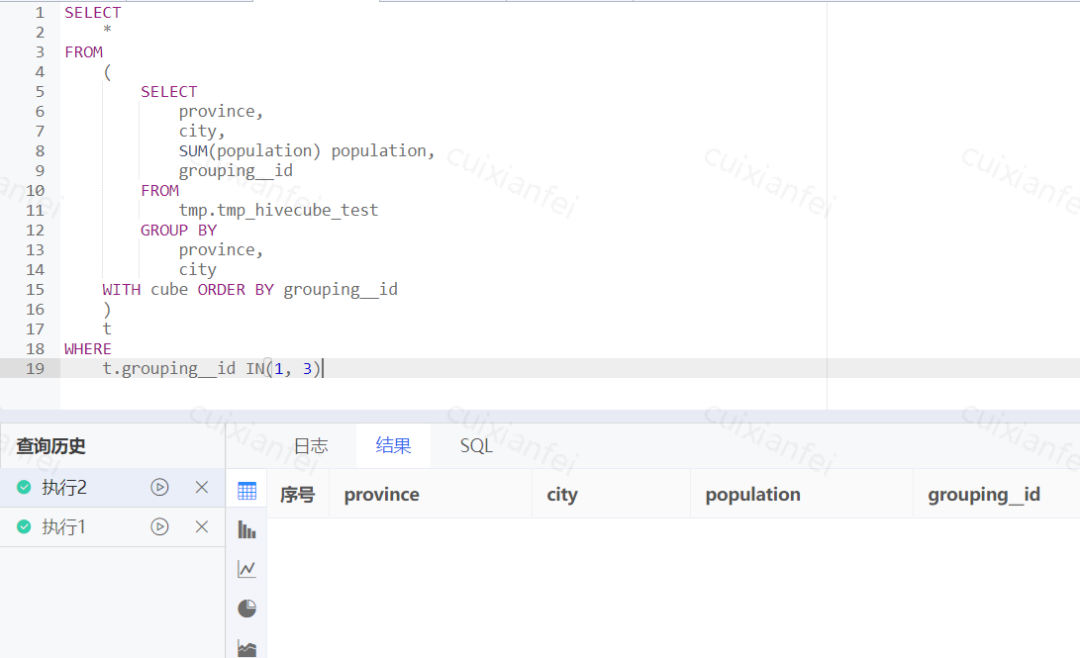
图9 grouping_id 使用示例
查询结果并非预期结果,好像grouping__id in (0,1,2,3)的所有数据都被剔除了。查看执行计划:
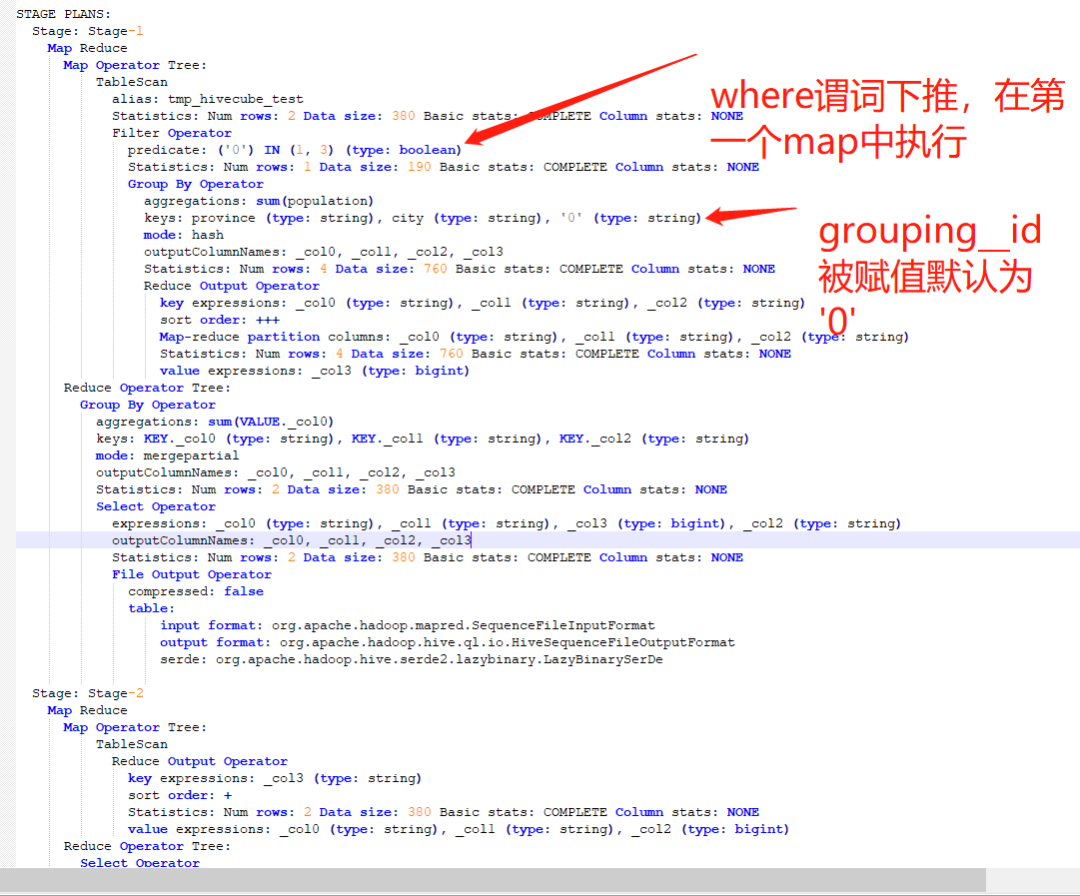
图10 Hive 执行计划
1.子查询外的where条件在第一个map中被执行;
2.cube执行前,grouping__id已经被赋值默认为‘0’。
通过分析可得,由于grouping__id默认值为‘0’,所以在做条件过滤grouping__id in (1, 3)判断结果为false,导致没有输出结果。其实,这是hive本身执行计划优化导致,称为谓词下推。其是为了将过滤条件提前到子查询中,以达到在map端尽量缩减数据的目的,碰巧遇到grouping__id先赋默认值的内置方法。可以通过增加参数(SET hive.optimize.ppd = false;--默认值为true),关闭谓词下推,可以得到预期结果,参考下图:
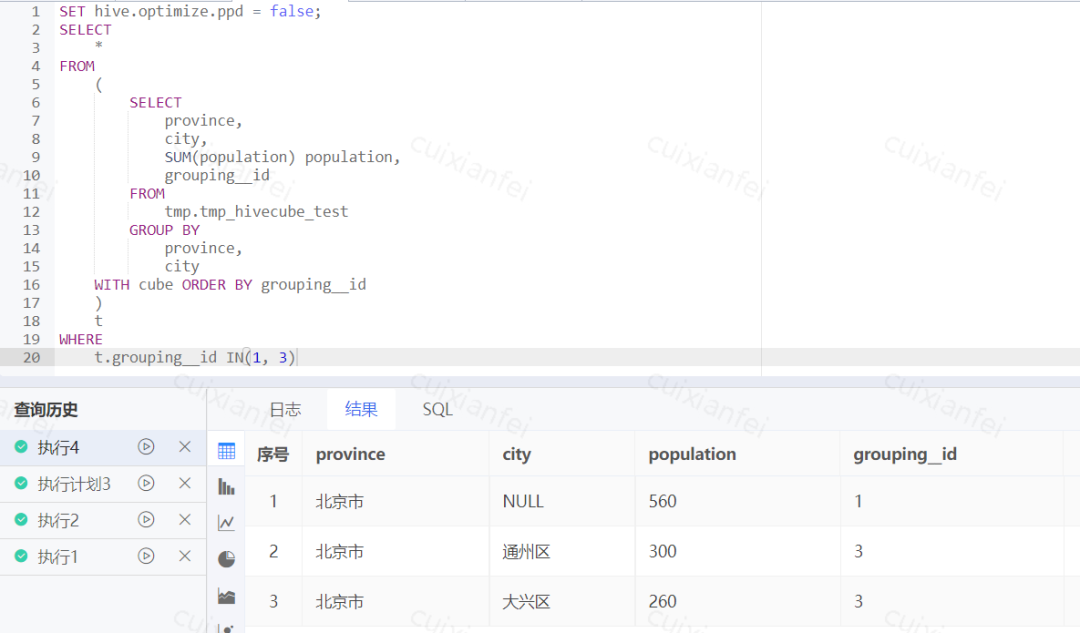
图11 关闭谓词下推
04
总结
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
在开发数据立方体实践过程中,可根据实际场景选择grouping方法:
1. 在不确定维度组合情况下,推荐使用with cube 和 grouping__id搭配使用,灵活聚合;
2. 在已确定维度组合情况下,推荐使用grouping sets,有效节省存储空间;
3. 如果存在层级鲜明、大小粒度不交叉的情况下,推荐使用with rollup,灵活上卷、下钻。